一.前期准备
1.1 Win7官网下载hadoop包
本文使用版本hadoop-2.6.5.tar.gz
1.2 配置jdk
jdk1.7:linux jdk安装和配置
1.3 centos7集群服务器
主机名 系统 IP地址
master centos7 192.168.32.128
slave01 centos7 192.168.32.131
slave02 centos7 192.168.32.132
1.4 多服务器ssh免密码登陆
由于Hadoop启动以后,namenode是通过SSH(Secure Shell)来启动和停止各个节点上的各种守护进程的,这就需要在节点之间执行指令的时候是不需要输入密码的方式,故我们需要配置SSH使用无密码公钥认证的方式。
ssh:SSH免密码登录详解
1.5 集群服务器名称配置
本文默认使用root用户登录,未新建hadoop专用登录名。
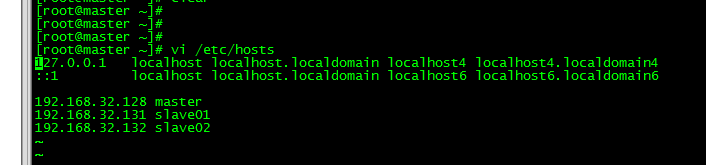
1.5.1 配置各个服务器ip地址对应的别名
vi /etc/hosts
#配置ip对应名
192.168.32.128 master
192.168.32.131 slave01
192.168.32.132 slave02
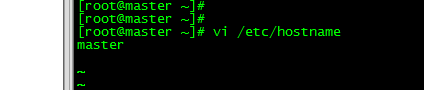
1.5.2 本地主机名配置
vi /etc/hostname
master
三台服务器依次修改,并重启。
二.hadoop完全分布式集群搭建
以下操作只针对master主机服务器,其他主机服务器类似。
2.1 上传hadoop包至 /opt/software目录
2.2 解压和拷贝hadoop至 /usr/local/hadoop
cd /opt/software
tar -zxvf hadoop-2.6.5.tar.gz
cp -r hadoop-2.6.5 /usr/local/hadoop

hadoop解压和拷贝完成
三.hadoop完全分布式集群配置
3.1 系统文件profile配置
配置系统环境变量
vi /etc/profile
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

退出保存,重启配置
source /etc/profile
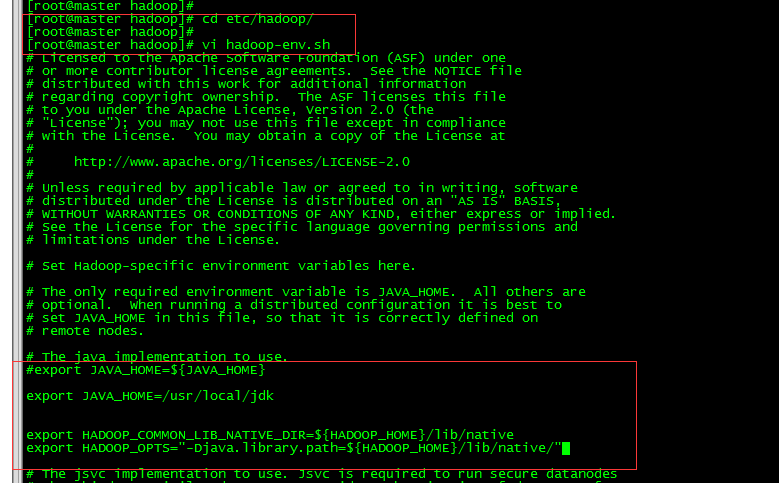
3.2 hadoop-env.sh文件配置
cd /usr/local/hadoop/etc/hadoop
vi hadoop-env.sh
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/local/jdk
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native/"
退出保存
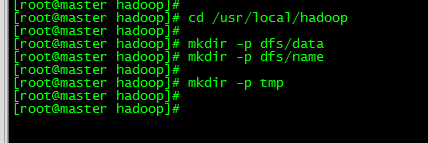
3.3 新增namenode和datanode存放,临时目录tmp
定位:
cd /usr/local/hadoop
mkdir -p dfs/data
mkdir -p dfs/name
mkdir -p tmp
3.4 修改hdfs-site.xml文件
vi hdfs-site.xml

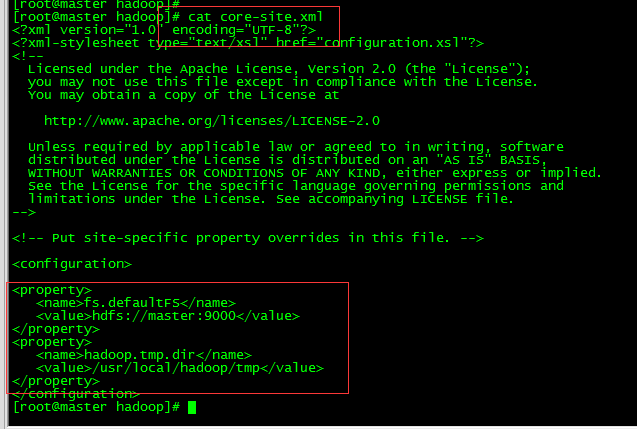
3.5 修改core-site.xml文件
vi core-site.xml
3.6 修改mapred-site.xml文件
目录默认只有mapred-site.xml.template文件,复制生成mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml

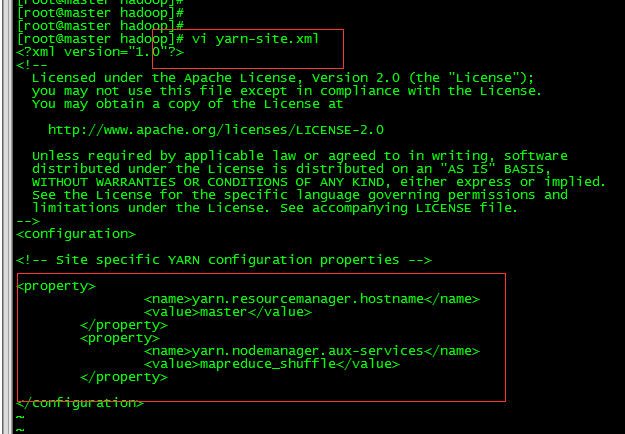
3.7 修改yarn-site.xml文件
vi yarn-site.xml
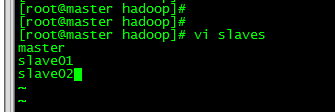
3.8 修改slaves文件
vi slaves
3.9 slave01和slave02服务器修改
3.9.1 hadoop文件复制
复制master中hadoop文件到slave01和slave02服务器的/usr/local目录
scp -r /usr/local/hadoop root@slave01:/usr/local/hadoop
scp -r /usr/local/hadoop root@slave012:/usr/local/hadoop
3.9.2 系统环境profile配置
类似3.2 分别在salve01和slave02配置系统环境
3.9.3 目录文件新建
类似3.3 分别在slave01和slave02新建文件目录
3.9.4 配置文件修改
修改core-site.xml文件
将fs.defaultFs对应的value中master修改slave02
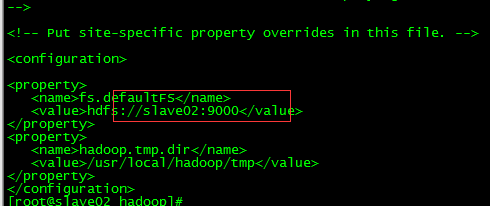
salve01修改类似。
四.hadoop集群测试
4.1 测试命令
#启动
start-all.sh start
#停止
stop-all.sh start
#格式化节点
hadoop namenode -format
或者hdfs namenode -format
4.2 集群测试
在master服务器运行启动命令
进入/usr/local/hadoop目录
4.2.1 格式化namenode

4.2.2 启动各个节点
sbin/start-all.sh start
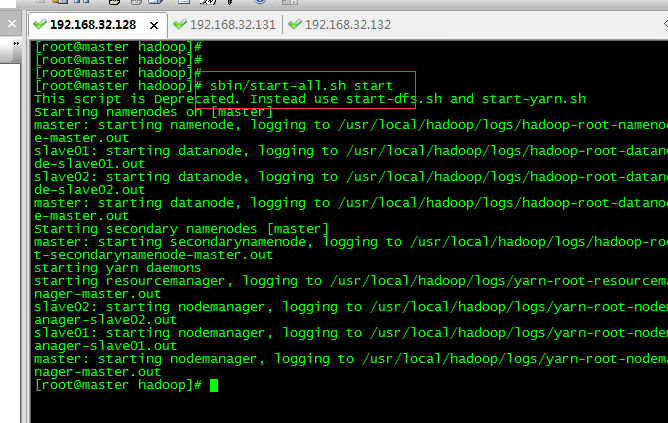
4.2.3 查看节点状态
jps查看节点进程
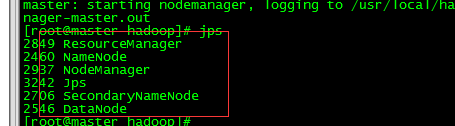
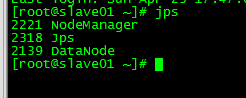
查看节点状态
http://192.168.32.128:50070/dfshealth.html#tab-overview
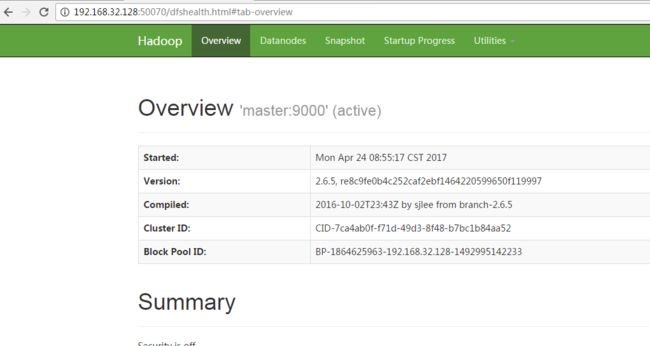
集群节点使用
http://192.168.32.128:8088/cluster/nodes
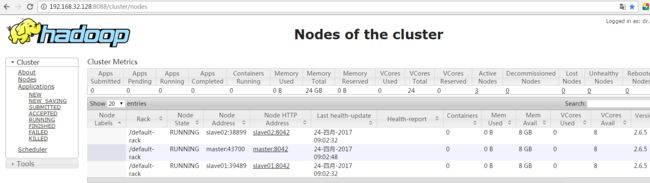
至此,hadoop完成分布式集群搭建完毕。