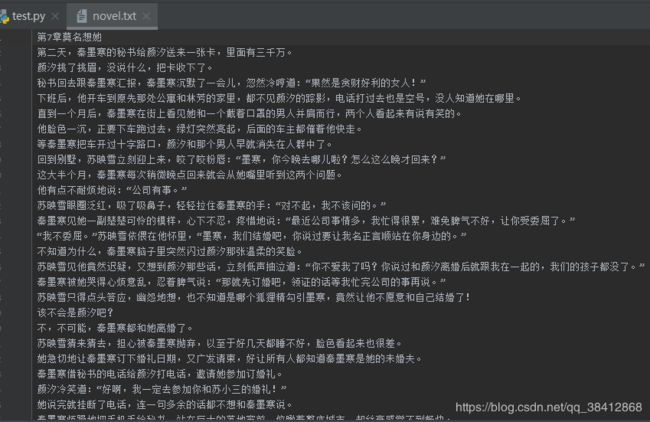
Python3读写txt文件
f=open('url.txt','r+',encoding='utf-8')
print(f.read())
f.close()若未加编码方式为utf-8,则会被默认为gbk或者gb2312编码,则在以utf-8来decode时会出错:

| 编码名称 | 用途 |
| utf8 | 所有语言 |
| gbk | 简体中文 |
| gb2312 | 简体中文 |
| gb18030 | 简体中文 |
| big5 | 繁体中文 |
| big5hkscs | 繁体中文 |
常用模式为:
r :只可读,若文件不存在,报错
r+:可读可写,若文件不存在,报错;若存在,覆盖写
w :只可写,若文件不存在,创建;若存在,清空后再写
w+: 可读可写,若文件不存在,创建;若存在,清空后再写
a :可写不可读,光标在最后面(然后读到最后面,所以读到空字符串),若文件不存在,创建;若存在,追加写
a+:可读可写,光标在最后面(然后读到最后面,所以读到空字符串),若文件不存在,创建;若存在,追加写
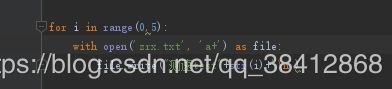
之前遇到写操作里面有循环的,用‘w+’模式,我还在想,循环中第二次会不会把第一次写入的清空掉再写,事实证明,并不会,在f.close()前仍是一次写的操作流程:
with open('novel.txt','w+',encoding='utf-8') as f:
for i in text:
f.write(i)
f.write('\n')循环中每一次写入一句并换行,下图说明每一次没有清空后写: