ACache介绍:
ACache类似于SharedPreferences,但是比SharedPreferences功能更加强大,SharedPreferences只能保存一些基本数据类型、Serializable、Bundle等数据。
而Acache可以缓存如下数据:
普通的字符串、JsonObject、JsonArray、Bitmap、Drawable、序列化的java对象,和 byte数据。
主要特色:
- 1:轻,轻到只有一个JAVA文件。
- 2:可配置,可以配置缓存路径,缓存大小,缓存数量等。
- 3:可以设置缓存超时时间,缓存超时自动失效,并被删除。
- 4:支持多进程。
应用场景:
- 1、替换SharePreference当做配置文件
- 2、可以缓存网络请求数据,比如oschina的android客户端可以缓存http请求的新闻内容,缓存时间假设为1个小时,超时后自动失效,让客户端重新请求新的数据,减少客户端流量,同时减少服务器并发量。
下载链接:https://github.com/yangfuhai/ASimpleCache
2、Android缓存机制
Android缓存分为内存缓存和文件缓存(磁盘缓存)。在早期,各大图片缓存框架流行之前,常用的内存缓存方式是软引用(SoftReference)和弱引用(WeakReference),如大部分的使用方式:HashMap
2.1 内存缓存——LruCache源码分析
2.1.1 LRU
LRU,全称Least Rencetly Used,即最近最少使用,是一种非常常用的置换算法,也即淘汰最长时间未使用的对象。LRU在操作系统中的页面置换算法中广泛使用,我们的内存或缓存空间是有限的,当新加入一个对象时,造成我们的缓存空间不足了,此时就需要根据某种算法对缓存中原有数据进行淘汰货删除,而LRU选择的是将最长时间未使用的对象进行淘汰。
2.1.2 LruCache实现原理
根据LRU算法的思想,要实现LRU最核心的是要有一种数据结构能够基于访问顺序来保存缓存中的对象,这样我们就能够很方便的知道哪个对象是最近访问的,哪个对象是最长时间未访问的。LruCache选择的是LinkedHashMap这个数据结构,LinkedHashMap是一个双向循环链表,在构造LinkedHashMap时,通过一个boolean值来指定LinkedHashMap中保存数据的方式,LinkedHashMap的一个构造方法如下:
/*
* 初始化LinkedHashMap
* 第一个参数:initialCapacity,初始大小
* 第二个参数:loadFactor,负载因子=0.75f
* 第三个参数:accessOrder=true,基于访问顺序;accessOrder=false,基于插入顺序
*/
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
init();
this.accessOrder = accessOrder;
}
显然,在LruCache中选择的是accessOrder = true;此时,当accessOrder 设置为 true时,每当我们更新(即调用put方法)或访问(即调用get方法)map中的结点时,LinkedHashMap内部都会将这个结点移动到链表的尾部,因此,在链表的尾部是最近刚刚使用的结点,在链表的头部是是最近最少使用的结点,当我们的缓存空间不足时,就应该持续把链表头部结点移除掉,直到有剩余空间放置新结点。
可以看到,LinkedHashMap完成了LruCache中的核心功能,那LruCache中剩下要做的就是定义缓存空间总容量,当前保存数据已使用的容量,对外提供put、get方法。
2.1.3 LruCache源码分析
在了解了LruCache的核心原理之后,就可以开始分析LruCache的源码了。
(1)关键字段
根据上面的分析,首先要有总容量、已使用容量、linkedHashMap这几个关键字段,LruCache中提供了下面三个关键字段
//核心数据结构
private final LinkedHashMap map;
// 当前缓存数据所占的大小
private int size;
//缓存空间总容量
private int maxSize;
要注意的是size字段,因为map中可以存放各种类型的数据,这些数据的大小测量方式也是不一样的,比如Bitmap类型的数据和String类型的数据计算他们的大小方式肯定不同,因此,LruCache中在计算放入数据大小的方法sizeOf中,只是简单的返回了1,需要我们重写这个方法,自己去定义数据的测量方式。因此,我们在使用LruCache的时候,经常会看到这种方式:
private static final int CACHE_SIZE = 4 * 1024 * 1024;//4Mib
LruCache bitmapCache = new LruCache(CACHE_SIZE){
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getByteCount();//自定义Bitmap数据大小的计算方式
}
};
(2)构造方法
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap(0, 0.75f, true);
}
LruCache只有一个唯一的构造方法,在构造方法中,给定了缓存空间的总大小,初始化了LinkedHashMap核心数据结构,在LinkedHashMap中的第三个参数指定为true,也就设置了accessOrder=true,表示这个LinkedHashMap将是基于数据的访问顺序进行排序。
(3)sizeOf()和safeSizeOf()方法
根据上面的解释,由于各种数据类型大小测量的标准不统一,具体测量的方法应该由使用者来实现,如上面给出的一个在实现LruCache时重写sizeOf的一种常用实现方式。通过多态的性质,再具体调用sizeOf时会调用我们重写的方法进行测量,LruCache对sizeOf()的调用进行一层封装,如下
private int safeSizeOf(K key, V value) {
int result = sizeOf(key, value);
if (result < 0) {
throw new IllegalStateException("Negative size: " + key + "=" + value);
}
return result;
}
里面其实就是调用sizeOf()方法,返回sizeOf计算的大小。
上面就是LruCache的基本内容,下面就需要提供LruCache的核心功能了。
(4)put方法缓存数据
首先看一下它的源码实现:
/**
* 给对应key缓存value,并且将该value移动到链表的尾部。
*/
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
// 记录 put 的次数
putCount++;
// 通过键值对,计算出要保存对象value的大小,并更新当前缓存大小
size += safeSizeOf(key, value);
/*
* 如果 之前存在key,用新的value覆盖原来的数据, 并返回 之前key 的value
* 记录在 previous
*/
previous = map.put(key, value);
// 如果之前存在key,并且之前的value不为null
if (previous != null) {
// 计算出 之前value的大小,因为前面size已经加上了新的value数据的大小,此时,需要再次更新size,减去原来value的大小
size -= safeSizeOf(key, previous);
}
}
// 如果之前存在key,并且之前的value不为null
if (previous != null) {
/*
* previous值被剔除了,此次添加的 value 已经作为key的 新值
* 告诉 自定义 的 entryRemoved 方法
*/
entryRemoved(false, key, previous, value);
}
//裁剪缓存容量(在当前缓存数据大小超过了总容量maxSize时,才会真正去执行LRU)
trimToSize(maxSize);
return previous;
}
可以看到,put()方法主要有以下几步:
1)key和value判空,说明LruCache中不允许key和value为null;
2)通过safeSizeOf()获取要加入对象数据的大小,并更新当前缓存数据的大小;
3)将新的对象数据放入到缓存中,即调用LinkedHashMap的put方法,如果原来存在该key时,直接替换掉原来的value值,并返回之前的value值,得到之前value的大小,更新当前缓存数据的size大小;如果原来不存在该key,则直接加入缓存即可;
4)清理缓存空间,如下;
(5)trimToSize()清理缓存空间
当我们加入一个数据时(put),为了保证当前数据的缓存所占大小没有超过我们指定的总大小,通过调用trimToSize()来对缓存空间进行管理控制。如下:
public void trimToSize(int maxSize) {
/*
* 循环进行LRU,直到当前所占容量大小没有超过指定的总容量大小
*/
while (true) {
K key;
V value;
synchronized (this) {
// 一些异常情况的处理
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(
getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
// 首先判断当前缓存数据大小是否超过了指定的缓存空间总大小。如果没有超过,即缓存中还可以存入数据,直接跳出循环,清理完毕
if (size <= maxSize || map.isEmpty()) {
break;
}
/**
* 执行到这,表示当前缓存数据已超过了总容量,需要执行LRU,即将最近最少使用的数据清除掉,直到数据所占缓存空间没有超标;
* 根据前面的原理分析,知道,在链表中,链表的头结点是最近最少使用的数据,因此,最先清除掉链表前面的结点
*/
Map.Entry toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
// 移除掉后,更新当前数据缓存的大小
size -= safeSizeOf(key, value);
// 更新移除的结点数量
evictionCount++;
}
/*
* 通知某个结点被移除,类似于回调
*/
entryRemoved(true, key, value, null);
}
}
trimToSize()方法的作用就是为了保证当前数据的缓存大小不能超过我们指定的缓存总大小,如果超过了,就会开始移除最近最少使用的数据,直到size符合要求。trimToSize()方法在put()的时候一定会调用,在get()的时候有可能会调用。
(6)get方法获取缓存数据
get方法源码如下:
/**
* 根据查询缓存,如果该对应的存在于缓存,直接返回;
*访问到这个结点时,LinkHashMap会将它移动到双向循环链表的的尾部。
* 如果如果没有缓存的值,则返回。(如果开发者重写了create()的话,返回创建的value
*/
public final V get(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
// LinkHashMap 如果设置按照访问顺序的话,这里每次get都会重整数据顺序
mapValue = map.get(key);
// 计算 命中次数
if (mapValue != null) {
hitCount++;
return mapValue;
}
// 计算 丢失次数
missCount++;
}
/*
* 官方解释:
* 尝试创建一个值,这可能需要很长时间,并且Map可能在create()返回的值时有所不同。如果在create()执行的时
* 候,用这个key执行了put方法,那么此时就发生了冲突,我们在Map中删除这个创建的值,释放被创建的值,保留put进去的值。
*/
V createdValue = create(key);
if (createdValue == null) {
return null;
}
/***************************
*不覆写方法走不到下面
***************************
/*
* 正常情况走不到这里
* 走到这里的话 说明 实现了自定义的 create(K key) 逻辑
* 因为默认的 create(K key) 逻辑为null
*/
synchronized (this) {
// 记录 create 的次数
createCount++;
// 将自定义create创建的值,放入LinkedHashMap中,如果key已经存在,会返回 之前相同key 的值
mapValue = map.put(key, createdValue);
// 如果之前存在相同key的value,即有冲突。
if (mapValue != null) {
/*
* 有冲突
* 所以 撤销 刚才的 操作
* 将 之前相同key 的值 重新放回去
*/
map.put(key, mapValue);
} else {
// 拿到键值对,计算出在容量中的相对长度,然后加上
size += safeSizeOf(key, createdValue);
}
}
// 如果上面 判断出了 将要放入的值发生冲突
if (mapValue != null) {
/*
* 刚才create的值被删除了,原来的 之前相同key 的值被重新添加回去了
* 告诉 自定义 的 entryRemoved 方法
*/
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
// 上面 进行了 size += 操作 所以这里要重整长度
trimToSize(maxSize);
return createdValue;
}
}
get()方法的思路就是:
1)先尝试从map缓存中获取value,即mapVaule = map.get(key);如果mapVaule != null,说明缓存中存在该对象,直接返回即可;
2)如果mapVaule == null,说明缓存中不存在该对象,大多数情况下会直接返回null;但是如果我们重写了create()方法,在缓存没有该数据的时候自己去创建一个,则会继续往下走,中间可能会出现冲突,看注释;
3)注意:在我们通过LinkedHashMap进行get(key)或put(key,value)时都会对链表进行调整,即将刚刚访问get或加入put的结点放入到链表尾部。
(7)entryRemoved()
entryRemoved的源码如下:
/**
* 1.当被回收或者删掉时调用。该方法当value被回收释放存储空间时被remove调用
* 或者替换条目值时put调用,默认实现什么都没做。
* 2.该方法没用同步调用,如果其他线程访问缓存时,该方法也会执行。
* 3.evicted=true:如果该条目被删除空间 (表示 进行了trimToSize or remove) evicted=false:put冲突后 或 get里成功create后
* 导致
* 4.newValue!=null,那么则被put()或get()调用。
*/
protected void entryRemoved(boolean evicted, K key, V oldValue, V newValue) {
}
可以发现entryRemoved方法是一个空方法,说明这个也是让开发者自己根据需求去重写的。entryRemoved()主要作用就是在结点数据value需要被删除或回收的时候,给开发者的回调。开发者就可以在这个方法里面实现一些自己的逻辑:
(1)可以进行资源的回收;
(2)可以实现二级内存缓存,可以进一步提高性能,思路如下:重写LruCache的entryRemoved()函数,把删除掉的item,再次存入另外一个LinkedHashMap>中,这个数据结构当做二级缓存,每次获得图片的时候,先判断LruCache中是否缓存,没有的话,再判断这个二级缓存中是否有,如果都没有再从sdcard上获取。sdcard上也没有的话,就从网络服务器上拉取。
entryRemoved()在LruCache中有四个地方进行了调用:put()、get()、trimToSize()、remove()中进行了调用。
(8)LruCache的线程安全性
LruCache是线程安全的,因为在put、get、trimToSize、remove的方法中都加入synchronized进行同步控制。
2.1.4 LruCache的使用
上面就是整个LruCache中比较核心的的原理和方法,对于LruCache的使用者来说,我们其实主要注意下面几个点:
(1)在构造LruCache时提供一个总的缓存大小;
(2)重写sizeOf方法,对存入map的数据大小进行自定义测量;
(3)根据需要,决定是否要重写entryRemoved()方法;
(4)使用LruCache提供的put和get方法进行数据的缓存
小结:
LruCache 自身并没有释放内存,只是 LinkedHashMap中将数据移除了,如果数据还在别的地方被引用了,还是有泄漏问题,还需要手动释放内存;
覆写entryRemoved方法能知道 LruCache 数据移除是是否发生了冲突(冲突是指在map.put()的时候,对应的key中是否存在原来的值),也可以去手动释放资源;
2.2磁盘缓存(文件缓存)——DiskLruCache分析
LruCache是一种内存缓存策略,但是当存在大量图片的时候,我们指定的缓存内存空间可能很快就会用完,这个时候,LruCache就会频繁的进行trimToSize()操作,不断的将最近最少使用的数据移除,当再次需要该数据时,又得从网络上重新加载。为此,Google提供了一种磁盘缓存的解决方案——DiskLruCache(DiskLruCache并没有集成到Android源码中,在Android Doc的例子中有讲解)。
2.2.1 DiskLruCache实现原理
我们可以先来直观看一下,使用了DiskLruCache缓存策略的APP,缓存目录中是什么样子,如下图:
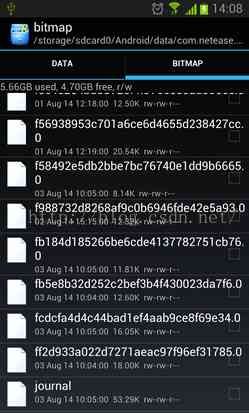
可以看到,缓存目录中有一堆文件名很长的文件,这些文件就是我们缓存的一张张图片数据,在最后有一个文件名journal的文件,这个journal文件是DiskLruCache的一个日志文件,即保存着每张缓存图片的操作记录,journal文件正是实现DiskLruCache的核心。看到出现了journal文件,基本可以说明这个APP使用了DiskLruCache缓存策略。
根据对LruCache的分析,要实现LRU,最重要的是要有一种数据结构能够基于访问顺序来保存缓存中的对象,LinkedHashMap是一种非常合适的数据结构,为此,DiskLruCache也选择了LinkedHashMap作为维护访问顺序的数据结构,但是,对于DiskLruCache来说,单单LinkedHashMap是不够的,因为我们不能像LruCache一样,直接将数据放置到LinkedHashMap的value中,也就是处于内存当中,在DiskLruCache中,数据是缓存到了本地文件,这里的LinkedHashMap中的value只是保存的是value的一些简要信息Entry,如唯一的文件名称、大小、是否可读等信息,如:
private final class Entry {
private final String key;
/** Lengths of this entry's files. */
private final long[] lengths;
/** True if this entry has ever been published */
private boolean readable;
/** The ongoing edit or null if this entry is not being edited. */
private Editor currentEditor;
/** The sequence number of the most recently committed edit to this entry. */
private long sequenceNumber;
private Entry(String key) {
this.key = key;
this.lengths = new long[valueCount];
}
public String getLengths() throws IOException {
StringBuilder result = new StringBuilder();
for (long size : lengths) {
result.append(' ').append(size);
}
return result.toString();
}
/**
* Set lengths using decimal numbers like "10123".
*/
private void setLengths(String[] strings) throws IOException {
if (strings.length != valueCount) {
throw invalidLengths(strings);
}
try {
for (int i = 0; i < strings.length; i++) {
lengths[i] = Long.parseLong(strings[i]);
}
} catch (NumberFormatException e) {
throw invalidLengths(strings);
}
}
private IOException invalidLengths(String[] strings) throws IOException {
throw new IOException("unexpected journal line: " + Arrays.toString(strings));
}
public File getCleanFile(int i) {
return new File(directory, key + "." + i);
}
public File getDirtyFile(int i) {
return new File(directory, key + "." + i + ".tmp");
}
DiskLruCache中对于LinkedHashMap定义如下
private final LinkedHashMap lruEntries
= new LinkedHashMap(0, 0.75f, true);
在LruCache中,由于数据是直接缓存中内存中,map中数据的建立是在使用LruCache缓存的过程中逐步建立的,而对于DiskLruCache,由于数据是缓存在本地文件,相当于是持久保存下来的一个文件,即使程序退出文件还在,因此,map中数据的建立,除了在使用DiskLruCache过程中建立外,map还应该包括之前已经存在的缓存文件,因此,在获取DiskLruCache的实例时,DiskLruCache会去读取journal这个日志文件,根据这个日志文件中的信息,建立map的初始数据,同时,会根据journal这个日志文件,维护本地的缓存文件。构造DiskLruCache的方法如下:
public static DiskLruCache open(File directory, int appVersion, int valueCount, long maxSize)
throws IOException {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
if (valueCount <= 0) {
throw new IllegalArgumentException("valueCount <= 0");
}
// prefer to pick up where we left off
DiskLruCache cache = new DiskLruCache(directory, appVersion, valueCount, maxSize);
if (cache.journalFile.exists()) {
try {
cache.readJournal();
cache.processJournal();
cache.journalWriter = new BufferedWriter(new FileWriter(cache.journalFile, true),IO_BUFFER_SIZE);
return cache;
} catch (IOException journalIsCorrupt) {
// System.logW("DiskLruCache " + directory + " is corrupt: "
// + journalIsCorrupt.getMessage() + ", removing");
cache.delete();
}
}
// create a new empty cache
directory.mkdirs();
cache = new DiskLruCache(directory, appVersion, valueCount, maxSize);
cache.rebuildJournal();
return cache;
}
其中,
cache.readJournal();
cache.processJournal();
正是去读取journal日志文件,建立起map中的初始数据,同时维护缓存文件。
那journal日志文件到底保存了什么信息呢,一个标准的journal日志文件信息如下:
libcore.io.DiskLruCache//第一行,固定内容,声明
1 //第二行,cache的版本号,恒为1
1 //第三行,APP的版本号
2 //第四行,一个key,可以存放多少条数据valueCount
//第五行,空行分割行
DIRTY335c4c6028171cfddfbaae1a9c313c52
CLEAN335c4c6028171cfddfbaae1a9c313c523934
REMOVE335c4c6028171cfddfbaae1a9c313c52
DIRTY1ab96a171faeeee38496d8b330771a7a
CLEAN1ab96a171faeeee38496d8b330771a7a1600234
READ335c4c6028171cfddfbaae1a9c313c52
READ3400330d1dfc7f3f7f4b8d4d803dfcf6
前五行称为journal日志文件的头,下面部分的每一行会以四种前缀之一开始:DIRTY、CLEAN、REMOVE、READ。
以一个DIRTY前缀开始的,后面紧跟着缓存图片的key。以DIRTY这个这个前缀开头,意味着这是一条脏数据。每当我们调用一次DiskLruCache的edit()方法时,都会向journal文件中写入一条DIRTY记录,表示我们正准备写入一条缓存数据,但不知结果如何。然后调用commit()方法表示写入缓存成功,这时会向journal中写入一条CLEAN记录,意味着这条“脏”数据被“洗干净了”,调用abort()方法表示写入缓存失败,这时会向journal中写入一条REMOVE记录。也就是说,每一行DIRTY的key,后面都应该有一行对应的CLEAN或者REMOVE的记录,否则这条数据就是“脏”的,会被自动删除掉。
在CLEAN前缀和key后面还有一个数值,代表的是该条缓存数据的大小。
因此,我们可以总结DiskLruCache中的工作流程:
1)初始化:通过open()方法,获取DiskLruCache的实例,在open方法中通过readJournal(); 方法读取journal日志文件,根据journal日志文件信息建立map中的初始数据;然后再调用processJournal();方法对刚刚建立起的map数据进行分析,分析的工作,一个是计算当前有效缓存文件(即被CLEAN的)的大小,一个是清理无用缓存文件;
2)数据缓存与获取缓存:上面的初始化工作完成后,我们就可以在程序中进行数据的缓存功能和获取缓存的功能了;
缓存数据的操作是借助DiskLruCache.Editor这个类完成的,这个类也是不能new的,需要调用DiskLruCache的edit()方法来获取实例,如下所示:
publicEditoredit(Stringkey)throwsIOException
在写入完成后,需要进行commit()。如下一个简单示例:
new Thread(new Runnable() {
@Override
public void run() {
try {
String imageUrl = "[https://img.my.csdn.net/uploads/201309/01/1378037235_7476.jpg](https://img.my.csdn.net/uploads/201309/01/1378037235_7476.jpg)";
String key = hashKeyForDisk(imageUrl);/MD5对url进行加密,这个主要是为了获得统一的16位字符
DiskLruCache.Editor editor = mDiskLruCache.edit(key);//拿到Editor,往journal日志中写入DIRTY记录
if(editor !=null) {
OutputStream outputStream = editor.newOutputStream(``0``);
if (downloadUrlToStream(imageUrl, outputStream)) { //downloadUrlToStream方法为下载图片的方法,并且将输出流放到outputStream
editor.commit();//完成后记得commit(),成功后,再往journal日志中写入CLEAN记录
}else {
editor.abort();//失败后,要remove缓存文件,往journal文件中写入REMOVE记录
}
}
mDiskLruCache.flush();//将缓存操作同步到journal日志文件,不一定要在这里就调用
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
注意每次调用edit()时,会向journal日志文件写入DIRTY为前缀的一条记录;文件保存成功后,调用commit()时,也会向journal日志中写入一条CLEAN为前缀的一条记录,如果失败,需要调用abort(),abort()里面会向journal文件写入一条REMOVE为前缀的记录。
获取缓存数据是通过get()方法实现的,如下一个简单示例:
try{
String imageUrl ="[https://img.my.csdn.net/uploads/201309/01/1378037235_7476.jpg](https://img.my.csdn.net/uploads/201309/01/1378037235_7476.jpg)";
String key = hashKeyForDisk(imageUrl);` `//MD5对url进行加密,这个主要是为了获得统一的16位字符
//通过get拿到value的Snapshot,里面封装了输入流、key等信息,调用get会向journal文件写入READ为前缀的记录
DiskLruCache.Snapshot snapShot = mDiskLruCache.get(key);
if(snapShot !=null) {
InputStream is = snapShot.getInputStream(0);
Bitmap bitmap = BitmapFactory.decodeStream(is);
mImage.setImageBitmap(bitmap);
}
}catch(IOException e) {
e.printStackTrace();
}
3)合适的地方进行flush()
在上面进行数据缓存或获取缓存的时候,调用不同的方法会往journal中写入不同前缀的一行记录,记录写入是通过IO下的Writer写入的,要真正生效,还需要调用writer的flush()方法,而DiskLruCache中的flush()方法中封装了writer.flush()的操作,因此,我们只需要在合适地方调用DiskLruCache中的flush()方法即可。其作用也就是将操作记录同步到journal文件中,这是一个消耗效率的IO操作,我们不用每次一往journal中写数据后就调用flush,这样对效率影响较大,可以在Activity的onPause()中调用一下即可。
小结&注意:
(1)我们可以在在UI线程中检测内存缓存,即主线程中可以直接使用LruCache;
(2)使用DiskLruCache时,由于缓存或获取都需要对本地文件进行操作,因此需要另开一个线程,在子线程中检测磁盘缓存、保存缓存数据,磁盘操作从来不应该在UI线程中实现;
(3)LruCache内存缓存的核心是LinkedHashMap,而DiskLruCache的核心是LinkedHashMap和journal日志文件,相当于把journal看作是一块“内存”,LinkedHashMap的value只保存文件的简要信息,对缓存文件的所有操作都会记录在journal日志文件中。
DiskLruCache可能的优化方案:
DiskLruCache是基于日志文件journal的,这就决定了每次对缓存文件的操作都需要进行日志文件的记录,我们可以不用journal文件,在第一次构造DiskLruCache的时候,直接从程序访问缓存目录下的缓存文件,并将每个缓存文件的访问时间作为初始值记录在map的value中,每次访问或保存缓存都更新相应key对应的缓存文件的访问时间,这样就避免了频繁的IO操作,这种情况下就需要使用单例模式对DiskLruCache进行构造了,上面的Acache轻量级的数据缓存类就是这种实现方式。
2.3 二级缓存
LruCache内存缓存在解决数据量不是很大的情况下效果不错,当数据很大时,比图需要加载大量图片,LruCache指定的缓存容量可能很快被耗尽,此时LruCache频繁的替换移除淘汰文件,又频繁要进行网络请求,很有可能出现OOM,为此,在大量数据的情况下,我们可以将磁盘缓存DiskLruCache作为一个二级缓存的模式,优化缓存方案。
流程就是,
(1)当我们需要缓存数据的时候,既在内存中缓存,也将文件缓存到磁盘;
(2)当获取缓存文件时,先尝试从内存缓存中获取,如果存在,则直接返回该文件;如果不存在,则从磁盘缓存中获取,如果磁盘缓存中还没有,那就只能从网络获取,获取到数据后,同时在内存和磁盘中进行缓存。