近年热门分类CNN网络结构的总结
总结的网络结构有:LeNet、AlexNet、ZF-Net、VGG、谷歌系列 :Inception v1到v4、Resnet、ResnetXt、SeNet、DenseNet、DPN。
LeNet
创新点:定义了CNN的基本组件,是CNN的鼻祖。
LeNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务。自那时起,CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。
网络结构:
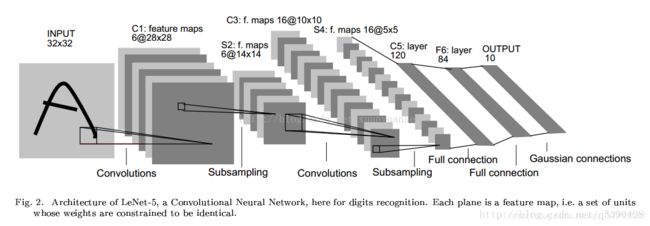

LaNet-5的局限性
CNN能够得出原始图像的有效表征,这使得CNN能够直接从原始像素中,经过极少的预处理,识别视觉上面的规律。然而,由于当时缺乏大规模训练数据,计算机的计算能力也跟不上,LeNet-5 对于复杂问题的处理结果并不理想。
AlexNet
2012年,Imagenet比赛冠军的model,作者是Alex,Hinton的学生
论文链接
参考:
在AlexNet中LRN 局部响应归一化的理解
tf.nn.conv3d和tf.nn.max_pool3d这两个tensorflow函数的功能和参数
Tensorflow的LRN是怎么做的
1D,2D,3D卷积的区别
3d卷积是如何计算的
创新点:
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化(相邻池化窗口之间会有重叠区域,此时kernel size>stride)。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
网络结构:
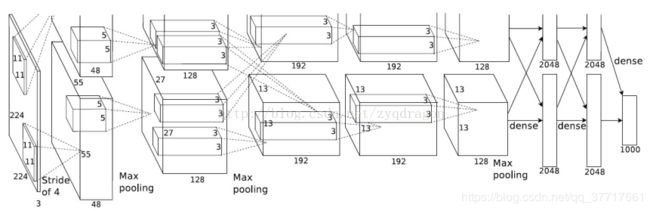
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。说实话,这个model的意义比后面那些model都大很多,首先它证明了CNN在复杂模型下的有效性,然后GPU实现使得训练在可接受的时间范围内得到结果,确实让CNN和GPU都大火了一把,顺便推动了有监督DL的发展。
关于为什么使用max pooling的理解:
池化的两种常见误差归纳如下:
(1)邻域大小受限造成的估计值方差增大;(2)卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息;max-pooling能减小第二种误差,更多的保留纹理信息。
边缘检测,就是因为边缘信息跟背景信息差别大,所以才能检测。max-pooling就是保留了最明显的信息。mean-pooling因为平均考虑,所以背景信息也保留了,所以肯定会丢失信息。
使用实验证明:
- 重叠池化:其他的设置都不变的情况下, top-1和top-5 的错误率分别减少了0.4% 和0.3%。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
LRN全称是local response normalization,局部响应归一化。
LRN的动机是 对于图像中的每个位置来说,我们可能并不需要太多的高激活神经元。但是后来,很多研究者发现 LRN 起不到太大作用,因为并不重要,而且我们现在并不用 LRN 来训练网络。
与BN的区别:
BN归一化主要发生在不同的样本之间,LRN归一化主要发生在不同的卷积核的输出之间。

公式:

其次,官方API的介绍是这样的:
sqr_sum[a, b, c, d] = sum(input[a,b, c, d - depth_radius : d + depth_radius + 1] ** 2)
output = input / (bias +alpha * sqr_sum) ** beta
以alexnet的论文为例,输入暂且定为 [batch_size, 224, 224, 96],这里224×224是图片的大小,经过第一次卷积再经过ReLU,就是LRN函数的输入。
注意上面API说明里的sum函数,意思就是,可能解释起来比较拗口,针对batch里每一个图的后3维向量,[224, 224, d - depth_radius : d + depth_radius + 1],对它按照半径 depth_radius求每个图里的每个像素的平方,再把这2× depth_radius+1个平方过后的图片加起来,就得到了这个batch的sqr_sum。
LRN的Pytorch代码:
class LRN(nn.Module):
'''
这个网络貌似后续被其它正则化手段代替,如dropout、batch normalization等。
目前该网络基本上很少使用了,这里为了原生的AlexNet而实现
'''
def __init__(self, local_size=1, alpha=1.0, beta=0.75, ACROSS_CHANNELS=False):
super(LRN, self).__init__()
self.ACROSS_CHANNELS = ACROSS_CHANNELS
if self.ACROSS_CHANNELS:
self.average=nn.AvgPool3d(kernel_size=(local_size, 1, 1), #0.2.0_4会报错,需要在最新的分支上AvgPool3d才有padding参数
stride=1,
padding=(int((local_size-1.0)/2), 0, 0))
else:
self.average=nn.AvgPool2d(kernel_size=local_size,
stride=1,
padding=int((local_size-1.0)/2))
self.alpha = alpha
self.beta = beta
def forward(self, x):
if self.ACROSS_CHANNELS:
div = x.pow(2).unsqueeze(1)
div = self.average(div).squeeze(1)
div = div.mul(self.alpha).add(1.0).pow(self.beta)#这里的1.0即为bias
else:
div = x.pow(2)
div = self.average(div)
div = div.mul(self.alpha).add(1.0).pow(self.beta)
x = x.div(div)
return x
我对公式的理解:x、y指的是固定的同一层同一位置width和height的值,i指的是第i层,公式只对第四维channal操作,depth_radius是可选的特征图范围,也就是对同一层同一位置不同的特征图的信息做累加操作。
代码中ACROSS_CHANNELS是否跨通道,使用3d的池化,也就是在第二维多了一个depth维度,3d一般用来处理视频,考虑时间维度的信息,多出来的维度是帧数。
ZF-Net
2013 ImageNet分类任务的冠军,其网络结构较AlexNet没什么改进,只是调了调参,性能较AlexNet提升了不少。
ZF-Net只是将AlexNet第一层卷积核由11变成7,步长由4变为2,第3,4,5卷积层转变为384,384,256。
创新点:
使用了更小的卷积核
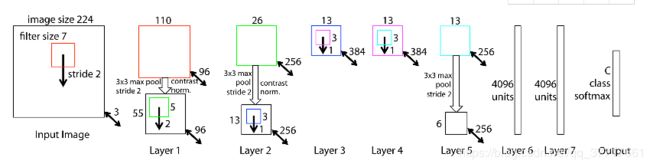
VGG
论文链接
参考博客:VGG模型核心拆解 、VGGNet网络结构
牛津大学计算机视觉组和DeepMind公司共同研发一种深度卷积网络,在ImageNet 2014年比赛上获得了分类项目的第二名,GoogleNet是第一名。
创新点:
-
全部使用更小的3*3卷积核,探索以堆叠小尺寸卷积核的方式来替代大尺寸卷积核,加深网络。 -
预训练(pre-trained)技巧。训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。 -
采用了
Multi-Scale的方法来针对训练和预测做数据增强。
VGGNet使用了Multi-Scale的方法做数据增强,将原始图像缩放到不同尺寸S,然后再随机裁切,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。实践中,作者令S在[256,512]这个区间内取值,使用Multi-Scale获得多个版本的数据,并将多个版本的数据合在一起进行训练。
- 实验证明了
LRN层无性能增益(A和A-LRN)。LRN是一种跨通道去normalize像素值的方法。
为什么使用3 * 3卷积来代替7 * 7或5 * 5卷积?
- 非线性操作更多,学习特征的能力更强。因为如果使用的都是线性操作,相当于整个网络都在做同样的事情,至是单纯地把参数加倍,加多少层都是一样的效果。非线性函数可以更好的拟合复杂的函数。
- 参数量更少。
感受野的计算:
假设输入i*i
3*3卷积:
第一次 (i-3)/1+1 = i-2
第二次 (i-2-3)/1+1 = i-4
第三次 (i-4-3)/1+1 = i-6
5*5卷积: (i-5)/1+1 = i-4
7*7卷积: (i-7)/1+1 = i-6
可以看出:两个 3 * 3 卷积层的串联相当于1个 5 * 5 的卷积层,3个 3 * 3 的卷积层串联相当于1个 7 * 7 的卷积层,即3个 3 * 3 卷积层的感受野大小相当于1个 7 * 7 的卷积层。
参数的计算 :
对于3个3*3卷积,(C * C * 3 * 3) *3= 27C^2
对于1个7*7卷积,(C * C * 7 * 7) = 49C^2
∴ 3个3*3卷积的参数量小于1个7*7卷积
对于2个3*3卷积,(C * C * 3 * 3) *2= 18C^2
对于1个5*5卷积,(C * C * 5 * 5) = 25C^2
∴ 2个3*3卷积的参数量小于1个5*5卷积
网络结构

谷歌系列 :Inception v1到v4
Paper列表:
[v1] Going Deeper with Convolutions, 6.67% test error, 2014
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, 2015
[v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error,2015
[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error,2016
大体思路:引用自博客
- Inception v1的网络,将1x1,3x3,5x5的conv和3x3的pooling,stack在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性;
- v2的网络在v1的基础上,进行了改进,一方面了加入了BN层,减少了Internal - Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了参数数量,也加速计算;
- v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块;
- v4研究了Inception模块结合Residual Connection能不能有改进,发现ResNet的结构可以极大地加速训练,同时性能也有提升,主要目的是提升速度;同时将卷积层堆叠顺序(1x1,3x3)变成 (3x3, 1x1)。
GoogLeNet(即Inception V1)
之所以是GoogLeNet而非GoogleNet,文章说是为了向早期的LeNet致敬。
论文链接
GoogLeNet系列解读
GoogleNet系列论文学习
在ImageNet2014和VGG竞争的第一名,这两个网络的大体思路都是一致的:go deeper。不同的是GoogleNet提出了Inception结构,往宽度探索,ImageNet主要还是在AlexNet结构上探索。
创新点:
- 引入
Inception结构 - 中间层的辅助LOSS单元
- 后面的全连接层全部替换为简单的
全局平均池化(GAP)
网络结构
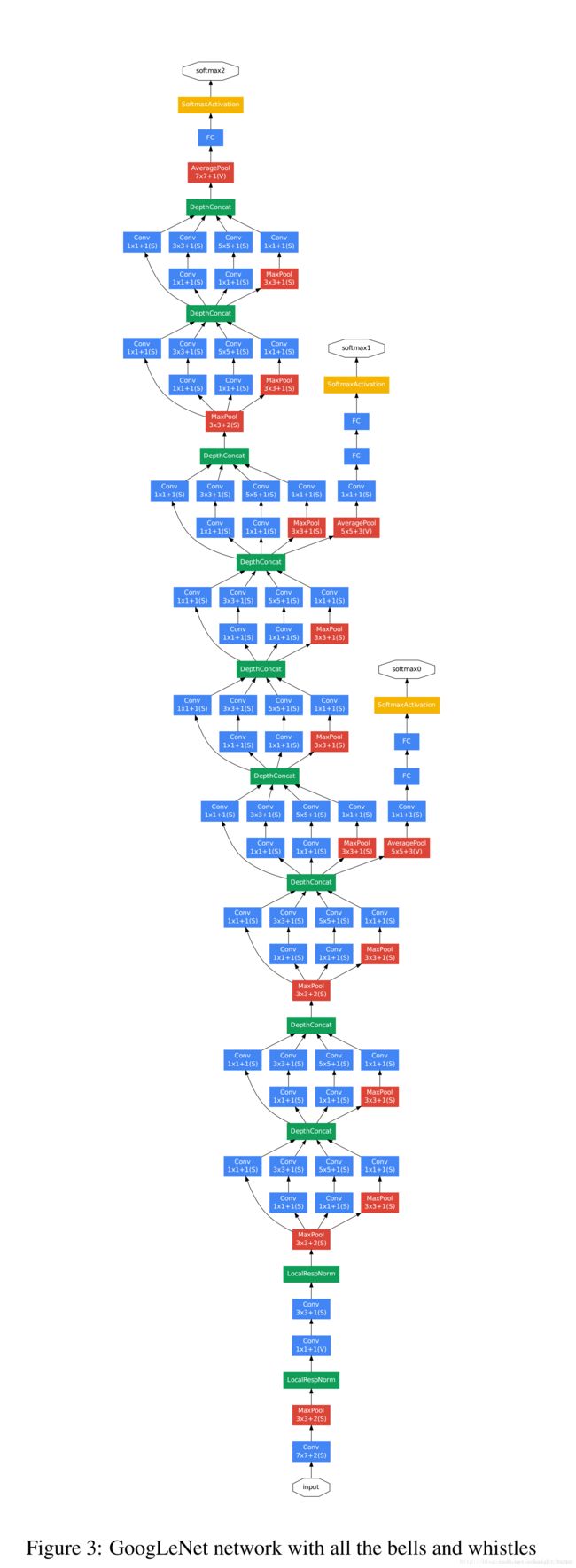
Inception结构

对上图做以下说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了;
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
改进版本:使用1 * 1卷积降维

全连接层一般是用来做分类,后接softmax等激活函数来输出分类的概率。
全局平均池化(GAP)来替代全连接层,原因是:对每个通道的feature map降维,尺寸降为1 * 1,既能实现全连接层的功能,又能避免全连接层的参数量过大、过拟合的问题。
Global Average Pooling全局平均池化的一点理解、关于 global average pooling
BN-GoogLeNet(即BN-Inception、Inception V2)
参考博客:
1.《Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift》阅读笔记与实现
2.从白化到BN、计算过程、求导过程
改进:
- 使用BN层,这样做的好处是:
① 允许使用更高的学习速率并且不太关心初始化,加快训练速度。如果每层的scale不一致,实际上每层需要的学习率是不一样的,同一层不同维度的scale往往也需要不同大小的学习率,通常需要使用最小的那个学习率才能保证损失函数有效下降,Batch Normalization将每层、每维的scale保持一致,那么我们就可以直接使用较高的学习率进行优化。
② 训练深度神经网络的复杂性在于,每层输入的分布在训练过程中会发生变化,因为前面的层的参数会发生变化。BN使每一层的输出都规范化到一个N(0, 1)的高斯,减轻了Internal Covariate Shift。 - 使用两个3 * 3卷积模块代替一个5 * 5(学习VGG),降低参数数量,加速计算。
- 移除或使用较低的dropout。 dropout是常用的防止overfitting的方法,而导致overfit的位置往往在数据边界处,如果初始化权重就已经落在数据内部,overfit现象就可以得到一定的缓解。论文中最后的模型分别使用10%、5%和0%的dropout训练模型,与之前的40%-50%相比,可以大大提高训练速度。
- 降低L2权重衰减系数。 还是一样的问题,边界处的局部最优往往有几维的权重(斜率)较大,使用L2衰减可以缓解这一问题,现在用了Batch Normalization,就可以把这个值降低了,论文中降低为原来的5倍。
- 取消Local Response Normalization层。 由于使用了一种Normalization,再使用LRN就显得没那么必要了。而且LRN实际上也没那么work。
Inception V3
参考博客
改进:
- 重大改进:使用分解卷积(Factorizing into smaller convolution) ,例如1 * 7、7 * 1 代替 7 * 7Conv,多余的计算能力可以多设1 * 1卷积来加深网络,增强非线性。
- 优化方式选择RMSProp,需要求参数的二阶导。

- label smoothing

new_labels = (1.0 - label_smoothing) * one_hot_labels + label_smoothing / num_classes
在网络实现的时候,令 label_smoothing = 0.1,num_classes = 1000。Label smooth提高了网络精度0.2%。
我对label smoothing理解是这样的,它把原来很突兀的one_hot_labels稍微的平滑了一点,枪打了出头鸟,削了立于鸡群那只鹤的脑袋,分了点身高给鸡们,避免了网络过度学习labels而产生的弊端。
- bn-auxiliary classifier
引入了附加分类器,其目的是从而加快收敛。辅助分类器其实起着着regularizer的作用。当辅助分类器使用了batch-normalized或dropout时,主分类器效果会更好。
1. 输入:3 * 299 * 299
############################## 输入处理 ###############################
# (Basic Conv Model:Conv2d->bn->relu)
######################################################################
2. Basic_Conv_Model: 32 * 149 *149 (k=3,s=2)
3. Basic_Conv Model: 32 * 147 *147 (k=3)
4. Basic_Conv_Model: 64 * 147 *147 (k=3,p=1)
5. max_pool :64 * 73 * 73 (k=3,s=2)
6. Basic_Conv_Model: 80 * 73 * 73 (k=1)
7. Basic_Conv_Model: 192 * 71 * 71 (k=3)
8. max_pool :192 * 35 * 35 (k=3,s=2)
############################## InceptionA ###############################
# branch1: 1 * 1 Conv
# branch2: 1 * 1 Conv -> 5 * 5 Conv (p=2)
# branch3: 1 * 1 Conv -> 3 * 3 Conv (p=1) -> 3 * 3 Conv (p=1)
# branch4: avg_pool(k=3,p=1) -> 1 * 1 Conv
######################################################################
9. 256 * 35 * 35
10. 288 * 35 * 35
11. 288 * 35 * 35
############################## InceptionB ##############################
# branch1: 3 * 3 Conv (s=2)
# branch2: 1 * 1 Conv -> 3 * 3 Conv (p=1) -> 3 * 3 Conv (s=2)
# branch3: max_pool(k=3,s=2)
######################################################################
12. 768 * 17 * 17
############################## InceptionC ##############################
# branch1: 1 * 1 Conv
# branch2: 1 * 1 Conv -> 1 * 7 Conv (p=(0,3)) -> 7 * 1 Conv (p=(3,0))
# branch3: 1 * 1 Conv -> 7 * 1 Conv (p=(3,0)) -> 1 * 7 Conv (p=(0,3))
# -> 7 * 1 Conv (p=(3,0)) -> 1 * 7 Conv (p=(0,3))
# branch4: avg_pool(k=3,p=1) -> 1 * 1 Conv
######################################################################
13. 768 * 17 * 17
14. 768 * 17 * 17
15. 768 * 17 * 17
16. 768 * 17 * 17
############################## InceptionD ##############################
# branch1: 1 * 1 Conv -> 3 * 3 Conv(s=2)
# branch2: 1 * 1 Conv -> 1 * 7 Conv (p=(0,3))->7 * 1 Conv(p=(3,0))
# -> 3 * 3 Conv(s=2)
# branch3: 1 * 1 Conv -> 7 * 1 Conv (p=(3,0)) -> 1 * 7 Conv (p=(0,3))
# -> 7 * 1 Conv (p=(3,0)) -> 1 * 7 Conv (p=(0,3))
# branch4: max_pool(k=3,s=2)
######################################################################
17. 1280 * 8 * 8
############################## InceptionE ##############################
# branch1: 1 * 1 Conv
# 1 * 1 Conv的参数共享
# branch2_1: 1 * 1 Conv -> 1 * 3 Conv (p=(0,3))
# branch2_2: 1 * 1 Conv -> 3 * 1 Conv (p=(3,0))
# 1 * 1 、3 * 3 Conv的参数共享
# branch3_1: 1 * 1 Conv -> 3 * 3 Conv (p=1) -> 1 * 3 Conv (p=(0,3))
# branch3_2: 1 * 1 Conv -> 3 * 3 Conv (p=1) -> 3 * 1 Conv (p=(3,0)) ,
# branch4: avg_pool(k=3,p=1) -> 1 * 1 Conv
######################################################################
18. 2048 * 8 * 8
19. 2048 * 8 * 8
# 输出处理
20. avg pool :2048 * 1 * 1 (k=8)
21. dropout : 2048 * 1 * 1
22. flatten :2048
23. fc: num_class
Inception V4
网络结构图
16年提出,受到15年resnet的启发。
inception v4实际上是把原来的inception v3加上了resnet的方法,从一个节点能够跳过一些节点直接连入之后的一些节点,并且残差也跟着过去一个。
另外就是V4把一个先1 * 1再3 * 3那步换成了先3 * 3再1 * 1.
论文说引入resnet不是用来提高深度,进而提高准确度的,只是用来提高速度的。
Resnet
论文链接
作者何凯明,ImageNet 2015比赛classification任务上获得第一名。
问题引出:
退化问题。随着网络的加深,出现了训练集准确率下降的现象,我们可以确定这不是由于Overfit造成的(过拟合的情况训练集应该准确率很高);所以作者针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能的加深,其中引入了全新的结构。

残差指的是什么?
其中ResNet提出了两种mapping:一种是identity mapping,指的就是图1中”弯弯的曲线”,另一种residual mapping(18、34使用basicblock,50、101、152使用bottleneck),指的就是除了”弯弯的曲线“那部分,所以最后的输出是y=F(x)+shortcut(x),最大的优势就是既能避免梯度消失、梯度爆炸又不增加额外的复杂度。identity mapping顾名思义,就是指本身,也就是公式中的x,而residual mapping指的是“差”,也就是y−x,所以残差指的就是F(x)部分。shortcut是在F(x)和x维度不匹配时使用,使用1 * 1卷积来统一维度。
于是通过VGG19设计出了plain 网络和残差网络,如下图中部和右侧网络。然后利用这两种网络进行实验对比。

论文中讨论了多张shortcut的形式,最后发现a的效果好。
ResnetXt
论文:Aggregated Residual Transformations for Deep Neural Networks Saining
参考博客:ResnetXt算法详解
Resnet的变体,ImageNet 2016的第二名,出自论文“Aggregated Residual Transformations for Deep Neural Networks”,主要是将残差块的中间的 3x3卷积层变成group卷积,同时扩大了3x3卷积的输入输出通道数,使得在与对应的ResNet网络的计算量和参数个数相近的同时提高网络的性能。值得一提的是,ResNeXt与常用的ResNet对应的层数完全相同,都是50、101、152层。ResNeXt已经被很多网络用来当作backbone,例如Mask RCNN中除了使用ResNet,也尝试使用了ResNeXt-101和ResNeXt-152。
解释cardinality:
原文的解释是the size of the set of transformations,如下图(左Resnet,右ResnetXt)右边是 cardinality=32 ,这里注意每个被聚合的拓扑结构都是一样的(这也是和 Inception 的差别,减轻设计负担)

参数量对比:
#Resnet
256*1*1*64+64*3*3*64+64*1*1*256 = 69632
#ResnetXt
(256*1*1*4+4*3*3*4+4*1*1*256)*32 = 70144
可见参数量差不多,网络宽度却增加了不少。
作者提出 ResNeXt 的主要原因在于:传统的要提高模型的准确率,都是加深或加宽网络,但是随着超参数数量的增加(比如channels数,filter size等等),网络设计的难度和计算开销也会增加。因此本文提出的 ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量。
附上原文比较核心的一句话,点明了增加 cardinality 比增加深度和宽度更有效:

当然还有一些数据证明 ResNeXt 网络的优越性,例如原文中的这句话:In particular, a 101-layer ResNeXt is able to achieve better accuracy than ResNet-200 but has only 50% complexity.
下图列举了 ResNet-50 和 ResNeXt-50 的内部结构,最后两行说明二者之间的参数量差别不大。

SeNet
论文:Squeeze-and-Excitation Networks
参考博客: SeNet算法笔记
ImageNet 2017第一名, Momenta (自动驾驶公司) 胡杰。

问题引出:
卷积神经网络建立在卷积运算的基础上,通过融合局部感受野内的空间信息和通道信息来提取信息特征。为了提高网络的代表性能力,许多现有工作已经显示出 增强空间编码 的好处。我们的目标是确保能够 提高网络对信息特征的敏感度 ,以便后续转换可以利用这些功能,并抑制不太有用的功能。我们建议通过显式建模 通道依赖性 来实现这一点,以便在进入下一个转换之前通过两步重新校准滤波器响应。
贡献:
- 引入
“挤压和激励模块”(Squeeze-and-Excitation):通过显示的对卷积层特征之间的通道相关性进行建模来提升模型的表征能力; - 提出了
特征重校准机制:通过使用全局信息去选择性的增强可信息化的特征并同时压缩那些无用的特征。
def forward(self, x):
out = F.relu(self.bn1(x))
#维度对齐
shortcut = self.shortcut(out) if hasattr(self, 'shortcut') else x
out = self.conv1(out)
out = self.conv2(F.relu(self.bn2(out)))
# Squeeze
w = F.avg_pool2d(out, out.size(2))
w = F.relu(self.fc1(w))
w = F.sigmoid(self.fc2(w))
# Excitation
out = out * w
out += shortcut
return out
-
解释Squeeze操作:
网络较低的层次其感受野尺寸很小(一般做1 * 1Conv来解决维度不匹配),Squeeze操作顺着空间维度来进行特征压缩(平均池化,将feature map的尺寸压缩为1 * 1),将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野。 -
解释Excitation操作:
它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。 -
解释Reweight(特征重校准)
最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
在实际网络中怎么添加SE模块?
Figure2是在Inception中加入SE block的情况。
Figure3是在ResNet中添加SE block的情况。

这两个全连接层的作用就是融合各通道的feature map信息,因为前面的squeeze都是在某个channel的feature map里面操作。
DenseNet
这篇文章是 CVPR 2017的oral论文
参考AI之路的博客
论文:Densely Connected Convolutional Networks
原作者的一些解释
最近的研究表明,想要训练一个更深更准确的网络,让靠近输入的层和靠近输出的层之间有更短的连接是有效的。
优点:
- 缓解梯度消失 。这个思想是基于ResNet的,DenseNet中的每一层可以直接接触到原始输入并且能接触到损失拿到梯度。
- 正则化效果。论文中提出
Composite function,包含BN->Relu->Conv。 - 特征重用。减少特征图的数量,使网络更narrow,参数更少, 因此能够更深,效果比ResNet好。
- 抗过拟合性。在CIFAR的数据集上做过实验,卷积每一层特征的提取都相当于对输入做非线性变换,而DenseNet汇聚了浅层特征的特点,有更好的泛化性。

传统的神经网络L层就会有L个连接,但是在DenseNet中,会有L(L+1)/2个连接,改动最大的地方是在block结构中,ResNet将输入block 的部分和输出结果做累加,而DenseNet直接将两者concat起来,所以叫做密集连接。
以下两个公式能说明两者的不同:
ResNet![]() , Densenet
, Densenet![]()
以下是一个layer的示例图:


网络结构设置

其中growth rate(即k)是卷积核个数变换的基数。
文章同时提出了DenseNet`,DenseNet-B,DenseNet-BC,三种结构,具体区别如下:
- 原始
DenseNet:
Dense Block模块:BN+Relu+Conv(3*3)+dropout
transition layer模块:BN+Relu+Conv(11)(filternum:m)+dropout+Pooling(22)
DenseNet-B:
Dense Block模块:BN+Relu+Conv(11)(filternum:4K)+dropout+BN+Relu+Conv(33)+dropout
transition layer模块:BN+Relu+Conv(11)(filternum:m)+dropout+Pooling(22)
DenseNet-BC:
Dense Block模块:BN+Relu+Conv(11)(filternum:4K)+dropout+BN+Relu+Conv(33)+dropout
transition layer模块:BN+Relu+Conv(11)(filternum:θm,其中0<θ<1,文章取θ=0.5)+dropout+Pooling(22)
其中,DenseNet-B在原始DenseNet的基础上,在Dense Block模块中加入了1*1卷积,使得将每一个layer输入的feature map都降为到4k的维度,大大的减少了计算量。
DenseNet-BC在DenseNet-B的基础上,在transitionlayer模块中加入了压缩率θ参数,论文中将θ设置为0.5,这样通过1*1卷积,将上一个Dense Block模块的输出feature map维度减少一半。
反正无脑用DenseNet-BC就行了
训练细节:
使用随机梯度下降(SGD)训练所有网络。
- 在CIFAR和SVHN上,我们使用批量训练大小为64,分别训练300和40个时期。 最初的学习率设定为0.1,并且在训练时期总数的50%和75%时除以10。
- 在ImageNet上,我们训练90个时期的模型,批量大小为256。学习率最初设定为0.1,并在epoch 30和60时除以10。
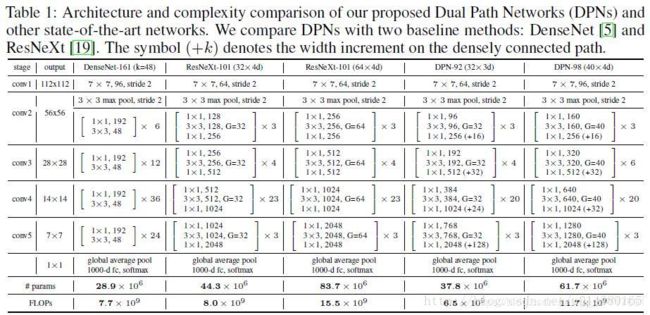
DPN
论文:Dual Path Networks,CVPR 2017
参考博客:DPN(Dual Path Network)算法详解
优点:
1、关于模型复杂度,作者的原文是这么说的:The DPN-92 costs about 15% fewer parameters than ResNeXt-101 (32 4d), while the DPN-98 costs about 26% fewer parameters than ResNeXt-101 (64 4d).
2、关于计算复杂度,作者的原文是这么说的:DPN-92 consumes about 19% less FLOPs than ResNeXt-101(32 4d), and the DPN-98 consumes about 25% less FLOPs than ResNeXt-101(64 4d).
class Bottleneck(nn.Module):
def __init__(self, last_planes, in_planes, out_planes, dense_depth, stride, first_layer):
super(Bottleneck, self).__init__()
self.out_planes = out_planes
self.dense_depth = dense_depth
self.conv1 = nn.Conv2d(last_planes, in_planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv2 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=32, bias=False)
self.bn2 = nn.BatchNorm2d(in_planes)
self.conv3 = nn.Conv2d(in_planes, out_planes+dense_depth, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes+dense_depth)
self.shortcut = nn.Sequential()
if first_layer:
self.shortcut = nn.Sequential(
nn.Conv2d(last_planes, out_planes+dense_depth, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_planes+dense_depth)
)
def forward(self, x): #假设输入x维度(3,32,32)
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out) #320*32*32(out_plane+(num_block+1)*dense_depth)
out = self.layer2(out) #672*16*16
out = self.layer3(out) #1528*8*8
out = self.layer4(out) #2560*4*4
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
大体的思路是:bottleneck的一条路线学习Resnet的shortcut,对x做维度对齐;一条路线学DenseNet,通过堆叠卷积模块1 * 1 conv->bn->relu->3 * 3 conv->bn->relu->1 * 1 conv->bn来扩大感受野,最后汇总两条路线的输出做concat,一层包含num_blocks个bottleneck,每层的输出通道数为out_plane+(num_block+1)*dense_depth。
有一个细节,3*3的卷积采用的是group操作,类似ResNeXt。
解释 group conv:
我们假设上一层的输出feature map有N个,即通道数channel=N,也就是说上一层有N个卷积核。再假设群卷积的群数目M。那么该群卷积层的操作就是,先将channel分成M份。每一个group对应N/M个channel,与之独立连接。然后各个group卷积完成后将输出叠在一起(concatenate),作为这一层的输出channel。这一操作适用于多GPU并行。
实验结果:


Figure 3,关于训练速度和存储空间的对比。现在对于模型的改进,可能准确率方面的提升已经很难作为明显的创新点,因为幅度都不大,因此大部分还是在模型大小和计算复杂度上优化,同时只要准确率还能提高一点就算进步了。
后续阅读路线
MobileNetV2
