- 我们使用Kafka, 最终都是要存,取消息,今天我们就来看下源码中和消息相关的类;
- 涉及到的类:
- Message
- Record
- MessageSet
- ByteBufferMessageSet
- BufferingOutputStream
- MessageWriter
- FileMessageSet
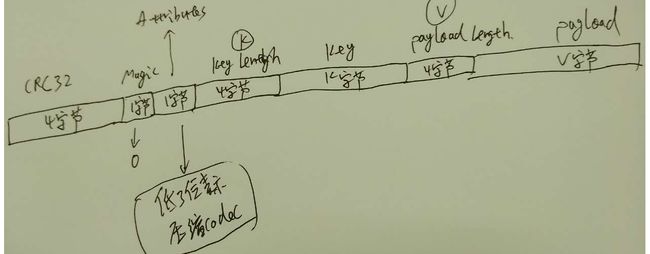
Message类:
- 所在文件: core/src/main/scala/kafka/message/Message.scala
- 作用: kafka系统单条message结构组成
- Message结构:
1.png
- 这个类主要就是使用ByteBuffer来承载Message这个结构, 默认构造函数封装了ByteBuffer, 还提供了一系列的
this构造函数,参数为Message结构的若干个字段; - checksum的计算: checksum的计算从
Magic字段开始, 计算结果写入CRC32字段. - 提供了一系列便捷方法,来获取Message结构中各个字段和属性:
/**
* The complete serialized size of this message in bytes (including crc, header attributes, etc)
*/
def size: Int = buffer.limit
/**
* The length of the key in bytes
*/
def keySize: Int = buffer.getInt(Message.KeySizeOffset)
/**
* The length of the message value in bytes
*/
def payloadSize: Int = buffer.getInt(payloadSizeOffset)
/**
* The magic version of this message
*/
def magic: Byte = buffer.get(MagicOffset)
/**
* The attributes stored with this message
*/
def attributes: Byte = buffer.get(AttributesOffset)
/**
* The compression codec used with this message
*/
def compressionCodec: CompressionCodec =
CompressionCodec.getCompressionCodec(buffer.get(AttributesOffset) & CompressionCodeMask)
/**
* A ByteBuffer containing the content of the message
*/
def payload: ByteBuffer = sliceDelimited(payloadSizeOffset)
Record类
- 实际上kafka源码中没有这个类, kafka中的一条消息是上面我们讲的一个
Message, 但实际上记录到log文件中的不是这个Message, 而是一条Record - Record的结构: 其实很简单
[Offset MessageSize Message], 在一条Message前面加上8字节的Offset和4字节的MessageSize - 实际是多条
Record就构成了我们下面要说的一个MessageSet
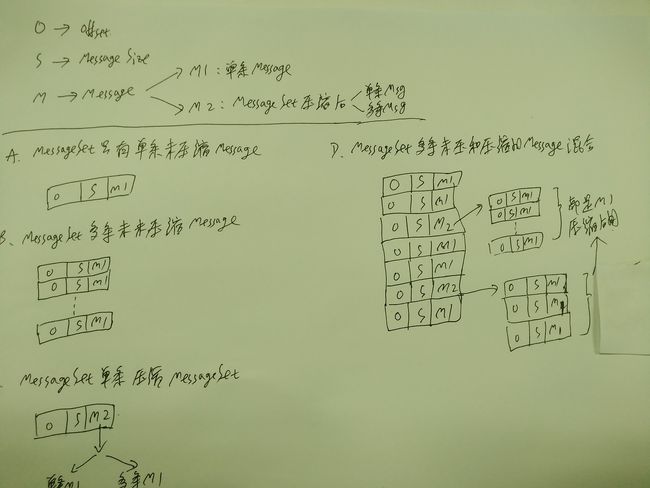
MessageSet类
- 所在文件: core/src/main/scala/kafka/message/MessageSet.scala
- 作用: 存储若干条
Record, 官网上给出的结构:
MessageSet => [Offset MessageSize Message] => 这里就是我们上面说的Record
Offset => int64
MessageSize => int32
Message
- 定义:
abstract class MessageSet extends Iterable[MessageAndOffset]
从定义可以看出MessageSet是个抽象类, 且继承了Iterable[MessageAndOffset], - 主要方法:
-
def iterator: Iterator[MessageAndOffset]: 返回迭代器, 用于迭代所有的MessageAndOffset, 主要是因为它继承了Iterable[MessageAndOffset]; -
def writeTo(channel: GatheringByteChannel, offset: Long, maxSize: Int): Int:写message到指定的Channel
-
- 在
Object Message里其实已经定义了我们上面说的Record:
val MessageSizeLength = 4
val OffsetLength = 8
val LogOverhead = MessageSizeLength + OffsetLength
//这里的entry就是我们说的Record
def entrySize(message: Message): Int = LogOverhead + message.size
- 结构示意图:
2.jpg
ByteBufferMessageSet类
- 所在文件: core/src/main/scala/kafka/message/ByteBufferMessageSet.scala
- 定义:
class ByteBufferMessageSet(val buffer: ByteBuffer) extends MessageSet with Logging- 继承于
MessageSet; - 提供了
ByteBuffer和MessageSet之间的相互转换,MessageSet在内存中的操作
- 继承于
- 主要方法:
-
override def iterator: Iterator[MessageAndOffset] = internalIterator(): 返回迭代器,用来遍历包含的每条MessageAndOffset; 主要是用来从ByteBuffer里抽取Message
1.1 实际上是通过internalIterator()方法返回;
1.2private def internalIterator(isShallow: Boolean = false): Iterator[MessageAndOffset],返回MessageAndOffset的迭代器new IteratorTemplate[MessageAndOffset]
1.3 真正干活的是IteratorTemplate[MessageAndOffset]的override def makeNext(): MessageAndOffset, 实际上就是把上面介绍的MessageSet的结构里的Record一条条解出来, 对于压缩后的MessageSet涉及到一层递归,具体可以参见上面的2.jpg
1.4 放一段核心代码:
-
if(isShallow) { //是不是要作深层迭代需要迭代,就是我们上面2.jpg里的M1
new MessageAndOffset(newMessage, offset) //直接返回一条MessageAndOffset
} else { //需要迭代,就是我们上面2.jpg里的M2
newMessage.compressionCodec match {//根据压缩Codec决定作什么处理
case NoCompressionCodec => //未压缩,直接返回一条MessageAndOffset
innerIter = null
new MessageAndOffset(newMessage, offset)
case _ => //压缩了的MessageSet, 就再深入一层, 逐条解压读取
innerIter = ByteBufferMessageSet.deepIterator(newMessage)
if(!innerIter.hasNext)
innerIter = null
makeNext()
}
}
-
private def create(offsetCounter: AtomicLong, compressionCodec: CompressionCodec, messages: Message*): ByteBuffer: 用于从MessageList到ByteBuffer的转换, 实际上最后生成的ByteBuffer里就是上面说的一条Record
if(messages.size == 0) {
MessageSet.Empty.buffer
} else if(compressionCodec == NoCompressionCodec) {
// 非压缩的
val buffer = ByteBuffer.allocate(MessageSet.messageSetSize(messages))
for(message <- messages)
writeMessage(buffer, message, offsetCounter.getAndIncrement)
buffer.rewind()
buffer
} else {
//压缩的使用 MessageWriter类来写
var offset = -1L
val messageWriter = new MessageWriter(math.min(math.max(MessageSet.messageSetSize(messages) / 2, 1024), 1 << 16))
messageWriter.write(codec = compressionCodec) { outputStream =>
val output = new DataOutputStream(CompressionFactory(compressionCodec, outputStream))
try {
//逐条压缩
for (message <- messages) {
offset = offsetCounter.getAndIncrement
output.writeLong(offset)
output.writeInt(message.size)
output.write(message.buffer.array, message.buffer.arrayOffset, message.buffer.limit)
}
} finally {
output.close()
}
}
//写入buffer作为一条Record
val buffer = ByteBuffer.allocate(messageWriter.size + MessageSet.LogOverhead)
writeMessage(buffer, messageWriter, offset)
buffer.rewind()
buffer
}
-
def writeTo(channel: GatheringByteChannel, offset: Long, size: Int): Int: 写MessageSet到GatheringByteChannel:
// Ignore offset and size from input. We just want to write the whole buffer to the channel.
buffer.mark()
var written = 0
while(written < sizeInBytes)
written += channel.write(buffer)
buffer.reset()
written
}
- Message验证和Offset的重新赋值: 这是一个神奇的函数,在broker把收到的producer request里的MessageSet append到Log之前,以及consumer和follower获取消息之后,都需要进行校验, 这个函数就是这个验证的一部分, 我把相应的说明写在源码里,这个函数在后面讲到处理log append和consumer时我们还会用到.
private[kafka] def validateMessagesAndAssignOffsets(offsetCounter: AtomicLong,
sourceCodec: CompressionCodec,
targetCodec: CompressionCodec,
compactedTopic: Boolean = false): ByteBufferMessageSet = {
if(sourceCodec == NoCompressionCodec && targetCodec == NoCompressionCodec) { // 非压缩的Message
// do in-place validation and offset assignment
var messagePosition = 0
buffer.mark()
while(messagePosition < sizeInBytes - MessageSet.LogOverhead) {
buffer.position(messagePosition)
// 根据参数传入的 offsetCountern 更新当前的Offset
buffer.putLong(offsetCounter.getAndIncrement())
val messageSize = buffer.getInt()
val positionAfterKeySize = buffer.position + Message.KeySizeOffset + Message.KeySizeLength
// 如果是compact topic(比如__cosumer_offsets), key是一定要有的, 这里检查这个key的合法性
if (compactedTopic && positionAfterKeySize < sizeInBytes) {
buffer.position(buffer.position() + Message.KeySizeOffset)
val keySize = buffer.getInt()
if (keySize <= 0) {
buffer.reset()
throw new InvalidMessageException("Compacted topic cannot accept message without key.")
}
}
messagePosition += MessageSet.LogOverhead + messageSize
}
buffer.reset()
this
} else {
// 压缩的Message, 下面源码里的注释已经说得很清楚了
// We need to deep-iterate over the message-set if any of these are true:
// (i) messages are compressed
// (ii) the topic is configured with a target compression codec so we need to recompress regardless of original codec
// 深度迭代, 获取所有的message
val messages = this.internalIterator(isShallow = false).map(messageAndOffset => {
if (compactedTopic && !messageAndOffset.message.hasKey)
throw new InvalidMessageException("Compacted topic cannot accept message without key.")
messageAndOffset.message
})
//使用targetCodec重新压缩
new ByteBufferMessageSet(compressionCodec = targetCodec, offsetCounter = offsetCounter, messages = messages.toBuffer:_*)
}
}
BufferingOutputStream类
- 所在文件: core/src/main/scala/kafka/message/MessageWriter.scala
- 定义:
class BufferingOutputStream(segmentSize: Int) extends OutputStream继承自OutputStream - 作用: 这个来接纳写入它的各种数据类型, 比如int, byte, byte array, 其内部定义了
Segment类,Segment内部使用Array[byte]来存储数据, 多个Segment连成一个链接, 链接可以自动扩展,来存储写入BufferingOutputStream的所有数据 - 主要方法:
- 一组
write函数: 用于写入不能类型的数据; -
def reserve(len: Int): ReservedOutput: 从当前位置开始预留len长度存储空间 -
def writeTo(buffer: ByteBuffer): Unit: 将存储在Segment链接中的数据全部拷贝到ByteBuffer中 .
- 一组
MessageWriter
- 所在文件: core/src/main/scala/kafka/message/MessageWriter.scala
- 定义:
class MessageWriter(segmentSize: Int) extends BufferingOutputStream(segmentSize), 继承自上面的BufferingOutputStream - 作用: 在
ByteBufferMessageSet::create中用到, 将若干条Message构造成多条对应的压缩后的Record, 将这个压缩后的结果再次作为payload构造成一条新的Message; - 主要方法:
- 构造
Message, 添加Crc, 写入Magic, Attribete, key size, key.......
- 构造
def write(key: Array[Byte] = null, codec: CompressionCodec)(writePayload: OutputStream => Unit): Unit = {
withCrc32Prefix {
write(CurrentMagicValue)
var attributes: Byte = 0
if (codec.codec > 0)
attributes = (attributes | (CompressionCodeMask & codec.codec)).toByte
write(attributes)
// write the key
if (key == null) {
writeInt(-1)
} else {
writeInt(key.length)
write(key, 0, key.length)
}
// write the payload with length prefix
withLengthPrefix {
writePayload(this)
}
}
}
FileMessageSet类
- 所在文件:core/src/main/scala/kafka/log/FileMessageSet.scala
- 定义:
class FileMessageSet private[kafka](@volatile var file: File, private[log] val channel: FileChannel, private[log] val start: Int, private[log] val end: Int, isSlice: Boolean) extends MessageSet with Logging - 作用:用于
MessageSet与磁盘文件之前的读取 - 主要方法:
-
def iterator(maxMessageSize: Int): Iterator[MessageAndOffset]: 返回一个迭代器,用于获取对应本地log文件里的每一条Record, 写入到文件里是不是Message,而是Record
override def makeNext(): MessageAndOffset = {
if(location >= end)
return allDone()
// read the size of the item
sizeOffsetBuffer.rewind()
// 先读Record的头部,Offset + MessageSize , 共12字节
channel.read(sizeOffsetBuffer, location)
if(sizeOffsetBuffer.hasRemaining)
return allDone()
sizeOffsetBuffer.rewind()
val offset = sizeOffsetBuffer.getLong()
val size = sizeOffsetBuffer.getInt()
if(size < Message.MinHeaderSize)
return allDone()
if(size > maxMessageSize)
throw new InvalidMessageException("Message size exceeds the largest allowable message size (%d).".format(maxMessageSize))
// read the item itself
// 根所MessageSize读Message
val buffer = ByteBuffer.allocate(size)
channel.read(buffer, location + 12)
if(buffer.hasRemaining)
return allDone()
buffer.rewind()
// increment the location and return the item
location += size + 1
new MessageAndOffset(new Message(buffer), offset)
}
-
def append(messages: ByteBufferMessageSet) { val written = messages.writeTo(channel, 0, messages.sizeInBytes) _size.getAndAdd(written) } :将多条Record`由内存落地到本地Log文件 -
def writeTo(destChannel: GatheringByteChannel, writePosition: Long, size: Int): Int: 将本地Log文件中的Message发送到批定的Channel
val newSize = math.min(channel.size().toInt, end) - start
if (newSize < _size.get()) {
throw new KafkaException("Size of FileMessageSet %s has been truncated during write: old size %d, new size %d"
.format(file.getAbsolutePath, _size.get(), newSize))
}
val position = start + writePosition
val count = math.min(size, sizeInBytes)
val bytesTransferred = (destChannel match {
// 利用sendFile系统调用已零拷贝方式发送给客户端
case tl: TransportLayer => tl.transferFrom(channel, position, count)
case dc => channel.transferTo(position, count, dc)
}).toInt
trace("FileMessageSet " + file.getAbsolutePath + " : bytes transferred : " + bytesTransferred
+ " bytes requested for transfer : " + math.min(size, sizeInBytes))
bytesTransferred
总结
- 我们看到
ByteBufferMessageSet和FileMessageSet都是继承于MessageSet, 也就是说一条Record的结构在内存和本地文件中的存储格式是完全一样的,在Message的读写时不用作多余的转换。