【数据库系统概念】第1-3章 数据库基础知识入门 知识总结
《数据库系统概念》第1-3章知识点总结
数据库:由一个互相关联的数据的集合和一组用以访问这些数据的程序组成。
元组:指代行
属性:指代列
在文件处理系统中存储组织信息的主要弊端:
(1)数据的冗余和不一致
(2)数据访问困难
(3)数据孤立
(4)完整性问题
所以我们要有数据库
数据结构的基础是数据模型
数据模型是一个描述数据、数据联系、数据语义以及一致性约束的概念工具集合。主要模型有以下四种:
(1)关系模型,relational model
(2)实体-联系模型,entity-relationship model
(3)基于对象的数据模型,object-based data model
(4)单结构化数据模型,semistructured data model;例如可扩展标记语言(XML)被广泛地用来表示半结构化数据
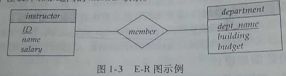
实体-联系模型
实体集:用矩形框表示,实体名在头部,属性名列在下面
联系集:用连接一对相关的实体集的菱形表示,联系名放在菱形内部
下面是一个例子:
row:行
column:列
record/taple:元组
attributes:属性(就是每一列)
domain:域,For each attribute of a relation ,there is a set of permitted values ,called the domain of that attribute.
atomic:原子性,For all relations r ,the domains of all attributes of r be atomic.
null:空,The null value is a special value that signifies that the value is unknown or does not exist.
database schema:数据库模式,is the logical design of the database.
database instance:数据库示例,is a snapshot of the data in the database at a given instant in time.
superkey:超码,is a set of one or more attributes that ,taken collectively ,allow us to identify uniquely a tuple in the relation.
candidate keys:候选码,the minimal superkeys are called candidate keys.
primary key:主码,one of the candidate keys is selected to be the primary key
foreign key:外码,a relation ,say r1 ,may include among its attributes the primary key of another relation ,say r2 .This attribute is called a foreign key form r1 ,referencing r2 .
referencing relation:外码依赖的参照关系,the relation r1 is called the referencing relation of the foreign key dependency
referenced relation:外码的被参照关系,r2 is called the referenced relation of the foreign key
超码:一个或多个属性的集合,这些属性的组合可以使我们在一个关系中唯一地表示一个元 组
候选码:最小超码。因为超码中可能包含无关紧要的属性,候选码中不存在无关紧要的属性。
主码:用来在一个关系中区分不同元组的候选码,应该选择那些值从不或极少变化的属性。 主码属性一般列在其他属性前面,且有下划线
外码:一个关系模式(如r1)可能在它的属性中包括另一个关系模式(如r2)的主码。这 个属性在r1上称作参照r2的外码。关系r1也称为外码依赖的参照关系,r2叫做外码 的被参照关系。
数据库中的常用的关系代数

初级SQL
The SQL language has several parts:
(1)Data_definition language(DDL,数据定义语言)
①defining relation schemas(定义关系模式)
②deleting relations(删除关系)
③modifying relation schemas(修改关系模式)
(2)Data_manipulation language(DML,数据操纵语言)
①query information from the database(查询信息)
②insert tuples into(插入元组)
③delete tuples from(删除元组)
④modify tuples(修改元组)(3)Integrity(完整性)
(4)View definition(视图定义)
(5)Transaction control(事务控制)
(6)Embedded SQL and dynamic SQL(嵌入式SQL和动态SQL)
(7)Authorization(授权)
SQL的基本类型:
(1)char(n):固定长度的字符串,全称character,输入字符数不足n时,追加空格
(2)varchar(n):可变长度的字符串,全称character varying
(3)int:整数类型,全称integer
(4)smallint:小整数类型
(5)numeric(p,d):定点数,这个数有p位数字,其中d位数字在小数点右边。
(6)real,double precision:浮点数与双精度浮点数
(7)float(n):精度至少为n位的浮点数
以下是几个后面会用到的表





创建、定义关系
通用形式是:
create table r
(A1 D1,
A2 D2,
...,
An Dn,
...,
r is the name of the relation
each Ai is the name of an attribute in the schema of relation r
each Di is the domain of attribute Ai
下面是一个具体的例子

primary key(A1,A2....):声明属性A1,A2....为关系的主码
foreign key(A1,A2....) references:声明表示关系中任意元组在属性(A1,A2....)上的取 值必须对应于关系s中某元组在主码属性上的取值
not null:不允许空值
单关系查询
(1)

(2)删除重复:distinct
![]()
(3)不去除重复:all,不过一般这是默认的,不需要写出来
![]()
where:用于选出那些在from子句的结果关系中满足特定谓词的元组
where中可以使用逻辑连词and or not。
多关系查询

自然连接
运算作用于两个关系,并产生一个关系作为结果。只考虑那些在两个关系模式中都出现的属性上取值相同的元组对
from子句中的“instructor natural join teaches”表达式可以替换成执行该自然连接后所得到的关系
 ====
====![]()
连接
join...using(A1,A2) 在t1.A1=t2.A1且t1.A2=t2.A2成立的前提下,来自r1的元组t1和来自r2的元组t2就能匹配
更名运算
old-name as new-name as子句既可出现在select子句中,也可以出现在from子句中

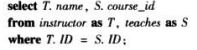
此处重新命名的标识符被称作相关名称、表别名、相关变量、元组变量
字符串运算
用like操作符来实现模式匹配,以下是两个特殊的字符
百分号(%):匹配任意子串
下划线(_):匹配任意一个字符
转义字符:用escape来定义,放在特殊字符前面使特殊字符得以显示
例:like ‘ab \% cd %’ escape‘\’ 匹配所有以ab % cd开头的字符串
select子句中的属性说明
星号‘*’可以用在select子句中表示“所有的属性”

元组的排序
order by xxx 表示按照xxx排序
desc表示降序
asc表示升序,没有说则默认为升序

where子句谓词
用between来表示一个区间,也可用not between

where子句谓词2
可以用记号(V1,V2,...,Vn)来表示一个分量值分别为V1,V2,...,Vn的n维元组
以下2段相等:


集合运算:并运算(union)、交运算(intersect)、差运算(except)
并运算
union运算自动去除重复,如果想保留所有重复,则用union all
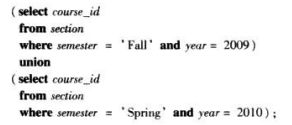
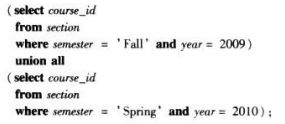
交运算
intersect运算自动去除重复,如果想保留所有重复,则用intersect all


差运算
except运算自动去除重复,如果想保留所有重复,则用except all
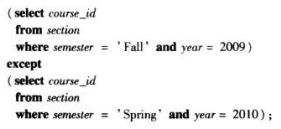

空值null
算术运算:如果算术表达式的任一输入为空,则该算术表达式(+ - * /)结果为空。
比较运算:涉及空值的任何比较运算的结果视为unknown。unknown是除true和false之外的第三个逻辑值
集合运算:
and:true and unknown = unknown
false and unknown = false
unknown and unknown = unknown
or:true or unknown = true
false or unknown = unknown
unknown or unknown = unknown
not:not unknown = unknown
如果where子句谓词对一个元组计算出false和unknown,那么该元组不能被加入到结果中。
聚集函数
聚集函数是以值的一个集合(集或多重集)为输入,返回单个值的函数。
平均值:avg
最小值:min
最大值:max
总和:sum
计数:count
sum和avg的输入必须是数字集
基本聚集
找出Computer Science系教师的平均工资

找出在2010年春季学期讲授一门课程的教师总数(去除了重复)

找出course关系中的元组数
![]()
分组聚集
group by子句中的所有属性上取值相同的元组被分在一个组中

注意:任何没有出现在group by子句中的属性如果出现在select子句中的话,它只能出现在聚集函数的内部,否则错误。例如,下述查询是错误的,因为ID没有出现在group by子句中,但它出现在了select子句中,而且没有被聚集

having子句
having子句中的谓词在形成分组后才起作用,也就是针对group by子句构成的分组
找出教室平均工资超过42000美元的系

注意:任何出现在having子句中,但没有被聚集的属性必须出现在group by子句中,否则错误。
SQL语句的执行顺序
from语句——where语句——group by语句——having语句——select语句
对空值和布尔值的聚集
除了count(*)外所有聚集函数都忽略输入集合中的空集,空集的count运算值为0。
嵌套子查询
集合成员资格
连接词in测试元组是否是集合中的成员
找出在2009年秋季和2010年春季学期同时开课的所有课程

括号中为子查询
集合的比较
some(至少):至少比某一个大—— >some
=some 等价于in
≠some 不等价于not in
找出满足下面条件的所有教师的姓名,她们的工资至少比Biology系某一个教师的工资要高

all(所有):比所有的都大—— >all
=all 不等价于in
≠all 等价于not in
找出满足下面条件的所有教师的姓名,她们的工资比Biology系每个教师的工资都高

空关系测试
exists结构可测试一个子查询的结果中是否存在元组,非空时返回true值。
not exists结构测试子查询结果中集中是否不存在元组
可以使用not exists结构模拟集合的【包含】操作:我们可以将“关系A包含关系B”写成not exists(B except A)
请看下面例子:
找出选修了Biology系开设的所有课程的学生

重复元组存在性测试
unique结构,测试在一个子查询的结果中是否存在重复元组,如果作为参数的子查询结果中没有重复的元组,则返回true值
找出所有在2009年最多开设一次的课程

lateral关键词
在from子句嵌套的子查询中并不能使用来自from子句其他关系的相关变量,而from子句其他关系的相关变量可以使用嵌套的子查询中的变量。
在from子句中的子查询添加关键词lateral作为前缀,就可以访问from子句中在它前面的表或子查询中的属性,例如
打印每位教师的姓名,以及他们的工资和所在系的平均工资

with子句
with子句提供定义临时关系的方法,这个定义只对包含with子句的查询有效
找出具有最大预算值的系
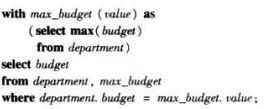
with子句定义了临时关系max_budget,此关系在随后的查询马上被使用了
数据库的修改
删除:只能删除整个元组,而不能只删除某些属性上的值
![]()
插入:待插入元组的属性值必须在相应属性的域中,并且分量数必须是正确的,且元组属性值的排列顺序和关系模式中属性排列的顺序一致。
![]()
更新:在不改变整个元组的情况下改变其部分属性的值
![]()
case结构

注:图片均来自《数据库系统概念》第6版——机械工业出版社