(近来有点小忙,更新慢了。想想说到第多少式了?接下来继续)。
第21式:CALCULATE的列表关系函数(基础部分)
在本系列的前面部分中,我们说明了DAX的数据摸型是由一个个单列表构成的,但并没有说明这些列表之间是靠什么连接(联系)在一起的。结论是:DAX的列表之间是通过列表关系连接在一起的。理解列表关系的最简单的方式是,将数据模型想象为一个个列表组合在一起的一个整体表,其中的连接方式就是列表关系。
(创建列表关系(仅指列表物理关系)的方法也相当简单,将表间的关系键列表连接起来即可。这里对于列表关系不作重点)。
所以,我们说,DAX的数据模型其实际就是由列表+关系构成。
列表关系包括你在数据模型里创建的物理关系,以及根据需要由函数定义的虚拟列表关系等,后面再详讲。这里为衔接前面的DAX的常见函数,先了解:DAX的列表关系函数。
你可以使用关系函数生成包含跨多个表的值列表表达式(其实只是一个关系连接的整体表,前期为了表述方便,我们这样描叙),DAX 将直接返回这些函数的每个结果,而不会考虑其中关系链的长度。
DAX 和 Excel 公式语言的一个显著区别是 :DAX 允许在表达式之间传递整个表,而不仅限于单个值(单元格)。DAX 的其中一项强大功能是:允许你在其表达式中筛选表格,然后使用筛选后的列表集。这就是我们所说的:写一个完整的DAX公式或DAX计算单元,总是需要先考虑列表(列表),然后再是值列表--即先“引用”再“定义 ” 。
通过 DAX,你可以创建全新的计算表,然后像处理其他表格一样处理它们 -- 包括在这些表和存在于你的数据模型中的其他表之间建立关系。
DAX 的列表函数
DAX 提供一套丰富的表函数,包括:
•FILTER
•ALL
•VALUES
•DISTINCT
• RELATED、RELATEDTABLE 等等
这些函数的结果都返回一个完整的列表,而不是每个单一的值。
通常,你会在进一步的分析中将表函数的结果(而不是返回的每个最终值)作为更大的某个表达式的一部分使用。
特别值得注意的是,使用这类表函数时,其结果将继承其元列表的关系。
这里需要注意的是,任何一个列表都包含其列表所在的关系,而值列表则不涉及到关系。比如,列表筛选会通过列表关系传递而筛选到关系列表,值列表筛选(行筛选)则不传递关系。这是列表和值列表的另一个关键的行为区别。 反之,如果一个列表在筛选中传递了关系,那么,这是一个列表筛选。
1、你可以在任意一个表达式中混合使用表函数,前提是每一个表达式只能使用一个表并返回一个表。
例如下面的 DAX 表达式:
FILTER (ALL (Table), Condition)
该表达式将筛选整个表(含全部行值的列表--Table),而忽略当前筛选的任何内容(即当前筛选不可见)。与ALL( )不同的是,DISTINCT( )函数返回一个列表的不同的唯一值,这些值在当前筛选中可见。
因此,以上述 DAX 表达式为例,在表达式中使用 ALL( ) 将会忽略筛选(严格也说,相当于由ALL()引用的表或列表,使用或保留了其所有列值的全集完整性。
ALL()即可作为列表(结果为该表所有行)被引用(如与新的筛选列表构建新的列表子集);同时也可作为列表筛选:由于其列值总为全集列表,用它筛选数据模型里任何列表都将不起作用,从而达到忽略某个表或列表的筛选功能。例如:
FILTER (Table, ALL (Date)
这里使用了ALL(Date)作为Table表的筛选列表(两个表之间存在关系),由于ALL()的结果是一个整体表(全集列表),使用它筛选任何列表或关系列表,都是不起作用的,从而达到避免Date表的任何列表对Table表做出筛选。
我们还经常需要 FILTER ( ALL (Date),Table)) 的写法,这与FILTER (Table, ALL (Date)只是ALL()的位置不同(即筛选的方向不同),本例中两个公式中的参数使用的都为列表(全集列表),无论如何筛选,都不起作用。
更多的是FILTER ( ALL (Date),Table)) 这种模式下起作用的情形,基于先引用列表,再定义值列表的规则,ALL (Date)引用的是全集列表(ALL函数功能),如果要筛选它,只能定义一个值列表(比如一个布尔值值列表),例如:
FILTER ( ALL (Date),Table[地区]=“华南区”))
这里使用Table表的子集值列表来筛选ALL (Date)表,以构成一个新的列表子集。当然你还可能添加AND“并”的更多筛选。
由于列表关系总会传递,实际上任何列表筛选都会传递到它的关系列表,从而也会筛选到这些关系列表(列值会变化--列值范围将缩小)。使用ALL (Date)则维护了其含全部列值)的列表形态(被筛选或筛选),而始终不是值列表。 如果我们使用另一个列表函数: DISTINCT或VALUES来替换ALL,则可得到一个非全集的列表(唯一值的列表)以作为筛选或被筛选列表。
我们常使用ALL()来引用一个全集的列表(一个或多个列表的筛选),即排除该列表上的任何筛选。例如,下图中,我们排除[MonthNum]列的筛选作用后(使用了ALL()),透视表中的月份筛选(透视表的行)结果将是同一个值。因为,我们说,这时候的行、列筛选相同。ALL( )删除了所有该列表上的筛选器,右列中的每个度量值单元都将与左列中的Grand Total(小计值)具有完全相同的筛选器 (行、列筛选)。
我们认为,你也可以把ALL()当作一种手段:即“引用”了一个透视表中的全部单元格。只要能从根本上理解它,你所做的就是从当前筛选器中清除/移除每个筛选器。
[All Month Net Sales] =CALCULATE( [Net Sales], ALL( Sales[MonthNum] ) )
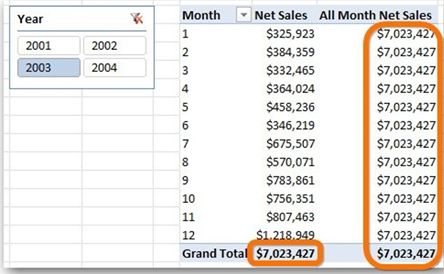
ALL()是很有用的。例如最常见的作为分子/分母的百分比计算:让我们做一个简单的比率计算,假如这两个指标已经在透视表上:
[Pct of All Month Net Sales] =[Net Sales] / [AllMonth Net Sales]
该新度量计算:将"每个月"与“整个月”的度量值相比较(分母是整个月的一个恒定的值)。 我们可以从数据轴上移除原始的所有其他度量值,新的[Pct ofAll Month Net Sales]仍然有效。
最后,你可以思考一下:既然ALL( )的功能是取得表或列表的全集,那么,直接引用列表也能达到该目的,为什么不直接引用列表?这至少说明ALL()函数能直接引用表或一个列表,然后目的是为了实现"使筛选不起作用"的功能。后面将专门有一式祥述ALL()以及与该函数的类似系列函数。 请注意接下来的一式中的解释。
2、RELATED是最常见的DAX列表关系函数。
RELATED可以与建立了关系的列表进行关连互动,返回列值(值列表),或者使用 DAX 函数定义以返回某一关系列表中的值列表。而另一个列表关系函数RELATEDTABLE 依照关系返回经过筛选的只包含相关行的整个表。
我们已经知道,行筛选不会自动通过关系传递。因而需要通过使用RELATED 和 RELATEDTABLE来手动进行传递。正确使用这些功能的前提是列表具有一对多关系: RELATED用于关系的多端,RELATEDTABLE用于关系的一端。即你可以理解为:RELATED 函数处理的是多对一的关系,而 RELATEDTABLE 函数处理的是一对多的关系。
你可以在前面的系列的“行筛选和关系” 一式中了解更多的关于这两个函数的实例。
第22式:CALCULATE 对列值(行)进行计数(列表的非完整性)。
1、Power BI 报表中希望回答的一个常见问题是: 我可以对该列表设置多少个值(值列表)?
如果针对的是一个表,那么,这是一个很好回答的简单问题。但是,DAX会采用其他方式来计算该值,尤其是在表之间存在关系时。
例如,DAX中包含未正确建立交叉索引的值时,如果传入关系已损坏,DAX会将新行添加到关系列表中每个字段都为空值的位置,并将其链接到未建立索引的行,以确保列表引用的完整性。这是DAX关系数据模型的一个很清晰但却最容易导致理解困难的地方。
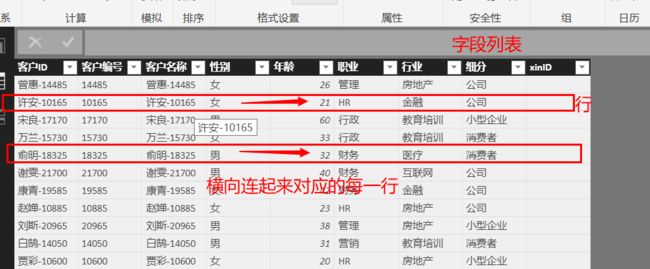
如果函数包含空白行(这在使用 ALL( ) 时经常出现,因为该函数的结果是表或列表的全集--全部列值)。那么,列表的返回值数目中将包含这些空白行。也就是说,DAX关系型数据模型列表总是具有相同的行(即所有列表的行具有“一一对应”式的对齐,后面将称为行索引……)。例如,一个只有一行一值的列表与一个100行100个值的列表如果具有关系,那么,一行一值的列表需要重复99次或用99个空值补齐99个行位来与100个行值的列表进行"行对齐"。如果有更多单列表的数据模型,则必须同时具有相同的行数,而且数据模型的每一行都是唯一值。
我们将这些数据模型中一个或多个列中所对应的每一行(横向连接)称之为数据模型的一行。所以,你不能用普通的单元格或表的慨念来理解DAX,而是一种"列表"的慨念。
了解这种横向一个或多个单列表的一行,以构成该数据模型的一行(唯一值)的特点,是熟练运用列表构建DAX的基础。所谓列表关系就是列表唯一值之间的索引或交叉索引关系。
上一部分中我们提到了:求数据模型表中各个列表的唯一值,见下图。
其中的邮寄方式只有4个值(基数),并且知道:由邮寄方式中其中的一个值(基数)筛选出来的表的行数为506行(我们可以说,筛选后的列表子集表的行数为506行,由于数据模型列表的行一一对应("行对齐)关系,这时,其它所有列表都将是506行,即由此将筛选一个506行的表。其他3个基数筛选出来的对应行数分别为:53、272、169(也将分别产生对应于该数值行的表),由4个值筛选出的4个子集列表的行之和为总行数:506+53+272+169=1000行(即完整数据表)。这说明该数据模型表共有1000行,该模型表中其他列表不管它有多少基数列值,都将对应有1000行。倒如,355个[客户lD]构成1000行,14个[数量]值构成1000行……等等。
这其中并没有一个具有1000个唯一值行的列表,上述列表肯定都存在大量的重复列值行或空值行。
PowerQurey里有一个简单的理解方式,即分组依据。如下图:我们观察到[出入库]列只有两个唯一值,根据列表的一一对应(行数一定),这两个值将分别对应于整个表的行数。也可以理解为:如果按这两个唯一值来分类(或筛选)该数据模型表,则该表所有内容将包含在这两个值所划分的组里,所有后续的计算都将与这有关(引用列表或定义值列表)。依次类推,有多少的这样的唯一值,就有多少这些唯一值以及由它们的组合的分组方式:
选择库存方式[出入库]列(也可以是其他你需要了解的列),进行“分组依据”操作:
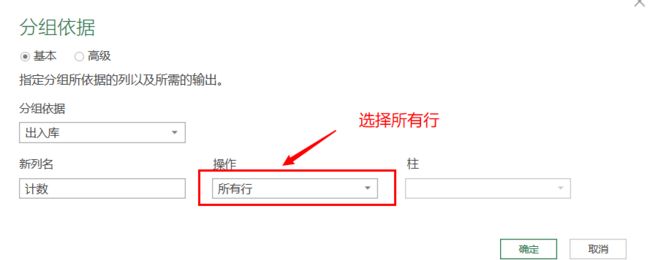
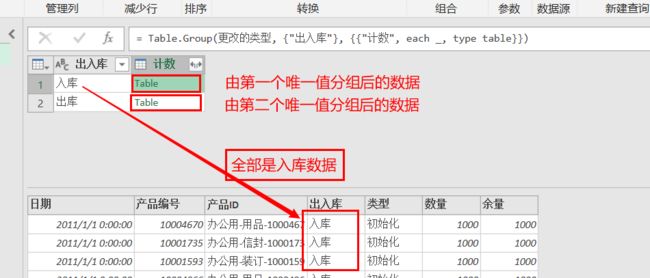
整个数据,显然已被分成了两个Table(数据区),点选其中任意一个,可以在下方观察到数据,其中[出入库]列表的行值全部为“入库”(包含“出库”内容的行被筛选掉--不在该类分组里)。这里我们利用了PowerQurey的“单元格”能装载Table的特性,以便于你更具体的了解列表特性以及列表筛选的实际。
当然,这时候,你也许会有进一步的需求操作,比如依据这两个唯一值指代为另外的主键列(例如给予一个编码或序号、创建关系列表等)。
2、当然,你还可以使用 DAX 函数来创建整个计算列表,这要求有一个表名称和一个表函数。计算表的使用(包括建立关系)和任何其他表一样。
你应该记得:DAX是一种函数式语言,你知道DAX表达式通常返回单个值,比如字符串或数字值。我们称这种表达式为值列表(这种情况下,也称为标量表达式,一种结果为数值的值列表)。
例如,当你定义一个度量或计算列,你定义的总是一个以字符串或数字为结果的值列表(该标量表达式,并不总是数字类型),如以下三种类型结果的例子:
= 4 + 3
= "DAX is a beautiful language"
= SUM ( Sales[Quantity] )
当然,你也可以编写一个产生列表的DAX表达式。但是,你不能直接将列表表达式分配给度量或计算列(前面所说:先有列表的全集数据,而后才有值列表。或者说,一般你不能直接"定义"一个列表,即便是其结果将作为列表的DAX表达式:即该列表表达式可以作为DAX的一个重要部分(列表)参与计算。
例如,某些DAX函数需要引用一个列表表达式作为参数,或者需要引用一个列表表达式来编写一个DAX查询(获得列表结果)等,这都只能是"引用"列表(无论该列表是如何产生的、以及是否元列表还是使用列表函数产生的结果列表等。总之,只要使用的是列表形态,我们都指代其为"引用"列表) 。
最简单的例子,一个列表表达式直接引用表名:如以下表达式返回整个Sales表的内容(所有列和行)的Sales表:
= Sales
但是,如果你试图将该表达式放置在度量或计算列中,则会得到一个错误,这是因为度量需要的是“定义”一个值列表。事实上,为了获得该标量值的值列表,DAX总需要“定义”表表达式,并可以使用可以定义表表达式的函数作为参数来实现。关于度量及计算列中使用列表、值列表的情形,我们在第一部分中的一开始就有举例。这里运用列表以及值列表的概念,做进一步的说明。
至此,你应该稍微明白了一些:为什么我们要花费这么多的时间、文字来讨论列表、列值以及列表的引用与值列表的定义概念。
例如,计算一个表里包含多少行的COUNTROWS函数:
= COUNTROWS ( Sales )
COUNTROWS函数有以下定义: COUNTROW是为数不多的一个接受表作为参数的DAX函数,它可以直接引用一个表的名称,或者函数定义的结果表作为参数。
我们根据函数结果返回的类型对DAX函数进行分类。如果返回一个标量值结果,我们说你调用的函数为"标量值列表(即值列表)函数,如果结果返回一个表(一个或多个列表),则调用的是"列表函数"。
例如,COUNTROWS是一个值列表函数,因为它返回每个数字结果,这与它接受一个表作为参数毫无关系! 请认真理解这句话,这对于后面DAX函数学习将由莫大的帮助。
许多表函数通常用于操作(引用)一个或多个列表(表),来更改元表的列表变化(通常是行列值的改变)。以返回一个或多个新的列表(表)集。例如, 通过使用以下表达式,可以计算销售表中的那些单价大于100的对应行的行数(值列表计算)。
= COUNTROWS ( FILTER (Sales, Sales[Unit Price] > 100))
在前面的表达式中,FILTER返回包含Sales表的所有列表,但其结果列表集只包含那些单价大于100的行。在后面内容中,你将了解更多关于FILTER筛选器功能的内容。COUNTROWS 函数引用该 FILTER()结果表(执行值列表的功能,但以列表形态在计算中被引用,即COUNTROWS引用的是表函数FILTER( )的结果表,即Sales表中符合条件的行构成的新的Sales表,而不是整个SaIes表):由于FILTER函数的功能:即使用该表表达式来遍历新的Sales表的行,并聚合这些行值,以返回一个标量值的结果值列表。
我们甚至可以给DAX筛选下一个帮助你理解的定义:所谓DAX筛选就是列表与值列表之间的转换、变化、组合等等。
上述公式,不能编写为:
= COUNTROWS (Sales[Unit Price] > 100))
因为这时候COUNTROWS()的参数 :SaIes[Unit Price]>100)是一个值列表而不是表,COUNTROWS函数只允许直接引用一个表(原表或结果表),而不是定义的值列表。我们将该公式与前面使用ALL()引用全集列表的公式,以及之前见到的类似的几个公式放置在一起,你可以试着对比一下,以分析它们之间的差异以及对错:
1) = COUNTROWS (Sales[Unit Price] > 100))
2) = COUNTROWS ( FILTER (Sales, Sales[Unit Price] > 100))
3) = COUNTROWS ( ALL (Sales), Sales[Unit Price] > 100))
4) = COUNTROWS ( CALCULATE (Sales), Sales[Unit Price] > 100))
5) = COUNTROWS ( CALCULATETABLE (Sales),Sales[Unit Price] > 100))
至少你应该理解一下与此节内容相关的第2、3两个公式。这里有一个很通俗的区别方法:公式 2),对于FILTER函数,有一个通常的理解:它是一个行筛选器,具有遍历表的每一行的行行为,因而,它的结果表是一行一行判断并找出来的,是内部引擎一行一行扫描出来的。而公式 3)则是直接“引用”一个列表筛选得出的。
为了更好的理解上面的一些概念。我们在Power BI 的新建表中使用ALL()来“引用”数据模型里的一个表:
再次使用FILTER()来“引用”数据模型里的同一个表:这时候会得到一个错误的提示:向FILTER函数传递的参数太少,该函数的最小参数计数为2.

有人试着使用专门的列表函数CALCULATETABLE,结果也是一样的错误提示。

想一下这里的该函数的最小参数计数为2,是什么意思?
再看一种情况:我们在计算诸如:销售量超过100,或者平均销量小于100等类似条件计算时,会用到:
CALCULATE([销售量], FILTER('门店信息表',[销售量]>200)) 或者:
CALCULATE([销售量], FILTER('时期表',[销售量]<100)) ......。
此类的DAX计算(是不是有一种很熟悉的感觉?)。
这两个FILTER( ) 的结果是一个值列表。首先,它们分别引用的是'门店信息表',以及'时期表',后面的筛选条件来自其他表(这里是布尔值值列表),其结果是这两个引用表被筛选后的值列表(已经不是原表的全集列表了),该值列表再次作为CALCILATE函数的第二个参数参与计算(这时是列表形态)--即在此列表筛选条件下计算。
FILTER('时期表',[销售量]<100) 作为值列表的功能是我们出于理解和编写DAX的需要,内部引擎始终会将其结果识别为列表处理,这是DAX里难于理解的地方,也是DAX优势的地方。
这在后面学习到DAX内部引擎原理时,将进一步学习到。
现在的问题是,既然我们已弄清楚了:FILTER('时期表',[销售量]<100)参与计算时是作为值列表还是列表存在。现在,我们单独将公式中:FILTER('时期表',[销售量]<100 部分拿出来,在Power BI 的新建表中使用它,结果是包含时期表全部字段的时期表(只是这时的时期表已经不是元时期表,行数范围变少了,这证明该表已被筛选,即符合定义条件的被保留了下来)。如图:
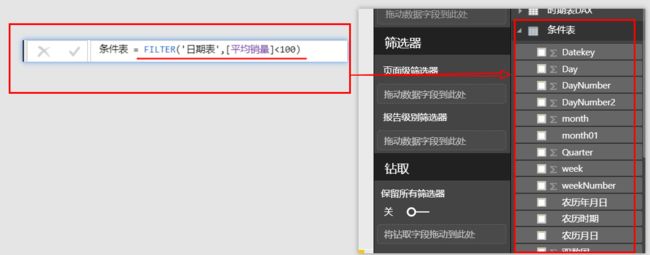
官方《DAX圣经》有句关于FILTER()的这一行为的描述:FILTER()作为列表结果而执行着标量值列表的功能。换句话说:FILTER() 总以列表形态存在着,但它首先是一个值列表结果。
公式:CALCULATE([销售量],FILTER('时期表',[销售量]<100))中, FILTER所引用表(例如本例中的时期表(被布尔值条件筛选后的时期表的子集表),但同时,该值列表又被CALCULATE作为列表“引用”(使用的是该值列表的全集列表)。
这种值列表转变为列表的行为(需要内部引擎识别一次),在DAX中被称为计数一次(前面讲函数的嵌套时的迭代也是,每遍历一次识别一次,哪怕是一行一值)。FILTER函数要求至少该计数为2(由于引擎总是处理列表,所以这里其实是列表出现的次数或者说是引擎处理的次数,原理上,处理一行一值一次与处理多行多值的一次没多大区别,对于引擎都是一次!)。因为,FILTER是一个行筛选器,具有遍历表的每一行的行行为,既然如此,计数为1,只有一个值就不需要遍历的行行为(实际已是列表,直接变成引用列表了,这不符合FILTER函数的功能),至少计数为2才满足遍历的条件。
例如:FILTER('门店信息表', 时期表) 。这种写法也是不对的。因为第二个参数引用的是表,计数为1。
当然,事实上,FILTER()可以有不限定计数(即可以定义多个值列表条件)。前面错误提示中的计数2,很多人理解为FILTER需要两个参数,这是两个概念。
说到这里,我们再想想之前提到的CALCULATE(度量或计算式,筛选1,筛选2,筛选3.....筛选N)中的筛选并没有FILTER式的限定,甚至可以不需要第二参数:CALCULATE(度量或计算式)。
事实上,你也可以简单理解为:像 FILTER(表)或FILTER(表[列])...这种直接引用表或列表的方式是不允许的。所以,严格地说,FILTER并不是表函数。根据列表的两种状态:列表与值列表,其实相应的函数也可以理解为只有两类:即引用列表的列表函数,以及定义值列表的值列表函数。当然你不需要记住这些,我们并不主张有这么多的概念。一句话:引用列表,定义值列表。
我们说,不能将表表达式直接作为度量或计算列里,但是,你可以在计算(比如提供行、列筛选)表中使用表表达式(如果该特性在将来可用)或在DAX查询中,将表表达式的内容显式化处理。例如,像前面举例的同类案例:获得一个包含所有单价大于100的[Unit Price]列的值列表对应的Sales表。
= FILTER (Sales,Sales[Unit Price] > 100)
前面提到,DAX公式还提供EVALUATE语句,可以用它来获得上述表表达式的结果列表输出:
EVALUATE
FILTER (Sales. Sales[Unit Price] > 100)
你可以在任何执行DAX查询的客户端工具(Microsoft Excel、DAX STUDIO) 看到EVALUATE语法的更详细的解释。
最后,鉴于FILTER函数的特性以及重要性,下面还会就该函数单独一式说明。
第23式:CALCULATE的列表表达式
正如前面所谈到的,你经常会使用表(列表)表达式作为DAX函数的参数。典型的用法是迭代表的函数,以及遍历每一行计算的DAX表达式等。例如,所有以一个“X”结尾的聚合类函数,如SUMX:
[Sales Amount] :=SUMX (Sales, Sales[Quantity] * Sales[Unit Price] )
在此计算的基础上(直接引用元表计算),你可以使用一个表函数来替换简单的表引用(这里是Sales表)。这是迄今为止,我们将要学习的第三种形态类型的DAX计算式:
SUMS类(显式行、列筛选计算):
SUMS类( 表或结果表,计算式)。
例如, 通过使用列表筛选功能,只计算那些销售数量大于1的度量:
[Sales Amount Multiple Items]:=
SUMX ( FILTER (Sales,Sales[Quantity] > 1), Sales[Quantity] * Sales[Unit Price])
这里SUMX函数的第一个参数使用了FILTER( )的结果列表(引用该值列表的全集结果列表),然后第二参数定义的计算在该子集列表下计算。所以,该计算检索的是经Sales[Quantity] > 1筛选后的那些行的表。你需要理解这句话的含义,以便于掌握这类DAX计算。这里的列表计数为2(出现两次列表形态)。
在计算列中书如果需要检索表的所有行,可以使用RELATEDTABLE表函数,该表函数引用位于一对多关系的多端的表。
例如,下面的计算列在Product(产品)表里计算相应的产品的销售额:
Product[Product Sales Amount] =
SUMX ( RELATEDTABLE ( Sales ), Sales[Quantity] * Sales[Unit Price])
因为我们在Product(产品)表里计算相应的产品的销售额,公式首先向Product(产品)表里添加一个计算列,SUMX的参数引用的是Sales表的该列表(当然前提是Product与SaIes表之间存在关系)计算。
很多时候,我们需要在一些看起来并不是事实表的表(例如参数表)里计算一些值,而计算数值需要来自某个事实表,通常的做法是在参数表里引入(VLOOKUP方式)一个计算列。除非必要,你可以像本例公式所示,使用RELATEDTABLE ()方式直接在度量里引用该列表,而不是创建一个新计算列。
在接下来的“CALCULATE的列表筛选”中,可以在“行筛选和列表关系”中找到相关的表函数的详细解释。
前面我们已提到:你还可以在同一个DAX表达式中嵌套调用表函数,因为任何一个表表达式都可以看成是该表函数对列表的调用(实际调用的是由值列表转化的列表)。例如,在Product表中的以下计算列为计算产品的销售数量,并仅考虑销售额大于1的那部分产品的销售额。
Product[Product Sales Amount Multiple Items] =
SUMX ( FILTER ( RELATEDTABLE ( Sales ),Sales[Quantity] > 1),
Sales[Quantity] * Sales[Unit Price])
这与前面直接使用FILTER( ) (第一参数)引用一个表不同的是,它引用的是RELATEDTABLE( )的结果表(附加有筛选)。这是两个表函数的嵌套调用(即一个表函数的结果表被另一个表函数引用,这其实也是一种获得多列表结果的方式。你可以理解DAX列表查询(可获得列表集结果)。
当表函数嵌套调用时,与其它函数定义的DAX一样,DAX将首先计算最内部的表函数定义的结果,然后依次对外层的其他函数进行计算。我们说,这其实是DAX内部计算的计算顺序,这与筛选看起来是相反的。
注意,不要将此规则与函数调用参数的计算顺序相混淆(你应该明白,计算顺序的每个过程是调用某个函数的功能结果,而函数的参数顺序仅针对该函数,显然不是一回事)。
还需要注意,稍后行将看到,嵌套调用的执行顺序可能会造成某些混淆。比如CALCULATETABLE的计算顺序就不同于FILTER。这将在下一式的CALCULATE中的FILTER行为,以及“CALCULATE与CALCULATETABLE”中找到有关CALCULATETABLE的描述。
第23式 CALCULATE的FILTER行为
我们已经知道,FILTER函数其实扮演着一个简单的角色:它获得一个与原始表具有相同列的表(行扫描的筛选条件下的行(即行范围己减少的表)。
先观察FILTER的语法:
FILTER (表,条件筛选)
FILTER迭代(遍历)表的每个行(一列或多列的行),并对每个行求值,你可以认为这是一个布尔值的值列表表达式,当结果值为TRUE时,筛选器返回该行(列值),否则,它就会跳过它(未被引用的行)。基于此,有人称FILTER为行迭代器)。
请注意,从DAX逻辑角度来看,FILTER 对<表>中每一行执行某个定义的<条件>。然而,由于DAX内部的优化原理(引擎总趋于最先找出最小基数的列表集):对于FILTER(表,条件),可能会将计算的数量减少到该<条件>表达式中包含的引用列表的唯一值的数量。也就是说这与列表的唯一值有关(耳语数据的多少关系不大)。后面还有关于列表唯一值的列表映射关系的再次说明。
有时候,你可能遇到过,使用CALCULATE(计算式,条件筛选)方式的某些公式会出现计算错误,将其中的"筛选"替代为:FILTER(表,条件)的筛选方式后则计算正确。这是什么原因?
这里要说的是其中的一个与粒度有关的原因: FILTER(表,条件筛选)的实际计算值对应于FILTER操作的列表“粒度”。
我们知道,一个列表无论什么类型,其实是不存在"粒度"的(一个列表就是一个整体、数据模型的构成单元),但计算中存在这种粒度,并需要我们经常考虑"粒度"。这时,我们只能借助值列表形态。
因为,FILTER()的上述语法中的可变换为:条件筛选 = 值列表,即:
FILTER(表, 值列表)
FILTER才是真正意义上的"筛选":先有列表,再有值列表(引用一个列表或表,然后定义一个值列表筛选它)。甚至由于FILTER本身也函数,你可以嵌套(FILTER(FILTER……))。
同时,FILTER的条件参数值列表的"粒度",决定了FILTER值列表条件筛选器的性能,它是DAX优化的一个重要因素(例如可能使用布尔值列表优化)。
当FILTER(表,条件) 中的"条件"与 CALCULATE(计算式,筛选)中的"筛选"相同时,可能有人会觉得后者的运行会快一些(理由是后者不需要迭代行)。当然,这种情况下,总使用 CALCULATE方式而不是FILTER。但需要说明的是,你不必要过于考虑它,自然地使用它们就行:由于数据结构的不同,以及FILTER的功能特点:行行为、考虑粒度、布尔值筛选优化等,该使用哪个方式自然就明白了。
再看几个实例。例如,以下查询筛选出所有品牌为"Fabrikam"的产品。
EVALUATE
FILTER (Product, Product[Brand] = "Fabrikam")
这是一个结果列表,FILTER的第一参数引用元表--Product表,然后定义一个布尔值列表,并基于此筛选出一个Product,表,并得到满足品牌为"Fabrikam"条件的那些行的Product表)。
我们说,你可以在另一个FILTER函数中嵌套引用FILTER( ),因为,可以使用任何表表达式作为FILTER的参数。这时,第一个FILTER执行的是最内层的。通常,嵌套两个FILTER产生的结果是相同的,而不是多个筛选器包含的逻辑条件的组合。换句话说,以下查询将产生相同的结果:
FILTER (表,AND (条件1,条件2 ) )
FILTER ( FILTER (表,条件1 ),条件2 ) )
但是,如果有许多行,并且两个或多个AND“并”条件有不同的复杂性,可能会观察到不同的性能差异。例如,考虑下面的查询,该查询将返回具有单位价格的产品,其单价是单位成本的3倍以上,如图3-7所示。
EVALUATE
FILTER (Product,AND (Product[Brand] = "Fabrikam",
Product[Unit Price] > Product[Unit Cost] * 3))
该查询只筛选了Product[Brand] = "Fabrikam,且Product[Unit Price] > Product[Unit Cost] * 3的产品。该查询可以将这两个条件应用到产品表的所有行中。如果两个条件之一中有一个是更快或更有选择性,那么,可以首先使用嵌套的FILTER函数来应用它。例如,下面的查询改变前一个公式最内层FILTER条件的位置:
EVALUATE
FILTER ( FILTER (Product, Product[Unit Price] > Product[Unit Cost] * 3),
Product[Brand] = "Fabrikam")
如果将条件反过来,则它们的执行顺序也会反过来。例如,下面的查询只适用于Fabrikam品牌的产品,这决定于条件所包含的行:
EVALUATE
FILTER ( FILTER (Product, Product[Brand] = "Fabrikam"),
Product[Unit Price] > Product[Unit Cost] * 3)
当优化DAX表达式时,这些知识将非常有用。你可以选择执行顺序,并首先应用最具有选择性、更快的筛选器。然而,这需要基于对列表筛选的清晰理解,否则,不要试图优化DAX。这将在本系列后面的“优化DAX”中找到更完整的关于查询优化的讨论。这些示例的目的是让你意识到表函数的嵌套调用的执行顺序。
请记住,通常,嵌套调用函数的执行顺序是从最里面到最外层的顺序。
但是,我们知道,CALCULATE和CALCULATETABLE可能是这种行为的一个例外(前面我们提到过)。 FILTER与CALCULATETABLE可能存在执行顺序的差异。这两个函数将依赖于用于计算的参数的特定顺序。因为,在类似的情况下你可能会使用FILTER或CALCULATETABLE,所以,在嵌套调用的情况下要注意这种差异。
请查阅: DAX联接表系列 之四中相关内容。
第24式:CALCULATE()条件筛选的构成
在之前的内容里,为了帮助你理解以及掌握“列表以及值列表”,我们已列举了大量的DAX案例公式,在这些公式中,涉及的一个主要内容是:引用列表以及定义值列表。
如果你仔细观察,无论多么复杂的DAX公式,我们都可以将其拆分为一个个构成单元,这一个个单元都是由列表构成(实际运用上,总是列表与值列表两种形态)。
由于函数的参数要求、以及计算逻辑的需要,引用列表以及定义值列表总存在于不同的场景和位置。所以,熟练掌握DAX,需要基于数据行为逻辑的理解、以及构建这些计算时需要使用的函数功能的了解。我们不止一次说道:DAX是一门函数式语言工具。
你不必刻意的记住那几百个的函数,需要什么计算、知道什么函数有这个功能实现它就行。
但首先,我们要学习DAX的构成单元是什么、以及它们是如何组织起来的(也就是说如何写出一个DAX计算式)。
注意:后面的DAX公式书写系列会详说。
其实前面我们已经说到这个问题,这里单独成为一式,只是为了加深一下理解。在创建任何DAX公式时,一般来讲,需要明白两点:
1、DAX执行的是列表(列表以及值列表);
2、DAX的计算单元几乎都是由列表+值列表 构成,即先有列表再有值列表。
常见的如(仅列举几个前面已有的公式):
1)FILTER (表,条件筛选),CALCULATE(计算列表,筛选)...模式;
2) FILTER (Product, Product[Brand] = "Fabrikam");
3) FILTER (Sales. Sales[Unit Price] > 100) ;
4)COUNTROWS ( FILTER (Sales, Sales[Unit Price] > 100)) ;
5)SUMX (Sales, Sales[Quantity] * Sales[Unit Price] )
......等等。
很多人纠结的:MIN函数与VALUES函数以及由它们构成的:
MIN(时期表[列])与VALUES(时期表[列]) 的区别。比如为什么在设置列表条件时:
不能:表[某列]<=VALUES(表[某列]), //列对列
可以:表[某列]<=MIN(表[某列]), //列对值
因为,任何筛选列表也应该符合:DAX的计算单元的列表+值列表 构成规则,第一个公式中的:VALUES(表[某列])(类似的有FISTDATE(时期表[列])等),是这个列表的所有唯一值列表,它是一个列表,左边也是一个列表,即列表<=列表,这是不允许的(全集的列表之间对比没有意义)。能对比的只有值列表(至少有一个是值列表,即对比的是列表的某个范围),第二个公式中MIN(表[某列])(类似的有MAX(表[某列]))是每个标量行值的值列表,列表<=值列表,符合DAX单元构成规则。
表[某列]<=VALUES(表[某列]) 如果计算正确,那么,这时候的VALUES(表[某列])则是一个值列表,即当VALUES()为每个唯一值的值列表时,该条件成立:实际上这时候常见的是写成:
表[某列] = VALUES(表[某列])
因为只有=(等于)才有可能表示为“每个当前值”,而使用<、>号,一般为某个范围值,大都被VALUES()函数指代为列表。这是VALUES()函数的特别之处。利用VALUES()函数的“两面性”可能会更好的理解列表+值列表的单元构成。
在接下类的一式中,还会提到VALUES函数,该函数是DAX中使用频率最高的函数之一。
这里我们暂时略过这个话题。
第25式 CALCULATE ( ) 的ALL函数系列
ALL函数系列包括ALL、ALLEXCEPT以及 ALLNOBLANKROW,所有这些函数都是很实用的系列函数:它们返回一个表(多个列表)的所有行或者一个列表的所有值,这取决于其使用的参数。
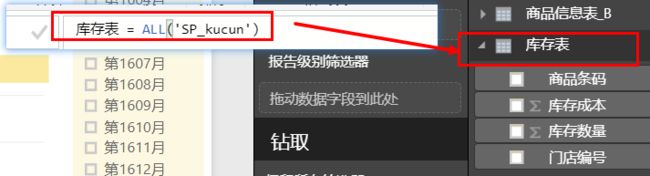
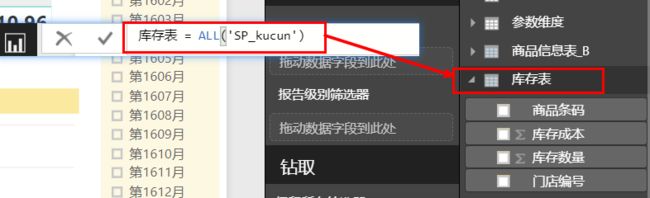
例如,下面使用ALL()函数的DAX查询返回库存表中的所有行:
库存表 = ALL ( 库存)
不能在ALL()参数中指定一个表表达式。必须指定一个表名的表或一个列名的列表。如图:由ALL()生成的包含多有行的库存表结果与原库存表的行数对比(使用Power BI的新表创建),该表共有16578行
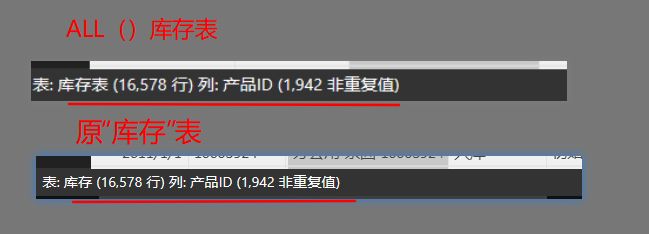
上图中,观察到产品ID列共有1942个唯一值(非重复值)。我们继续“新表”,写入公式:
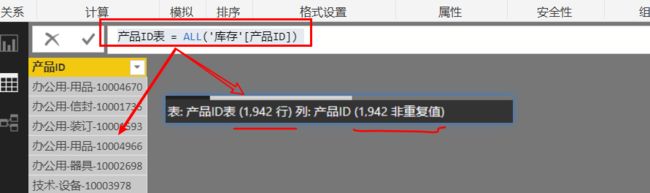
产品ID表 = ALL('库存'[产品ID])
如图可知: 如果ALL使用单个列,结果是一个包含该列唯一值的列表。该列共有1942个唯一值,即1942行的列表结果。
再次“新表”,写入公式:
产品ID表2 = ALL('库存'[产品ID],'库存'[类型]) ,即ALL()针对两列:
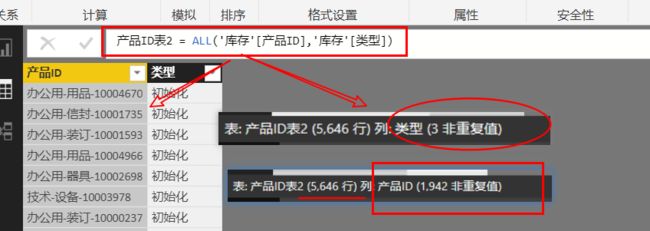
如果在ALL()里再添加一列[类型],结果相同:
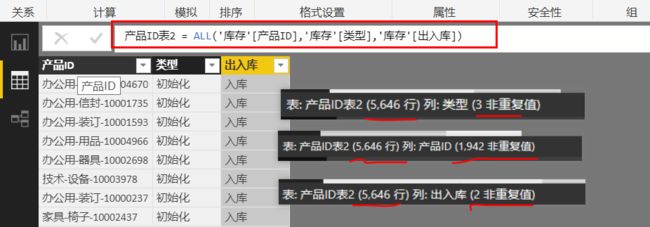
为什么这时候的结果表行数不是前面的1942个行的表呢?
这里,我们在ALL函数的参数中指定了来自同一个表的更多列。如果使用多个列,结果将是一个具有相同行数量的列表,其中包含这些列中现有值的列表组合(比如笛卡尔积值)。
在:产品ID表2 = ALL('库存'[产品ID],'库存'[类型]) 结果中,ALL()取两列的共有行的组合,由于[产品ID]列的唯一值是1942,[类型]列的唯一值是3,则两列的行数组合将会是:1942×3= 5826(与结果5646有点差异,可能有“没有匹配”的行空值等)。因为后面添加进的[出入库]列只有2(比[类型[列唯一值3要少),所以,不影响总行数结果。
如果我们去掉[类型[列,改为:产品ID表2 = ALL('库存'[产品ID]) ,则这时候为该两列的行组合,行数应为:1942×2= 3884,如图,结果是3884行的结果表。
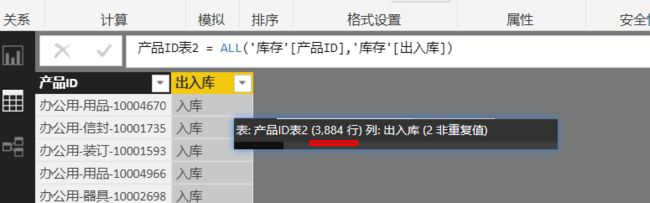
很多人对于ALL(表)返回该表的所有行,而ALL(单个列表)时生成该列表的唯一值列表有些费解。ALL()的作用是处理表或列表的唯一值,对于表,其唯一值就是该表的现有行数(在数据模型里的单独的每个表即然可以单独作为一个表,是因为它们拥有唯一值的行,我们前面说过,你需要将表的一个或多个列的某个行横向连起来看作该表的一行,并不是某一个列表列值所在的一个行)。同理,依据数据模型表的行的一一对应(行映射),当某些列的唯一值不相同时将使用重复值或空值填充。
所以,对更多列的所有值的查询将返回一个当前存在的行值组合的列表。在ALL的那些变体函数中,都忽略了任何现有的筛选器来产生结果,你可以将所有这些结果作为迭代函数的参数,如SUMX和FILTER,或者作为一个CALCULATE函数中的筛选器参数(稍后将会看到)。
如果想在ALL函数调用中包含表的大部分列,则可以使用ALLEXCEPT代替。要想从结果中排除哪些列,则需要先引用一个表,后面再是该表的列。因此,ALLEXCEPT返回一个表,其中有在ALLEXCEPT()里未指定的表的其他列中唯一值组合的列表。
实际上,ALLEXCEPT是一种编写DAX表达式的方式,它将自动包含在ALL( )结果中。今后,如果再在数据模型中添加其他新列,也可能自动添加在ALL()里。例如,如果有一个带有五个列的产品表:产品名称、产品编码、品牌、类别、颜色,下面的语法产生相同的结果:
ALL ( 产品[产品名称],产品[品牌],产品[类别] ) // 需处理的三列
ALLEXCEPT ( 产品,产品[产品编码],产品[颜色] ) // 排除在外的两列
然而,如果以后需要添加两列:比如,[产品成本]和[产品单价]列,那么,所有的结果将同时忽略它们(自动添加进ALL()里),而前面ALLEXCEPT将返回相当于:下面的查询返回的一个表,该表还是除了产品代码和产品颜色外的所有列:
ALL (产品[产品名称],产品[品牌],产品[类别],产品[成本]......,产品[单价]);
该结果与原来的表的行数相同,因为,其结果包含了产品编码列,该列的每一行都有一个唯一的值。结果其他列的组合可能会返回更少的行,因为在返回的列值中删除了重复值。它还是等同于:
ALLEXCEPT ( 产品,产品[产品编码],产品[颜色] )
ALLEXCEPT() 返回所有在参数中没有指定的列的值的组合。在前面的示例中,已经看到了ALL( )的计算语句,它在没有任何现有筛选器的情况下执行DAX表达式。
出于这个原因,最好用一个示例,使用数据透视表中ALL()返回的行数的度量方法,其中每个单元格使用不同的筛选器对度量值进行计算。考虑以下度量:
[Products] : = COUNTROWS ( Product )
[All Products] := COUNTROWS ( ALL ( Product ) )
[All Brands] : = COUNTROWS ( ALL ( Product[Brand] ) )
你可以设想一下每个度量的不同结果是什么。
第1、2个公式,会显示相同的数字(针对的是Product 表)。ALL()语句的计算忽略了透视表的每个单元格所定义的筛选器(不受透视表筛选影响)。基于行映射,当调用关系的父表时,如果子表包含一个或多个与父表中的值不匹配的行,则会检索额外的空行。
这可以使用ALLNOBLANKROW()而不是ALL()的方法来忽略结果中的这个特殊行(一般为空值)。
ALLNOBLANKROW的度量的值与ALL版本都比Product表和Products[Model]的ALLNOBLANKROW版本多了一个。原因是Sales表中有一些行在Product表中没有匹配的行,因此实际上添加了一个额外的行。
ALL和 ALLNOBLANKROW度量不同,如果目标表包含一个额外的空行时,它们定义的度量总是返回相同的值。如果计算表中包含对不匹配行的值的引用,所有这些行将被分组在相同的(空白)值中,并用于计算。
ALLNOBLANKROW的这一点可能有用于:当需要编写一个迭代值用以忽略关系中不匹配的值时使用。然而,我们通用都是使用ALL(),而ALLNOBLANKROW()却很少被使用。
关于ALL、ALLEXCEPT函数,考虑到后面的内容,以及前面的“ALL”介绍,所以,应该不需要用冗长的解释来烦你。我们再简单聊一下它的干脆性和实用性方面。
1、ALL()函数总在一个CALCULATE()中使用,并作为它的筛选参数之一。它从当前任何筛选里删除所有的筛选器。考虑有这样一个透视表:年份在切片器上的[Net Sales]按月显示的度量,现在,我们将使用这个透视表来演示ALL()的用法。我们建立一个新度量:
[All Month Net Sales] = CALCULATE ( [Net Sales], ALL ( Sales[MonthNum] ) )
因为从ALL( )从Sales[MonthNum]中删除了所有筛选器,透视表值区域中的每个度量单元将都与Grand Total(小计项)具有完全相同的筛选器 (行列坐标)。
前面说过,你也可以把ALL()当作一种手段:“引用”一个透视表中的全部单元格,即从当前筛选器中清除/移除每个筛选器。取消一个切片器这个很有用,也很有趣。例如,变化ALL( )还可可以用于去除单个列之外的参数。比如这两种变化都是有效的:
(1)ALL(,,…) –-用于指定的多个列 :
例: ALL(Sales[ProductKey], Sales[Year])
(2)ALL( ) –- 用于指定的一个表(该表的所有列),用于表的每一列(整个表)
例: ALL(Sales)
需要重复的是:ALLEXCEPT() 函数,假设有在一个表中有12个列,你想要将ALL( )应用到12个列中其中的一个或多个列。然后,你可以使用:
ALLEXCEPT(<表>,< 要取消筛选的列1>,< 要取消筛选的列2>…)
例如:这与列出Sales-销售表中除[ProductKey]列之外的每一列相同:
ALL (Sales[OrderQuantity],Sales[UnitPrice],Sales[ProductCost],Sales[CustomerKey],Sales[OrderDate], Sales[MonthNum],…< ProductKey之外的所有列>)
在这种情况下,使用ALLEXCEPT( )更方便,你只需要将不需要排除掉筛选作用的一列,使用 ALLEXCEPT即可:
ALLEXCEPT (Sales,Sales[ProductKey])
另一个不同之处,使用ALLEXCEPT( )除了方便之外,如果随后需要添加一个新的列到Sales表,ALLEXCEPT( )将“提取它”,并将ALL( )行为同样应用到它,而不需要你更改度量公式。在编辑公式之前,ALL(<列出每个列>)的方法显然不会应用到新列。
第26式 CALCULATE ( ) 的VALUES 和 DISTINCT定义的唯一值列表函数
在前一式中,已经看到,使用一个列的ALL() 返回一个具有所有唯一值的表。DAX函数提供了两个其他类似的函数:返回一个列表的唯一值列。这就是 VALUES 和 DISTINCT。 其中的VALUES已简单介绍过。
在没有任何其他筛选操作的情况下,如果在计算语句中使用VALUES 或 DISTINCT看起来是相同的。但是,当将这些函数放入到DAX度量中时,可以观察到它们不同的行为。
因为,在一个数据透视表的每个单元格中,计算发生在不同的当前筛选中。考虑下面的度量,计算Product[Brand]和Product[Size] 列唯一值的数量。
1)[Products] : = COUNTROWS ( Product )
2)[Values Brands]:= COUNTROWS ( VALUES ( Product[Brand] ) )
3)[Distinct Brands]:= COUNTROWS ( DISTINCT ( Product[Brand] ) )
4)[Values Sizes]: = COUNTROWS ( VALUES ( Product[Size] ) )
5) [Distinct Sizes] : = COUNTROWS ( DISTINCT ( Product[Size] ) )
VALUES()返回当前可见的唯一值列表,包括未匹配值的可选空白行;DISTINCT执行相同的操作,但并不返回未匹配值的空行(这是两者的区别)。然而, 如果空白值显示为列的有效值,这两个函数将包括空白行。惟一的区别是,添加了空白行来处理关系中的缺失值。
VALUES和DISTINCT只在将空白的行内容添加到模型中,以包含那些未匹配的行,这在报告的(空白)行中是可见的。另一个差异是可见的:VALUES 返回的值比DISTINCT应用于同一列的值可能要多。
假设没有筛选器,DISTINCT的行为对应于ALLNOBLANKROW(),而VALUES的行为对应于ALL()。VALUES也接受一个表作为参数。这种情况下,它将返回当前单元格中可见的整个表,并有选择地包括未匹配关系的空行。
例如,在数据模型中考虑以下度量,其中Sales表与Product产品表具有关系,并包含与产品键不匹配的任何现有产品的事务记录:
1) [Products] : = COUNTROWS ( Product )
2)[Values Products]: = COUNTROWS ( VALUES ( Product ) )
3) [All NoBlank Products]:= COUNTROWS ( ALLNOBLANKROW( Product) )
4) [All Products]: = COUNTROWS ( ALL ( Product ) )
当没有筛选器时,VALUES的结果对应于ALL的行为,包括添加的空白行,以显示未匹配产品的计算。这种情况下,不能在一个表上使用DISTINCT(不能代替公式2中的VALUES)。
在引用一个表或列时,VALUES与ALL()的结果相同:
= ALL ( Product )
= VALUES ( Product )
= ALL ( Product [])
= VALUES ( Product[Brand])
= ALL ( Product[Brand]
在引用表时,VALUES与ALL()的结果相同:
如果需要删除一列中重复的行, DAX函数中没有单一这样的函数来删除重复的行(这时必须使用SUMMARIZE,稍后将会介绍)。
然而,当没有筛选器时,1) 中[Products]度量将计数表中的行数,并忽略一个可能的空白行,该行为与ALLNOBLANKROW相同。
你可以使用VALUES创建标量值,即使VALUES是一个表函数,也会经常使用它来计算标量值,在后面的式中将学习到DAX的这一特殊特性。
例如,可以在表达式中定义VALUES(),如下面的一个,它显示颜色名称,以确保选择的为相同颜色的所有产品:
[Color Name] :=
IF (COUNTROWS ( VALUES ( Product[Color] ) ) = 1, VALUES ( Product[Color] ))
当ColorName度量结果包含空白时,意味着有两个或更多不同的颜色;
当VALUES返回一行,可以使用它将结果转换为一个标量值,比如Color Name度量。
有趣的一点是,我们可以使用VALUES()作为标量值的结果,即使它返回一个表。这不是VALUES的特殊行为,但它代表DAX语言更一般的行为:如果需要一个表表达式返回一行或一列,并需要它自动完成(隐式),则可以使用任何表表达式来将列表转换为标量值(即将列表转换为值列表)。
在实践中,如果结果正好为一行或一列,可以使用任何表表达式作为一个标量值(这不是函数的行为,而是DAX内部引擎的行为)。而当表返回多行时,在执行时会得到一个错误:“一个多值的表是由其他方式提供的”。
因此,你应该保持该标量值的转换条件:使表表达式返回一个不同的多行结果 (你应该已经知道,当你写DAX函数表达式时,该表表达式只返回一行)。前面的[Color Name]示例,使用COUNTROWS检查Color颜色在Products产品表的选择里是否只有一个值。
一个更简单的完全相同的控制方法是使用HASONEVALUE,它执行同样的检查,如果列只有一个值,返回TRUE,否则返回FALSE。以下两个语法是等价的:
1)COUNTROWS ( VALUES () ) = 1
2)HASONEVALUE ()
你应该用HASONEVALUE代替COUNTROWS,这有两个原因:可读性更强,以及可以稍快一些。下面是一个更好的基于HASONEVALUE设置的度量:[Color Name]。
[Color Name] :=
IF (HASONEVALUE ( Product[Color] ), VALUES ( Product[Color] ))
经常使用值作为标量表达式的原因是,它返回单个列,并可能返回单个行,这取决于执行的筛选条件。在许多DAX模式中,使用VALUES()作为标量表达式是很常见的,并且反复出现。
在 [Color Name] :=
IF (COUNTROWS ( VALUES ( Product[Color] ) ) = 1, VALUES ( Product[Color] )) 这个公式中有两点值得注意:
1)IF函数的测试条件是:COUNTROWS ( VALUES ( Product[Color] ) ) = 1计数。这种模式很常见:检查计数结果是否只有一个可见值或符合指定值(这里为=1)。**
如果当前测试条件结果中没有内容,那么,在当前筛选器筛选中,列的所有值都是可见的:也就是说,HASONEVALUE将返回FALSE(因为该列有许多不同的值,这不符合条件)。另一方面,如果有一个值时(计数为1),那么只有这个值是可见的,这时,HASONEVALUE将返回TRUE。
因此,在本例中,我们需要返回的值将是唯一的值,是否为唯一值这个条件是由IF测试的。
未完待续