1.cost function
1.1 距离
常见的为欧式距离(L1 norm)&&p=2,拓展的可以有闵可夫斯基距离(L2 norm)&&p=1:
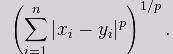
当p趋向于无穷的时候,切比雪夫距离(Chebyshev distance):
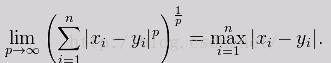

红色的时候为切比雪夫距离,蓝色为闵可夫斯基距离,绿色为欧式距离。
1.2相似系数
夹角余弦及相关系数,相关系数不受线性变换的影响,但是计算速度远慢于距离计算。
1.3dynamic time warping动态时间规整
举例子:
序列A:1,1,1,10,2,3,序列B:1,1,1,2,10,3
欧式距离:distance[i][j]=(b[j]-a[i])*(b[j]-a[i])来计算的话,总的距离和应该是128
应该说这个距离是非常大的,而实际上这个序列的图像是十分相似的。因为序列A中的10对应得是B中的2,A中的2对应的B中的10,导致计算膨胀,现在将A中的10对应B中的10,A中的1对应B中的2再计算,膨胀因素会小很多(时间前推一步)。
2.聚类算法
2.1分层聚类:
自上而下:所有点先聚为一类,然后分层次的一步一步筛出与当前类别差异最大的点
自下而上:所有点先各自为一类,组合成n个类的集合,然后寻找出最靠近的两者聚为新的一类,循环往复
数值类分类:(适用于计算量巨大或者数据量巨大的时候)
BIRCH算法,层次平衡迭代规约和聚类,
主要参数包含:聚类特征和聚类特征树:
聚类特征:
给定N个d维的数据点{x1,x2,....,xn},CF定义如下:CF=(N,LS,SS),其中,N为子类中的节点的个数,LS是子类中的N个节点的线性和,SS是N个节点的平方和
存在计算定义:CF1+CF2=(n1+n2, LS1+LS2, SS1+SS2)
假设簇C1中有三个数据点:(2,3),(4,5),(5,6),则CF1={3,(2+4+5,3+5+6),(2^2+4^2+5^2,3^2+5^2+6^2)}={3,(11,14),(45,70)}
假设一个簇中,存在质心C和半径R,若有xi,i=1...n个点属于该簇,质心为:C=(X1+X2+...+Xn)/n,R=(|X1-C|^2+|X2-C|^2+...+|Xn-C|^2)/n
其中,簇半径表示簇中所有点到簇质心的平均距离。当有一个新点加入的时候,属性会变成CF=(N,LS,SS)的统计值,会压缩数据。
聚类特征树:
内节点的平衡因子B,子节点的平衡因子L,簇半径T。
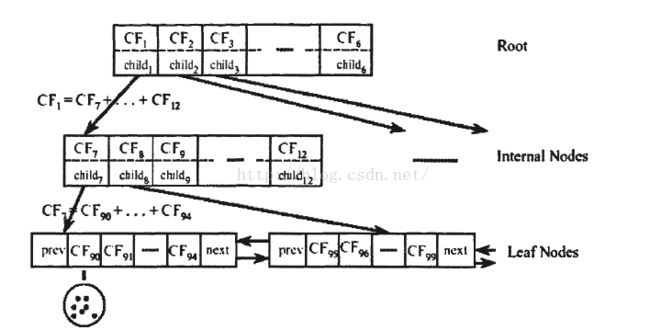
B=6,深度为3,T为每个子节点中簇的范围最大不能超过的值,T越大簇越少,T越小簇越多。
名义分类:
ROCK算法:凝聚型的层次聚类算法
1.如果两个样本点的相似度达到了阈值(θ),这两个样本点就是邻居。阈值(θ)有用户指定,相似度也是通过用户指定的相似度函数计算。常用的分类属性的相似度计算方法有:Jaccard系数,余弦相似度
Jaccard系数:J=|A∩B|/|A∪B|,一般用于分类变量之间的相似度
余弦相似度:【-1,1】之间,越趋近于0的时候,方向越一致,越趋向同一。
2.目标函数(criterion function):最终簇之间的链接总数最小,而簇内的链接总数最大
3.相似度合并:遵循最终簇之间的链接总数最小,而簇内的链接总数最大的规则计算所有对象的两两相似度,将相似性最高的两个对象合并。通过该相似性度量不断的凝聚对象至k个簇,最终计算上面目标函数值必然是最大的。
load('country.RData')
d<-dist(countries[,-1])
x<-as.matrix(d)
library(cba)
rc <-rockCluster(x, n=4, theta=0.2, debug=TRUE)
KNN算法:
先确定K的大小,计算出每个点之外的所有点到这个目标点的距离,选出K个最近的作为一类。一般类别之间的归类的话,投票和加权为常用的,投票及少数服从多数,投票的及越靠近的点赋予越大的权重值。
2.2分隔聚类:
需要先确定分成的类数,在根据类内的点都足够近,类间的点都足够远的目标去做迭代。
常用的有K-means,K-medoids,K-modes等,只能针对数值类的分类,且只能对中等量级数据划分,只能对凸函数进行聚类,凹函数效果很差。
2.3密度聚类:
有效的避免了对分隔聚类下对凹函数聚类效果不好的情况,有效的判别入参主要有1:单点外的半径2:单点外半径内包含的点的个数
DBSCAN为主要常见的算法,可优化的角度是现在密度较高的地方进行聚类,再往密度较低的地方衍生,优化算法:OPTICS。
2.4网格聚类:
将n个点映射到n维上,在不同的网格中,计算点的密度,将点更加密集的网格归为一类。
优点是:超快,超级快,不论多少数据,计算速度只和维度相关。
缺点:n维的n难取,受分布影响较大(部分行业数据分布及其不规则)
2.5模型聚类:
基于概率和神经网络聚类,常见的为GMM,高斯混合模型。缺点为,计算量较大,效率较低。
GMM:每个点出现的概率:将k个高斯模型混合在一起,每个点出现的概率是几个高斯混合的结果
假设有K个高斯分布,每个高斯对data points的影响因子为πk,数据点为x,高斯参数为theta,则:

利用极大似然的方法去求解均值Uk,协方差矩阵(Σk),影响因子πk,但是普通的梯度下降的方法在这里求解会很麻烦,这边就以EM算法代替估计求解。
3.优化数据结构:
1.数据变换:
logit处理,对所有数据进行log变换
傅里叶变换
小波变换
2.降维:
PCA:
利用降维(线性变换)的思想,整体方差最大的情况下(在损失很少信息的前提下),把多个指标转化为几个不相关的综合指标(主成分),将变量线性组合代替原变量,保持代替后的数据信息量最大(方差最大)。
LLE:
(1) 寻找每个样本点的k个近邻点;
(2)由每个样本点的近邻点计算出该样本点的局部重建权值矩阵;
(3)由该样本点的局部重建权值矩阵和其近邻点计算出该样本点的输出值。
(换句话说,就是由周围N个点构成改点的一个向量矩阵表示)