最新语义分割算法MS R-CNN、YOLACT小结
Mask Scoring R-CNN论文:https://arxiv.org/abs/1903.00241
GitHub地址:https://github.com/zjhuang22/maskscoring_rcnn
YOLACT论文:https://arxiv.org/abs/1904.02689
GitHub地址: https://github.com/dbolya/yolact
自己先简单做个笔记,下图都在作者的论文和GitHub上面找的。
Mask Scoring R-CNN
Mask Scoring R-CNN主要针对Mask RCNN进行改进,单独加了一个MaskIoU用于mask score,精度比Mask RCNN高。
结构如下:

可视化:
左四幅图像显示了良好的检测结果,分类分数高,但Mask质量低。Mask Scoring R-CNN方法旨在解决这个问题。最右边的图片显示了一个分类分数很高的Mask的情况。Mask Scoring R-CNN方法将重新训练高分。
YOLACT
检测速度对比:

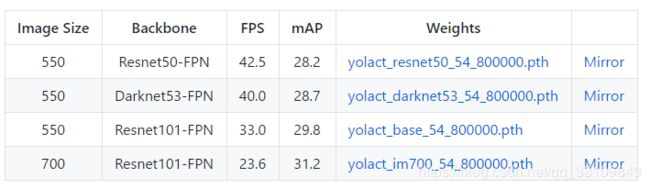
我自己测试的摄像头本身帧率在45左右,显卡1080ti,使用Resnet50-FPN模型,算法可以达到25FPS,Resnet101-FPN可达16FPS。
可视化:


YOLACT原理解析
主要参考:https://blog.csdn.net/jiaoyangwm/article/details/89176767
1.引言
目前在实例分割方面取得最好效果的入Mask R-CNN和FCIS,都是直接从目标检测的方法,如Faster R-CNN或R-FCN等中衍生的。但这些方法主要聚焦于网络的精度而非速度,使得缺乏与实时目标检测器(SSD或YOLO等)类似的实例分割方法。
本文的目标是跨越这个一直被忽略的实时实例分割的任务,建立一个快速的单级实例分割模型,类似于SSD和YOLO系列对弥补目标检测无单级网络所做的工作。
实现好的实例分割有一定的困难,且比目标检测困难许多。单级的目标检测器SSD和YOLO的出现使得目标检测的时间相对于使用两级检测器(Faster R-CNN等)有了大幅度的下降,单级检测器是通过去除第二级并在其他方面做了些弥补而获得了高速检测过程。目前最好的两级实例分割方法,在产生模板mask上非常依赖于特征定位准确与否,也就是在一些b-box区域要对特征进行“repooling”(RoI pooling/Align pooling),之后将新的定位特征送入mask预测器中,这个过程是内在有序的,故很难加速。单级的方法将该过程变为如FCIS那样并行的,但是这样一来就需要在定位之后进行很多后处理,仍然和“实时”有一定的差距。
本文提出的YOLACT(You Only Look At CoefficienTs)能够实时解决实例分割问题,放弃了定位的步骤。
YOLACT将实例分割分为两个并行任务:
1)针对整幅图像生成模板mask
2)对每个实例预测一系列的mask系数
之后,可以简洁的从上述两步中产生整幅图像的实例分割:对每个实例,将模板mask和预测的相应系数进行线性组合,并与预测的b-box进行裁剪。本文后续展示了通过以这种方式进行分割的过程,网络学会了自己定位实例mask,在这种情况下,视觉上、空间上和语义上相似的实例将在模板中呈现不同。
由于模板mask的数量不依赖于类别数量,也就是类别可能比模板数量多,YOLACT学习到的是一种分布式的表示,其中每个实例都有多个模板原型组合分割,这些模板在不同类别之间共享。
该分布式表示导致模板域出现了一些情况:一些模板在空间上划分开了图像,一些定位实例,一些检测实例的轮廓,一些编码对位置敏感的方向图谱,可能同时也会划分图像,如Fig.5。

Fig.5 :模板的效果,六种不同的模板对不同图像特征的响应。其中1,4,5可以检测出来轮廓清晰的目标;2能检测出左下方向的特征;3能够区分前景和背景,并提供实例的轮廓;6能够区分出来背景
算法优点
1.快速性
2.高质量的mask

3.易于泛化
生成模板mask和mask系数的理论可以用于目标任何的目标检测器。
2.YOLACT
本文的目标是对目前已有的单级目标检测网络添加一个产生mask的分支,就像Mask R-CNN对Faster R-CNN所做的工作一样,但是不包含定位步骤(如feature repooling)。我们将复杂的实例分割过程拆分为两个简单的并行过程,获得最终的mask。
第一个分支利用FCN来产生一系列与图像大小一致的“prototype masks”,且不依赖于任一特定实例。
第二个分支是给目标检测分支添加一个输出,对每个anchor来预测“mask coefficients”,也就是对实例的表示编码为prototype域的表达。
最后,对每个实例,使用NMS对所预测的mask进行处理。
①原理
该方法来实现实例分割的首要原因是mask之间是空域相关的,也就是像素距离越近,越可能是一个实例的某一部分。然而卷积层可以很好的从这些相关性中提取出特征,全连接层却不能。这就出现了一个问题,因为单级目标检测方法的fc层输出对每个anchor的类别和框位置的预测,两级方法(如Mask R-CNN)利用定位步骤(RoI Align)解决了这个问题,保持了特征的空域相关性也允许mask作为卷积层的输出。但是这样一来就需要一个很重要的分结构来等待第一级RPN输出的候选区域,很大程度上加大了时间开销。
YOLCAT将该问题分解为两个并行步骤,使用了fc层,该层在产生语义向量上很有优势,卷积层在产生空域相关mask上很有优势,能够产生“mask coefficients”。因为模板mask和mask系数的计算是可以分别进行的,所以检测器的主要计算就花费在两者的组合上,但这可以用用单个矩阵相乘来实现。这样一来,我们可以在特征域上保持空间相关性的同时保持单级网络的快速性。
 ②模板的产生
②模板的产生
模板产生的分支(protonet)针对每幅图像预测k个模板mask,本文用FCN的方式来实现protonet,FCN最后一层有k个channel,每个channel对应一个模板,且每个channel都被送入主要特征层(Fig.3)。

这样的结构类似于一般的语义分割,不同的是YOLACT提出这些模板没有很大的损失,所有的监督都源于集成后的mask损失。
③两个重要的设计
1.从更深的主要特征中产生更多的鲁棒mask,来获得protonet
2.更高分辨率的模板源于在小目标物体上更高质量的mask和在更好的性能
使用FPN是因为它最大的特征层是最深的层(P3,Fig.2),之后上采样将其尺寸提升到输入图像大小的1/4,来提高对小目标物体的检测性能。protonet的输出是无界的,这点很重要,因为这就允许网络在模板上产生强大的激活输出(如明显的背景)。选择Relu函数来获得更多可解释的模板。
④Mask 系数
典型的基于anchor的目标检测器有两个分支:
1.一个分支用来预测 c个类别的置信分数
2.另一个分支用来预测b-box的4个坐标
mask 系数的预测:
给系统添加第三个分支来预测 k个mask系数,每个系数对应于每个模板,所以我们预测 4+c+k个数。
非线性化:从最终的mask中去掉模板是很重要的,所以对 k个mask系数都使用 tanh来非线性处理,这样比未进行非线性处理的输出更稳定。该设计在Fig.2 中有体现,如果不允许做差,那么两个mask都是不可构造的。
⑤Mask集成
为了产生实例的mask,将产生模板的分支和产生mask系数的分支使用线性组合的方法进行结合,并对组合结果使用Sigmoid非线性化来获得最终的mask,该过程可以用单个矩阵相乘的方法来高效实现:
其中P为h×w×k大小的模板mask,C为n×k 大小的mask系数的转置,是经过了NMS和得分阈值处理后保留的n个实例的系数。
⑥损失函数
1)分类损失Lcls
2)边界框回归损失Lbox
3)mask损失Lmask =BCE(M,Mgt ),M是预测的mask,Mgt是真实的mask,公式为两者像素级二进制交叉熵。
⑦Mask的裁剪:
为了在模板中保留小目标物体,我们将最终的mask根据预测的b-box进行裁剪,训练过程中,我们使用真实的边界框进行裁剪,并且将Lmask除以真实的边界框的面积。
3. 检测器
对于检测器,我们首先考虑速度和特征丰富度,因子预测这些模板和系数是一项艰难的任务,好的特征才能获得好的结果。本文的检测器在RetinaNet的基础上,更加注重速度。
YOLACT 检测器:
本文使用RestNet-101和FPN作为默认特征主干网络,图像大小都为550×550。为了获得对每幅图像都相同的评估时间,不保留原始的纵横比。
类似于RetinaNet,我们对FPN做如下修改,不产生 P2,并且从P5 开始产生 P6 和 P7 作为连续的3×3 步长的卷积层,并且在每个上面放置纵横比为 [1,1/2,2] 的三个anchor。
P3 的 anchor 是面积为 24 pix的正方形,每个后面的层都是前面尺度的2倍,也就是 [24; 48; 96; 192; 384]。
因为预测输出依赖于每个Pi,我们对这三个分支共享一个 3×3的卷积核,之后每个分支获得自己的卷积核。与RetinaNet相比,本文的预测输出设计更为简洁和高效(Fig 4)

YOLACT利用smooth-L1 损失来进行box的回归训练,并且利用与SSD相同的方法来编码box回归的坐标。为了训练分类,我们使用softmax 交叉熵损失,有c个正标签和一个背景标签,训练样本的 neg:pos=3:1 neg:pos=3:1。不同于RetinaNet,YOLACT没有使用焦点损失。在相同大小的输入图像的情况下,比SSD表现的更快更好。
4.其他
Fast NMS

语义分割损失
Fast NMS 在提升速度的情况下,有少许的性能损失,还有别的方法在提升性能的情况下,对速度没有任何损失。其中一种方法,在训练中给模型添加额外的损失函数,但在测试中不添加,这样在没有速度损失的情况下有效的提升了特征的丰富性。故我们在训练过程中,给特征域增加了语义分割损失。因为我们从实例注释中构造损失的真值,没有直接的捕捉语义分割(也就是没有强制要求每个像素都是一个标准类)。
为了在训练中预测,我们简单的将有c个输出通道的1×1卷积层直接附加到主干网络最大的特征图(P3)上,因为,每个像素都可以分配多于1的类别,我们使用sigmoid和 cc 个通道而不是softmax和c+1个通道,这样定义损失函数的训练方法将mAP提升了0.4%。
5. 结果
本文在 MS COCO 数据集上进行了实例分割任务,在 train2017上进行训练,在val2017和test-dev上进行评估。
5.1 实例分割结果
首先,在 MS COCO 的test-dev数据集上对YOLACT和目前最好的方法进行了性能对比。
本文的关注点在于速度的提升,故我们和其他单模型的结果进行了对比,其中不包括测试时间。
本文的所有实验都是在Titan Xp上进行的,故一些结果和原文中的结果可能略有不同。
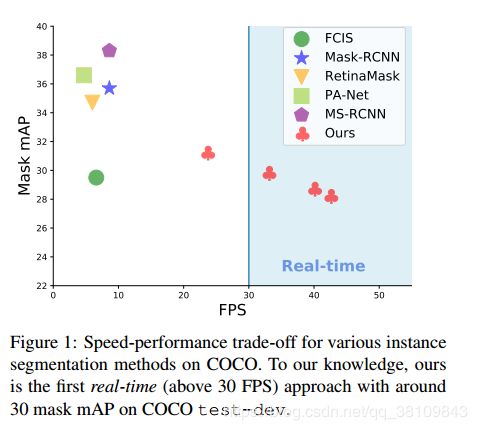
YOLACT-550,是目前最快的网络在COCO上实现实例分割速度的3.8倍
Fig 7中展示了,YOLACT-500和Mask R-CNN在IouO阈值为0.5的时候,AP之间的差距为9.5,当IoU阈值为0.75的时候,AP差距为6.6。
FCIS和MaskR-CNN之间的变化与其不同,该两者的差距基本是稳定的,前者的AP为7.5,后者的AP为7.6。

Table 1 同样也进行了实验来验证本文模型在不同大小输入图像情况下的性能。除过基本的 550×550大小模型,作者也训练了400×400和700×700的模型,相应地也调整了anchor的尺寸(Sx =S550 /550⋅x)。

降低图像大小会导致性能的大幅度下降,这说明越大的图像进行实例分割的性能越好,但提升图像尺寸带来性能提升的同时会降低运行速度。除了在基准主要网络RestNet-101上实验以外,同样在RestNet-50和RestNet-53上进行了实验来获得更快的效果。如果提升速度更好的话,作者建议使用RestNet-50或RestNet-53而不是减小图像大小,因为这样一来实现的性能比YOLACT-400上好很多,只是时间上略微慢一些而已。
5.2 Mask质量
我们产生的最终mask大小为138×138,且由于直接从原始特征中直接产生mask(未进行repooling则可能产生位移),我们针对大目标的mask比Mask R-CNN和 FCIS的质量有显著的优势。
Fig 7 中,YOLACT 对胳膊的边界产生了一个清楚的mask,Mask R-CNN和 FCIS的mask则带有一些噪声。
当IoU阈值为9.5的时候,本文的基准模型的AP达到了1.6,Mask R-CNN 达到了1.3,这意味着repooling会造成一定的mask 性能损失。
5.3 动态稳定性
本文的方法在动态视频上的稳定性高于Mask R-CNN , Mask R-CNN在帧间过渡的时候有很多跳动,甚至在目标静止的情况下也是一样。
作者之所以认为我们的方法对动态视频更稳定原因有两个:
1.YOLACT的mask性能更高,故帧间并没有很大误检
2.YOLACT的模型是单级的
多级模型更多的依赖于第一级产生的区域提议
YOLACT的方法当模型在帧间预测多个不同的候选框时,protonet不响应,故YOLACT的方法对动态视频更稳定。
5.4 实现细节
所有的模型训练都使用ImageNet训练的参数作为预定义参数,在单个GPU上训练,批量大小为8。这个大小适合于批归一化,所以我们保持预训练批规范化固定不变,也没有添加额外的bn层。
使用SGD方法进行800k次迭代,初始学习率设置为0.003,并且在迭代次数为280k, 600k, 700k, 和750k时,分别下降10%。
权重衰减率为0.0005,动量为0.9。
7. 结论
本文的网络优势:
快速,高质量的mask,优良的动态稳定性
本文网络的劣势:
性能略低于目前最好的实例分割方法,很多错误原因检测错误,分类错误和边界框的位移等
下面说明两个由YOLACT的mask生成方法造成的典型错误:
1)定位误差
当场景中一个点上出现多个目标时,网络可能无法在自己的模板中定位到每个对象,此时将会输出一些和前景mask相似的物体,而不是在这个集合中实例分割出一些目标。
Fig 6(第一行第一列)中的第一幅图,蓝色的卡车在红色的飞机之下,就没有得到正确的定位。
2)频谱泄露
本文的网络对预测的集成mask进行了裁剪,且并未对输出的结果进行去噪。这样一来,当b-box时准确的的时候,没有什么影响,但是当b-box不准确的时候,噪声将会被带入实例mask,造成一些“泄露”。
当两个目标离得很远的时候也会发生“泄露”的情况,因为网络学习到的是不需要定位离得很远的目标,但是裁剪的过程会关系这点。
假如预测的b-box很大,那么该mask将包括那些离得很远的mask,如Fig 6(第二行第四列)中发生的泄露是由于mask分支认为这三个滑雪的人离得足够远,并不用将他们划分开来。
该问题可以通过mask error down-weighting机制得到缓解,如MS R-CNN中那样,其中显示这些错误的mask可以被忽略。


最后放一个YOLACT的yolact_base_config模型结构:
Yolact(
(backbone): ResNetBackbone(
(layers): ModuleList(
(0): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(6): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(7): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(8): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(9): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(10): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(11): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(12): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(13): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(14): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(15): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(16): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(17): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(18): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(19): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(20): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(21): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(22): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
)
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(proto_net): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): ReLU(inplace)
(6): InterpolateModule()
(7): ReLU(inplace)
(8): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace)
(10): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))
)
(fpn): FPN(
(lat_layers): _ConstModuleList(
(0): WeakScriptModuleProxy()
(1): WeakScriptModuleProxy()
(2): WeakScriptModuleProxy()
)
(pred_layers): _ConstModuleList(
(0): WeakScriptModuleProxy()
(1): WeakScriptModuleProxy()
(2): WeakScriptModuleProxy()
)
(downsample_layers): _ConstModuleList(
(0): WeakScriptModuleProxy()
(1): WeakScriptModuleProxy()
)
)
(prediction_layers): ModuleList(
(0): PredictionModule(
(upfeature): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
)
(bbox_layer): Conv2d(256, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conf_layer): Conv2d(256, 243, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(mask_layer): Conv2d(256, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): PredictionModule()
(2): PredictionModule()
(3): PredictionModule()
(4): PredictionModule()
)
(semantic_seg_conv): Conv2d(256, 80, kernel_size=(1, 1), stride=(1, 1))
)