对于一个规模很大,访问量很高的Web系统,缓存总是一个不可缺少的重要组成部分。然而一个合适的,高效的缓存设计方案却并非易事。
本文将简单介绍一下缓存设计所要注意的方面,以便让有需求的系统设计者能够很快地了解缓存设计的相关知识。

1、数据库瓶颈
在系统开发中我们经常会发现,用户的并发访问量特别高,如果系统没有相应缓存的支撑,那么对数据库的访问量也就特别大, 所以就要求数据库能够有很好的读写性能;而传统的关系型数据库在处理高并发的场景确实效果不是太理想。
对于一个日均PV千万的大型网站来讲,每天所有的数据读写请求量可能远超出关系型数据的处理能力,更别说在流量峰值的情况下了;所以我们必须要有高效的缓存手段来抵挡住大部分的数据请求, 直接查询缓存中的数据,返回给用户。
2、缓存的类型
缓存就是将数据存放在距离计算最近的位置以加快处理速度,是改变软件性能的第一手段。
现代CPU越来越快的一个重要因素就是使用了更多的缓存,在复杂的软件设计中,缓存几乎无处不在。大型网站架构设计在很多方面都使用了缓存的设计。
CDN
即内容分发网络,部署在距离终端用户最近的网络服务商,用户的网络请求总是先到达他的网络服务商那里,在这里缓存网站的一些静态资源,可以就近以最快的数据返回给用户,如视频网站和门户网站会将用户访问量大的热点内容缓存在CDN。
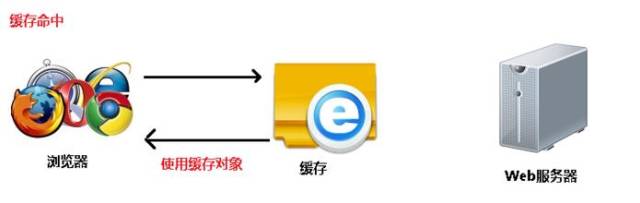
浏览器缓存
对于网站应用而言,css,javascript,logo。。。这些静态资源文件更新的频率都比较低,这些文件又几乎每次HTTP请求都需要,如果将这些文件缓存在浏览器中,可以很好的改善网站的性能。通过设置HTTP头中Cache-Control和Expire的属性,可设定浏览器缓存,缓存的时间可以是数天,甚至是几个月。
如图:
反向代理
反向代理属于网站前端架构的一部分,部署在网站的前端,当用户请求到达网站的数据中心时,最先访问到的就是反向代理服务器,这里缓存网站的静态资源,无需将请求继续转发给应用服务器就能返回给用户。
本地缓存
在应用服务器本地缓存着热点数据,应用程序可以在本机内存直接访问数据,无需访问数据库。
集中式缓存
大型网站的数据量非常庞大,即使只缓存一小部分,需要的内容空间也不是单机能承受的,所以除了本地缓存,还需要分布式缓存,将数据缓存在一个专门的分布式缓存集群中,应用程序通过网络通信访问缓存数据。
数据库的缓存
目前主流的数据库都提供了查询缓存,不同的数据库有着不同的实现,比如Oracle会在SGA开辟专门的查询缓存,当Oracle接收到一条查询语句之后,首先会进行语法,语义检查,然后会查看缓存是否有相同的语句,如果有则选择已经生成的执行计划和优化方案,如果没有命中,则Oracle会进行相应的解析生成相应的执行计划和优化方案,然后对查询数据进行hash算法存储到缓存中。
使用缓存有两个前提条件:
①数据访问热点不均衡,某些数据会被更频繁的访问,这些数据应该放在缓存中;
②数据在某个时间段内有效,不会很快过期,否则缓存的数据就会因已经失效而产生脏读,影响结果的正确性。
网站应用中,缓存除了可以加快数据的访问速度,还可以减轻后端应用和数据存储的负载压力,这一点对网站数据库架构至关重要,网站数据库几乎都是按照有缓存的前提进行负载能力设计的。
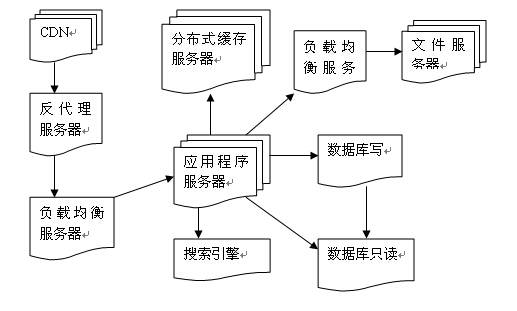
3、缓存的设计与策略
缓存对象
缓存主要用来存放那些读写比很高,很少变化的数据,如商品的类目信息,热门词的搜索列表信息,热门商品信息等。应用程序读取数据时,先到缓存中读取,如果读取不到或数据已失效,再访问数据库,并将数据写入缓存。网站数据访问通常遵循二八定律,即80%的访问落在20%的数据上,因此利用Hash表和内存的高速访问特性,将这20%的数据缓存起来,可以很好的改善系统的性能,提高数据的读取数度,降低存储的访问压力。
缓存更新策略
主要有两种方式:被动失效和主动更新。
被动失效
缓存中的数据主要用来满足读的请求。被动失效策略是指对缓存中的数据设置一个失效的时间,或当数据库中的数据有更新的时候,删除掉缓存中的数据。当再次请求的时候,发现数据已经不再或者已经失效了,则需要重新访问数据库,然后更新缓存。
被动失效策略中存在一个问题:从缓存失效或者丢失开始直到新的数据再次被更新到缓存中的这段时间,所有的读请求都将会直接落到数据库上;而对于一个大访问量的系统来说,这有可能会带来风险。这就需要另外一种更新策略。
主动更新
我们提到主动更新主要是为了解决空窗期的问题,但是这同样会带来另一个问题,就是并发更新的情况;
在集群环境下,多台应用服务器同时访问一份数据是很正常的,这样就会存在一台服务器读取并修改了缓存数据,但是还没来得及写入的情况下,另一台服务器也读取并修改旧的数据,这时候,后写入的将会覆盖前面的,从而导致数据丢失;这也是分布式系统开发中,必然会遇到的一个问题。
解决的方式主要有三种:
锁控制
这种方式一般在客户端实现(在服务端加锁是另外一种情况),其基本原理就是使用读写锁,即任何进程要调用写方法时,先要获取一个排他锁,阻塞住所有的其他访问,等自己完全修改完后才能释放;如果遇到其他进程也正在修改或读取数据,那么则需要等待; 锁控制虽然是一种方案,但是很少有真的这样去做的,其缺点显而易见,其并发性只存在于读操作之间,只要有写操作存在,就只能串行。
版本控制
这种方式也有两种实现,一种是单版本机制,即为每份数据保存一个版本号,当缓存数据写入时,需要传入这个版本号,然后服务端将传入的版本号和数据当前的版本号进行比对,如果大于当前版本,则成功写入,否则返回失败;这样解决方式比较简单;但是增加了高并发下客户端的写失败概率。
多版本机制
即存储系统为每个数据保存多份,每份都有自己的版本号,互不冲突,然后通过一定的策略来定期合并,再或者就是交由客户端自己去选择读取哪个版本的数据。很多分布式缓存一般会使用单版本机制,而很多NoSQL则使用后者。

4、常见的分布式缓存比较
Memcached
简单的通讯协议
远程通信设计需要考虑两方面的要素,一是通信协议,即选择TCP协议还是UDP协议,抑或HTTP协议;一是通信序列化协议,数据传输的两端,必须使用彼此可以识别的数据序列化方式才能使通信得以完成,如XML,JSON等文本序列化协议,或者google protobuffer等二进制序列化协议。Memcached使用TCP协议。
丰富的客户端程
Memcached通信协议非常简单,只要支持该协议的客户端都可以和Memcached服务器通信,因此Memcached发展出非常丰富的客户端程序,几乎支持所有主流的网站编程语言,JAVA,C/C++/C#,PHP,Python。
高性能的网络通信
Memcached服务端通信模块基于Libevent,一个支持事件触发的网络通信程序库。Libevent的设计和实现有许多值得改善的地方,但它在稳定的长连接方面的表现确是Memcached需要的。
高效的内存管理
内存管理中一个令人头痛的问题就是内存碎片的管理。操作系统,虚拟机垃圾回收在这方面想了许多办法:压缩,复制等。Memcached使用了一个非常简单的办法--固定空间分配。
Redis
Redis除了像Memcached那样支持普通的类型的存储外,还支持List、Set、Map等集合类型的存储,这种特性有时候在业务开发中会比较方便;
Redis支持数据的备份,即master-slave模式的数据备份。
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
在Redis中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别。
内存数据库
这里的内存数据库只要是指关系型内存数据库。一般来说,内存数据库使用场景可大致分为两种情况:
①对数据计算实时性要求比较高,基于磁盘的数据库很难处理;同时又要依赖关系型数据库的一些特性,比如说排序、加合、复杂条件查询等等;这样的数据一般是临时的数据,生命周期比较短,计算完成或者是进程结束时即可丢弃;
②数据的访问量比较大,但是数据量却不大,这样即便丢失也可以很快的从持久化存储中把数据加载进内存。
但不管是在哪种场景中,存在于内存数据库中的数据都必须是相对独立的或者是只服务于读请求的,这样不需要复杂的数据同步处理。
总结
Web系统中缓存的设计方案有很多,各有各的使用场景,我们总能找到一款适合自己系统的缓存策略。
参考文献:
1.李智慧 《大型网站技术架构》
2.腾讯网文 《大型web系统数据缓存设计》
本文作者:单绍国(点融黑帮),点融网FinTech团队高级软件工程师,5年外企工作经验,8年来一直从事于金融项目的研究与开发,平时喜欢研究新的技术,尤其对互联网系统的架构很感兴趣。