Prometheus 是什么?
Prometheus是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的。随着发展,越来越多公司和组织接受采用Prometheus,社区也十分活跃,他们便将它独立成开源项目,并且有公司来运作。google SRE的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus。现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控。
Prometheus 的优点
- 非常少的外部依赖,安装使用超简单
- 已经有非常多的系统集成 例如:docker HAProxy Nginx JMX等等
- 服务自动化发现
- 直接集成到代码
- 设计思想是按照分布式、微服务架构来实现的
Prometheus 的特性
- 自定义多维度的数据模型
- 非常高效的存储 平均一个采样数据占 ~3.5 bytes左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G。
- 强大的查询语句
- 轻松实现数据可视化
架构图

组件介绍
Prometheus生态系统由多个组件组成。其中许多组件都是可选的
Promethus server
- 必须安装,
- 本质是一个时序数据库
- 主要负责数据pull、存储、分析
Push Gateway
- 非必选项
- 支持临时性Job主动推送指标的中间网关
exporters
- 部署在客户端的agent,如 node_exporte, mysql_exporter等
alertmanager
- 用来进行报警,Promethus server 经过分析, 把出发的警报发送给 alertmanager 组件,alertmanager 组件通过自身的规则,来发送通知,(邮件,或者webhook)
接下来就是实战啦
本章内容
mkdir /opt/monitor/ -p
cd /opt/monitor/
wget https://github.com/x82423990/prometheus/archive/v2.0.0.tar.gz
tar xf v2.0.0.tar.gz
cd prometheus-2.0.linux-amd64
# 运行
# ./prometheus &
通过启动日志,可以看到 Prometheus Server 默认端口是 9090。
当 Prometheus 启动后,你可以通过浏览器来访问
http://IP:9090,将看到如下页面
在默认配置中,我们已经添加了 Prometheus Server 的监控,所以我们现在可以使用PromQL(Prometheus Query Language)来查看,比如

so , 既然他是一个数据库, 我们来简单的了解他的数据结构及他的数据模型
Prometheus 存储的是时序数据, 即按照相同时序(相同的名字和标签),以时间维度存储连续的数据的集合。
时序索引
时序(time series) 是由名字(Metric),以及一组 key/value 标签定义的,具有相同的名字以及标签属于相同时序。
时序的名字由 ASCII 字符,数字,下划线,以及冒号组成,它必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*, 其名字应该具有语义化,一般表示一个可以度量的指标,例如 http_requests_total, 可以表示 http 请求的总数。
时序的标签可以使 Prometheus 的数据更加丰富,能够区分具体不同的实例,例如 http_requests_total{method="POST"} 可以表示所有 http 中的 POST 请求。
标签名称由 ASCII 字符,数字,以及下划线组成, 其中 __ 开头属于 Prometheus 保留,标签的值可以是任何 Unicode 字符,支持中文。
时序样本
按照某个时序以时间维度采集的数据,称之为样本,其值包含:
- 一个 float64 值
- 一个毫秒级的 unix 时间戳
格式
Prometheus 时序格式与 OpenTSDB 相似:
{ 其中包含时序名字以及时序的标签。
作业和实例
prometheus 中,将任意一个独立的数据源(target)称之为实例(instance)。包含相同类型的实例的集合称之为作业(job)。
如下是一个含有四个重复实例的作业:
- job: api-server
- instance 1: 1.2.3.4:5670
- instance 2: 1.2.3.4:5671
- instance 3: 5.6.7.8:5670
- instance 4: 5.6.7.8:5671
自生成标签和时序
prometheus 在采集数据的同时,会自动在时序的基础上添加标签,作为数据源(target)的标识,以便区分:
job: The configured job name that the target belongs to.
instance: The : part of the target's URL that was scraped.
如果其中任一标签已经在此前采集的数据中存在,那么将会根据 honor_labels 设置选项来决定新标签。详见官网解释: scrape configuration documentation
对每一个实例而言,prometheus 按照以下时序来存储所采集的数据样本:
up{job="", instance=""}: 1 表示该实例正常工作
up{job="", instance=""}: 0 表示该实例故障
scrape_duration_seconds{job="", instance=""} 表示拉取数据的时间间隔
scrape_samples_post_metric_relabeling{job="", instance=""} 表示采用重定义标签(relabeling)操作后仍然剩余的样本数
scrape_samples_scraped{job="", instance=""} 表示从该数据源获取的样本数
其中 up 时序可以有效应用于监控该实例是否正常工作。
时序 4 种类型
Prometheus 时序数据分为 Counter, Gauge, Histogram, Summary 四种类型。
Counter
Counter 表示收集的数据是按照某个趋势(增加/减少)一直变化的,我们往往用它记录服务请求总量,错误总数等。
例如 Prometheus server 中 http_requests_total, 表示 Prometheus 处理的 http 请求总数,可以使用 delta, 很容易得到任意区间数据的增量。
Gauge
Gauge 表示搜集的数据是一个瞬时的,与时间没有关系,可以任意变高变低,往往可以用来记录内存使用率、磁盘使用率等。
例如 Prometheus server 中 go_goroutines, 表示 Prometheus 当前 goroutines 的数量。
Histogram
Histogram 由
例如 Prometheus server 中 prometheus_local_storage_series_chunks_persisted, 表示 Prometheus 中每个时序需要存储的 chunks 数量,我们可以用它计算待持久化的数据的分位数。
Summary
Summary 和 Histogram 类似,由
例如 Prometheus server 中 prometheus_target_interval_length_seconds。
Histogram vs Summary
- 都包含
_sum _count - Histogram 需要通过
_bucket
PromQL 基本使用
PromQL (Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力非常丰富,内置函数很多,在日常数据可视化,rule 告警中都会使用到它。
我们可以在页面 http://localhost:9090/graph 中,输入下面的查询语句,查看结果,例如:
http_requests_total{code="200"}
字符串和数字
字符串: 在查询语句中,字符串往往作为查询条件 labels 的值,和 Golang 字符串语法一致,可以使用 "", '', 或者 ``, 格式如:
"this is a string"
'these are unescaped: \n \\ \t'
`these are not unescaped: \n ' " \t`
正数,浮点数: 表达式中可以使用正数或浮点数,例如:
3
-2.4
查询结果类型
PromQL 查询结果主要有 3 种类型:
- 瞬时数据 (Instant vector): 包含一组时序,每个时序只有一个点,例如:
http_requests_total - 区间数据 (Range vector): 包含一组时序,每个时序有多个点,例如:
http_requests_total[5m] - 纯量数据 (Scalar): 纯量只有一个数字,没有时序,例如:
count(http_requests_total)
查询条件
Prometheus 存储的是时序数据,而它的时序是由名字和一组标签构成的,其实名字也可以写出标签的形式,例如 http_requests_total 等价于 {name="http_requests_total"}。
一个简单的查询相当于是对各种标签的筛选,例如:
http_requests_total{code="200"} // 表示查询名字为 http_requests_total,code 为 "200" 的数据
查询条件支持正则匹配,例如:
http_requests_total{code!="200"} // 表示查询 code 不为 "200" 的数据
http_requests_total{code=~"2.."} // 表示查询 code 为 "2xx" 的数据
http_requests_total{code!~"2.."} // 表示查询 code 不为 "2xx" 的数据
操作符
Prometheus 查询语句中,支持常见的各种表达式操作符,例如
算术运算符:
支持的算术运算符有 +,-,*,/,%,^, 例如 http_requests_total * 2 表示将 http_requests_total 所有数据 double 一倍。
比较运算符:
支持的比较运算符有 ==,!=,>,<,>=,<=, 例如 http_requests_total > 100 表示 http_requests_total 结果中大于 100 的数据。
逻辑运算符:
支持的逻辑运算符有 and,or,unless, 例如 http_requests_total == 5 or http_requests_total == 2 表示 http_requests_total 结果中等于 5 或者 2 的数据。
聚合运算符:
支持的聚合运算符有 sum,min,max,avg,stddev,stdvar,count,count_values,bottomk,topk,quantile,, 例如 max(http_requests_total) 表示 http_requests_total 结果中最大的数据。
注意,和四则运算类型,Prometheus 的运算符也有优先级,它们遵从(^)> (*, /, %) > (+, -) > (==, !=, <=, <, >=, >) > (and, unless) > (or) 的原则。
内置函数
Prometheus 内置不少函数,方便查询以及数据格式化,例如将结果由浮点数转为整数的 floor 和 ceil,
floor(avg(http_requests_total{code="200"}))
ceil(avg(http_requests_total{code="200"}))
查看 http_requests_total 5分钟内,平均每秒数据
rate(http_requests_total[5m])
更多请参见详情。
与 SQL 对比
下面我将以 Prometheus server 收集的 http_requests_total 时序数据为例子展开对比。
MySQL 数据准备
mysql>
# 创建数据库
create database prometheus_practice;
use prometheus_practice;
# 创建 http_requests_total 表
CREATE TABLE http_requests_total (
code VARCHAR(256),
handler VARCHAR(256),
instance VARCHAR(256),
job VARCHAR(256),
method VARCHAR(256),
created_at DOUBLE NOT NULL,
value DOUBLE NOT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE http_requests_total ADD INDEX created_at_index (created_at);
# 初始化数据
# time at 2017/5/22 14:45:27
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "query_range", "localhost:9090", "prometheus", "get", 1495435527, 3);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("400", "query_range", "localhost:9090", "prometheus", "get", 1495435527, 5);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "prometheus", "localhost:9090", "prometheus", "get", 1495435527, 6418);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "static", "localhost:9090", "prometheus", "get", 1495435527, 9);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("304", "static", "localhost:9090", "prometheus", "get", 1495435527, 19);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "query", "localhost:9090", "prometheus", "get", 1495435527, 87);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("400", "query", "localhost:9090", "prometheus", "get", 1495435527, 26);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "graph", "localhost:9090", "prometheus", "get", 1495435527, 7);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "label_values", "localhost:9090", "prometheus", "get", 1495435527, 7);
# time at 2017/5/22 14:48:27
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "query_range", "localhost:9090", "prometheus", "get", 1495435707, 3);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("400", "query_range", "localhost:9090", "prometheus", "get", 1495435707, 5);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "prometheus", "localhost:9090", "prometheus", "get", 1495435707, 6418);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "static", "localhost:9090", "prometheus", "get", 1495435707, 9);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("304", "static", "localhost:9090", "prometheus", "get", 1495435707, 19);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "query", "localhost:9090", "prometheus", "get", 1495435707, 87);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("400", "query", "localhost:9090", "prometheus", "get", 1495435707, 26);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "graph", "localhost:9090", "prometheus", "get", 1495435707, 7);
INSERT INTO http_requests_total (code, handler, instance, job, method, created_at, value) values ("200", "label_values", "localhost:9090", "prometheus", "get", 1495435707, 7);
数据初始完成后,通过查询可以看到如下数据:
mysql>
mysql> select * from http_requests_total;
+------+--------------+----------------+------------+--------+------------+-------+
| code | handler | instance | job | method | created_at | value |
+------+--------------+----------------+------------+--------+------------+-------+
| 200 | query_range | localhost:9090 | prometheus | get | 1495435527 | 3 |
| 400 | query_range | localhost:9090 | prometheus | get | 1495435527 | 5 |
| 200 | prometheus | localhost:9090 | prometheus | get | 1495435527 | 6418 |
| 200 | static | localhost:9090 | prometheus | get | 1495435527 | 9 |
| 304 | static | localhost:9090 | prometheus | get | 1495435527 | 19 |
| 200 | query | localhost:9090 | prometheus | get | 1495435527 | 87 |
| 400 | query | localhost:9090 | prometheus | get | 1495435527 | 26 |
| 200 | graph | localhost:9090 | prometheus | get | 1495435527 | 7 |
| 200 | label_values | localhost:9090 | prometheus | get | 1495435527 | 7 |
| 200 | query_range | localhost:9090 | prometheus | get | 1495435707 | 3 |
| 400 | query_range | localhost:9090 | prometheus | get | 1495435707 | 5 |
| 200 | prometheus | localhost:9090 | prometheus | get | 1495435707 | 6418 |
| 200 | static | localhost:9090 | prometheus | get | 1495435707 | 9 |
| 304 | static | localhost:9090 | prometheus | get | 1495435707 | 19 |
| 200 | query | localhost:9090 | prometheus | get | 1495435707 | 87 |
| 400 | query | localhost:9090 | prometheus | get | 1495435707 | 26 |
| 200 | graph | localhost:9090 | prometheus | get | 1495435707 | 7 |
| 200 | label_values | localhost:9090 | prometheus | get | 1495435707 | 7 |
+------+--------------+----------------+------------+--------+------------+-------+
18 rows in set (0.00 sec)
基本查询对比
假设当前时间为 2017/5/22 14:48:30
- 查询当前所有数据
// PromQL
http_requests_total
// MySQL
SELECT * from http_requests_total WHERE created_at BETWEEN 1495435700 AND 1495435710;
我们查询 MySQL 数据的时候,需要将当前时间向前推一定间隔,比如这里的 10s (Prometheus 数据抓取间隔),这样才能确保查询到数据,而 PromQL 自动帮我们实现了这个逻辑。
- 条件查询
// PromQL
http_requests_total{code="200", handler="query"}
// MySQL
SELECT * from http_requests_total WHERE code="200" AND handler="query" AND created_at BETWEEN 1495435700 AND 1495435710;
- 模糊查询: code 为 2xx 的数据
// PromQL
http_requests_total{code~="2xx"}
// MySQL
SELECT * from http_requests_total WHERE code LIKE "%2%" AND created_at BETWEEN 1495435700 AND 1495435710;
- 比较查询: value 大于 100 的数据
// PromQL
http_requests_total > 100
// MySQL
SELECT * from http_requests_total WHERE value > 100 AND created_at BETWEEN 1495435700 AND 1495435710;
- 范围区间查询: 过去 5 分钟数据
// PromQL
http_requests_total[5m]
// MySQL
SELECT * from http_requests_total WHERE created_at BETWEEN 1495435410 AND 1495435710;
聚合, 统计高级查询
- count 查询: 统计当前记录总数
// PromQL
count(http_requests_total)
// MySQL
SELECT COUNT(*) from http_requests_total WHERE created_at BETWEEN 1495435700 AND 1495435710;
- sum 查询: 统计当前数据总值
// PromQL
sum(http_requests_total)
// MySQL
SELECT SUM(value) from http_requests_total WHERE created_at BETWEEN 1495435700 AND 1495435710;
- avg 查询: 统计当前数据平均值
// PromQL
avg(http_requests_total)
// MySQL
SELECT AVG(value) from http_requests_total WHERE created_at BETWEEN 1495435700 AND 1495435710;
- top 查询: 查询最靠前的 3 个值
// PromQL
topk(3, http_requests_total)
// MySQL
SELECT * from http_requests_total WHERE created_at BETWEEN 1495435700 AND 1495435710 ORDER BY value DESC LIMIT 3;
- irate 查询,过去 5 分钟平均每秒数值
// PromQL
irate(http_requests_total[5m])
// MySQL
SELECT code, handler, instance, job, method, SUM(value)/300 AS value from http_requests_total WHERE created_at BETWEEN 1495435700 AND 1495435710 GROUP BY code, handler, instance, job, method;
总结
通过以上一些示例可以看出,在常用查询和统计方面,PromQL 比 MySQL 简单和丰富很多,而且查询性能也高不少。
Prometheus Web
Prometheus 自带了 Web Console, 安装成功后可以访问 http://localhost:9090/graph 页面,用它可以进行任何 PromQL 查询和调试工作,非常方便,例如:
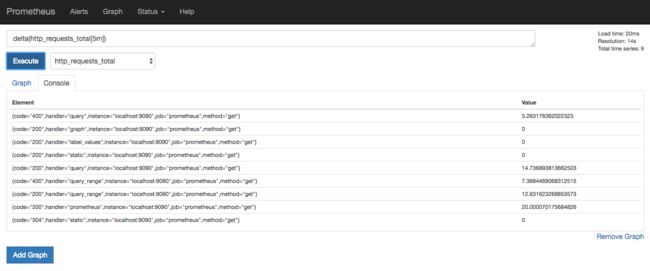

通过上图你不难发现,Prometheus 自带的 Web 界面比较简单,因为它的目的是为了及时查询数据,方便 PromeQL 调试。
它并不是像常见的 Admin Dashboard,在一个页面尽可能展示多的数据,如果你有这方面的需求,不妨试试 Grafana。
Grafana 使用
Grafana 是一套开源的分析监视平台,支持 Graphite, InfluxDB, OpenTSDB, Prometheus, Elasticsearch, CloudWatch 等数据源,其 UI 非常漂亮且高度定制化。
这是 Prometheus web console 不具备的,在上一节中我已经说明了选择它的原因。
版本说明
- Mac version 4.3.2
安装和运行程序
这里我使用 brew 安装,命令为
brew update
brew install grafana
当安装成功后,你可以使用默认配置启动程序
grafana-server -homepath /usr/local/Cellar/grafana/4.3.2/share/grafana/
如果顺利,你将看到如下日志
INFO[06-11|15:20:14] Starting Grafana logger=main version=4.3.2 commit=unknown-dev compiled=2017-06-01T05:47:48+0800
INFO[06-11|15:20:14] Config loaded from logger=settings file=/usr/local/Cellar/grafana/4.3.2/share/grafana/conf/defaults.ini
INFO[06-11|15:20:14] Path Home logger=settings path=/usr/local/Cellar/grafana/4.3.2/share/grafana/
INFO[06-11|15:20:14] Path Data logger=settings path=/usr/local/Cellar/grafana/4.3.2/share/grafana/data
INFO[06-11|15:20:14] Path Logs logger=settings path=/usr/local/Cellar/grafana/4.3.2/share/grafana/data/log
INFO[06-11|15:20:14] Path Plugins logger=settings path=/usr/local/Cellar/grafana/4.3.2/share/grafana/data/plugins
INFO[06-11|15:20:14] Initializing DB logger=sqlstore dbtype=sqlite3
INFO[06-11|15:20:14] Starting DB migration logger=migrator
INFO[06-11|15:20:14] Executing migration logger=migrator id="copy data account to org"
INFO[06-11|15:20:14] Skipping migration condition not fulfilled logger=migrator id="copy data account to org"
INFO[06-11|15:20:14] Executing migration logger=migrator id="copy data account_user to org_user"
INFO[06-11|15:20:14] Skipping migration condition not fulfilled logger=migrator id="copy data account_user to org_user"
INFO[06-11|15:20:14] Starting plugin search logger=plugins
INFO[06-11|15:20:14] Initializing Alerting logger=alerting.engine
INFO[06-11|15:20:14] Initializing CleanUpService logger=cleanup
INFO[06-11|15:20:14] Initializing Stream Manager
INFO[06-11|15:20:14] Initializing HTTP Server logger=http.server address=0.0.0.0:3000 protocol=http subUrl= socket=
此时,你可以打开页面 http://localhost:3000, 访问 Grafana 的 web 界面。
其他平台安装方案,请参考更多安装。
登录并设置 Prometheus 数据源
Grafana 本身支持 Prometheus 数据源,故不需要安装其他插件。
使用默认账号 admin/admin 登录 grafana

在 Dashboard 首页,点击添加数据源
配置 Prometheus 数据源
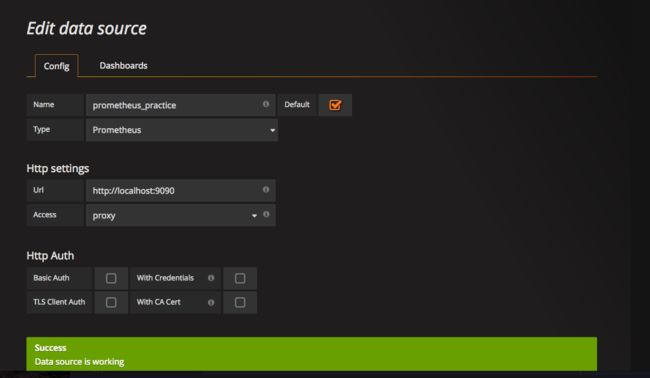
目前为止,Grafana 已经和 Prometheus 连上了,你将看到这样的 Dashboard

自定义监视画板
由顶部 Manage dashboard -> Settings 进入管理页面

在管理页面中取消 Hide Controls
点击页面底部 + ADD ROW 按钮, 并选择 Graph 类型

点击 Panel Title -> Edit 进入 Panel 编辑页面,并在 Metrics 中
的 Metric lookup 选择 go_goroutines

你也可以直接在管理界面中填写 Prometheus 的查询语句,以及修改查询的 step 数值。
当你修改了 Dashboard 后,记得点击顶部的 Save dashboard 按钮,或直接 CTRL+S 保存。
至此,我们自定义的 Panel 已添加完成

我们可以通过拖拽,拉升调节 panel 的位置和尺寸,我们调节的目的是尽量在一个屏幕显示更多信息。
总结
Grafana 是一款非常漂亮,强大的监视分析平台,本身支持了 Prometheus 数据源,所以在做数据和监视可视化的时候,Grafana + Prometheus 是个不错的选择。
全局配置
global 属于全局的默认配置,它主要包含 4 个属性,
- scrape_interval: 拉取 targets 的默认时间间隔。
- scrape_timeout: 拉取一个 target 的超时时间。
- evaluation_interval: 执行 rules 的时间间隔。
- external_labels: 额外的属性,会添加到拉取的数据并存到数据库中。
配置文件结构大概为:
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # By default, scrape targets every 15 seconds.
scrape_timeout: 10s # is set to the global default (10s).
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'