1.安装及入门介绍
推荐直接
pip install jieba
结巴中文分词涉及到的算法包括:
(1) 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);
(2) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3) 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
结巴中文分词支持的三种分词模式包括:
(1) 精确模式:试图将句子最精确地切开,适合文本分析;
(2) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
(3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
同时结巴分词支持繁体分词和自定义字典方法。
#encoding=utf-8
importjieba
#全模式
text ="我来到北京清华大学"
seg_list = jieba.cut(text, cut_all=True)
printu"[全模式]: ","/ ".join(seg_list)
#精确模式
seg_list = jieba.cut(text, cut_all=False)
printu"[精确模式]: ","/ ".join(seg_list)
#默认是精确模式
seg_list = jieba.cut(text)
printu"[默认模式]: ","/ ".join(seg_list)
#新词识别 “杭研”并没有在词典中,但是也被Viterbi算法识别出来了
seg_list = jieba.cut("他来到了网易杭研大厦")
printu"[新词识别]: ","/ ".join(seg_list)
#搜索引擎模式
seg_list = jieba.cut_for_search(text)
printu"[搜索引擎模式]: ","/ ".join(seg_list)
输出如下图所示:

代码中函数简单介绍如下:
jieba.cut():第一个参数为需要分词的字符串,第二个cut_all控制是否为全模式。
jieba.cut_for_search():仅一个参数,为分词的字符串,该方法适合用于搜索引擎构造倒排索引的分词,粒度比较细。
其中待分词的字符串支持gbk\utf-8\unicode格式。返回的结果是一个可迭代的generator,可使用for循环来获取分词后的每个词语,更推荐使用转换为list列表。
2.添加自定义词典
由于"国家5A级景区"存在很多旅游相关的专有名词,举个例子:
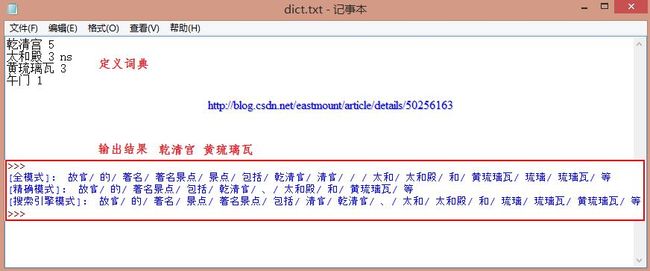
[输入文本] 故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等
[精确模式] 故宫/的/著名景点/包括/乾/清宫/、/太和殿/和/黄/琉璃瓦/等
[全 模 式] 故宫/的/著名/著名景点/景点/包括/乾/清宫/太和/太和殿/和/黄/琉璃/琉璃瓦/等
显然,专有名词"乾清宫"、"太和殿"、"黄琉璃瓦"(假设为一个文物)可能因分词而分开,这也是很多分词工具的又一个缺陷。但是Jieba分词支持开发者使用自定定义的词典,以便包含jieba词库里没有的词语。虽然结巴有新词识别能力,但自行添加新词可以保证更高的正确率,尤其是专有名词。
基本用法:jieba.load_userdict(file_name) #file_name为自定义词典的路径
词典格式和dict.txt一样,一个词占一行;每一行分三部分,一部分为词语,另一部分为词频,最后为词性(可省略,ns为地点名词),用空格隔开。
强烈推荐一篇词性标注文章,链接如下:
http://www.hankcs.com/nlp/part-of-speech-tagging.html
#encoding=utf-8
importjieba
#导入自定义词典
jieba.load_userdict("dict.txt")
#全模式
text ="故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等"
seg_list = jieba.cut(text, cut_all=True)
printu"[全模式]: ","/ ".join(seg_list)
#精确模式
seg_list = jieba.cut(text, cut_all=False)
printu"[精确模式]: ","/ ".join(seg_list)
#搜索引擎模式
seg_list = jieba.cut_for_search(text)
printu"[搜索引擎模式]: ","/ ".join(seg_list)
输出结果如下所示,其中专有名词连在一起,即"乾清宫"和"黄琉璃瓦"。
3.关键词提取
在构建VSM向量空间模型过程或者把文本转换成数学形式计算中,你需要运用到关键词提取的技术,这里就再补充该内容,而其他的如词性标注、并行分词、获取词位置和搜索引擎就不再叙述了。
基本方法:jieba.analyse.extract_tags(sentence, topK)
需要先import jieba.analyse,其中sentence为待提取的文本,topK为返回几个TF/IDF权重最大的关键词,默认值为20。
#encoding=utf-8
importjieba
importjieba.analyse
#导入自定义词典
jieba.load_userdict("dict.txt")
#精确模式
text ="故宫的著名景点包括乾清宫、太和殿和午门等。其中乾清宫非常精美,午门是紫禁城的正门,午门居中向阳。"
seg_list = jieba.cut(text, cut_all=False)
printu"分词结果:"
print"/".join(seg_list)
#获取关键词
tags = jieba.analyse.extract_tags(text, topK=3)
printu"关键词:"
print" ".join(tags)
输出结果如下,其中"午门"出现3次、"乾清宫"出现2次、"著名景点"出现1次,按照顺序输出提取的关键词。如果topK=5,则输出:"午门 乾清宫 著名景点 太和殿 向阳"。
分词结果:
故宫/的/著名景点/包括/乾清宫/、/太和殿/和/午门/等/。/其中/乾清宫/非常/精美/,/午门/是/紫禁城/的/正门/,/午门/居中/向阳/。
关键词:
午门 乾清宫 著名景点
4.对百度百科获取摘要分词
从BaiduSpider文件中读取0001.txt~0204.txt文件,分别进行分词处理再保存。
#encoding=utf-8
importsys
importre
importcodecs
importos
importshutil
importjieba
importjieba.analyse
#导入自定义词典
jieba.load_userdict("dict_baidu.txt")
#Read file and cut
defread_file_cut():
#create path
path ="BaiduSpider\\"
respath ="BaiduSpider_Result\\"
ifos.path.isdir(respath):
shutil.rmtree(respath,True)
os.makedirs(respath)
num =1
whilenum<=204:
name ="%04d"% num
fileName = path + str(name) +".txt"
resName = respath + str(name) +".txt"
source = open(fileName,'r')
ifos.path.exists(resName):
os.remove(resName)
result = codecs.open(resName,'w','utf-8')
line = source.readline()
line = line.rstrip('\n')
whileline!="":
line = unicode(line,"utf-8")
seglist = jieba.cut(line,cut_all=False)#精确模式
output =' '.join(list(seglist))#空格拼接
printoutput
result.write(output +'\r\n')
line = source.readline()
else:
print'End file: '+ str(num)
source.close()
result.close()
num = num +1
else:
print'End All'
#Run function
if__name__ =='__main__':
read_file_cut()
运行结果如下图所示:

5.去除停用词
在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。但是,并没有一个明确的停用词表能够适用于所有的工具。甚至有一些工具是明确地避免使用停用词来支持短语搜索的。[参考百度百科]
#encoding=utf-8
importjieba
#去除停用词
stopwords = {}.fromkeys(['的','包括','等','是'])
text ="故宫的著名景点包括乾清宫、太和殿和午门等。其中乾清宫非常精美,午门是紫禁城的正门。"
segs = jieba.cut(text, cut_all=False)
final =''
forseginsegs:
seg = seg.encode('utf-8')
ifsegnotinstopwords:
final += seg
printfinal
#输出:故宫著名景点乾清宫、太和殿和午门。其中乾清宫非常精美,午门紫禁城正门。
seg_list = jieba.cut(final, cut_all=False)
print"/ ".join(seg_list)
#输出:故宫/ 著名景点/ 乾清宫/ 、/ 太和殿/ 和/ 午门/ 。/ 其中/ 乾清宫/ 非常/ 精美/ ,/ 午门/ 紫禁城/ 正门/ 。
原文参考:http://blog.csdn.net/eastmount/article/details/50256163