- Abstract
We present an online visual tracking algorithm by managing multiple target appearance models in a tree structure. The proposed algorithm employs Convolutional Neural Networks (CNNs) to represent target appearances, where multiple CNNs collaborate to estimate target states and determine the desirable paths for online model updates in the tree. By maintaining multiple CNNs in diverse branches of tree structure, it is convenient to deal with multi-modality in target appearances and preserve model reliability through smooth updates along tree paths.
The final target state is estimated by sampling target candidates around the state in the previous frame and identifying the best sample in terms of a weighted average score from a set of active CNNs.
- Introduction
Most existing tracking algorithms update the target model assuming that target appearances change smoothly over time. However, this strategy may not be appropriate for handling more challenging situations such as occlusion, illumination variation, abrupt motion and deformation, which may break temporal smoothness assumption. Some algorithms employ multiple models[38, 28, 40], multi-modal representations [11] or nonlinear classifiers [10, 12] to address these issues. However, the constructed models are still not strong enough and online model updates are limited to sequential learning in a temporal order, which may not be able to make the models sufficiently discriminative and diverse.
However, online learning with CNNs is not straightforward because neural networks tend to forget previously learned information quickly when they learn new information [27]. This property often incurs drift problem especially when background information contaminates target appearance models, targets are completely occluded by other objects, or tracking fails temporarily. This problem may be alleviated by maintaining multiple versions of target appearance models constructed at different time steps and updating a subset of models selectively to keep a history of target appearances. This idea has been investigated in [22], where a pool of CNNs are used to model target appearances, but it does not consider the reliability of each CNN to estimate target states and update models.
We propose an online visual tracking algorithm, which estimates target state using the likelihoods obtained from multiple CNNs. The CNNs are maintained in a tree structure and updated online along the path in the tree. Since each path keeps track of a separate history about target appearance changes, the proposed algorithm is effective to handle multi-modal target appearances and other exceptions such as short-term occlusions and tracking failures. In addition, since the new model corresponding to the current frame is constructed by fine-tuning the CNN that produces the highest likelihood for target state estimation, more consistent and reliable models are to be generated through online learning only with few training examples.
The main contributions of our paper are summarized below:
• We propose a visual tracking algorithm to manage target appearance models based on CNNs in a tree structure, where
the models are updated online along the path in the tree. This strategy enables us to learn more persistent models
through smooth updates.
• Our tracking algorithm employs multiple models to capture diverse target appearances and performs more robust
tracking even with challenges such as appearance changes, occlusions, and temporary tracking failures.
- Related Works
Tracking-by-detection approaches formulate visual tracking as a discriminative object classification problem in a sequence of video frames. The techniques in this category typically learn classifiers to differentiate targets from surrounding backgrounds.
Tracking algorithms based on hand-crafted features [15, 38] often outperform CNN-based approaches. This is partly because CNNs are difficult to train using noisy labeled data online while they are easy to overfit to a small number of training examples; it is not straightforward to apply CNNs to visual tracking problems involving online learning. For example, the performance of [22], which is based on a shallow custom neural network, is not as successful as recent tracking algorithms based on shallow feature learning. However, CNN-based tracking algorithms started to present competitive accuracy in the online tracking benchmark [37] by transferring the CNNs pretrained on ImageNet [8].
Multiple models are often employed in generative tracking algorithms to handle target appearance variations and recover from tracking failures. Trackers based on sparse representation [28, 40] maintain multiple target templates to compute the likelihood of each sample by minimizing its reconstruction error while [21] integrates multiple observation models via an MCMC framework. Nam et al. [29] integrates patch-matching results from multiple frames and estimates the posterior of target state. On the other hand, ensemble classifiers have sometimes been applied to visual tracking problem. Tang et al. [32] proposed a co-tracking framework based on two support vector machines. An ensemble of weak classifiers is employed to estimate target states in [1, 3]. Zhang et al. [38] presented a framework based on multiple snapshots of SVM-based trackers to recover from tracking failures.
- Algorithm Overview
Our algorithm maintains multiple target appearance models based on CNNs in a tree structure to preserve model consistency and handle appearance multi-modality effectively. The proposed approach consists of two main components as in ordinary tracking algorithms—state estimation and model update—whose procedures are illustrated in Figure 1. Note that both components require interaction between multiple CNNs.
When a new frame is given, we draw candidate samples around the target state estimated in the previous frame, and compute the likelihood of each sample based on the weighted average of the scores from multiple CNNs. The weight of each CNN is determined by the reliability of the path along which the CNN has been updated in the tree structure. The target state in the current frame is estimated by finding the candidate with the maximum likelihood. After
tracking a predefined number of frames, a new CNN is derived from an existing one, which has the highest weight among the contributing CNNs to target state estimation. This strategy is helpful to ensure smooth model updates and maintain reliable models in practice.
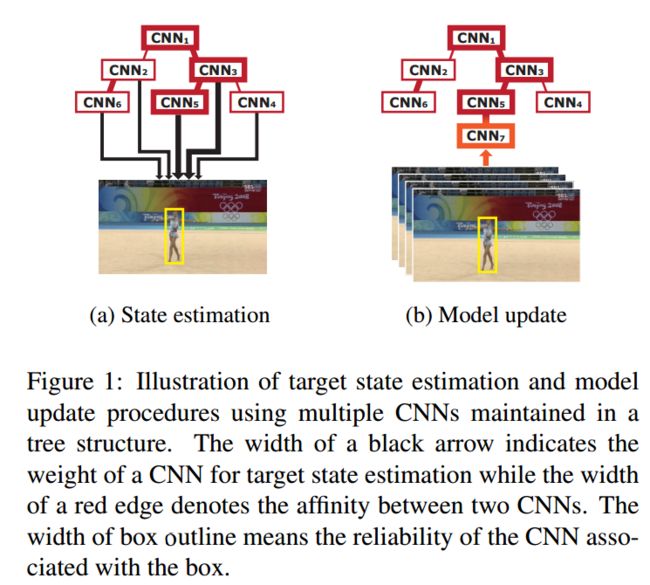
Our approach has something in common with [22], which employs a candidate pool of multiple CNNs. It selects k nearest CNNs based on prototype matching distances for tracking. Our algorithm is differentiated from this approach since it is more interested in how to keep multimodality of multiple CNNs and maximize their reliability by introducing a novel model maintenance technique using a tree structure. Visual tracking based on a tree-structured graphical model has been investigated in [13], but this work is focused on identifying the optimal density propagation path for offline tracking. The idea in [29] is also related, but it mainly discusses posterior propagation on directed acyclic graphs for visual tracking.
- Proposed Algorithm
5.1 CNN Architecture
Our network consists of three convolutional layers and three fully connected layers. The convolution filters are identical to the ones in VGG-M network [4] pretrained on ImageNet [8]. The last fully connected layer has 2 units for binary classification while the preceding two fully connected layers are composed of 512 units. All weights in these three layers are initialized randomly. The input to our network is a 75 × 75 RGB image and its size is equivalent to the receptive field size of the only single unit (per channel) in the last convolutional layer. Note that, although we borrow the convolution filters from VGG-M network, the size of our network is smaller than the original VGG-M network. The output of an input image x is a normalized vector [φ(x), 1 − φ(x)]T , whose elements represent scores for target and background, respectively.
5.2 Tree Construction
We maintain a tree structure to manage hierarchical multiple target appearance models based on CNNs. In the tree structure T = {V, E}, a vertex v ∈ V corresponds to a CNN and a directed edge (u, v) ∈ E defines the relationship between CNNs. The score of an edge (u, v) is the affinity between two end vertices, which is given by
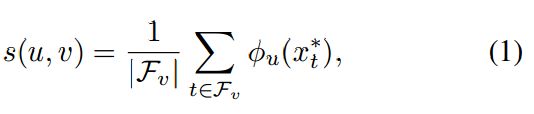
where Fv is a set of consecutive frames that is used to train the CNN associated with v, x^∗_t is the estimated target state at frame t, and φu(·) is the predicted positive score with respect to the CNN in u.
5.3. Target State Estimation using Multiple CNNs