这章我们将深入Forth的引擎内部,了解其底层机制
这里可能重复介绍些我们以前已经接触过的机制,为了从整体上审视Forth底层机制,重复介绍下也是有必要的
1 解释器内部
在第一章我们介绍到Forth解释器会从输入流中截取word,然后在字典中查找其定义,如果找到这个word的定义,就会执行这个word定义的操作
我们自己也可以使用组成解释器(INTERPRET)的组件来实现这些分步操作。一个重要的word'将会在字典中查找word然后返回word对应的执行token。
以曾经定义的wordGREET为例
' GREET U. return-key 输出(4956608 ok)
这个输出值就是GREET的执行token
我们也可以间接调用EXECUTE ,这样解释器(INTERPRET)将会执行一个数字栈提供的可运行token(xt)。
' GREET EXECUTE return-key 输出(Hello, I speak Forth ok)
这个和直接输入GREET的效果相同,不过这个绕了路。
如果'查找word失败,那么将会使用ABORT"报错。
Forth的文本解释器使用'查找word时将会返回真假标志flag。因此解释器(INTERPRET)的基本结构看做如下的模式
(find the word) IF (查找word成功执行 execute the word)
ELSE (查找word失败时 convert to a number)
THEN
可以使用' GREET . 输出GREET的地址而不执行
也可以使用xt与DUMP的结合输出定义的内容
' GREET 12 CELLS DUMP
2 向量运行
除了可以执行xt处的定义,我们可以将xt存储到变量中,然后运行这个word
' GREET pointer ! pointer @ EXECUTE
将会存储GREETd的xt到ponitner,然后返回pointer的内容地址,并运行
最为关键的是我们可以在后面修改这个pointer的内容,这样一来一个word就可以运行不同的内容
' 通常回去从输入流中查找下个word的xt。如果使用在:定义中时。它也只会从输入流中查找word。而不会查找定义中的word地址
如果想要在定义中使用',我们可以使用[]
: COMING ['] HELLO 'aloha !
: GOING ['] GOODBYE 'aloha !
将会在定义中查找word
3 字典结构机制
我们曾经使用的定义词: VAIAVLKE VALUE CREATE等在内存中使用相同的基本结构
name field
link field
code pointer field
data filed
可以使用变量DATE作为例子。字典中的结构如下
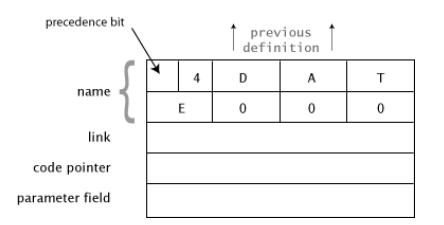
本书我们只关注这些结构组织,忽略其顺序组织。
name 字段
在DATE的name字段中首先是name的长度,然后是name的各个字母。
需要注意的是name的第一个bit位,用来区别立即word和普通word
link 字段
Link的字段中保存着字典序列中上一个定义的地址。这些link用来在字典中搜索word。
每次编译器在字典中添加一个word将会将link字段设置为上一个定义的地址。
搜索的时候 '将会从最近定义的word开始沿着link链搜索,直到查找成功或者到达最早的定义 。通常最早定义位置包含一个0.用来返回给'查找word失败信息
code pointer字段
code pinter字段非常重要,用来区分variable,constant,colon等定义的word的不同。
这里保存一个地址 指向特定类型的word在运行时会执行的指令组合
变量Variable的code pointer字段存储的地址,指向一段代码,将会将变量的地址存储到数字栈(stack)
常量Constant的code pointer字段存储的地址,指向一段代码,将会将常量的内容存储到数字栈(stack)。因此常量内容一旦定义是无法修改的。
分号定义的code pointer字段存储的地址,指向一段代码,将会运行编译到word中的xt序列。
这种机制可以通过各种方式实现。
这段code称为运行时code,因为经常用在word运行期间。
所有的变量共享相同的code pointer
所有的常量共享相同的code pointer
Data field字段
紧接着code pointer的是Data 字段,
在变量和常量的Data字段通常只包含一个cell。
而在2Variable和2Constant中的Data字段通常包含两个cell。
数组中的Data字段可以包含需要长度的cell
在一个分号定义中,Data字段的长度根据定义的内容,
事实上现代的forth中分号定义word并不会包含Data字段
4 分号的基本结构
字典中不同类型的定义的name,link 和code pointer基本相似,而data字段通常包含具体的不同内容,接下来详细介绍分号定义word的data字段
分号定义word的data字段中包含word定义时包含在其中word的xt序列。
这里以PHOTOGRAPH为例
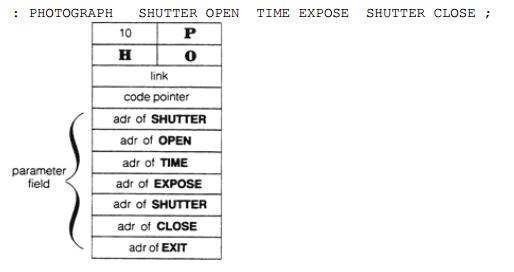
当PHOTOGRAPH运行时,code pointer指向的代码段将会依次运行data字段包含的xt序列。
这种读取定义中xt序列并运行的机制称为地址解释器
分号定义中的;也就是EXIT.通常分号处于字典定义的最后,因此运行的时候最好会调用EXIT,终止这个地址运行器,这个会在下节介绍运行层次嵌套
5 嵌套的运行层次
EXITword用来修改运行流,从当前word返回到高层次的word中,这一节介绍这个返回机制
以DINNER的定义为例
: DINNER SOUP ENTREE DESSERT ;,其中的ENTREE如下组成
: ENTREE CHICKEN RIC ;.
因此DINNER在字典中的布局如下

因此当我们运行DINNER定义在刚完成SOUP的时候,接下来我们的地址解释器将会指向ENTREE,我们的解释器将会从ENTREE的地址中获取xt。
可以将这个地址解释器看做一个xts列表的子调用。在Forth的return栈中保存着调用完成的返回地址。而EXIT的工作就是从子调用返回的指令
调用栈组织
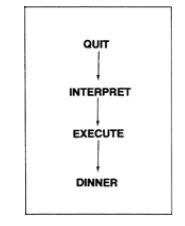
解释扩展
也需要会疑惑,当我们最终从DINNER中EXIT的时候,我们从返回栈中获取的返回地址是什么,我们将返回到哪里呢?
我们从前面可知 DINNER是由EXECUTE执行其xt开始的。因此EXECUTE就是DINNER的调用者,而这个EXECUTE又是在INTERPRET中调用的,INTERPRET构成一个检测输入数据流的循环。
如果我们在DINNER后输入了回车键,那么解释器机会认为DINNER解释运行完后没有可以解释的,将会退出解释器INTERPRET。那么这时我们将退回到哪里?事实上整个Forth终端的最外层的调用称为QUIT。其中的调用层次如上图
QUIT的基本结构可以看做如下定义
: QUIT
BEGIN (clear return stack)
(accept input)
INTERPRET
." ok " CR
AGAIN ;
在解释器INTERPRET运行完后,返回ok并换行。
然后再次返回到QUIT开头,清空返回栈等待再次输入内容
如果我们直接调用QUIT,我们会立即结束整个运行,并且返回到QUIT的开头,清空返回栈等待的输入内容。而ABORT" 就是使用了QUIT。
跳出循环
我们也可以在定义的中间嵌入EXIT用户跳出循环
: ENTREE CHIKEN EXIT RICE ;
运行流程如下

6 Forth的内存布局
到此我们需要简单介绍下Forth的内存布局
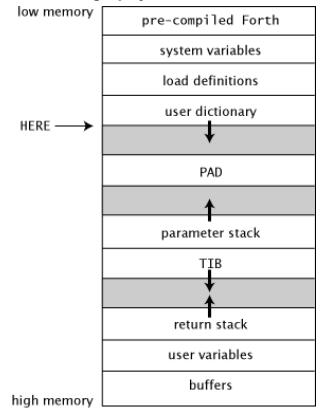
一个Forth虚拟机的内存可用简单划分为总体划分为3部分
一部分是数据字典功能
一部分是过程运行功能
一部分是输入输出功能
1 数据字典功能
pre-compiled Forth : Forth依赖的底层预定义接口
sys variables :Forth由底层接口创建的在整个系统中应用的变量
load definitions Forth通过文件导入的定义字典,有关导入定义id组织需要使用Vocabularies机制
user dictionary Forth用户数据字典核心。其向下扩展。在数据字典中当前可用存储地址叫做CP(current pointer)。在整个编译过程中,CP会按照cell的大小逐渐增加作为新的定义入口。因此CP是编译的字典标签。存储着接下来的编译可用的字典地址
CP 这个地址值会在ALLOT中使用,ALLOT会将CP增加字节
5 CELLS ALLOT将会使得CP增加5个cell大小(32位机器也就是4字节),
另外CP还会在HERE中用到: HERE CP @ ;可用看出CP也是一个地址,存储着当前字典可用地址,HERE获取CP地址的内容,存储到数字栈(stack)。其中CP的存储在下面介绍的用户变量(user variables)中。
另外,会使用HERE。,将一个值存储字典当前可用位置。因此定义为
: , HERE ! CELL ALLOT ;
可用使用HERE来判断应用从开始到运行结束后所需要的内存空间
**user variables 上面的CP 等就是存储在用户变量中的,可用发生变动,用户变量还包含TIB #TIB SCR BASE CP >IN BLK等等用户变量
用户变量不同于普通变量,普通变量存储在用户字典或者导入字典中。每一个用户变量存储在用户变量表,字典入口对于每个用户变量会定位到其他位置,其body存储一个指向用户表的偏移位置,
因此可以使用@!来对用户变量进行操作
最为常用的用户变量BASE定义了数的基数,比如2进制8进制10进制就是修改BASE得到的
用户变量使用USER定义,因此包含三类变量系统变量 用户变量 普通变量
2 运行功能
运行功能包含两个栈
数字栈(parameter stack) 存储word的操作对象与结果
运行栈(return stack) 存储运行过程的返回地址与运行控制信息
3 输入输出功能
PAD 在距离HERE的固定距离的内存位置,有一块区域成为PAD。正如一个便签本(缓存器)用来存储ASCII字符编码,在输出信息到终端前进行转义处理。例如数字格式word正是使用PAD存储ASCII数字编码转换在TYPE之前
这个PAD的大小是不确定的。大多数Forth包括到数字栈顶部。
因为PAD根据HERE定义,因此随着定义增多PAD的地址会发生变化,可以使用PAD 返回当前pad的开始地址
其中的输入输出关键部分在下一节介绍
TIB
**buffers