机器学习之使用FP-growth算法来高效发现频繁项集
本文根据最近学习机器学习书籍网络文章的情况,特将一些学习心得做了总结,详情如下.如有不当之处,请各位大拿多多指点,在此谢过。
一、 概述
1、相关背景
我们在日常工作生活中,总会在电脑上使用搜索引擎,输入一个单词或单词的一部分,搜索引擎会自动补全查询词项。而系统给出的这些查询推荐词项,是基于使用了一定的算法而得到的。他们通过查看互联网上的用词来查找经常一块出现的词对。显然这就需要一种高效发现频繁集的算法。
这种算法就是FP-growth算法,是基于上一篇文章提到Apriori算法构建,但在完成相同任务时采用了一些不同的技术,速度比Apriori算法要快。这里的任务是将数据集存储在一个特定的称为FP树的结构之后发现频繁项集或频繁项对,即常在一块出现的元素项的FP集合。
FP-growth算法只需对数据库进行两次扫描,而Apriori算法对每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,所以,FP-growth算法速度要高于Apriori算法。当然,在处理小规模数据时没什么问题,但在处理大数据时会产生很大的问题。FP-growth算法只会扫描数据库两次,它发现频繁项集的基本过程如下:
1)、构建FP树;2)、从FP树中挖掘频繁项集。
这种算法虽然能够高效发现频繁项集,但它不适用于发现关联规则。
2、 相关概念
FP-groth算法将数据存储在一种称为FP树的紧凑数据结构中。FP代表频繁模式(Frequent Pattern)。一棵FP树与计算机科学中的其他树结构类似,但它是 通过链接(link)连接相似元素,被连起来的元素项被称为一个链表。图12-1给出了一个FP树的例子。

同搜索树不同的是,一个元素项可以在FP树中出现多次。FP树会存储项集的出现频率,而每个项集会以路径的方式存储在树中。存在相似元素的集合会共享树的一部分。只有当集合之间完全不同时,树才会分叉。树节点上会给出集合中单个元素及其在序列中出现的次数,路径会给出该序列出现的次数。
相似项之间的链接称为节点链接(node link),用于快速发现相似项的位置。
条件模式基:头部链表中的某一点的前缀路径组合就是条件模式基,条件模式基的值取决于末尾节点的值。
条件FP树:以条件模式基为数据集构造的FP树叫做条件FP树。
3、 FP-growth算法的一般流程
1)、收集数据: 使用任意方法。
2)、 准备数据: 由于要存储的是集合,所以需要离散数据。如果要处理连续数据,需要将它们量化为离散值。
3)、 分析数据: 使用任意方法。
4)、训练算法: 构建一棵FP树,并对树进行挖掘。
5)、测试算法: 没有测试过程。
6)、 使用算法: 可以用于识别经常出现的元素项,从而用于制定政策、推荐元素或进行预测等应用中。
4、相关特性
1)、优点:
-
因为FP-growth算法只需要对数据库进行扫描两遍,所以其运行速度更快,尤其是比Apriori算法快;
-
FP树将集合按照支持度降序排列,不同路径如果有相同前缀路径共享存储空间,使得数据得到了压缩处理;
-
不需要生成候选集;
2)、缺点:
-
FP-Tree第二次遍历时会存储很多中间的过程值,占用很多内存资源;
-
构建FP-Tree是比较昂贵的。
3)、 适用数据类型:标称型数据(离散型数据)
二、工作原理
基于数据构建FP树
1、步骤1
1)、遍历所有的数据集合,计算所有项的支持度;
2)、丢弃非频繁的项;
3)、基于支持度降序排序所有的项;

4)、所有数据集合按照得到的顺序重新整理;
5)、重新整理完成后,丢弃每个集合末尾非频繁的项。

2、步骤2
6)、读取每个集合插入FP树中,同时用一个头部链表数据结构维护不同集合的相同项。

接下来,我们就得到下面这样一棵FP树。

这样,我们从FP树中挖掘出频繁项集。
3、步骤3
1)、对头部链表进行降序排序;
2)、对头部链表节点从小到大遍历,得到条件模式基,同时获得一个频繁项集。
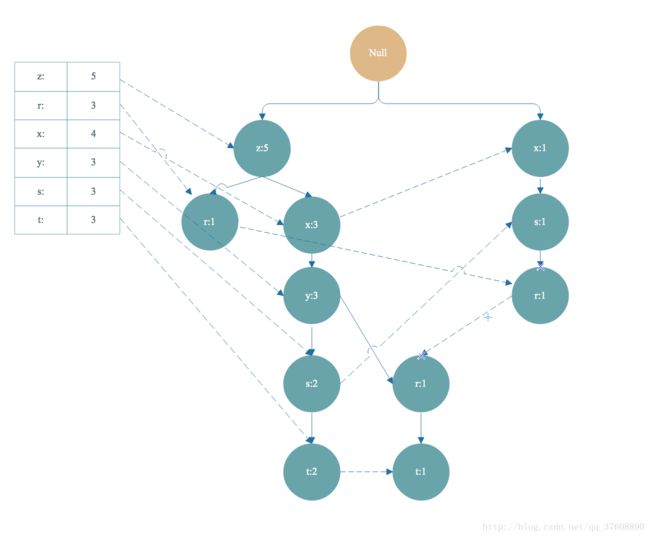
如上图,从头部链表 t 节点开始遍历,t 节点加入到频繁项集。找到以 t 节点为结尾的路径如下

我们把FP树中的t节点去掉,就得到条件模式基<左边路径,左边是值>[z,x,y,s,t]:2,[z,x,y,r,t]:1 。条件模式基的值取决于末尾节点 t ,因为 t 的出现次数最小,一个频繁项集的支持度由支持度最小的项决定。所以 t 节点的条件模式基的值可以理解为对于以 t 节点为末尾的前缀路径出现次数。
3)、条件模式基继续构造条件 FP树, 得到频繁项集,和之前的频繁项组合起来,这是一个递归遍历头部链表生成FP树的过程,递归截止条件是生成的FP树的头部链表为空。根据步骤 2 得到的条件模式基 [z,x,y,s,t]:2,[z,x,y,r,t]:1 作为数据集继续构造出一棵FP树,计算支持度,去除非频繁项,集合按照支持度降序排序,重复上面构造FP树的步骤。最后得到下面 t-条件FP树:

接下来,我们根据 t-条件FP树的头部链表进行遍历,从 y 开始。得到频繁项集 ty 。接着又得到 y 的条件模式基,构造出 ty的条件FP树,即 ty-条件FP树。继续遍历ty-条件FP树的头部链表,得到频繁项集 tyx,紧接着又得到频繁项集 tyxz. 然后得到构造tyxz-条件FP树的头部链表是空的,终止遍历。这时,我们得到的频繁项集有 t->ty->tyz->tyzx,这只是一小部分。
三、实现过程
1、构建FP树
在第二次扫描数据集时会构建一棵树。为构建一棵树,需要一个容器来保存树。
1.1 创建FP树的数据结构
FP树的类定义如下
class treeNode:
#name存放节点名称
#count存放计数值
#nodeLink链接相似元素
#parent存放父节点
#children存放子节点
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
self.count += numOccur
def disp(self, ind=1):
print(' '*ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind+1)输入
rootNode = treeNode('pyramid' , 9 , None)
rootNode.children['eye'] = treeNode('eye',13, None)
rootNode.disp()输出
pyramid 9
eye 13输入
rootNode.children['phoenix'] = treeNode('phoenix',3, None)
rootNode.disp()输出
pyramid 9
eye 13
phoenix 3
1.2 构建FP树
除了图12-1给出的FP树之外,还需要一个头指针表来指向给定类型的第一个实例。利用头指针表 ,可以快速访问FP树中一个给定类型的所有元素。图12-2给出了一个头指针表的示意图。

这里使用一个字典作为数据结构,来保存头指针表。除了存放指针外,头指针表还可以用来保存FP树中每类元素的总数。
第一次遍历数据集会获得每个元素项的出现频率。接下来,去掉不满足最小支持度的元素项。再下一步构建FP树。在构建时,读人每个项集并将其添加到一条已经存在的路径中。如果该路径不存在,则创建一条新路径。每个事务就是一个无序集合。假设有集合{z,x,y}和{y,z,r},那么在FP树中,相同项会只表示一次。为了解决此问题,在将集合添加到树之前,需要对每个集合进行排序。排序基于元素项的绝对出现频率来进行。使用图12-2中的头指针节点值,对表12-2中数据进行过滤、重排序后的数据显示在表12-2中。

在对事务记录过滤和排序之后,就可以构建FP树了。从空集(符号为∅\emptyset)开始,向其中不断添加频繁项集。过滤、排序后的事务依次添加到树中,如果树中巳存在现有元素,则增加现有元素的值;如果现有元素不存在,则向树添加一个分枝。对表12-2前两条事务进行添加的过程显示在图12-3中。

FP构建函数如下:
#create FP-tree from dataset but don't mine
def createTree(dataSet, minSup=1):
headerTable = {}
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
headerTable = {k:v for k,v in headerTable.items() if v >= minSup}
freqItemSet = set(headerTable.keys())
if len(freqItemSet) == 0: return None, None #if no items meet min support -->get out
for k in headerTable:
headerTable[k] = [headerTable[k], None] #reformat headerTable to use Node link
retTree = treeNode('Null Set', 1, None)
for tranSet, count in dataSet.items():
localD = {}
for item in tranSet: #put transaction items in order
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)]
updateTree(orderedItems, retTree, headerTable, count)
return retTree, headerTable #return tree and header table
def updateTree(items, inTree, headerTable, count):
#如果items[0]项在树中,那么增加树种对应节点计数值
if items[0] in inTree.children:#check if orderedItems[0] in retTree.children
inTree.children[items[0]].inc(count) #incrament count
else:
inTree.children[items[0]] = treeNode(items[0], count, inTree)
if headerTable[items[0]][1] == None: #update header table
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1:#call updateTree() with remaining ordered items
updateTree(items[1::], inTree.children[items[0]], headerTable, count)
#this version does not use recursion
def updateHeader(nodeToTest, targetNode):
while (nodeToTest.nodeLink != None):
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode输入
d = {'a':2,'c':1,'b':3}
sorted(d.items(),key=lambda p:p[1], reverse=True)输出
[('b', 3), ('a', 2), ('c', 1)]输入
[v[0] for v in sorted(d.items(),\
key=lambda p:p[1],reverse=True)]输出
['b', 'a', 'c']简单数据集及数据包装器如下
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
retDict[frozenset(trans)] = 1
return retDict输入
simpDat = loadSimpDat()
simpDat输出
[['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]输入
initSet = createInitSet(simpDat)
initSet输出
{frozenset({'z'}): 1,
frozenset({'h', 'j', 'p', 'r', 'z'}): 1,
frozenset({'s', 't', 'u', 'v', 'w', 'x', 'y', 'z'}): 1,
frozenset({'n', 'o', 'r', 's', 'x'}): 1,
frozenset({'p', 'q', 'r', 't', 'x', 'y', 'z'}): 1,
frozenset({'e', 'm', 'q', 's', 't', 'x', 'y', 'z'}): 1}输入
myFPTree,myHeaderTab = createTree(iniSet,3)
myFPTree.disp()输出
Null Set 1
z 5
r 1
x 3
s 2
y 2
t 2
r 1
y 1
t 1
x 1
s 1
r 12、 从一棵FP树中挖掘频繁项集
我们在有了FP树之后,就可以抽取频繁项集了。当然,这里的思路与Apriori算法大致类似,首先从单元素项集合开始,然后在此基础上逐步构建更大的集合。当然这里将利用FP树来做实现上述过程 ,不再需要原始数据集了。
从FP树中抽取频繁项集的三个基本步骤,详见下方:
1)从FP树中获得条件模式基;
2)利用条件模式基,构建一个条件FP树;
3)迭代重复步骤(1)步骤(2 ) ,直到树包含一个元素项为止。
接下来重点关注第(1)步,即寻找条件模式基的过程。之后,为每一个条件模式基创建对应的条件FP树。最后需要构造少许代码来封装上述两个函数,并从FP树中获得频繁项集。
2.1 抽取条件模式基
首先从上一节发现的巳经保存在头指针表中的单个频繁元素项开始。对于每一个元素项,获得其对应的条件模式基(conditionalpattembase)。条件模式基是以所查找元素项为结尾的路径集合。每一条路径其实都是一条前辍路径(prefixpath)。简而言之,一条前缀路径是介于所査找元素项与树根节点之间的所有内容。
回到图12-2,符号r的前缀路径是{x,s}、{z,x,y}和{z}。每一条前缀路径都与一个计数值关联。该计数值等于起始元素项的计数值,该计数值给了每条路径上的数目。表12-3列出了上例当中每一个频繁项的所有前缀路径。

为了获得这些前缀的路径,可以对树进行穷举式搜索,直到获得想要的频繁项为止,或者使用一个更有效的方法来加速搜索过程。可以利用先前创建的头指针表来得到一种更有效的方法。头指针表包含相同类型元素链表的起始指针。一旦到达了每一个元素项,就可以上溯这棵树直到根节点为止。
发现以给定元素项结尾的所有路径的函数
#从叶子节点回溯到根节点
def ascendTree(leafNode, prefixPath):
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath)
def findPrefixPath(basePat, treeNode):
condPats = {}
while treeNode != None:
prefixPath = []
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count
treeNode = treeNode.nodeLink
return condPats输入
findPrefixPath('x',myHeaderTab['x'][1])输出
{frozenset({'z'}): 3}输入
findPrefixPath('z',myHeaderTab['z'][1])输出 {}输入
findPrefixPath('r',myHeaderTab['r'][1])输出
{frozenset({'z'}): 1, frozenset({'s', 'x'}): 1, frozenset({'x', 'z'}): 1}2.2 创建条件FP树
对于每一个频繁项,都要创建一棵条件FP树。我们会为z、x以及其他频繁项构建条件树。可以使用刚才发现的条件模式基作为输入数据,并通过相同的建树代码来构建这些树。然后,我们会递归地发现频繁项、发现条件模式基,以及发现另外的条件树。举个例子来说,假定为频繁项测建一个条件FP树,然后对{t,y}、{t,x}、…重复该过程。元素项t的条件FP树的构建过程如图12-4所示。

在图12-4中,注意到元素项s以及r是条件模式基的一部分,但是它们并不属于条件FP树。原因是什么?如果讨论s以及r的话,它们难道不是频繁项吗?实际上单独来看它们都是频繁项,但是在t的条件树中,它们却不是频繁的,也就是说,{t,r}及{t,s}是不频繁的。
接下来,对集{t,z}、{t,x}以及{t,y}来挖掘对应的条件树。这会产生更复杂的频繁项集。该过程重复进行,直到条件树中没有元素为止,然后就可以停止了。实现代码相对比较直观,使用一些递归加上之前写的代码就可以完成。
递归查找频繁项集的mineTree的函数,代码如下:
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
#这一行与书中不一样在于p[1][0],通过headerTable中项对应的个数来排序
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1][0])]
for basePat in bigL:
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
freqItemList.append(newFreqSet)
condPattBases = findPrefixPath(basePat, headerTable[basePat][1])
myCondTree, myHead = createTree(condPattBases, minSup)
if myHead != None: #3. mine cond. FP-tree
print('conditional tree for: ',newFreqSet)
myCondTree.disp(1)
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)输入
freqItems = []
mineTree(myFPTree,myHeaderTab,3,set([]),freqItems)输出
freqItems输入
len(freqItems)输出 18
四、小结
FP-groth算法是一种用于发现数据集中频繁模式的有效方法。FP-growth利用Apriori原则,执行速度较Apriori算法更快。Apriori算法产生候选项集,然后扫描数据集检查它们是否频繁。而FP-groth算法只扫描数据集两次,这也是它执行速度更快的原因所在。在FP-groth算法中,数据集存储在一个称为FP树的结构中。FP树构建完成后,可以通过查找元素项的条件基及构建条件FP树来发现频繁项集。该过程不断以更多元素作为条件重复进行,直到FP树只包含一个元素为止。
以利用FP-growth算法在多种文本文档中查找频繁单词。频繁项集还有其他一些应用,例如购物交易、医院诊断即大气研究等。