百亿数据入库elasticsearch生产实践(二)
一、前言
之所以有本文,可翻阅下我的上一篇文章《百亿数据入库mongodb生产实践》。
前情回顾,hive中有三个具有关联关系的表,依次是一对多的关系,当前历史数据总量在500亿左右,每日增量依次是百万、千万、亿级的体量。其中,这500亿数据只是一个领域,还有另一个块更大领域的数据第三层日增量在10~25亿之间,这块还没来得及去啃。这一块数据,需要对多个业务部门提供数据服务,主要是数据聚合处理和历史明细查询。明细查询这一块由于查询条件、范围的不确定性,需要构建一个层级的全量表提供快速检索查询。在mongo的实践中,我们的瓶颈主要是海量数据高频次的update操作,导致mongodb承受不了这个压力。这次我们改用elasticsearch。yes, for search!
二、elasticsearch初遇
2.1 在了解elasticsearch之前,我们需要先了解下下面几点概念。
全文检索:一种将文件中所有文本与检索项匹配的检索方法。它可以根据需要获得全文中有关章、节、段、句、词等信息。计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程。经过几年的发展,全文检索从最初的字符串匹配程序已经演进到能对超大文本、语音、图像、活动影像等非结构化数据进行综合管理的大型软件。
全文检索与数据库like查询的区别:数据查询通常的做法是是通过数据库模糊匹配即Like '%keyword%'的方式,这种方式是对全表进行顺序扫描,适合应用在数据量较小的结构化数据上。如果数据量很大,则查询效率将非常耗时。而全文检索主要就是面向海量数据的查询,并且数据源不限于结构化的数据,对于非结构化的数据依然很有效。
lucene:最初是由Doug cutting,没错,就是那个开发出hadoop的人。lucene是apache下的一个开源全文检索引擎工具包,提供了完整的查询引擎和索引引擎。它提供了文档索引、查询和存储等多种api,可供开发人员整合到wen项目、搜索引擎等多种应用场景中。
lucene主要包结构:
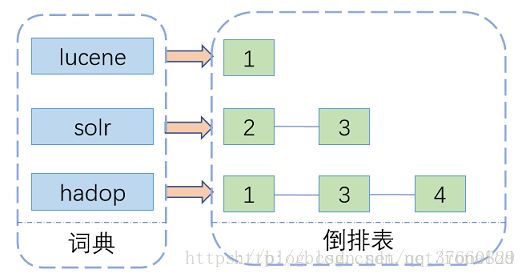
lucene索引的原理:基于倒排索引来实现,主要包含两部分--词典和倒排表。
假如现在有一篇文章,一般我们可能会考虑这篇文章里头包含了哪些词哪些关键字。而倒排索引则是反着推,有一个关键词,它是在文中哪个位置,出现的次数是多少。然后词(term)的的集合就形成了词典,而记录词的位置和频率的信息就是一个倒排链表。如果我们需要索引一篇文章用于后面的关键词检索,我们需要先对文章进行分词,形成如图左边的单个单词,在倒排表里记录在文中出现的位置,和次数。所有词(term)处理完后,会对词典进行排序去重,相应的记录词频的倒排表也会进行整合得到所有的出现位置和一个总频次。以上是一个简单的理解,想深入理解下lucene的索引原理,可以参考一下这篇关于lucene底层原理的博文。
2.2 elsticsearch
一系列铺垫之后,我们了解了全文检索的概念和lucene索引的原理。那elasticsearch是什么呢?其实主要是基于lucene的一个搜索服务器,是一个分布式的检索引擎,对lucene进行进一步的封装和更能增强。elasticsearch提供了一个对海量数据检索的解决方案,大大降低了使用门槛。
使用elasticsearch首先要先创建一个索引,索引类似于数据库,可以向索引中写入数据和读取数据。一个索引可以包含多种类型,每种类型可以建议不同的文档mapping。es还支持分片处理,用于数据负载均衡和分布式查询。这里的每一个分片其实就是一个lucene索引,如果查询时能带着路由条件查询将精准命中对应分片,减少无关分片的扫描,大大提供查询效率和减少查询性能消耗。更多关于索引、类型、映射、分片、副本等详细信息描述更参考这篇博文。
2.3 elsticsearch使用
2.3.1 安装
参考官方文档进行安装:https://www.elastic.co/guide/en/elasticsearch/reference/5.4/gs-installation.html
我这里选择的是5.3.0版的tar包方式安装,使用默认配置启动单节点,正常启动如下:
安装并启动kibana用于界面化操作,配置参数主要更改监听elasticsearch的http服务端口:
启动后可选择 dev tools选项,在console进行dsl操作。
elasticsearch提供的操作api很丰富,常用的主要有操作文档的document api、查询 api、操作索引的api、查询常规配置和信息的api和集群状态管理的api。
es基本操作可参考以上几个api去练手。
三、进入主题--实践环节
3.1 数据模型构建
按照构建层级结构文档的指导思想,我首先研究在es中如何去实现这个数据模型。这里,可以推荐一个博主,他写的文章在初期给了我不少指引。es作为一个nosql类型的数据库,本身对关系的处理是比较弱的,后文的实践也有所体现。但是事实数据肯定存在各种关系,关系数据描述中无非是一对一、一对多、多对多,而多对多又能转化成一对多。由于es对json的完美支持,所以可以将数据间的关系以保准json表现出来,无论嵌套多少层,都能存到es里。es中处理这种数据有三种方式:
3.1.1 使用object和array[object]进行存储
这种模式其实使用的就是es的默认的mapping,底层自动做类型映射。这种方式处理起来方便,但是要先将数据的关系用json组织好再写入。并且数据查询的时候也有限制,数据检索时,是整个文档返回,如果文档嵌套太深或者子文档太多而想获取的只是某部分则占用了无益的io。
插入数据:
{
"name" : "Zach",
"car" : [
{
"make" : "Saturn",
"model" : "SL"
},
{
"make" : "Subaru",
"model" : "Imprezza"
}
]
}底层存储结构:
{
"name" : "Zach",
"car.make" : ["Saturn", "Subaru"]
"car.model" : ["SL", "Imprezza"]
}es的底层lucene是多值域存储,所以上面看起来像数组结构。检索数据时,无法获取单个的内层文档信息,“Saturn”与“SL”已经没有关系了。
3.1.2 使用nested[object]类型
要使上述每个汽车的信息作为一个整体,可以将car映射成nested类型
PUT /my_index
{
"mappings": {
"user": {
"properties": { "car": {
"type": "nested",
"properties": {
"make": { "type": "string" },
"model": { "type": "string" }
}
}
}
}
}
}nested类型在查询的时候可以单独对子文档进行查询,并且查询效率也很好,因为嵌套文档与上一级文档在同一分片上,查询时能同一路由进行定位。但是有一个很大的缺点,在子文档更新时需要对整个结构体进行重索引。嵌套文档数量越大,成本越高。同时,返回的文档也是整个文档,不能返回指定文档。
3.1.3 parent-child --父子关系文档
父子关系文档,除了最顶层的文档外,下一级的文档都要指定它的"_parent"属性定位它的父级文档,第二级的路由默认为"_parent",第三级以后还要指定"_routing"以确定路由到哪个分片上存储。es管理这种关系,会在每个shard的内存中维护一个关系表,检索时,通过过滤器has_parent和has_child获取关联数据。这种模式下,子父文档是压平存储的,彼此相互独立,可自由更新子文档。检索时能获取对应的子文档,但是查询效率会比nested低。
结合数据应用场景和数据体量情况,选择parent-child 方式能满足要求。
数据模型相关内容清参考这篇博文,或者官方文档权威指南。
3.2 历史数据入库
3.2.1 mapping构建
PUT /my_index
{
"mappings": {
"r1":{
"_all": {"enabled": false},
"properties": {
"filed1":{
"type":"keyword"
},
"filed2":{
"type":"keyword"
},
"filed3":{
"type":"text"
},
"filed4":{
"type":"text",
"index": false
},
"filed5":{
"type": "date"
}
}
},
"r2":{
"_all": {"enabled": false},
"_parent":{
"type": "r1"
},
"_routing": {
"required": true
},
"properties": {
"filed1":{
"type":"keyword"
},
"filed2":{
"type":"keyword"
},
"filed3":{
"type":"text"
},
"filed4":{
"type":"text",
"index": false
},
"filed5":{
"type": "date"
}
}
},"r3":{
"_all": {"enabled": false},
"_parent":{
"type": "r2"
},
"_routing": {
"required": true
},
"properties": {
"filed1":{
"type":"keyword"
},
"filed2":{
"type":"keyword"
},
"filed3":{
"type":"text"
},
"filed4":{
"type":"text",
"index": false
},
"filed5":{
"type": "date"
}
}
}
},
"settings": {
"number_of_shards": 5,
"number_of_replicas": 0,
"refresh_interval": -1
}
} 3.2.2 基于数据体量,利用spark进行快速入库es进行索引。
package com.huawei.datalake.elasticsearch
import java.net.InetAddress
import java.sql.Timestamp
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.elasticsearch.client.transport.TransportClient
import org.elasticsearch.common.settings.Settings
import org.elasticsearch.common.transport.InetSocketTransportAddress
import org.elasticsearch.transport.client.PreBuiltTransportClient
import org.elasticsearch.common.xcontent.XContentFactory._
/**
* Created by zhang on 2018/7/5.
*/
object EsTest {
/* bulkwrite每次提交1024,单个EXECUTOR */
private val DefaultMaxBatchSize: Int = 1024
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("integration_to_es").setMaster(args(0))
val sc = new SparkContext(conf)
/**
* 数据源模拟
*/
val r1 = R("123", "grandfather", "info1", "info1", new Timestamp(System.currentTimeMillis()), "r1")
val r2 = R("123456", "father", "123", "info2", new Timestamp(System.currentTimeMillis()), "r2")
val r3 = R("123456789", "child", "123456", "123", new Timestamp(System.currentTimeMillis()), "r3")
val rdd = sc.parallelize(Seq(r1, r2, r3))
save(rdd)
sc.stop()
}
//通过SPARK并行批量进行索引
def save(rdd: RDD[R]) = {
rdd.foreachPartition(partition=>{
val client = getClient()
partition.grouped(DefaultMaxBatchSize).foreach(batch=>{
val bulkRequest = client.prepareBulk()
batch.foreach(row=>{
try{
val xContentContext = jsonBuilder.startObject()
.field("filed1", row.filed1)
.field("filed2", row.filed2)
.field("filed3", row.filed3)
.field("filed4", row.filed4)
.field("filed5", row.filed5)
.endObject()
val style = row.style
style match {
case "r1" => bulkRequest.add(client.prepareIndex("my_index", "r1", row.filed1).setSource(xContentContext))
case "r2" => bulkRequest.add(client.prepareIndex("my_index", "r2", row.filed1).setParent(row.filed3).setSource(xContentContext))
case "r3" => bulkRequest.add(client.prepareIndex("my_index", "r3", row.filed1).setParent(row.filed3).setRouting(row.filed4).setSource(xContentContext))
case _ =>
}
}catch{
case e: Exception =>{
throw new Exception(e.getMessage)
}
}
})
val response = bulkRequest.execute().actionGet()
if(response.hasFailures){
println("=============="+response.buildFailureMessage())
}
})
if (client!=null) client.close()
})
}
//获取客户端
def getClient(): TransportClient = {
val settings = Settings.builder()
.put("transport.type", "netty3")//解决与SPARK中的netty版本不一致的问题
.put("http.type", "netty3").build()
// .put("cluster.name", "myClusterName")//集群模式需要添加此参数
val client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("localhost"), 9300))
// .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("host2"), 9300))
client
}
case class R(filed1: String, filed2: String, filed3: String, filed4: String, filed5: Timestamp, style: String)
}
在这里遇到的问题主要是不同版本的依赖冲突问题,我这里是由于spark1.6.1引用的netty版本与es的不一致,导致出错。可参考代码里的参数设置,将es引用的netty也改为netty3。
导入完成后,在kibana中通过search api: GET my_index/_search查询数据。(由于前面把refresh关闭里,要先_flush才能看到数据)。
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "my_index",
"_type": "r1",
"_id": "123",
"_score": 1,
"_source": {
"filed1": "123",
"filed2": "grandfather",
"filed3": "info1",
"filed4": "info1",
"filed5": "2018-07-07T02:14:15.901Z"
}
},
{
"_index": "my_index",
"_type": "r2",
"_id": "123456",
"_score": 1,
"_routing": "123",
"_parent": "123",
"_source": {
"filed1": "123456",
"filed2": "father",
"filed3": "123",
"filed4": "info2",
"filed5": "2018-07-07T02:14:15.901Z"
}
},
{
"_index": "my_index",
"_type": "r3",
"_id": "123456789",
"_score": 1,
"_routing": "123",
"_parent": "123456",
"_source": {
"filed1": "123456789",
"filed2": "child",
"filed3": "123456",
"filed4": "123",
"filed5": "2018-07-07T02:14:15.901Z"
}
}
]
}
}查询出的数据是压平存储的,父子关系通过_parent值进行连接。
3.3 父子关系关联查询
在实际查询场景中,每一层可能都有查询条件。同时,对于每层返回的字段也有要求。
GET my_index/r1/_search
{
"_source": {
"includes": ["filed1","filed2","filed5"]
},
"query": {
"bool": {
"must": [
{"match": {
"filed1": "123"
}},
{
"has_child": {
"type": "r2",
"query": {
"bool": {
"must": [
{"match": {
"filed2": "father"
}},
{"has_child": {
"type": "r3",
"query": {
"bool": {
"must": [
{"range": {
"filed5": {
"gte": "2018-07-07T01:14:15.901Z",
"lte": "2018-07-07T03:14:15.901Z"
}
}}
]
}
},
"inner_hits":{
"_source":{
"includes":["filed1","filed2","filed3","filed4","filed5"]
}
}
}}
]
}
},
"inner_hits":{
"_source":{
"includes":["filed1","filed2","filed3","filed5"]
}
}
}
}
]
}
}
}result:
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.9808292,
"hits": [
{
"_index": "my_index",
"_type": "r1",
"_id": "123",
"_score": 1.9808292,
"_source": {
"filed1": "123",
"filed2": "grandfather",
"filed5": "2018-07-07T02:14:15.901Z"
},
"inner_hits": {
"r2": {
"hits": {
"total": 1,
"max_score": 1.9808292,
"hits": [
{
"_type": "r2",
"_id": "123456",
"_score": 1.9808292,
"_routing": "123",
"_parent": "123",
"_source": {
"filed1": "123456",
"filed2": "father",
"filed3": "123",
"filed5": "2018-07-07T02:14:15.901Z"
},
"inner_hits": {
"r3": {
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_type": "r3",
"_id": "123456789",
"_score": 1,
"_routing": "123",
"_parent": "123456",
"_source": {
"filed1": "123456789",
"filed2": "child",
"filed3": "123456",
"filed4": "123",
"filed5": "2018-07-07T02:14:15.901Z"
}
}
]
}
}
}
}
]
}
}
}
}
]
}
}这里对子文档的获取主要用了"inner_hits",可以对has_child中的子文档的字段取出来。
关联查询在数据量少的时候问题不是很大,但是随着数据量的增长,达到百亿级,查询直接无响应。多代文档的联合查询(查看 祖辈与孙辈关系)虽然看起来很吸引人 ,但必须考虑如下的代价:
- 联合越多,性能越差。
- 每一代的父文档都要将其字符串类型的
_id字段存储在内存中,这会占用大量内存。
当你考虑父子关系是否适合你现有关系模型时,请考虑下面这些建议 :
- 尽量少地使用父子关系,仅在子文档远多于父文档时使用。
- 避免在一个查询中使用多个父子联合语句。
- 在 has_child 查询中使用 filter 上下文,或者设置 score_mode 为 none 来避免计算文档得分。
- 保证父 IDs 尽量短,以便在 doc values 中更好地压缩,被临时载入时占用更少的内存。
3.4 优化
3.4.1 索引优化
驴之所以倔,是因为它不知变通。
树挪死,人挪活。关联处理不了,我把几个表分开索引了。分开索引,检索时分别查询也能一定程度上满足业务需求,只是单次查询量有上限。这是查询效率与查询量的取舍。分开索引后有两条重要的原则:
(1)shard数建议为集群节点数的1.5到3倍之间
(2)每个分片数据量应在30gb到50gb为宜
按照这个原则,对每个单表数据也需要分索引。这里需要引入index api的另一个功能,索引模版。可以预先建立一个模版,模版可定义索引的通配符和对应mapping和settings。动态创建索引时,如果索引名匹配了该模版定义的索引命名规则,则引用模版预设的参数设置。模版可基于类型和基于时间进行匹配,比较通用的一个例子是:logstash集成日志到es中,可根据"logstash-*"去匹配"logstash-2018-07-07","logstash-2018-07-08","logstash-2018-07-09"等,同时每天新建一个索引。从而把数据分散到多个索引里。在查询时也可通过规则匹配进行一个类索引进行查询。
index template:
PUT _template/template_1
{
"template": "logstash*",
"settings": {
"number_of_shards": 1
},
"mappings": {
"type1": {
"_source": {
"enabled": false
},
"properties": {
"host_name": {
"type": "keyword"
},
"created_at": {
"type": "date",
"format": "EEE MMM dd HH:mm:ss Z YYYY"
}
}
}
}
}3.4.2 查询优化
要使查询效率提升,应尽量保证多的副本和少的分片。这一点与数据索引是相反的,所以要均衡处理。前文中提到历史数据初始化时把副本和refresh都关闭了,在数据入库完毕后可以恢复需要值,以保证数据查询效率。数据分片数要结合数据大小和分索引情况一起考虑,按照分索引的两个原则去处理。此外,这也不是完全贴合实际情况的一个最佳配置,需要在业务使用场景中一段时间应用才能确定最佳值,跟机器性能关系比较大。
我在实践之处没有做分索引处理,直接把单分片index到了lucene的最大值:2^31,大概是21亿多个,这是lucene的上限。到达上限的lucene索引无法进行查询,该分片处于unassigned状态,但是其他分片也接近最大值,检索效率依然很好。这可能是因为是新机器,并且没有其他业务线在使用。
常规优化:
1. segment合并,可通过相关参数配置segment合并频率,基于段大小和每次合并个数。
2. 线程池配置,包括merge线程池,search线程池,index线程池,线程池作用主要是提高响应操作的并发量。比如默认的merge只有一个线程,合并segment的时候会比较慢一些,增加线程数可加快合并速率。
3. _forcemerge api 设置 max_num_segments为1进行强制合并,这个针对历史数据更更新情况
4. 用过滤器对query进行替换使用,query与filter的区别可以参考这里。简而言之,可以归结为query需要计算匹配相似得分,而filter是精确匹配,不计算得分并且对经常查询的过滤器会有缓存,查询更快。
5. 带路由条件查询,我的2,3表的数据中有上级的主外建信息,可以将与上一级的关联id作为_routing。查询时带路由查询直接定位分片位置,从而减少无关分片查询。
四、总结
万事开头难,回忆却也平淡。
由于个人对架构的认知和多样的功能框架的了解还很少,所以生产实践中还是免不了踩很多坑。必须认识到的一点,走过一段沼泽后,前面不一定就是美丽新世界,可能是--悬崖!接触新事物的时候,充满陌生、惊奇,在摸索中遇到问题有时也苦恼,在榨干脑汁找出解决方法时会莫名的愉悦。不管过程怎么样,在得到结果后再去回忆,并没有感觉有什么值得兴奋的东西,这大概就是成长吧。
批量理解,持续学习!