tensorflow_framework
图片来源
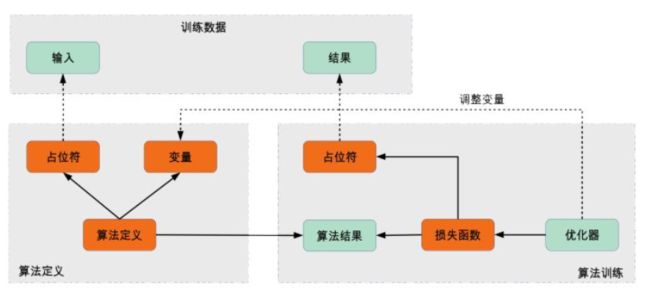
对于训练数据和算法定义这块基本了解,但是对于算法训练这块,总觉得自己写的很奇怪,今天决定总结一下别人怎么写的,一点一点慢慢改善。
- tensorflow mnist tutorial
这个教程感觉和之前看到的已经不一样了,tensorflow要大力推广一下Estimator和Dataset的框架,所以这个写法如下:
在模型定义的最后:
### predictions是字典,包含输出的类别和概率
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
### loss是labels与logits的交叉熵
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-3)
train_op = optimizer.monimize(loss=loss,global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
### 如果不是以上两种模式,则当做EVAL处理
eval_metric_ops = {
"accuracy": tf.metrics.accuracy(labels=labels, predictions=predictions["classes"])}
return tf.estimator.EstimatorSpec(mode=mode,loss=loss,eval_metric_ops=eval_metric_ops)
我对上述代码有个问题:这一段是写在
def cnn_model_fn(features, labels, mode)中的,如果是PREDICT模式,那么没有办法提供labels怎么办?
然后在主函数中:
mnist_classifier = tf.estimator.Estimator(
model_fn=cnn_model_fn, model_dir="/tmp/mnist_convet_model")
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x = {"x": train_data},
y = train_labels,
batch_size = 100,
num_epochs = None,
shuffle = True)
mnist_classifier.train(input_fn = train_input_fn, steps = 20000, hooks=[logging_hook])
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x = {"x": eval_data},
y = eval_labels,
num_epochs = 1,
shuffle = False)
eval_results = mnist_classifier.evaluate(input_fn=eval_input_fn)
所以mode参数不是显式给定的,应该是通过调用estimator的不同方法而隐式确定,所以tensorflow应该有内部的方法去处理没有labels的问题,可能直接赋值0就可以了。
- 极客学院MNIST
这个似乎是我之前看到过的版本,确实比较简明。
其实必要条件也这么多,定义好train_op以及一系列metrics,在循环中得到batch input,然后训练,一定间隔后输出loss和metrics信息。
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))
sess.run(tf.initialize_all_variables())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0 :
train_accuracy = accuracy.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0)
print "setp %d, training accuracy %g"%(i, train_accuray)
train_step.run(feed_dict={x:batch[0],y_=batch[1]},keep_prob:0.5)
- FCN_tensorflow in github
sess = tf.Session()
print("Setting up Saver...")
saver = tf.train.Saver()
summary_writer = tf.summary.FileWriter(FLAGS.logs_dir, sess.graph)
sess.run(tf.global_variables_initializer())
ckpt = tf.train.get_checkpoint_state(FLAGS.logs_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
print("Model restored...")
if FLAGS.mode == "train":
for itr in xrange(MAX_ITERATION):
train_images, train_annotations = train_dataset_reader.next_batch(FLAGS.batch_size)
feed_dict = {image:train_images, annotation:train_annotations, keep_probability: 0.85}
sess.run(train_op, feed_dict = feed_dict)
if itr % 10 ==0:
train_loss, summary_str = sess.run([loss,summary_op], feed_dict=feed_dict)
print("Step: %d, Train_loss: %g" % (itr, train_loss))
summary_writer.add_summary(summary_str, itr)
if itr % 500 ==0:
valid_images, valid_annotations = validation_dataset_reader.next_batch(FLAGS.batch_size)
valid_loss = sess.run(loss, feed_dict = {image:valid_images, annotation:valid_annotations, keep_probability: 1.0})
print("%s --> Validation_loss: %g" % (datetime.datatime.now(), valid_loss))
saver.save(sess, FLAGS.logs_dir + "model.ckpt", itr)
这一个稍微复杂一些,但是目前看来,函数式的训练方法大体都是这样。