目录:
- 虚拟化
- dpdk的实现研究
- virtio
- vhost
- SR-IOV
- 热迁移相关
- 研究拓展
本文记录近期对dpdk在虚拟化和云计算领域应用的研究成果,内容梳理如下。
虚拟化
虚拟化,抽象来说,就是将物理资源逻辑化。具体来说,虚拟技术的实现是在系统中加入一个虚拟化层(也就是hypervisor),将下层的物理资源(如disk,nic,cpu,memory等)抽象成另一种形式的资源,提供给上层应用,通过空间上的分割,时间上的分时以及模拟,将一份资源抽象成多份。
虚拟化能带来的好处不言而喻,可以显著提高物理资源的使用效率,能够进行动态分配、资源管理和负载的相互隔离,并提供高安全性和自动化。虚拟化还为云计算提供支持,主要提供按需的服务配置和软件定义的资源编排等。
X86平台的虚拟化实现主要有三部分:CPU虚拟化、内存虚拟化和IO虚拟化。
- CPU虚拟化
intel引入VT-x来提升CPU虚拟化效率和虚拟机安全性(参见图1)。VT-x扩展了传统的x86处理器架构,它引入了两种操作模式:VMX root operation(根虚拟化操作)和VMX non-root operation(非根虚拟化操作),统称为VMX操作模式。 此外,还支持虚机热迁移特性。
图1.支持intel VT-x的虚拟化架构
为了建立这种两个操作模式的架构,VT-x设计了一个Virtual-Machine Control Structure(VMCS,虚拟机控制结构)的数据结构,包括了Guest-State Area(客户状态区)和Host-State Area(主机状态区),用来保存虚拟机以及主机的各种状态参数,并提供了VM entry和VM exit两种操作在虚拟机与VMM之间切换,并在切换时会自动查询和更新VMCS,加速guest状态切换时间。这样非根模式下敏感指令不再是直接执行或者通过陷入再模拟的方式执行,而是通过VM exit和VM entry这两个操作完成切换,既解决了虚拟机的隔离问题,又解决了性能问题。
关于VT-x的详细介绍,还可以参考这里和这里。 - 内存虚拟化
内存虚拟化的核心任务是实现地址空间虚拟化,一般的实现原理是这样的:
 图2:地址空间虚拟化实现
图2:地址空间虚拟化实现
通过两次地址转化来支持地址空间虚拟化:GVA(Guest Virtual Address)->GPA(Guest Physical Address)->GMA(Host Physical Address).其中VA->PA的转换由guest完成,通常是通过VMCS中的客户机状态域CR3指向的页表来指定;PA->MA的转换由宿主机完成,一般在guest建立时就分配好固定的物理内存,并采用一定的数据结构记录响应的映射关系。
传统的IA架构只支持一次地址转换,即CR3指向的页表来实现虚拟地址到物理地址的转化(即VA->PA的转化),这和上面的过程中要求的两次地址转换是矛盾的,因此为解决这个问题,Intel引入了VT-x技术,在原有的一次地址转换基础上,又引入了EPT页表实现PA->MA的转换,从而在硬件上支持了两次地址转化,大大提高了地址转换的性能。
关于EPT的工作原理如图3描述::
 图3:EPT工作原理
图3:EPT工作原理
首先根据VA的地址和CR3指向的页表计算出PA,在通过EPT页表实现PA->MA的地址转化。关于内存虚拟化的详细介绍,还可以参考这里和这里。 - IO虚拟化
IO虚拟化包括管理虚拟设备和物理硬件之间的IO请求的路由选择。实现方式可以划分为:全虚拟化、半虚拟化,IO透传,SR-IOV。
其中全虚拟化是指客户机的所有功能或总线结构都可以在宿主机上进行模拟,宿主机通过截获客户机的I/O请求,通过软件来完全模拟硬件。尽管这样模拟得很彻底,但效率却比较低(需要由VMM来捕获特权指令和翻译地址)。
半虚拟化是指客户机能够感知自己是虚拟机,执行特权指令时直接向hypervisor call调用,省去指令的翻译过程,从而提升性能。
I/O透传是指直接将物理设备分配给虚拟使用,这种方式需要硬件平台具备I/O透传技术,能获取到近乎本地的性能,且CPU开销小。透传的使用通常结合intel VT-D来使用。
SR-IOV主要用来解决透传时一个物理硬件只能被一台虚拟子机访问的问题。SR-IOV需要网卡硬件支持,支持SR-IOV功能的网卡(PF)可以在Hypervior里面注册成多个网卡(VF)(每个网卡都独立的中断ID、收发队列、QOS管理机制),每个VF可以通过pass-through方式分配给虚拟子机。
关于这块的资料比较多,就不展开介绍,想了解的可以点这里和这里。
DPDK通过virtio和vhost PMD来实现IO的半虚拟化功能。此外,DPDK还支持I/O透传,SR-IOV等特性,进一步提升IO性能。
除了X86服务器平台的虚拟化,还有些比较重要的领域就是网络虚拟化(NFV)和软件定义网络(SDN)。
- NFV
即网络功能虚拟化,Network Function Virtualization。通过使用x86等通用性硬件以及虚拟化技术,来承载很多功能的软件处理。从而降低网络昂贵的设备成本。可以通过软硬件解耦及功能抽象,使网络设备功能不再依赖于专用硬件,资源可以充分灵活共享,实现新业务的快速开发和部署,并基于实际业务需求进行自动部署、弹性伸缩、故障隔离和自愈等。关于NFV的概念可以参考这里。
其中NFV框架中所有的软件功能都由虚拟的VNF来实现,虚机本身的性能就存在很大的优化空间。当考虑VNF性能时,需要考虑本身的架构设计,以及NFVI能够提供的硬件资源能力和交互接口等等。
一般上在系统整体架构上需要考虑如下几点:- VNF本身特性:计算密集型?IO密集型?内存密集型?有可能是多种特性集一身
- 系统资源的分配:评估VNF或者VNF子模块对处理器、内存、存储、网络的需求
- 网卡虚拟化接口的选择:是否独占物理网卡,独占的化使用透传技术,否则需要共享。还需要考虑接口的性能、迁移性、维护性、安全性等
- 网卡轮询和中断模式的选择:轮询模式CPU占比高,但网络吞吐性能高,100%占有一个core来进行收包是否合理? 中断模式CPU占有率低,但处理小包的性能不高
- 硬件加速功能的考虑:支持硬件卸载的网卡,定制的FPGA,QAT加速卡等是否可以和业务配合使用?
- QOS保证:多VNF运行在同一台服务器时,由于物理资源共享,各VNF对资源的使用率又不尽相同,可能会造成互相干扰性能下降
- 是否需要支持动态迁移:这个对IO,内存,CPU等都会提出特殊要求
- SDN
SDN主要是一种实现网络框架,最重要的三个概念是:可编程(开放的API接口)、控制平面与数据平面分离,以及集中式控制模型。基于SDN的网络架构可以更容易地实现网络虚拟化。关于SDN的概念讨论可以参考这里。
目前DPDK对SDN的支持可以落在以下几个点上:- 对数据转发面的优化,包括提升VNF的性能、和ovs的结合
- SFC(软件服务链)转发性能优化,多个SF之间的数据交互,可以不用过vswitch,而是直接通过virtio-pci进行传输。
DPDK的实现
DPDK对I/O虚拟化的支持主要集中在I/O半虚拟化,通过提供virtio PMD 和 vhost后端加速驱动来提升I/O处理性能;此外,对于SR-IOV虚拟出来的PF和VF也提供了VMDQ来支持,下面来分别展开介绍。
virtio
virtio是一种半虚拟化的设备抽象接口规范,在guest操作系统中实现的前端驱动程序一般直接称为virtio,在host操作系统实现的后端驱动从程序通常称为vhost。与guest端纯软件模拟I/O(如e1000,rt18139)相比,virtio可以提供很好的I/O性能,虽然同I/O透传技术或者SR-IOV技术相比,目前在网络吞吐率、时延以及抖动性各方面相比都不具备优势,相关的优化工作正在进行当中。此外,使用virtio技术可以支持虚拟机的动态迁移以及灵活的流分类规则。
virtio主要有两个版本,0.95和1.0,其规定的实现接口有PCI,MMIO和Channel IO方式,其中Channel IO方式是在1.0版本中新增的。PCI是现代计算机系统中普遍使用的一种总线接口,最新规范为PCI-e,DPDK目前只支持PCI接口方式。
Virtio 使用 virtqueue 来实现其 I/O 机制,每个 virtqueue 就是一个承载大量数据的 queue。vring 是 virtqueue 的具体实现方式,针对 vring 会有相应的描述符表格进行描述。框架如下图所示:

其中比较重要的 几个概念是:
- 设备的配置:初始化、配置PCI设备空间和特性、中断配置和专属配置
- 虚拟队列的配置:virtqueue、vring、descriptor table、avaliable ring和used ring的使用
- 设备的使用
- 驱动向设备提供缓冲区并写入数据
- 设备使用数据及归还缓冲区
关于virtio的基本概念和设备操作可以参考这里,对于补充virtio相关基础知识个人认为介绍的足够了。
dpdk对virtio的实现
virtio在linux内核和dpdk都有相应的驱动,其中linux内核版本功能更加全面,dpdk版本更注重性能。可以先参考下内核中对virtio的实现抽象层次:
- 第一层抽象:底层PCI-e设备层,负责检测PCI-e设备,并初始化设备对应的驱动程序,提供两个抽象类:virtio_driver和virtio_device
- 第二层抽像:中间virio虚拟队列层,实现virtqueue,提供类:vring_virtqueue,vring等
- 第三层抽象:上层网络设备层,实现底层的两个抽象类:virtio_net_driver和dev,能够供应用软件将其看成普通的网口使用
对应的dpdk驱动也是按照这个思路来进行实现的,pmd驱动文件的组成见下图(参考17.05版本,目录为:dpdk-17.05\drivers\net\virtio\):
图6:virtio pmd文件组成
除了上图中框出的文件,还有和virtio_user相关的文件主要用来实现类似KNI的exception path,这块内容放到其它篇幅再继续研究,这里先跳过。
第一层抽象
//drivers\net\virio\virtio_pic.h
/*第一大块:virtio设备的配置相关宏定义*/
/* VirtIO PCI vendor/device ID. */
#define VIRTIO_PCI_VENDORID 0x1AF4
#define VIRTIO_PCI_LEGACY_DEVICEID_NET 0x1000
#define VIRTIO_PCI_MODERN_DEVICEID_NET 0x1041
/*
* VirtIO Header, located in BAR 0
* 具体的相关宏定义可参考virtio设备标准
*/
#define VIRTIO_PCI_HOST_FEATURES 0 /* host's supported features (32bit, RO)*/
#define VIRTIO_PCI_GUEST_FEATURES 4 /* guest's supported features (32, RW) */
#define VIRTIO_PCI_QUEUE_PFN 8 /* physical address of VQ (32, RW) */
#define VIRTIO_PCI_QUEUE_NUM 12 /* number of ring entries (16, RO) */
#define VIRTIO_PCI_QUEUE_SEL 14 /* current VQ selection (16, RW) */
#define VIRTIO_PCI_QUEUE_NOTIFY 16 /* notify host regarding VQ (16, RW) */
#define VIRTIO_PCI_STATUS 18 /* device status register (8, RW) */
#define VIRTIO_PCI_ISR 19 /* interrupt status register, reading
* also clears the register (8, RO) */
/* Only if MSIX is enabled: */
#define VIRTIO_MSI_CONFIG_VECTOR 20 /* configuration change vector (16, RW) */
#define VIRTIO_MSI_QUEUE_VECTOR 22 /* vector for selected VQ notifications
(16, RW) */
/* The bit of the ISR which indicates a device has an interrupt. */
#define VIRTIO_PCI_ISR_INTR 0x1
/* The bit of the ISR which indicates a device configuration change. */
#define VIRTIO_PCI_ISR_CONFIG 0x2
/* Vector value used to disable MSI for queue. */
#define VIRTIO_MSI_NO_VECTOR 0xFFFF
/* VirtIO device IDs. virtio不止有网卡,还有存储、内存等等*/
#define VIRTIO_ID_NETWORK 0x01
#define VIRTIO_ID_BLOCK 0x02
#define VIRTIO_ID_CONSOLE 0x03
#define VIRTIO_ID_ENTROPY 0x04
#define VIRTIO_ID_BALLOON 0x05
#define VIRTIO_ID_IOMEMORY 0x06
#define VIRTIO_ID_9P 0x09
/* Status byte for guest to report progress.
* 当驱动初始化一个virtio设备时,通过设备状态来反应进度
*/
#define VIRTIO_CONFIG_STATUS_RESET 0x00
#define VIRTIO_CONFIG_STATUS_ACK 0x01
#define VIRTIO_CONFIG_STATUS_DRIVER 0x02
#define VIRTIO_CONFIG_STATUS_DRIVER_OK 0x04
#define VIRTIO_CONFIG_STATUS_FEATURES_OK 0x08
#define VIRTIO_CONFIG_STATUS_FAILED 0x80
/*
* Each virtqueue indirect descriptor list must be physically contiguous.
* To allow us to malloc(9) each list individually, limit the number
* supported to what will fit in one page. With 4KB pages, this is a limit
* of 256 descriptors. If there is ever a need for more, we can switch to
* contigmalloc(9) for the larger allocations, similar to what
* bus_dmamem_alloc(9) does.
*
* Note the sizeof(struct vring_desc) is 16 bytes.
*/
#define VIRTIO_MAX_INDIRECT ((int) (PAGE_SIZE / 16))
/* The feature bitmap for virtio net
* 对网卡设备,一些feature的定义
*/
#define VIRTIO_NET_F_CSUM 0 /* Host handles pkts w/ partial csum */
#define VIRTIO_NET_F_GUEST_CSUM 1 /* Guest handles pkts w/ partial csum */
#define VIRTIO_NET_F_MTU 3 /* Initial MTU advice. */
#define VIRTIO_NET_F_MAC 5 /* Host has given MAC address. */
#define VIRTIO_NET_F_GUEST_TSO4 7 /* Guest can handle TSOv4 in. */
#define VIRTIO_NET_F_GUEST_TSO6 8 /* Guest can handle TSOv6 in. */
#define VIRTIO_NET_F_GUEST_ECN 9 /* Guest can handle TSO[6] w/ ECN in. */
#define VIRTIO_NET_F_GUEST_UFO 10 /* Guest can handle UFO in. */
#define VIRTIO_NET_F_HOST_TSO4 11 /* Host can handle TSOv4 in. */
#define VIRTIO_NET_F_HOST_TSO6 12 /* Host can handle TSOv6 in. */
#define VIRTIO_NET_F_HOST_ECN 13 /* Host can handle TSO[6] w/ ECN in. */
#define VIRTIO_NET_F_HOST_UFO 14 /* Host can handle UFO in. */
#define VIRTIO_NET_F_MRG_RXBUF 15 /* Host can merge receive buffers. */
#define VIRTIO_NET_F_STATUS 16 /* virtio_net_config.status available */
#define VIRTIO_NET_F_CTRL_VQ 17 /* Control channel available */
#define VIRTIO_NET_F_CTRL_RX 18 /* Control channel RX mode support */
#define VIRTIO_NET_F_CTRL_VLAN 19 /* Control channel VLAN filtering */
#define VIRTIO_NET_F_CTRL_RX_EXTRA 20 /* Extra RX mode control support */
#define VIRTIO_NET_F_GUEST_ANNOUNCE 21 /* Guest can announce device on the
* network */
#define VIRTIO_NET_F_MQ 22 /* Device supports Receive Flow
* Steering */
#define VIRTIO_NET_F_CTRL_MAC_ADDR 23 /* Set MAC address */
/* Do we get callbacks when the ring is completely used, even if we've
* suppressed them?,暂未实现 */
#define VIRTIO_F_NOTIFY_ON_EMPTY 24
/* Can the device handle any descriptor layout? 用来优化对vring的使用 */
#define VIRTIO_F_ANY_LAYOUT 27
/* We support indirect buffer descriptors */
#define VIRTIO_RING_F_INDIRECT_DESC 28
#define VIRTIO_F_VERSION_1 32
#define VIRTIO_F_IOMMU_PLATFORM 33
/*
* Some VirtIO feature bits (currently bits 28 through 31) are
* reserved for the transport being used (eg. virtio_ring), the
* rest are per-device feature bits.
*/
#define VIRTIO_TRANSPORT_F_START 28
#define VIRTIO_TRANSPORT_F_END 34
/* The Guest publishes the used index for which it expects an interrupt
* at the end of the avail ring. Host should ignore the avail->flags field. */
/* The Host publishes the avail index for which it expects a kick
* at the end of the used ring. Guest should ignore the used->flags field. */
#define VIRTIO_RING_F_EVENT_IDX 29
#define VIRTIO_NET_S_LINK_UP 1 /* Link is up */
#define VIRTIO_NET_S_ANNOUNCE 2 /* Announcement is needed */
/*
* Maximum number of virtqueues per device.
* 底层驱动和设备对queue的支持
*/
#define VIRTIO_MAX_VIRTQUEUE_PAIRS 8
#define VIRTIO_MAX_VIRTQUEUES (VIRTIO_MAX_VIRTQUEUE_PAIRS * 2 + 1)
/* Common configuration */
#define VIRTIO_PCI_CAP_COMMON_CFG 1
/* Notifications */
#define VIRTIO_PCI_CAP_NOTIFY_CFG 2
/* ISR Status */
#define VIRTIO_PCI_CAP_ISR_CFG 3
/* Device specific configuration */
#define VIRTIO_PCI_CAP_DEVICE_CFG 4
/* PCI configuration access */
#define VIRTIO_PCI_CAP_PCI_CFG 5
/*第二大块:相关数据结构,主要是对设备的配置相关*/
/* This is the PCI capability header: */
struct virtio_pci_cap {
uint8_t cap_vndr; /* Generic PCI field: PCI_CAP_ID_VNDR */
uint8_t cap_next; /* Generic PCI field: next ptr. */
uint8_t cap_len; /* Generic PCI field: capability length */
uint8_t cfg_type; /* Identifies the structure. */
uint8_t bar; /* Where to find it. */
uint8_t padding[3]; /* Pad to full dword. */
uint32_t offset; /* Offset within bar. */
uint32_t length; /* Length of the structure, in bytes. */
};
struct virtio_pci_notify_cap {
struct virtio_pci_cap cap;
uint32_t notify_off_multiplier; /* Multiplier for queue_notify_off. */
};
/* Fields in VIRTIO_PCI_CAP_COMMON_CFG: */
struct virtio_pci_common_cfg {
/* About the whole device. */
uint32_t device_feature_select; /* read-write */
uint32_t device_feature; /* read-only */
uint32_t guest_feature_select; /* read-write */
uint32_t guest_feature; /* read-write */
uint16_t msix_config; /* read-write */
uint16_t num_queues; /* read-only */
uint8_t device_status; /* read-write */
uint8_t config_generation; /* read-only */
/* About a specific virtqueue. */
uint16_t queue_select; /* read-write */
uint16_t queue_size; /* read-write, power of 2. */
uint16_t queue_msix_vector; /* read-write */
uint16_t queue_enable; /* read-write */
uint16_t queue_notify_off; /* read-only */
uint32_t queue_desc_lo; /* read-write */
uint32_t queue_desc_hi; /* read-write */
uint32_t queue_avail_lo; /* read-write */
uint32_t queue_avail_hi; /* read-write */
uint32_t queue_used_lo; /* read-write */
uint32_t queue_used_hi; /* read-write */
};
struct virtio_hw;
/*对virtio设备进行操作的函数指针结构*/
struct virtio_pci_ops {
void (*read_dev_cfg)(struct virtio_hw *hw, size_t offset,
void *dst, int len);
void (*write_dev_cfg)(struct virtio_hw *hw, size_t offset,
const void *src, int len);
void (*reset)(struct virtio_hw *hw);
uint8_t (*get_status)(struct virtio_hw *hw);
void (*set_status)(struct virtio_hw *hw, uint8_t status);
uint64_t (*get_features)(struct virtio_hw *hw);
void (*set_features)(struct virtio_hw *hw, uint64_t features);
uint8_t (*get_isr)(struct virtio_hw *hw);
uint16_t (*set_config_irq)(struct virtio_hw *hw, uint16_t vec);
uint16_t (*set_queue_irq)(struct virtio_hw *hw, struct virtqueue *vq,
uint16_t vec);
uint16_t (*get_queue_num)(struct virtio_hw *hw, uint16_t queue_id);
int (*setup_queue)(struct virtio_hw *hw, struct virtqueue *vq);
void (*del_queue)(struct virtio_hw *hw, struct virtqueue *vq);
void (*notify_queue)(struct virtio_hw *hw, struct virtqueue *vq);
};
struct virtio_net_config;
/*底层的device抽象*/
struct virtio_hw {
struct virtnet_ctl *cvq;
uint64_t req_guest_features;
uint64_t guest_features;
uint32_t max_queue_pairs;
uint16_t started;
uint16_t max_mtu;
uint16_t vtnet_hdr_size;
uint8_t vlan_strip;
uint8_t use_msix;
uint8_t modern;
uint8_t use_simple_rxtx;
uint8_t port_id;
uint8_t mac_addr[ETHER_ADDR_LEN];
uint32_t notify_off_multiplier;
uint8_t *isr;
uint16_t *notify_base;
struct virtio_pci_common_cfg *common_cfg;
struct virtio_net_config *dev_cfg;
void *virtio_user_dev;
struct virtqueue **vqs;
};
/*
* While virtio_hw is stored in shared memory, this structure stores
* some infos that may vary in the multiple process model locally.
* For example, the vtpci_ops pointer.
* 针对多核的优化,将常用访问字段放到process的local mem里
*/
struct virtio_hw_internal {
const struct virtio_pci_ops *vtpci_ops;
struct rte_pci_ioport io;
};
#define VTPCI_OPS(hw) (virtio_hw_internal[(hw)->port_id].vtpci_ops)
#define VTPCI_IO(hw) (&virtio_hw_internal[(hw)->port_id].io)
extern struct virtio_hw_internal virtio_hw_internal[RTE_MAX_ETHPORTS];
/*
* This structure is just a reference to read
* net device specific config space; it just a chodu structure
* 这个结构体更像是为上传抽象提供的相关组合字段
*/
struct virtio_net_config {
/* The config defining mac address (if VIRTIO_NET_F_MAC) */
uint8_t mac[ETHER_ADDR_LEN];
/* See VIRTIO_NET_F_STATUS and VIRTIO_NET_S_* above */
uint16_t status;
uint16_t max_virtqueue_pairs;
uint16_t mtu;
} __attribute__((packed));
/*
* How many bits to shift physical queue address written to QUEUE_PFN.
* 12 is historical, and due to x86 page size.
*/
#define VIRTIO_PCI_QUEUE_ADDR_SHIFT 12
/* The alignment to use between consumer and producer parts of vring. */
#define VIRTIO_PCI_VRING_ALIGN 4096
static inline int
vtpci_with_feature(struct virtio_hw *hw, uint64_t bit)
{
return (hw->guest_features & (1ULL << bit)) != 0;
}
/* 第三大块:函数声明,对外提供的操作接口
* Function declaration from virtio_pci.c
*/
int vtpci_init(struct rte_pci_device *dev, struct virtio_hw *hw);
void vtpci_reset(struct virtio_hw *);
void vtpci_reinit_complete(struct virtio_hw *);
uint8_t vtpci_get_status(struct virtio_hw *);
void vtpci_set_status(struct virtio_hw *, uint8_t);
uint64_t vtpci_negotiate_features(struct virtio_hw *, uint64_t);
void vtpci_write_dev_config(struct virtio_hw *, size_t, const void *, int);
void vtpci_read_dev_config(struct virtio_hw *, size_t, void *, int);
uint8_t vtpci_isr(struct virtio_hw *);
/*关于0.95和1.0的版本差异前面已经介绍,具体的ops函数需要区分两个版本分别实现*/
extern const struct virtio_pci_ops legacy_ops;//ver 0.95
extern const struct virtio_pci_ops modern_ops;//ver 1.0
extern const struct virtio_pci_ops virtio_user_ops;
关于实现这块没有太多需要解释的,主要是针对头文件中定义的相关函数和操作进行实现,需要注意的是需要区分legacy和modern两种版本,简单看一个函数具体实现
//drivers\net\virio\virtio_pic.c
/*
* 初始化函数中,需要根据virtio的特性自动识别版本
* Return -1:
* if there is error mapping with VFIO/UIO.
* if port map error when driver type is KDRV_NONE.
* if whitelisted but driver type is KDRV_UNKNOWN.
* Return 1 if kernel driver is managing the device.
* Return 0 on success.
*/
int
vtpci_init(struct rte_pci_device *dev, struct virtio_hw *hw)
{
/*
* Try if we can succeed reading virtio pci caps, which exists
* only on modern pci device. If failed, we fallback to legacy
* virtio handling.
*/
if (virtio_read_caps(dev, hw) == 0) {
PMD_INIT_LOG(INFO, "modern virtio pci detected.");
virtio_hw_internal[hw->port_id].vtpci_ops = &modern_ops;
hw->modern = 1;
return 0;
}
/*如果失败,就尝试绑定legacy操作*/
PMD_INIT_LOG(INFO, "trying with legacy virtio pci.");
if (rte_pci_ioport_map(dev, 0, VTPCI_IO(hw)) < 0) {
//跳过内核管理的virtio
if (dev->kdrv == RTE_KDRV_UNKNOWN &&
(!dev->device.devargs ||
dev->device.devargs->type !=
RTE_DEVTYPE_WHITELISTED_PCI)) {
PMD_INIT_LOG(INFO,
"skip kernel managed virtio device.");
return 1;
}
return -1;
}
virtio_hw_internal[hw->port_id].vtpci_ops = &legacy_ops;
hw->modern = 0;
return 0;
}
第二层抽象
本层中比较重要的数据结构是vring,virtqueue:
//drivers\net\virtio\virtio_ring.h
/* 每个描述符代表guest侧的一个数据缓冲区,供guest和host传递数据。
* 如果要传递的数据大于一个desc的容量,可以包含多个desc,由next串起来*/
struct vring_desc {
uint64_t addr; /* Address (guest-physical). */
uint32_t len; /* Length. */
uint16_t flags; /* The flags as indicated above. */
uint16_t next; /* We chain unused descriptors via this. */
};
/* id is a 16bit index. uint32_t is used here for ids for padding reasons. */
struct vring_used_elem {
/* Index of start of used descriptor chain. */
uint32_t id;
/* Total length of the descriptor chain which was written to. */
uint32_t len;
};
/* vring的布局:num个vring_desc + available ring size + pad + used ring size
* The standard layout for the ring is a continuous chunk of memory which
* looks like this. We assume num is a power of 2.
* NOTE: for VirtIO PCI, align is 4096.
*/
struct vring {
// The actual descriptors (16 bytes each)
struct vring_desc desc[num];
/*可用环表,由驱动提供(写入),设备使用(读取)。*/
__u16 avail_flags;
__u16 avail_idx;
__u16 available[num];
__u16 used_event_idx;
// Padding to the next align boundary.
char pad[];
/*已用环表,由设备提供(写入),驱动使用(读取)*/
__u16 used_flags;
__u16 used_idx;
struct vring_used_elem used[num];
__u16 avail_event_idx;
};
/*vring size的计算公式*/
vring_size(unsigned int num, unsigned long align)
{
size_t size;
size = num * sizeof(struct vring_desc);
size += sizeof(struct vring_avail) + (num * sizeof(uint16_t));
size = RTE_ALIGN_CEIL(size, align);
size += sizeof(struct vring_used) +
(num * sizeof(struct vring_used_elem));
return size;
}
关于available ring和used ring中的flags字段,需要特别解释下:
- available ring flag:该环中的desc可能是可读,也可能是可写的。可写的是指驱动提供给设备的desc,供设备写入后还需要传回给驱动;可读的则是用于发送驱动的数据到设备中。flag可以用来标示设备在使用了desc后是否发送中断给驱动。
- used ring flag:表示已用环表的一些属性,包括是否需要驱动在回收了已用环表中的表项后发送提醒给设备。
//drivers\net\virtio\virtqueue.h
struct virtqueue {
struct virtio_hw *hw; /**< virtio_hw structure pointer. */
struct vring vq_ring; /**< vring keeping desc, used and avail */
/**
* Last consumed descriptor in the used table,
* trails vq_ring.used->idx.
*/
uint16_t vq_used_cons_idx;
uint16_t vq_nentries; /**< vring desc numbers */
uint16_t vq_free_cnt; /**< num of desc available */
uint16_t vq_avail_idx; /**< sync until needed */
uint16_t vq_free_thresh; /**< free threshold */
void *vq_ring_virt_mem; /**< linear address of vring*/
unsigned int vq_ring_size;
/*用途,是收包,发包还是控制通道?*/
union {
struct virtnet_rx rxq;
struct virtnet_tx txq;
struct virtnet_ctl cq;
};
phys_addr_t vq_ring_mem; /**< physical address of vring,
* or virtual address for virtio_user. */
/**
* Head of the free chain in the descriptor table. If
* there are no free descriptors, this will be set to
* VQ_RING_DESC_CHAIN_END.
*/
uint16_t vq_desc_head_idx;
uint16_t vq_desc_tail_idx;
uint16_t vq_queue_index; /**< PCI queue index */
uint16_t offset; /**< relative offset to obtain addr in mbuf,具体使用可以参见宏VIRTIO_MBUF_ADDR*/
uint16_t *notify_addr;
struct rte_mbuf **sw_ring; /**< RX software ring. */
struct vq_desc_extra vq_descx[0];
};
//todo:对virtqueue的使用接口
每个设备拥有多个 virtqueue 用于大块数据的传输。virtqueue 是一个简单的队列(其中包括vring),guest 把 buffers 插入其中,每个 buffer 都是一个分散-聚集数组。virtqueue 的数目根据设备的不同而不同,例如network 设备通常有 2 个 virtqueue,一个用于发送数据包,一个用于接收数据包。
第三层抽象
本层实现virtio设备以及对设备的各种操作函数。对virtio设备的初始化配置以及特性设置主要集中在virtio_ethdev.c中实现。
这一步的实现代码比较多,仅罗列一些比较重要的,感兴趣的可深入阅读相关接口。
/*驱动初始化virtio设备
* 重新设置rte_eth_dev结构及特性,最大化共用基础结构,而没有重新定义一个virtio dev structure
* 在这个接口里还会和host进行feature的协商,为device申请分配virtqueue,配置中断等等
*/
eth_virtio_dev_init(struct rte_eth_dev *eth_dev);
/*为device分配virtqueue,首先获取支持的最大队列,再对每个队列执行初始化*/
virtio_alloc_queues(struct rte_eth_dev *dev);
/*具体的一个队列初始化函数,在这个函数里会区分队列类型,是收包,发包还是控制队列*/
static int virtio_init_queue(struct rte_eth_dev *dev, uint16_t vtpci_queue_idx)
/*另外比较重要的是,通过以上初始话过程,会赋值设备的dev_ops,rx_pkt_burst,tx_pkt_burst*/
eth_dev->dev_ops = &virtio_eth_dev_ops;
eth_dev->tx_pkt_burst = &virtio_xmit_pkts;
rx_func_get(struct rte_eth_dev *eth_dev)
{
struct virtio_hw *hw = eth_dev->data->dev_private;
if (vtpci_with_feature(hw, VIRTIO_NET_F_MRG_RXBUF))
eth_dev->rx_pkt_burst = &virtio_recv_mergeable_pkts;//如果打开mergeable特性的化
else
eth_dev->rx_pkt_burst = &virtio_recv_pkts;//普通的收包函数
}
设备初始化好后,virtio设备的使用主要包括两部分:驱动通过描述符列表和可用环表提供数据缓冲区给设备,设备使用数据缓冲区再通过已用环表还给驱动。以网卡为例:网络设备一般有两个vq:发包队列和接收队列。驱动添加要发送的包到发送队列,然后设备读取并发送完成后,驱动再释放这些包。反方向,设备将包写入到接收队列中,驱动则在已用环表中处理这些包。
先看收包函数:
//drivers\net\virtio\virtio_rxtx.c
uint16_t
virtio_recv_pkts(void *rx_queue, struct rte_mbuf **rx_pkts, uint16_t nb_pkts)
{
...
num = (uint16_t)(likely(nb_used <= nb_pkts) ? nb_used : nb_pkts);
num = (uint16_t)(likely(num <= VIRTIO_MBUF_BURST_SZ) ? num : VIRTIO_MBUF_BURST_SZ);
if (likely(num > DESC_PER_CACHELINE))
num = num - ((vq->vq_used_cons_idx + num) % DESC_PER_CACHELINE);
/*驱动一次性从收包队列中获取num个报文,实际上是读取已用环表获取描述符,
*读取完成后需要释放desc到free chain中
*/
num = virtqueue_dequeue_burst_rx(vq, rcv_pkts, len, num);
PMD_RX_LOG(DEBUG, "used:%d dequeue:%d", nb_used, num);
/*将前面读出来的报文赋值到二级指针rx_pkts中*/
for (i = 0; i < num ; i++) {
rxm = rcv_pkts[i];
PMD_RX_LOG(DEBUG, "packet len:%d", len[i]);
if (unlikely(len[i] < hdr_size + ETHER_HDR_LEN)) {
PMD_RX_LOG(ERR, "Packet drop");
nb_enqueued++;
virtio_discard_rxbuf(vq, rxm);
rxvq->stats.errors++;
continue;
}
rxm->port = rxvq->port_id;
rxm->data_off = RTE_PKTMBUF_HEADROOM;
rxm->ol_flags = 0;
rxm->vlan_tci = 0;
rxm->pkt_len = (uint32_t)(len[i] - hdr_size);
rxm->data_len = (uint16_t)(len[i] - hdr_size);
hdr = (struct virtio_net_hdr *)((char *)rxm->buf_addr +
RTE_PKTMBUF_HEADROOM - hdr_size);
if (hw->vlan_strip)
rte_vlan_strip(rxm);
if (offload && virtio_rx_offload(rxm, hdr) < 0) {
virtio_discard_rxbuf(vq, rxm);
rxvq->stats.errors++;
continue;
}
VIRTIO_DUMP_PACKET(rxm, rxm->data_len);
/*把报文dump出来到rx_pkts*/
rx_pkts[nb_rx++] = rxm;
rxvq->stats.bytes += rxm->pkt_len;
virtio_update_packet_stats(&rxvq->stats, rxm);
}
.....
/* 重新对used descriptor分配mbuf,并插入到可用队列中 */
error = ENOSPC;
while (likely(!virtqueue_full(vq))) {
new_mbuf = rte_mbuf_raw_alloc(rxvq->mpool);
if (unlikely(new_mbuf == NULL)) {
struct rte_eth_dev *dev
= &rte_eth_devices[rxvq->port_id];
dev->data->rx_mbuf_alloc_failed++;
break;
}
error = virtqueue_enqueue_recv_refill(vq, new_mbuf);
if (unlikely(error)) {
rte_pktmbuf_free(new_mbuf);
break;
}
nb_enqueued++;
}
/*可用队列更新后,要通知host端设备*/
if (likely(nb_enqueued)) {
vq_update_avail_idx(vq);
if (unlikely(virtqueue_kick_prepare(vq))) {
virtqueue_notify(vq);
PMD_RX_LOG(DEBUG, "Notified");
}
}
return nb_rx;
}
再看发包函数:
virtio_xmit_pkts(void *tx_queue, struct rte_mbuf **tx_pkts, uint16_t nb_pkts)
{
......
virtio_rmb();//加锁
/*如果已用环表空间不足,将已经传输完成的释放掉*/
if (likely(nb_used > vq->vq_nentries - vq->vq_free_thresh))
virtio_xmit_cleanup(vq, nb_used);
for (nb_tx = 0; nb_tx < nb_pkts; nb_tx++) {
struct rte_mbuf *txm = tx_pkts[nb_tx];
int can_push = 0, use_indirect = 0, slots, need;
...
/* 实际的发包函数,将txm中的数据通过txvq发送出去 */
virtqueue_enqueue_xmit(txvq, txm, slots, use_indirect, can_push);
txvq->stats.bytes += txm->pkt_len;
virtio_update_packet_stats(&txvq->stats, txm);
}
txvq->stats.packets += nb_tx;
/*通知host*/
if (likely(nb_tx)) {
vq_update_avail_idx(vq);
if (unlikely(virtqueue_kick_prepare(vq))) {
virtqueue_notify(vq);
PMD_TX_LOG(DEBUG, "Notified backend after xmit");
}
}
return nb_tx;
}
virtqueue_enqueue_xmit(struct virtnet_tx *txvq, struct rte_mbuf *cookie,
uint16_t needed, int use_indirect, int can_push)
{
....
do {
start_dp[idx].addr = VIRTIO_MBUF_DATA_DMA_ADDR(cookie, vq);
start_dp[idx].len = cookie->data_len;
start_dp[idx].flags = cookie->next ? VRING_DESC_F_NEXT : 0;
idx = start_dp[idx].next;
} while ((cookie = cookie->next) != NULL);
if (use_indirect)
idx = vq->vq_ring.desc[head_idx].next;
vq->vq_desc_head_idx = idx;
if (vq->vq_desc_head_idx == VQ_RING_DESC_CHAIN_END)
vq->vq_desc_tail_idx = idx;
vq->vq_free_cnt = (uint16_t)(vq->vq_free_cnt - needed);
//把cookie内容放入desc中,更新可用环表
vq_update_avail_ring(vq, head_idx);
}
关于virtio的其它学习资料,还可以参考这里以及这里。
vhost
vhost就是virtio-net的后端驱动,关于dpdk vhost这部分资料总结和介绍,可以参考之前整理的文档:
- dpdk vhost研究(一)
- dpdk vhost研究(二)
- dpdk vhost研究(三)
SR-IOV
SR-IOV 是PCI-SIG的一个IOV的规范,目的是提供一种标准规范,通过为虚拟机提供独立的内存空间,中断,DMA流,来绕过VMM实现数据移动。SR-IOV 架构被设计用于将单个设备通过支持多个VF,并减少硬件的开销。
SR-IOV 引入了两种类型:
- PF: 包含完整的PCIe 功能,包括SR-IOV的扩展能力,其包含用于配置和管理 SR-IOV 的功能。可以使用 PF 来配置和控制 PCIe 设备,且 PF 具有将数据移入和移出设备的完整功能。
- FV: 包含轻量级的PCIe 功能。其包含数据移动所需的所有资源,且具有一套经过仔细精简的配置资源集。
要实现SRIOV功能,前提条件就是网卡硬件首先要支持SRIOV,其次主板要支持intel VT-d技术。
SR-IOV的结构图实现如下:

以上图为例逐个解释关键词:
- PF就是物理网卡所支持的一项PCI功能,PF可以扩展出若干个VF
- VF是支持SRIOV的物理网卡所虚拟出的一个“网卡”或者说虚出来的一个实例,它会以一个独立网卡的形式呈现出来,每一个VF有它自己独享的PCI配置区域,并且可能与其他VF共享着同一个物理资源(公用同一个物理网口)
- PF miniport driver即PF驱动是工作于Hyper-V虚拟化平台父区域的,并在VF之前最先加载
- VF miniport driver即VF驱动是工作于Hyper-V虚拟化平台子区域的,即guestOS;需要注意的是,VF及PF之间是隔离的,任何经由VF驱动或所执行的结果都不会影响到其他的VF或PF
- Network Interface Card即物理网卡,在启用SRIOV之后会生成若干vport,物理NIC所要做的就是转发physical port与vport之间的流量
- physical port顾名思义就是物理网口,在SRIOV场景中physical port充当一个面向对外的网络媒介
- VPort是个抽象出来的接口,类似于物理网口,它们被映射给每一个VF或者PF,供parentOS或guestOS来使用
启用SRIOV之后,物理NIC将通过VF与虚拟机(VF driver)进行数据交互,反之亦然。那么这样一来即可跳过中间的虚拟化堆栈(即VMM层),以达到近乎于纯物理环境的性能;这一点也是SRIOV最大的价值所在。
关于更详细的介绍资料和实验数据对比,可以参考这里和这里
关于dpdk使用SR-IOV的参考资料在这里。
摘自上面的资料,使用SR_IOV技术和纯物理机,以及用户态的ovs性能对比如下:
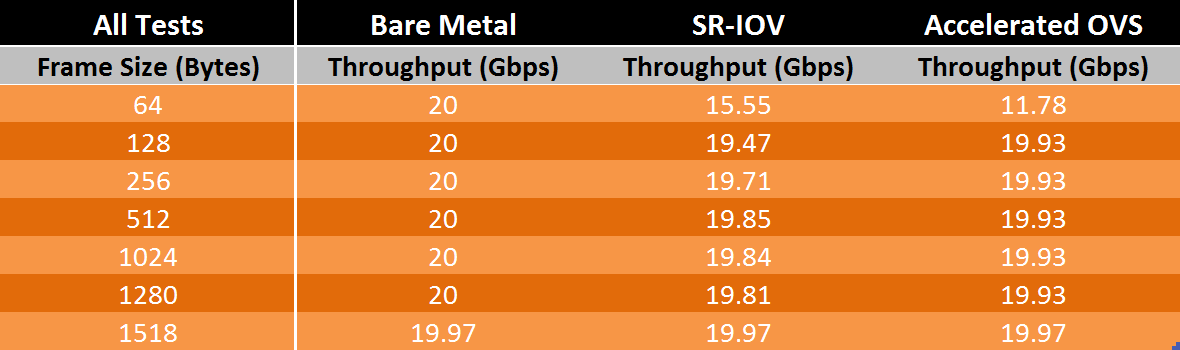
比较典型的IMIX流量中小包占比会在50%~60%之间,从上表可以看到SR-IOV的测试数据中小包处理能力在70%左右,这就表明该技术在实际的使用环境中能够应对绝大多数场景;而OVS在此方面的优化还需要继续努力。
另外关于dpdk使用SR-IOV的配置,可以参考如下:
热迁移相关
从上面的介绍了解,要使用DPDK技术,在VM中可以使用virtio驱动,也可以使用硬件网卡提供的SR-IOV VF来支持。对于热迁移来说,就需要针对两种驱动单独考虑。
如何使用
DPDK关于使用两种驱动的测试用例在官网有提供,可以参考:
- Live Migration of VM with SR-IOV VF,由于这种驱动是硬件提供switch来完成报文到VF的分发,很难去感知VM的迁移,因此需要借助其他技术来实现迁移,文中提到的使用bond口就是当前的实现方案
- Live Migration of Vm with Virtio on host running vhost-user,这种驱动中使用的vswitch功能,因此还是比较好实现VM的迁移的。
结合ovs的测试方法,可以参考这里。
代码相关支持
对代码的修改主要是由以下patch来完成:
- Patch 1 handles VHOST_USER_SET_LOG_BASE, which tells us where
the dirty memory bitmap is.
//通过mmap将要迁移的dirty memory设置成shared状态,可供对端读写
static int
vhost_user_set_log_base(struct virtio_net *dev, struct VhostUserMsg *msg)
{
int fd = msg->fds[0];
uint64_t size, off;
void *addr;
if (fd < 0) {
RTE_LOG(ERR, VHOST_CONFIG, "invalid log fd: %d\n", fd);
return -1;
}
if (msg->size != sizeof(VhostUserLog)) {
RTE_LOG(ERR, VHOST_CONFIG,
"invalid log base msg size: %"PRId32" != %d\n",
msg->size, (int)sizeof(VhostUserLog));
return -1;
}
size = msg->payload.log.mmap_size;
off = msg->payload.log.mmap_offset;
RTE_LOG(INFO, VHOST_CONFIG,
"log mmap size: %"PRId64", offset: %"PRId64"\n",
size, off);
/*
* mmap from 0 to workaround a hugepage mmap bug: mmap will
* fail when offset is not page size aligned.
*/
addr = mmap(0, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
close(fd);
if (addr == MAP_FAILED) {
RTE_LOG(ERR, VHOST_CONFIG, "mmap log base failed!\n");
return -1;
}
/*
* Free previously mapped log memory on occasionally
* multiple VHOST_USER_SET_LOG_BASE.
*/
if (dev->log_addr) {
munmap((void *)(uintptr_t)dev->log_addr, dev->log_size);
}
dev->log_addr = (uint64_t)(uintptr_t)addr;
dev->log_base = dev->log_addr + off;
dev->log_size = size;
return 0;
}
- Patch 2 introduces a vhost_log_write() helper function to log
pages we are gonna change. 对端vm通过同步这些page即可完成状态的迁移。
//rte_vhost_log_write->vhost_log_write
static inline void __attribute__((always_inline))
vhost_log_write(struct virtio_net *dev, uint64_t addr, uint64_t len)
{
uint64_t page;
if (likely(((dev->features & (1ULL << VHOST_F_LOG_ALL)) == 0) ||
!dev->log_base || !len))
return;
if (unlikely(dev->log_size <= ((addr + len - 1) / VHOST_LOG_PAGE / 8)))
return;
/* To make sure guest memory updates are committed before logging */
rte_smp_wmb();
page = addr / VHOST_LOG_PAGE;
while (page * VHOST_LOG_PAGE < addr + len) {
vhost_log_page((uint8_t *)(uintptr_t)dev->log_base, page);
page += 1;
}
}
static inline void __attribute__((always_inline))
vhost_log_page(uint8_t *log_base, uint64_t page)
{
log_base[page / 8] |= 1 << (page % 8);
}
- Patch 3 logs changes we made to used vring.
//rte_vhost_log_used_vring->vhost_log_used_vring
static inline void __attribute__((always_inline))
vhost_log_used_vring(struct virtio_net *dev, struct vhost_virtqueue *vq,
uint64_t offset, uint64_t len)
{
vhost_log_write(dev, vq->log_guest_addr + offset, len);
}
- Patch 4 sets log_shmfd protocol feature bit, which actually
enables the vhost-user live migration support.
#define VHOST_USER_PROTOCOL_F_LOG_SHMFD 1
#define VHOST_USER_PROTOCOL_FEATURES ((1ULL << VHOST_USER_PROTOCOL_F_MQ) | \
(1ULL << VHOST_USER_PROTOCOL_F_LOG_SHMFD) |\
(1ULL << VHOST_USER_PROTOCOL_F_RARP) | \
(0ULL << VHOST_USER_PROTOCOL_F_REPLY_ACK) | \
(1ULL << VHOST_USER_PROTOCOL_F_NET_MTU))
RARP报文
构造免费ARP报文RARP来解决vm迁移后的丢包问题
研究拓展
TODO
(ovs+dpdk,SPDK,SFC,DPACC)