持续更新
如何浅显易懂地解说 Paxos 的算法?
参考资料 #8:知行学社的分布式系统与Paxos算法视频课程,循序渐进,讲解得比较浅显易懂
Paxos
背景
什么是 consensus (一致性)问题?
在一个分布式系统中,有一组的 process,每个 process 都可以提出一个 value,consensus 算法就是用来从这些 values 里选定一个最终 value。如果没有 value 被提出来,那么就没有 value 被选中;如果有1个 value 被选中,那么所有的 process 都应该被通知到。
上面问题看上去很好解决,比如用一个 master,所有 process 都向这个 master 提交 value,这个 master 可以根据先到的原则选择最先到达的 value 为最终 value 并通知给所有 process。这里有个问题,如果这个 master 断了、当机、重启、崩溃了怎么办?所以一个好的方法就是选择一组 masters,value 由这一组 masters 共同决定,有点像 ”议会“。为了解决这个问题,大家提出了各种各样的 protocols(协议),其中最有名的就是 Lamport 的 Paxos.
Icon
Paxos is a consensus algorithm executed by a set of processes, termed replicas, to agree on a single value in the presence of failures.
Paxos算法解决的问题是在一个可能发生异常(进程可能会慢、被杀死或者重启,消息可能会延迟、丢失、重复,不考虑消息篡改即拜占庭错误的情况)的分布式系统中如何就某个值达成一致,保证不论发生以上任何异常,都不会破坏决议的一致性。
Paxos协议提出只要系统中2f+1个节点中的f+1个节点可用,那么系统整体就可用并且能保证数据的强一致性,它对于可用性的提升是极大的。
Paxos协议由Leslie Lamport最早在1990年提出,由于Paxos在云计算领域的广泛应用Leslie Lamport因此获得了2013年度图灵奖。
算法
Leslie写的两篇论文:《The Part-Time Parliament》和《Paxos Made Simple》比较完整的阐述了Paxos的工作流程和证明过程,Paxos协议把每个数据写请求比喻成一次提案(proposal),每个提案都有一个独立的编号,提案会转发到提交者(Proposer)来提交,提案必须经过投票委员会(Quorum)接受才会生效,投票委员会中的节点叫做Acceptor。
角色分为proposers,acceptors(允许身兼数职)
proposers提出提案,提案信息包括提案编号和提议的value
acceptor收到提案后可以接受(accept)提案,若提案获得多数acceptors的接受,则称该提案被批准(chosen)
Paxos协议流程划分为两个阶段,第一阶段是Proposer学习提案最新状态的准备阶段;第二阶段是根据学习到的状态组成正确提案提交的阶段,完整的协议过程如下:
prepare 阶段:
1a) proposer选择一个提案编号n并将prepare请求发送给acceptors中的一个多数派;
1b) acceptor收到prepare消息后,如果提案的编号大于它已经回复的所有prepare消息,则acceptor将自己上次接受的提案回复给proposer,并承诺不再回复小于n的提案;accept 阶段:
2a) 当一个proposer收到了多数acceptors对prepare的回复后,就进入批准阶段。它要向回复prepare请求的acceptors发送accept请求,包括编号n和根据P2c决定的value(如果根据P2c没有已经接受的value,那么它可以自由决定value)。
2b) 在不违背自己向其他proposer的承诺的前提下,acceptor收到accept请求后即接受这个请求。
这个过程在任何时候中断都可以保证正确性。例如如果一个proposer发现已经有其他proposers提出了编号更高的提案,则有必要中断这个过程。
P2c:如果一个编号为n的提案具有value v,那么存在一个多数派,要么他们中所有人都没有接受(accept)编号小于n 的任何提案,要么他们已经接受(accept)的所有编号小于n的提案中编号最大的那个提案具有value v。
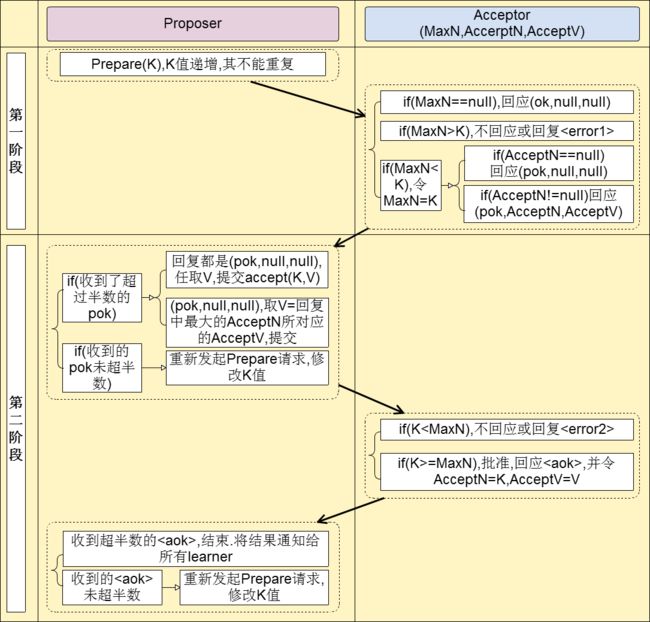
核心
可以简单描述为:Proposer先从大多数Acceptor那里学习提案的最新内容,然后根据学习到的编号最大的提案内容组成新的提案提交,如果提案获得大多数Acceptor的投票通过就意味着提案被通过。
由于学习提案和通过提案的Acceptor集合都超过了半数,所以一定能学到最新通过的提案值,两次提案通过的Acceptor集合中也一定存在一个公共的Acceptor,在满足约束条件b时这个公共的Acceptor时保证了数据的一致性,于是Paxos协议又被称为多数派协议。
算法本质上很简单,保证一致性所依赖的物理事实是:两个多数集合至少有一个公共成员。把全局信息存储在多数集合返回的统计结果上。
如果一个值曾经被通过了,多数集合中至少有一个成员记得它。
所以提议新值之前,先通过一个prepare阶段就是从一个多数集合中收集到可能已经通过的值,并同步时钟。
然后在accept阶段就是发送可能已通过的值,或者在没有值的情况下提议一个新值。
PaxosLease
PaxosLease 是 Kespace 开发的基于 Paxos、Lease 机制的 Master 选举算法
由来
在Paxos中,如果能够选举出一个leader(在Lamport的论文中称之为总统),那么有助于提高投票的成功率。另外这个leader在多个决议的选举中有很重要的作用(要靠他得到决议的连续id)。因此,如何通过某种方法得到一个leader就是PaxosLease所说明的。
Master选举的过程是这样的:从众多的Node中选择一个作为Master,如果该Master 一直 alive则无需选举,如果master crash,则其他的node进行选举下一个master。选择正确性的保证是:任何时刻最多只能有一个master。
逻辑上Master更像一把无形的锁,任何一个节点拿到这个锁,都可成为master,所以本质上Master选举是个分布式锁的问题,但完全靠锁来解决选举问题也是有风险的:如果一个Node拿到了锁,之后crash,那锁会导致无法释放,即死锁。一种可行的方案是给锁加个时间(Lease),拿到锁的Master只能在Lease有效期内访问锁定的资源,在Lease timeout后,其他Node可以继续竞争锁,这就从根本上避免了死锁。
Master在拿到锁后,如果一直alive,可以向其他node”续租“锁,从而避免频繁的选举活动。
算法
算法过程略,详见参考资料 #10:PaxosLease - 老码农的专栏
1、算法的角色与Paxos一样,也分Proposer、Acceptor、Learner,各角色的行为也与paxos基本一致。
2、accept 的 1a) 阶段
原始的paxos规定,如果接收的value v不为空,则使用v继续accept阶段,以保证每次选举仅选出一个决议;
PaxosLease选举的目的是使其他node接受自己作为master,当接收的value不为空时,自己应该退出选举,而不是继续提交其他Node的value。也就是说,只要当前node知道其他Node可能会优先自己成为master,则退出选举,成就他人。
3、Master选举因为频率低。PaxosLease在失败重新提交proposal时随机等待一段时间,因为各Node等待时间的不一致,只要运行足够长的时间,活锁总能避免。
4、重新加入的节点可能会扰乱前面的paxos过程,因此强制Node在重新加入前必须等待M秒,因为M > T,所以只要等待M秒便可以越过本次paxos选举。其实不能从理论上完全保证PaxosLease能正确执行。重要的是重加入后不能立即参加paxos过程。在实际中因为选举的过程非常快,节点重加入的过程也可监控,这些理论上的错误是很难发生的。
PaxosLease的正确性是有Paxos算法保证的,PaxosLease只是在Paxos的基础上限定了一个时间。在时间T之内,任何Node都不能申请lease,因此master宕机后重新选择master的最大时间为T,也即服务不可用的最大时间为T。
T设的过小会减少服务不可用的时间,但会产生更多的内部消息;设的过大内部消息减少,但会导致更长的宕机时间。
PaxosLease是一个节点之间不存在依赖的简洁的选举算法,就像其论文所说每个节点都有两个状态:
我不是master,也不知道谁是master
我是master
正因为如此,PaxosLease的缺点就是无法做到负载均衡,无法按权重选择master。
Lease 机制
Lease机制是最重要的分布式协议,广泛应用于各种实际的分布式系统中。
Lease通常定义为:颁发者在一定期限内給予持有者一定权利的协议。
Lease 表达了颁发者在一定期限内的承诺,只要未过期颁发者必须严格遵守 lease 约定的承诺;
Lease 的持有者在期限内使用颁发者的承诺,但 lease 一旦过期必须放弃使用或者重新和颁发者续约。
参考资料 #12
Multi-Paxos
paxos是对一个值达成一致,multi-paxos是运行多个paxos instance来对多个值达成一致,每个paxos instance对一个值达成一致。在一个支持多写并且强一致性的系统中,每个节点都可以接收客户端的写请求,生成redo日志然后开始一个paxos instance的prepare和accept过程。这里的问题是每条redo日志到底对应哪个paxos instance。
Multi Paxos基于Basic Paxos,将原来2-Phase过程简化为了1-Phase,从而加快了提交速度。Multi Paxos要求在各个Proposer中有唯一的Leader,并由这个Leader唯一地提交value给各Acceptor进行表决,在系统中仅有一个Leader进行value提交的情况下,Prepare的过程就可以被跳过,而Leader的选举则可以由Paxos Lease来完成。
Fast Paxos
参考资料:#15
工程实践的角度重新描述了Paxos,使其更贴近应用场景
就是Client的提案由Coordinator进行,Coordinator存在多个,但只能通过其中被选定Leader进行;提案由Leader交由Server进行表决,之后Client作为Learner学习决议的结果。
这种方式更多地考虑了Client/Server这种通用架构,更清楚地注意到了Client既作为Proposer又作为Learner这一事实。
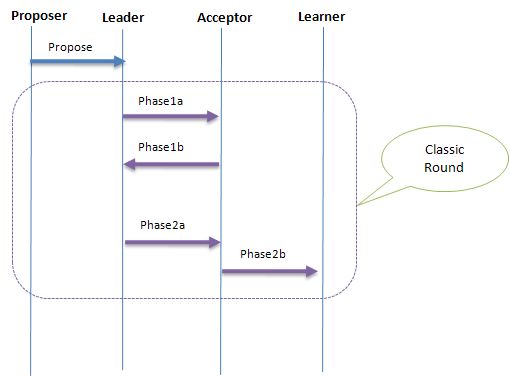
下面是Classic Paxos交互图:
下面是Fast Paxos的交互图:
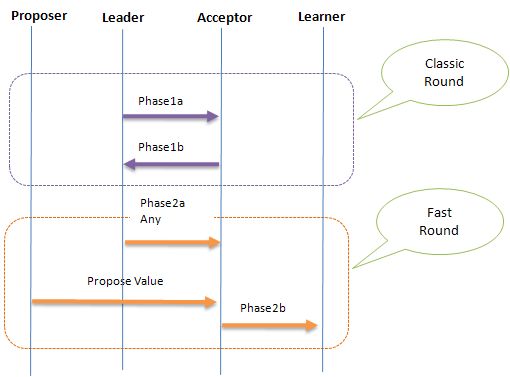
Fast Paxos基本是本着乐观锁的思路:如果存在冲突,则进行补偿。其中Leader起到一个初始化Progress和解决冲突的作用,如果Progress一直执行良好,则Leader将始终不参与一致性过程。
因此Fast Paxos理论上只需要2个通信步骤,而Classic Paxos需要3个,但Fast Paxos在解决冲突时有至少需要1个通信步骤,在高并发的场景下,冲突的概率会非常高,冲突解决的成本也会很大。
另外,Fast Paxos把Client深度引入算法中,致使其架构远没Classic Paxos那么清晰,也没Classic Paxos容易扩展。
实现
libpaxos
虽然libpaxos对PAXOS算法做了基础的实现,但这个库本身不能直接用于生产环境
采用的是libevent单线程reactor模型,无法利用充分利用多CPU的优势,并发上会是个问题。另外,libpaxos并没有实现PAXOS的leader模式。
libpaxos的主要价值是可以用来做研究,可以让程序员对PAXOS的细节了解更加清楚
依赖 libevent 事件驱动、msgpack 序列化库。
数据默认保存在内存,不持久化。也可支持持久化到 bdb 数据库。
分为两个部分
libpaxos 实现 Paxos 算法
libevpaxos 基于 libpaxos 和 libevent 的实现
KeySpace 中的 paxos
见参考资料 #11:Keyspace中的paxos - 老码农的专栏
参考资料
1.https://zh.wikipedia.org/wiki/Paxos算法
2.paxos 算法的理解
- The Part-Time Parliament(Paxos算法)中文、英文
- Paxos Made Simple中文、英文
- Paxos Made Live中文、英文
- Paxos Made Code 中文、英文
7.浅谈分布式系统的基本问题:可用性与一致性
8.知行学社的分布式系统与Paxos算法视频课程 - PaxosLease中文、英文
10.PaxosLease - 老码农的专栏
11.Keyspace中的paxos - 老码农的专栏
12.分布式领域基本概念- Lease
13.分布式系统--Lease机制 - libpaxoshttp://libpaxos.sourceforge.net、https://bitbucket.org/sciascid/libpaxos
15.Fast Paxos - 老码农的专栏