【2019.09.14】基于TensorFlow2.0,使用Keras + mnist(手写数字) 数据集进行深度学习实战
基于TensorFlow2.0,使用Keras + mnist(手写数字) 数据集进行深度学习实战
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPooling2D, Dropout
from tensorflow.keras import datasets
%matplotlib inline
# 1、加载数据
(train_images,train_labels),(test_images,test_labels) = datasets.mnist.load_data()
print(train_images.shape)
print(train_labels.shape)
print(test_images.shape)
print(test_labels.shape)
(60000, 28, 28)
(60000,)
(10000, 28, 28)
(10000,)
可以看到训练数据集由60000张28*28的图片组成,Label就是每个图像对应的手写字体的数字
# 2、构建模型
model = Sequential([Dense(512, activation='relu', input_shape=(28*28,)),
Dense(256, activation='relu'),
Dense(10, activation='softmax')])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 401920
_________________________________________________________________
dense_1 (Dense) (None, 256) 131328
_________________________________________________________________
dense_2 (Dense) (None, 10) 2570
=================================================================
Total params: 535,818
Trainable params: 535,818
Non-trainable params: 0
_________________________________________________________________
# 3、编译模型
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
在开始训练(拟合模型)之前,对数据进行预处理,将其变换为网络要求的形状
# 训练图像保存在一个uint8 类型的数组中,其形状为(60000, 28, 28),取值区间为[0, 255]。我们需要将其变换为一个float32 数组,其形状为(60000, 28 * 28),取值范围为0~1。
train_images = train_images.reshape(60000, 28*28).astype('float32') / 255
test_images = test_images.reshape(10000, 28*28).astype('float32') / 255
# 对标签进行分类编码
train_labels = tf.keras.utils.to_categorical(train_labels)
test_labels = tf.keras.utils.to_categorical(test_labels)
# 4、拟合模型
history = model.fit(train_images, train_labels,
epochs=10, batch_size=128,
validation_data=(test_images, test_labels))
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0134 - acc: 0.9955 - val_loss: 0.0824 - val_acc: 0.9812
Epoch 2/10
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0110 - acc: 0.9965 - val_loss: 0.0845 - val_acc: 0.9783
Epoch 3/10
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0092 - acc: 0.9968 - val_loss: 0.0957 - val_acc: 0.9788
Epoch 4/10
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0081 - acc: 0.9971 - val_loss: 0.0882 - val_acc: 0.9808
Epoch 5/10
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0095 - acc: 0.9968 - val_loss: 0.0861 - val_acc: 0.9819
Epoch 6/10
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0074 - acc: 0.9973 - val_loss: 0.0931 - val_acc: 0.9806
Epoch 7/10
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0077 - acc: 0.9973 - val_loss: 0.0970 - val_acc: 0.9805
Epoch 8/10
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0132 - acc: 0.9960 - val_loss: 0.0979 - val_acc: 0.9808
Epoch 9/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0025 - acc: 0.9992 - val_loss: 0.0934 - val_acc: 0.9810
Epoch 10/10
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0063 - acc: 0.9978 - val_loss: 0.0961 - val_acc: 0.9815
# 5、评估模型
# model.predict(test_images)
# model.predict_class(test_images)
model.evaluate(test_images, test_labels)
10000/10000 [==============================] - 1s 54us/sample - loss: 0.0961 - acc: 0.9815
[0.09613426262197114, 0.9815]
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(8,4),dpi=100)
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
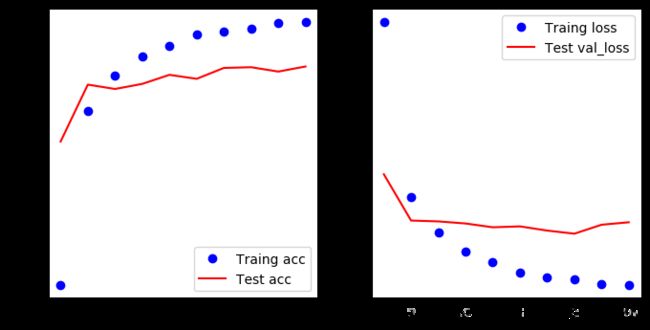
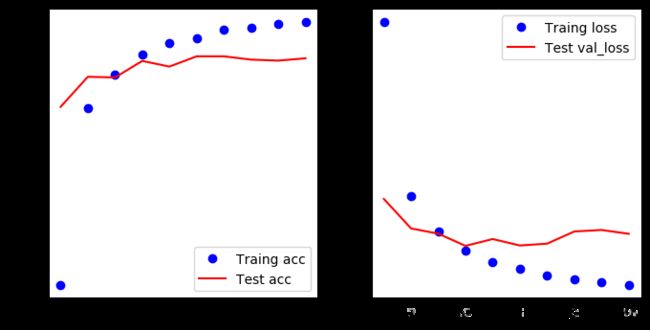
可以看出,准确率还是可以,不过测试数据比训练数据的结果还是要差一些,可能是因为有点过拟合了,我们只是一个3层的模型呀,增加一个Dropout层看看结果如何
# 2、构建模型
model = Sequential([Dense(512, activation='relu', input_shape=(28*28,)),
Dense(256, activation='relu'),
Dropout(0.5),
Dense(10, activation='softmax')])
# 3、编译模型
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
# 4、拟合模型
history = model.fit(train_images, train_labels,
epochs=10, batch_size=128,
validation_data=(test_images, test_labels))
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
60000/60000 [==============================] - 2s 36us/sample - loss: 0.2852 - acc: 0.9139 - val_loss: 0.1057 - val_acc: 0.9678
Epoch 2/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.1090 - acc: 0.9674 - val_loss: 0.0758 - val_acc: 0.9769
Epoch 3/10
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0730 - acc: 0.9775 - val_loss: 0.0704 - val_acc: 0.9767
Epoch 4/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0530 - acc: 0.9837 - val_loss: 0.0580 - val_acc: 0.9817
Epoch 5/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0415 - acc: 0.9871 - val_loss: 0.0650 - val_acc: 0.9800
Epoch 6/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0345 - acc: 0.9886 - val_loss: 0.0584 - val_acc: 0.9831
Epoch 7/10
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0282 - acc: 0.9912 - val_loss: 0.0603 - val_acc: 0.9831
Epoch 8/10
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0238 - acc: 0.9918 - val_loss: 0.0727 - val_acc: 0.9821
Epoch 9/10
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0211 - acc: 0.9929 - val_loss: 0.0742 - val_acc: 0.9818
Epoch 10/10
60000/60000 [==============================] - 2s 31us/sample - loss: 0.0188 - acc: 0.9935 - val_loss: 0.0703 - val_acc: 0.9825
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(8,4),dpi=100)
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
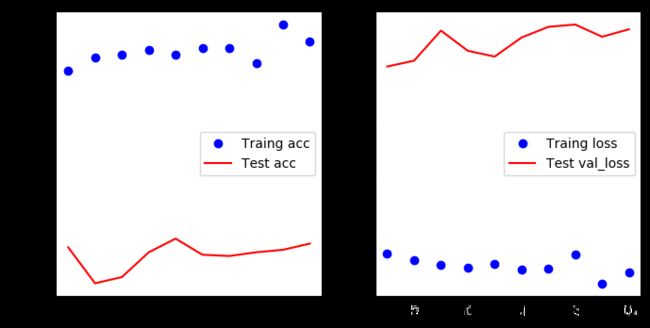
结果的趋势还没有很明显,增加epochs看看
history = model.fit(train_images, train_labels,
epochs=20, batch_size=128,
validation_data=(test_images, test_labels))
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
60000/60000 [==============================] - 2s 31us/sample - loss: 0.0154 - acc: 0.9952 - val_loss: 0.0694 - val_acc: 0.9842
Epoch 2/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0167 - acc: 0.9944 - val_loss: 0.0651 - val_acc: 0.9837
Epoch 3/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0142 - acc: 0.9953 - val_loss: 0.0829 - val_acc: 0.9823
Epoch 4/20
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0126 - acc: 0.9956 - val_loss: 0.0928 - val_acc: 0.9788
Epoch 5/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0109 - acc: 0.9963 - val_loss: 0.0758 - val_acc: 0.9832
Epoch 6/20
60000/60000 [==============================] - 2s 28us/sample - loss: 0.0114 - acc: 0.9961 - val_loss: 0.0850 - val_acc: 0.9821
Epoch 7/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0141 - acc: 0.9957 - val_loss: 0.0962 - val_acc: 0.9815
Epoch 8/20
60000/60000 [==============================] - 2s 31us/sample - loss: 0.0099 - acc: 0.9965 - val_loss: 0.0815 - val_acc: 0.9852
Epoch 9/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0108 - acc: 0.9964 - val_loss: 0.0870 - val_acc: 0.9839
Epoch 10/20
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0095 - acc: 0.9968 - val_loss: 0.0848 - val_acc: 0.9841
Epoch 11/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0102 - acc: 0.9966 - val_loss: 0.0864 - val_acc: 0.9826
Epoch 12/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0070 - acc: 0.9977 - val_loss: 0.0897 - val_acc: 0.9843
Epoch 13/20
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0092 - acc: 0.9973 - val_loss: 0.0935 - val_acc: 0.9834
Epoch 14/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0077 - acc: 0.9976 - val_loss: 0.0928 - val_acc: 0.9840
Epoch 15/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0085 - acc: 0.9974 - val_loss: 0.0921 - val_acc: 0.9850
Epoch 16/20
60000/60000 [==============================] - 2s 30us/sample - loss: 0.0085 - acc: 0.9973 - val_loss: 0.1007 - val_acc: 0.9829
Epoch 17/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0090 - acc: 0.9972 - val_loss: 0.1169 - val_acc: 0.9813
Epoch 18/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0066 - acc: 0.9978 - val_loss: 0.0962 - val_acc: 0.9838
Epoch 19/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0077 - acc: 0.9977 - val_loss: 0.1108 - val_acc: 0.9812
Epoch 20/20
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0074 - acc: 0.9977 - val_loss: 0.1012 - val_acc: 0.9836
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(8,4),dpi=100)
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
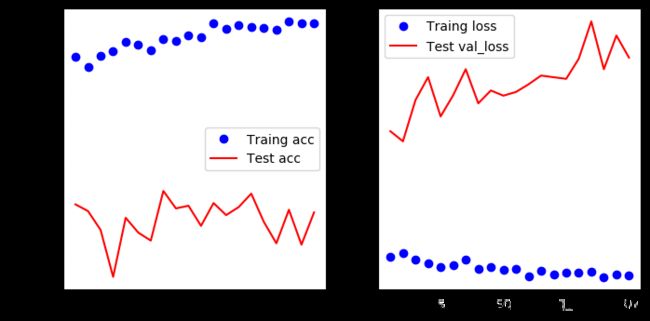
看样子又出现过拟合情况了,接下来大家可以调整各个超参数和网络层数,继续试试
# 全部代码
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPooling2D, Dropout
from tensorflow.keras import datasets
%matplotlib inline
# 1、加载数据
(train_images,train_labels),(test_images,test_labels) = datasets.mnist.load_data()
# 训练图像保存在一个uint8 类型的数组中,其形状为(60000, 28, 28),取值区间为[0, 255]。我们需要将其变换为一个float32 数组,其形状为(60000, 28 * 28),取值范围为0~1。
train_images = train_images.reshape(60000, 28*28).astype('float32') / 255
test_images = test_images.reshape(10000, 28*28).astype('float32') / 255
# 对标签进行分类编码
train_labels = tf.keras.utils.to_categorical(train_labels)
test_labels = tf.keras.utils.to_categorical(test_labels)
# 2、构建模型
model = Sequential([Dense(512, activation='relu', input_shape=(28*28,)),
Dense(256, activation='relu'),
Dropout(0.4),
Dense(10, activation='softmax')])
# 3、编译模型
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
# 4、拟合模型
history = model.fit(train_images, train_labels,
epochs=10, batch_size=128,
validation_data=(test_images, test_labels))
# 5、评估模型
# model.predict(test_images)
# model.predict_class(test_images)
model.evaluate(test_images, test_labels)
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(8,4),dpi=100)
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
60000/60000 [==============================] - 2s 33us/sample - loss: 0.2642 - acc: 0.9219 - val_loss: 0.1211 - val_acc: 0.9613
Epoch 2/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.1001 - acc: 0.9698 - val_loss: 0.0777 - val_acc: 0.9770
Epoch 3/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0665 - acc: 0.9794 - val_loss: 0.0769 - val_acc: 0.9758
Epoch 4/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0488 - acc: 0.9849 - val_loss: 0.0749 - val_acc: 0.9772
Epoch 5/10
60000/60000 [==============================] - 2s 31us/sample - loss: 0.0384 - acc: 0.9877 - val_loss: 0.0714 - val_acc: 0.9797
Epoch 6/10
60000/60000 [==============================] - 2s 32us/sample - loss: 0.0285 - acc: 0.9908 - val_loss: 0.0722 - val_acc: 0.9786
Epoch 7/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0247 - acc: 0.9916 - val_loss: 0.0683 - val_acc: 0.9816
Epoch 8/10
60000/60000 [==============================] - 2s 29us/sample - loss: 0.0221 - acc: 0.9924 - val_loss: 0.0653 - val_acc: 0.9818
Epoch 9/10
60000/60000 [==============================] - 2s 27us/sample - loss: 0.0182 - acc: 0.9939 - val_loss: 0.0738 - val_acc: 0.9806
Epoch 10/10
60000/60000 [==============================] - 2s 31us/sample - loss: 0.0175 - acc: 0.9943 - val_loss: 0.0761 - val_acc: 0.9820
10000/10000 [==============================] - 1s 55us/sample - loss: 0.0761 - acc: 0.9820