在pytorch框架下使用LSTM预测sin函数
基于pytroch使用LSTM预测sin函数
pytorch作为近期最火的深度学习库,拥有大量的使用粉丝。本文通过实战使用pytorch库,运用长短时记忆神经网络做预测。
- 什么是预测
- LSTM
- Code
- 什么是预测
大家都希望预测未来,所以在科研各个领域预测一直是科研中绕不开的话题。大家比较熟悉的有GDP预测、股票中的预测、人口预测,在这些预测中都需要很重要的一个因素,即历史数据。最开始的预测研究集中在线性回归、组合预测等等方式。这些方法通常用有形的函数对发展趋势做拟合配对,选取一个符合历史发展趋势的函数对未来进行预测。近年来深度学习迅速发展,通过使用神经网络进行回归预测的方法几乎占据了预测这类文章。
但是,我觉得预测就是一种伪科学,事物的发展具有不确定性,我也曾看过有硕士毕业论文写事故数预测,让我大跌眼镜,事物的发展固然有特定趋势,但是各种不确定性改变着事物的发展,如果一个事物受人为干预较多的,即强随机性的事物通常不可以预测,而相对较固定的事物预测确实可以通过预测的到相对合理的结果。综上,预测这种事物大家看看就好。
如果想了解预测可以看看这个ppt个人感觉还是写的不错。
(https://wenku.baidu.com/view/185f1a477dd184254b35eefdc8d376eeaeaa17c0.html)
- LSTM
LSTM全称 Long Short-Term Memory 是一种经典的神经网络算法。是循环神经网络RNN的一种变种,LSTM区别于RNN的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为cell。想了解LSTM可以看看这个博客。(https://www.cnblogs.com/wangduo/p/6773601.html)
LSTM就像神经网络界的AK47。不管我们怎么努力想用新玩意儿取代它,50年后数风流还得看它。 via:hardmaru
- CODE
下面附python 预测使用sin前两个数字预测下一位数的模式预测,使用了一部分别人的代码,如果涉及版权请找我删除。
# -*- coding: utf-8 -*-
"""
Created on Mon Feb 5 19:51:23 2018
@author: Maohan
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt#matplotlib inline
import math
dataset=[]
for data in np.arange(0, 3, .01):
data = math.sin(data*math.pi)
dataset.append(data)
dataset=np.array(dataset)
dataset = dataset.astype('float32')
max_value = np.max(dataset)
min_value = np.min(dataset)
scalar = max_value - min_value
dataset = list(map(lambda x: x / scalar, dataset))
def create_dataset(dataset, look_back=3):
dataX, dataY = [], []
for i in range(len(dataset) - look_back):
a = dataset[i:(i + look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(dataset)
train_size = int(len(data_X) * 0.7)
test_size = len(data_X) - train_size
train_X = data_X[:train_size]
train_Y = data_Y[:train_size]
test_X = data_X[train_size:]
test_Y = data_Y[train_size:]
import torch
train_X = train_X.reshape(-1, 1, 3)
train_Y = train_Y.reshape(-1, 1, 1)
test_X = test_X.reshape(-1, 1, 3)
train_x = torch.from_numpy(train_X)
train_y = torch.from_numpy(train_Y)
test_x = torch.from_numpy(test_X)
from torch import nn
from torch.autograd import Variable
# 定义模型
class lstm_reg(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(lstm_reg, self).__init__()
self.rnn = nn.LSTM(input_size, hidden_size, num_layers) # rnn
self.reg = nn.Linear(hidden_size, output_size) # 回归
def forward(self, x):
x, _ = self.rnn(x) # (seq, batch, hidden)
s, b, h = x.shape
x = x.view(s*b, h) # 转换成线性层的输入格式
x = self.reg(x)
x = x.view(s, b, -1)
return x
net = lstm_reg(3, 20)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=1e-2)
# 开始训练
for e in range(1000):
var_x = Variable(train_x)
var_y = Variable(train_y)
# 前向传播
out = net(var_x)
loss = criterion(out, var_y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e + 1) % 100 == 0: # 每 100 次输出结果
print('Epoch: {}, Loss: {:.10f}'.format(e + 1, loss.data[0]))
net = net.eval() # 转换成测试模式
data_X = data_X.reshape(-1, 1, 3)
data_X = torch.from_numpy(data_X)
var_data = Variable(data_X)
pred_test = net(var_data) # 测试集的预测结果
# 改变输出的格式
pred_test = pred_test.view(-1).data.numpy()
# 画出实际结果和预测的结果
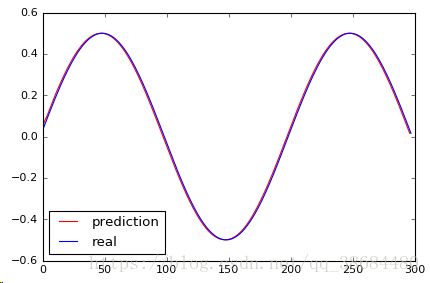
plt.plot(pred_test, 'r', label='prediction')
plt.plot(dataset[2:], 'b', label='real')
plt.legend(loc='best')
结果