Hadoop+HBase环境搭建(单机版伪分布式)
一、准备工作
下载Hadoop:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
下载HBase: https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/
Linux版本:任选(我选择的是Centos7)
下载时,注意查看官方HBase版本与Hadoop版本两者支持的版本,然后下载相应的版本。

二、环境搭建
1.配置Java环境变量(两种)
首先查看官方文档HBase版本与JDK版本的支持: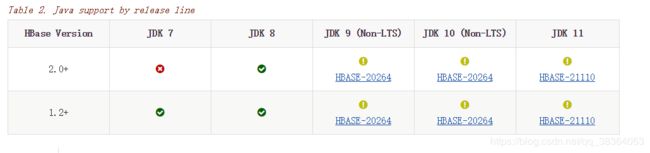
2.添加JAVA JDK环境变量:(推荐)
# vim /etc/profile.d/java.sh JAVA_HOME=/usr/local/jdk1.8.0_144 JRE_HOME=/usr/local/jdk1.8.0_144/jre CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export JAVA_HOME JRE_HOME PATH CLASSPATH# source /etc/profile.d/java.sh
3.另外一种添加Java JDK环境变量(选一种即可)
# vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_144 export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar export PATH=$JAVA_HOME/bin:$HOME/bin:$HOME/.local/bin:$PATH# reboot
我这里为centos7,如果选择在 /etc/profile 里添加 source命令不行 ,只能重启生效。
4.配置一下 hosts文件(目的是将你的 IP 和 主机名对应起来)
# vi /etc/hosts
我这里的主机已经改为master,不懂的自行百度修改主机名。

二、编辑Hadoop的配置文件
hadoop-env.sh 配置环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_144
core-site.xml 配置公共属性
fs.default.name
hdfs://master:9000
hadoop.tmp.dir
/home/hadoop-2.7.4/tmp
hdfs-site.xml 配置HDFS
dfs.namenode.secondary.http-address
master:9001
dfs.replication
1
yarn-site.xml 配置YARN
yarn.nodemanager.aux-services
mapreduce_shuffle
mapred-site.xml 配置MapReduce
mapreduce.framework.name
yarn
slaves 配置DataNode节点
# vi slaves
master
三、配置HBase
1.编辑hbase-env.sh文件
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME=/usr/local/jdk1.8.0_144
2.编辑hbase-site.xml
hbase.rootdir
hdfs://master:9000/hbase
hbase.zookeeper.quorum
master
hbase.zookeeper.property.dataDir
/home/hbase-1.2.6/data/zookeeper
hbase.cluster.distributed
true
3.编辑regionservers文件
# vi /opt/hbase-1.2.6/conf/regionservers
master
四、配置Hadoop和HBase的环境变量
# vi /etc/profile
#Hadoop Environment Setting
export HADOOP_HOME=/opt/hadoop-2.7.4#HBase Environment Setting
export HBASE_HOME=/opt/hbase-1.2.6export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin
# reboot
再次强调我的是centos7,这里用 source /etc/profile 报错,只好重启reboot生效
五、ssh免密设置
在[root@master ~]# 目录下
[root@master ~]# ssh-keygen -t rsa
一路回车
你会看到 ~ 目录下多了一个.ssh文件
[root@master ~]# ls -a
. anaconda-ks.cfg .bash_logout .bashrc .oracle_jre_usage .ssh
.. .bash_history .bash_profile .cshrc .pki .tcshrc[root@master .ssh]# ls
id_rsa id_rsa.pub[root@master .ssh]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
免密设置的目的是为了启动hadoop每次不用输入密码,也就是跳过输密码步骤,免得麻烦。
六、启动Hadoop(启动前先格式化)
# hdfs namenode -format
格式化后会有提示,如果看到 status=0表示格式化成功,然后每次启动hadoop集群namenode的信息
hadoop.tmp.dir
/home/hadoop-2.7.4/tmp
是放在/home/hadoop-2.7.4/tmp路径文件中,如果之后集群出问题需要格式化,那么需要先删除这个文件路径中的内容。
1.格式化后启动hadoop,配置了Hadoop的环境变量的,在全局都可以启动
# start-dfs.sh
# start-yarn.sh
启动完后访问50070端口, 我的ip是192.168.233.128:50070如果hadoop是启动成功的,然后访问不了界面,那么请检查下你虚拟机的 防火墙开启了吗。
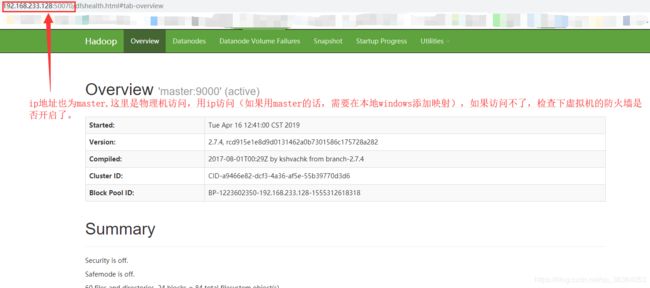
2.启动hbase,配置了Hbase的环境变量的,在全局都可以启动
# start-hbase.sh
启动成功后在物理机访问 16010 端口,HBase默认的Web UI端口
 这样HBase已经启动成功。
这样HBase已经启动成功。
如果还需要加Spark框架:https://www.jianshu.com/p/9622f684144d ,我的已经配置成功了。