Video Restoration with Enhanced Deformable Convolutional Networks论文翻译(具有增强的可变形卷积网络的视频恢复)
摘要
视频恢复任务,包括超分辨率,去模糊等,正在计算机视觉社区中引起越来越多的关注。在NTIRE19挑战赛中发布了名为REDS的具有挑战性的基准。这个新的基准测试从两个方面挑战现有方法:(1)如何在给定大运动的情况下对齐多个帧,(2)如何有效地融合具有不同运动和模糊的不同帧。在这项工作中,我们提出了一种新的视频恢复框架,其具有增强的可变形卷积,称为EDVR,以应对这些挑战。首先,为了处理大运动,我们设计了金字塔,级联和可变形(PCD)对准模块,其中使用可变形卷积以粗到细的方式在特征级别完成帧对齐。 其次,我们提出了时间和空间注意(TSA)融合模块,其中在时间和空间上都应用注意力,以便强调后续恢复的重要特征。 得益于这些模块,我们的EDVR赢得了冠军,并且在NTIRE19视频恢复和增强挑战的所有四个轨道中都大幅超越了第二名。 EDVR还展示了最先进的视频超分辨率和去模糊方法的卓越性能。代码可在https://github.com/xinntao/EDVR找到。
1.介绍
在本文中,我们描述了我们在NTIRE 2019视频恢复和增强挑战中的成功解决方案。 该挑战为上述任务发布了一个有价值的基准,称为REalistic和Diverse Scenes数据集(REDS)。相比下,对于现有数据集,REDS中的视频包含更大且更复杂的内容动作,使其更具现实性和挑战性。该竞赛可以实现不同算法之间的公平比较,并促进视频恢复的进展。
由于深度学习,过去几年中超分辨率(SR)和去模糊等图像恢复任务经历了显著的改进。 这些成功鼓励社区进一步尝试深入学习更具挑战性的视频恢复问题。早期研究将视频恢复视为图像恢复的简单扩展。相邻帧之间的时间冗余未被充分利用。最近的研究通过更精细的管道解决了上述问题,这些管道通常由四个部分组成,即特征提取,对准,融合和重建。当视频包含遮挡,大运动和严重模糊时,挑战在于对齐和融合模块的设计。为了获得高质量的输出,必须(1)在多个帧之间对齐并建立准确的对应关系,(2)有效地融合对准的特征以进行重建。
对齐。 大多数现有方法通过明确地估计参考帧与其相邻帧之间的光流场来执行对准。 基于估计的运动场变形相邻帧。另一个研究分支通过动态滤波或可变形卷积实现隐式运动补偿。REDS对现有的对齐算法提出了很大的挑战。特别地,精确的流量估计和精确的变形对于基于流量的方法而言可能是具有挑战性的并且是耗时的。在大运动的情况下,难以在单个分辨率范围内明确地或隐含地执行运动补偿。
融合。 融合对齐帧的功能是视频恢复任务中的另一个关键步骤。大多数现有方法或者使用卷积来对所有帧执行早期融合,或者采用循环网络来逐渐融合多个帧。 Liu等人提出了一种能够在不同时间尺度上动态融合的时间自适应网络。这些现有方法都没有考虑每个帧的潜在视觉信息-不同的帧和位置对于重建不具有相同的信息或益处,因为一些帧或区域受到不完美的对齐和模糊的影响。
我们方案。 我们提出了一个称为EDVR的统一框架,它可以扩展到各种视频恢复任务,包括超分辨率和去模糊。 EDVR的核心是(1)称为金字塔,级联和可变形卷积(PCD)的对准模块,(2)称为时间和空间注意(TSA)的融合模块。
PCD模块受到TDAN的启发,使用可变形卷积将每个相邻帧与特征级别的参考帧对齐。与TDAN不同,我们以粗到细的方式执行对齐以处理大而复杂的运动。具体来说,我们使用金字塔结构,首先将较低比例的特征与粗略估计对齐,然后将偏移和对齐特征传播到更高比例以促进精确的运动补偿,类似于光流估计中采用的概念。此外,我们在锥形对准操作之后级联另外的可变形卷积,以进一步提高对准的稳健性。
提出的TSA是一种融合模块,可帮助汇总多个对齐特征的信息。为了更好地考虑每帧的视觉信息,我们通过计算参考帧和每个相邻帧的特征之间的元素相关性来引入时间关注。然后,相关系数对每个位置处的每个相邻特征进行加权,指示重建参考图像的信息量。然后将来自所有帧的加权特征卷积并融合在一起。 在融合时间关注之后,我们进一步应用空间关注来为每个信道中的每个位置分配权重,以更有效地利用跨信道和空间信息。
我们参与了视频恢复和增强挑战中的所有四个赛道,包括视频超分辨率(clean/blur)和视频去模糊(clean/compression artifacts)。由于有效的对齐和融合模块,我们的EDVR赢得了所有四个挑战赛道的冠军,展示了我们的方法的有效性和普遍性。除竞赛结果外,我们还报告了现有视频超分辨率和去模糊基准的比较结果。我们的EDVR在这些视频恢复任务中表现出优于最先进方法的性能。
2.相关工作
视频恢复。 自SRCNN的先驱工作以来,深度学习方法在图像和视频超分辨率方面带来了显着的改进。对于视频超分辨率,时间对准起着重要作用,并且已经被广泛研究。几种方法使用光流来估计图像之间的运动并执行变形。然而,在闭塞和大运动的情况下难以获得准确的流动。TOFlow还表明,标准光流不是视频恢复的最佳运动表示。DUF和TDAN通过隐式运动补偿来克服问题并超越基于流的方法。我们的EDVR还具有隐式对齐的优点,具有金字塔和级联架构来处理大型运动。
视频去模糊也受益于基于学习方法的发展。几种方法直接融合多个帧而没有明确的时间对齐,因为模糊的存在增加了运动估计的难度。与这些方法不同,我们尝试使用对齐从多个帧中获取信息,稍微修改一下,当存在模糊时,在对齐之前添加图像去模糊模块。
可变形卷积。 Dai等人首先提出了可变形卷积,其中学习了额外的偏移以允许网络从其常规局部邻域获得信息,从而提高了定期卷积的能力。可变形卷积广泛用于各种任务,例如视频对象检测,动作识别,语义分割和视频超分辨率。特别地,TDAN使用可变形卷积来在特征级别对齐输入帧而无需显式运动估计或图像变形。受TDAN的启发,我们的PCD模块采用*可变形卷积作为对齐的基本操作。
注意机制。 注意力已证明其在许多任务中的有效性。例如,在视频SR中,Liu等人学习了一组权重图来权衡来自不同时间分支的特征。非局部运算将位置处的响应计算为所有位置处的特征的加权和,以捕获长程依赖性。在这些作品成功的推动下,我们在TSA融合模块中采用时间和空间关注,以便在不同的时间和空间位置上进行不同的重点。
3.方法
3.1.概观

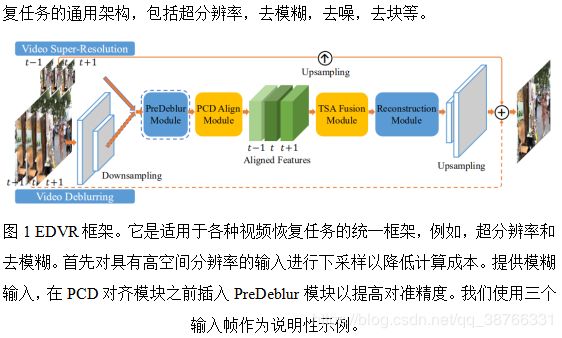

对于具有高空间分辨率输入的其他任务,例如视频去模糊,首先使用跨步卷积层对输入帧进行下采样。然后,大多数计算在低分辨率空间中完成,这在很大程度上节省了计算成本。最后的上采样层将功能调整为原始输入分辨率。在对齐模块之前使用PreDeblur模块来预处理模糊输入并提高对齐精度。
虽然单个EDVR模型可以实现最先进的性能,但我们采用两阶段策略来进一步提升NTIRE19比赛中的性能。具体而言,第一阶段,我们级联相同的EDVR网络,但深度较浅,以优化输出帧。级联网络可以进一步消除前一模型无法处理的严重运动模糊。详情见第3.4节。
3.2.与金字塔,级联和可变形卷积对齐


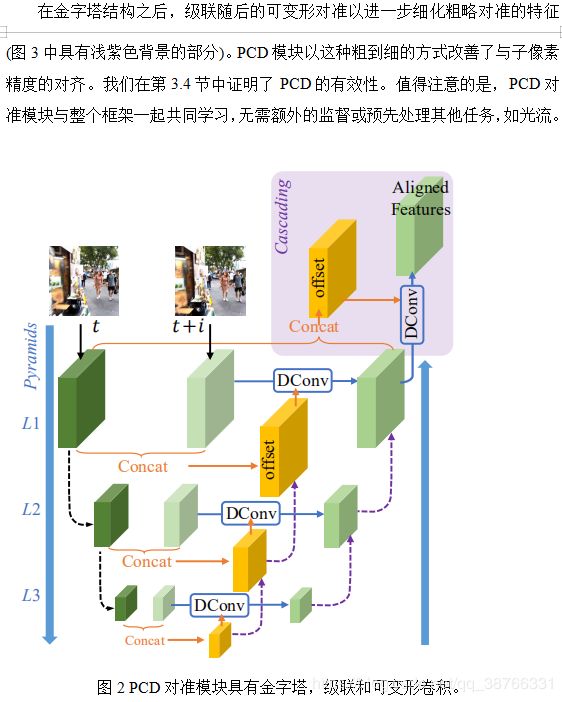
3.3.与时空注意融合
帧间时间关系和帧内空间关系在融合中是关键的,因为1)由于遮挡,模糊区域和视差问题,不同的相邻帧不具有相同的信息量;2)前一个对准阶段产生的不对准和不对准会对后续的重建性能产生不利影响。因此,动态聚合像素级的相邻帧对于有效和高效的融合是必不可少的。为了解决上述问题,我们提出了TSA融合模块。在每个帧上分配像素级聚合权重。具体而言,我们在融合过程中采用时空关注,如图3所示。


3.4.两阶段恢复
虽然配备PCD对准模块和TSA融合模块的单个EDVR可以实现最先进的性能,但是观察到恢复的图像并不完美,尤其是当输入帧模糊或严重失真时。 在如此恶劣的环境中,运动补偿和细节聚集受到影响,导致较差的重建性能。
直观地,粗略恢复的框架将极大地减轻对准和融合的压力。因此,我们采用两阶段策略来进一步提升性能。具体而言,类似但较浅的EDVR网络级联以细化第一阶段的输出帧。优点是双重的:1)它有效地消除了前一模型中无法处理的严重运动模糊,提高了恢复质量; 2)它减轻了输出帧之间的不一致性。第四节说明了两阶段恢复的有效性。
4.实验
4.1.训练数据集和详细信息
训练数据集。 之前关于视频处理的研究通常是在私人数据集上开发或评估的。缺乏标准和开放视频数据集限制了公平比较。REDS是NTIRE19竞赛中新提出的高质量(720p)视频数据集。REDS包含240个训练片段,30个验证片段和30个测试片段(每个片段有100个连续帧)。在比赛期间,由于test ground truth不可用,我们选择四个代表性片段(具有不同的场景和动作)作为我们的测试设置,由REDS4表示。剩下的训练和验证片段被重新分组为我们的训练数据集(共266个片段)。为了与我们在竞赛中的方法和流程保持一致,我们在本文中也采用了这种配置。
Vimeo-90K是一种广泛使用的训练数据集,通常与Vid4和Vimeo-90K测试数据集(由Vimeo-90K-T表示)一起用于评估。当训练集的分布偏离测试集的分布时,我们观察到数据集偏差。更多细节见第4.3节。
训练详细信息。
PCD对准模块采用五个残余块(RB)来执行特征提取。我们在重建模块中使用40个RB,在第二阶段模型中使用20个RB。每个残余块中的通道大小设置为128。我们分别使用大小为64×64和256×256的RGB补丁作为视频SR和去模糊任务的输入。小批量大小设置为32。除非另有说明,否则网络需要五个连续帧(即N = 2)作为输入。我们使用随机水平翻转和90°旋转来增加训练数据。我们只采用Charbonnier惩罚函数作为最终损失,定义为:

4.2.与最先进的方法进行比较
我们将EDVR与几种最先进的视频SR和视频去模糊方法进行了比较。不使用两阶段和自集合策略。在评估中,我们包括所有输入帧而不裁剪任何边界 除DUF方法之外的像素。由于严重的边界效应,我们在DUF的图像边界附近裁剪了8个像素。
视频超分辨。 我们将EDVR方法与九种算法进行比较:RCAN,DeepSR,BayesSR,VESPCN,SPMC,TOFlow,FRVSR,DUF和RBPN在三个测试数据集上:Vid4,Vimeo-90K-T和REDS4。大多数先前的方法使用不同的训练集和不同的下采样内核,使得比较困难。每个测试数据集具有不同的特征。Vid4通常用于视频SR。 数据的运动受到限制。视觉真物(GT)帧上也存在视觉伪影。Vimeo-90K-T是一个包含各种动作和不同场景的更大的数据集。 REDS4由高质量的图像组成,但运动更大,更复杂。 当训练和测试集分歧时,我们观察到数据集偏差。因此,当我们在Vid4和Vimeo-90K-T上进行评估时,我们在Vimeo-90K上训练我们的模型。
我们将EDVR方法与九种算法进行比较:RCAN,DeepSR,BayesSR,VESPCN,SPMC,TOFlow,FRVSR,DUF和RBPN在三个测试数据集上:Vid4,Vimeo-90K-T和REDS4。大多数先前的方法使用不同的训练集和不同的下采样内核,使得比较困难。每个测试数据集具有不同的特征。Vid4通常用于视频SR。 数据的运动受到限制。视觉真物(GT)帧上也存在视觉伪影。Vimeo-90K-T是一个包含各种动作和不同场景的更大的数据集。 REDS4由高质量的图像组成,但运动更大,更复杂。当训练和测试集分歧时,我们观察到数据集偏差。因此,当我们在Vid4和Vimeo-90K-T上进行评估时,我们在Vimeo-90K上训练我们的模型。
Vid4,Vimeo-90K-T和REDS4的定量结果分别显示在表1,表2和表3(左)中。在Vid4上,EDVR实现了与DUF相当的性能,并且大幅优于其他方法。在Vimeo-90K-T和REDS上,EDVR明显优于最先进的方法,包括DUF和RBPN。 Vid4和Vimeo-90K-T的定性结果分别如图4和图5所示。在两个数据集上,与现有方法相比,EDVR恢复了更精确的纹理,特别是在图6的第二个图像中,其中字符只能在EDVR的输出中正确识别。

视频去模糊。 我们将EDVR方法与四种算法进行比较:REDS4数据集上的DeepDeblur,DeblurGAN,SRN-Deblur和DBN。定量结果如表3(右)所示。我们的EDVR大大超过了最先进的方法。我们将这归因于我们的方法的有效性和包含复杂模糊的具有挑战性的REDS数据集。可见结果如图6所示,而大多数方法能够解决小模糊,只有EDVR可以从极其模糊的图像中成功恢复清晰的细节。

4.3.消融研究
PCD对准模块。 如表4(左)所示,我们的基线(模型1)仅采用一个可变形卷积进行对齐。模型2遵循TDAN的设计,使用四个可变形的卷积进行对准,实现0.2 dB的改进。使用我们提出的PCD模块,模型3比模型2好近0.4 dB,具有大致相同的计算成本,证明了PCD对准模块的有效性。在图7中,我们显示了不同对齐模块之前和之后的代表性特征,并描绘了参考和相邻特征之间的流程(由PWCNet导出)。与没有PCD对齐的流程相比,PCD输出的流量更小更清晰,表明PCD模块可以成功处理大而复杂的运动。

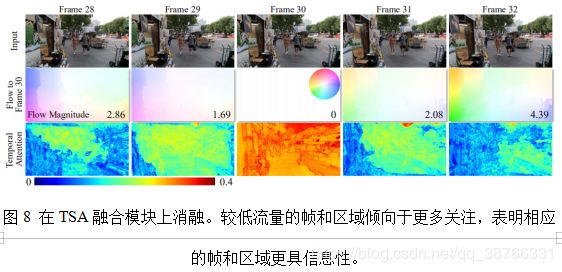
TSA注意模块。 如表4(左)所示,使用TSA注意模块,与具有类似计算的模型3相比,模型4实现了0.14 dB的性能增益。在图8中,我们呈现参考帧和相邻帧之间的流,以及每帧的时间注意力。观察到具有较低流量的帧和区域倾向于具有较高的关注度,表明运动越小,相应的帧和区域的信息量越大。
数据集偏差。 如表4(右)所示,我们对视频超分辨率进行了不同的训练和测试数据集设置。结果表明存在较大的数据集偏差。当训练和测试数据的分布不匹配时,性能下降0.5-1.5 dB。我们认为视频恢复方法的普遍性值得研究。
4.4.对REDS数据集的评估
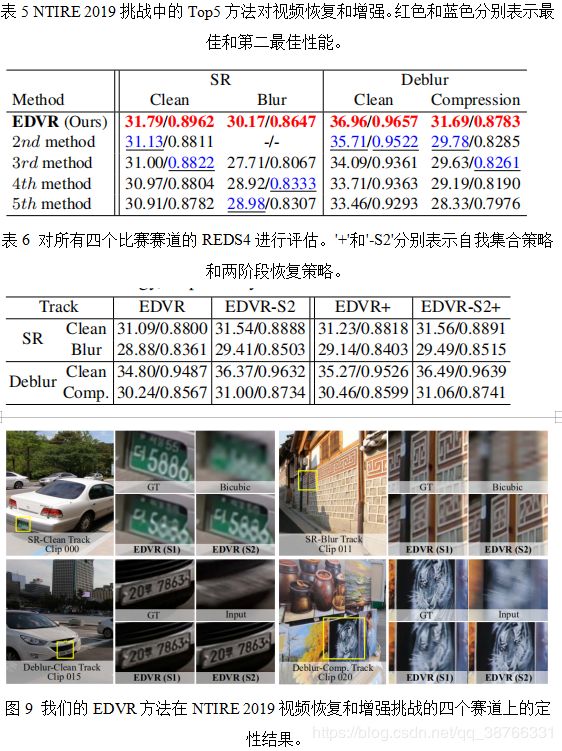
我们参与了NTIRE19视频恢复和增强挑战中的所有四个赛道。定量结果如表5所示。我们的EDVR赢得冠军,并且在所有赛道中均大幅超越第二名。在比赛中,我们采用自我整合作为[4,5]。具体来说,在测试期间,我们翻转并旋转输入图像,为每个样本生成四个增强输入。然后,我们对每个应用EDVR方法,对恢复的输出反转转换,并对最终结果求平均值。第3.4节中描述的两阶段恢复策略也用于提高性能。如表6所示,我们观察到两阶段恢复大大改善了0.5 dB左右的性能(EDVR(+)与EDVR-S2(+))。虽然自组合在第一阶段(EDVR与EDVR +)有帮助,但它仅在第二阶段(EDVR-S2与EDVR-S2 +)带来微小的改善。定性结果如图10所示。观察到第二阶段有助于在具有挑战性的案例中恢复清晰的细节,例如,输入非常模糊。
5.结论
我们在NTIRE 2019视频恢复和增强挑战中介绍了我们的获胜方法。为了应对比赛中发布的具有挑战性的基准,我们提出了EDVR,这是一个独特设计的统一框架,可在各种视频恢复任务中实现良好的对齐和融合质量。得益于PCD校准模块和TSA融合模块,EDVR不仅赢得了NTIRE19挑战赛中的所有四个赛道,而且在视频超分辨率和去模糊的几个基准测试中展示了现有方法的卓越性能。
参考文献
[1]Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. In ICCV, 2017. 2, 3.
[2]Xintao Wang, Ke Yu, Chao Dong, and Chen Change Loy.Recovering
realistic texture in image super-resolution by deep spatial feature transform. In CVPR, 2018. 1, 4.
[3]Tianfan Xue, Baian Chen, Jiajun Wu, Donglai Wei, and William T
Freeman. Video enhancement with task-oriented flow. arXiv preprint arXiv:1711.09078, 2017. 1, 2, 4, 5, 6, 7.
[4] Radu Timofte, Rasmus Rothe, and Luc Van Gool. Seven ways to improve example-based single image super resolution. In CVPR, 2016. 8.
[5] Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. In CVPRW, 2017. 1, 2, 5, 8.