Open-falcon是小米运维团队从互联网公司的需求出发,根据多年的运维经验,结合SRE、SA、DEVS的使用经验和反馈,开发的一套面向互联网的企业级开源监控产品。
官方手册
架构图
 image
image
组件介绍
-
agent
agent用于采集机器负载监控指标,比如cpu.idle、load.1min、disk.io.util等等,每隔60秒push给Transfer。agent与Transfer建立了长连接,数据发送速度比较快,agent提供了一个http接口/v1/push用于接收用户手工push的一些数据,然后通过长连接迅速转发给Transfer。
配置说明
{ "debug": true, # 控制一些debug信息的输出,生产环境通常设置为false "hostname": "", # agent采集了数据发给transfer,endpoint就设置为了hostname,默认通过`hostname`获取,如果配置中配置了hostname,就用配置中的 "ip": "", # agent与hbs心跳的时候会把自己的ip地址发给hbs,agent会自动探测本机ip,如果不想让agent自动探测,可以手工修改该配置 "plugin": { "enabled": false, # 默认不开启插件机制 "dir": "./plugin", # 把放置插件脚本的git repo clone到这个目录 "git": "https://github.com/open-falcon/plugin.git", # 放置插件脚本的git repo地址 "logs": "./logs" # 插件执行的log,如果插件执行有问题,可以去这个目录看log }, "heartbeat": { "enabled": true, # 此处enabled要设置为true "addr": "127.0.0.1:6030", # hbs的地址,端口是hbs的rpc端口 "interval": 60, # 心跳周期,单位是秒 "timeout": 1000 # 连接hbs的超时时间,单位是毫秒 }, "transfer": { "enabled": true, # 此处enabled要设置为true "addrs": [ "127.0.0.1:8433", "127.0.0.1:8433" ], # transfer的地址,端口是transfer的rpc端口, 可以支持写多个transfer的地址,agent会保证HA "interval": 60, # 采集周期,单位是秒,即agent一分钟采集一次数据发给transfer "timeout": 1000 # 连接transfer的超时时间,单位是毫秒 }, "http": { "enabled": true, # 是否要监听http端口 "listen": ":1988" # 如果监听的话,监听的地址 }, "collector": { "ifacePrefix": ["eth", "em"] # 默认配置只会采集网卡名称前缀是eth、em的网卡流量,配置为空就会采集所有的,lo的也会采集。可以从/proc/net/dev看到各个网卡的流量信息 }, "ignore": { # 默认采集了200多个metric,可以通过ignore设置为不采集 "cpu.busy": true, "mem.swapfree": true } } -
hbs(Heartbeat Server)
心跳服务器,公司所有agent都会连到HBS,每分钟发一次心跳请求。agent会定期从hbs中拉取配置,比如:需要运行plugins的目录;
judge模块也会定期从hbs去获取告警策略;
-
transfer
transfer是数据转发服务。它接收agent上报的数据,然后按照哈希规则进行数据分片、并将分片后的数据分别push给graph&judge等组件。配置说明
debug: true/false, 如果为true,日志中会打印debug信息 http - enable: true/false, 表示是否开启该http端口,该端口为控制端口,主要用来对transfer发送控制命令、统计命令、debug命令等 - listen: 表示监听的http端口 rpc - enable: true/false, 表示是否开启该jsonrpc数据接收端口, Agent发送数据使用的就是该端口 - listen: 表示监听的http端口 socket #即将被废弃,请避免使用 - enable: true/false, 表示是否开启该telnet方式的数据接收端口,这是为了方便用户一行行的发送数据给transfer - listen: 表示监听的http端口 judge - enable: true/false, 表示是否开启向judge发送数据 - batch: 数据转发的批量大小,可以加快发送速度,建议保持默认值 - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认 - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认 - pingMethod: 后端提供的ping接口,用来探测连接是否可用,必须保持默认 - maxConns: 连接池相关配置,最大连接数,建议保持默认 - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认 - replicas: 这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可 - cluster: key-value形式的字典,表示后端的judge列表,其中key代表后端judge名字,value代表的是具体的ip:port graph - enable: true/false, 表示是否开启向graph发送数据 - batch: 数据转发的批量大小,可以加快发送速度,建议保持默认值 - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认 - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认 - pingMethod: 后端提供的ping接口,用来探测连接是否可用,必须保持默认 - maxConns: 连接池相关配置,最大连接数,建议保持默认 - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认 - replicas: 这是一致性hash算法需要的节点副本数量,建议不要变更,保持默认即可 - cluster: key-value形式的字典,表示后端的graph列表,其中key代表后端graph名字,value代表的是具体的ip:port(多个地址用逗号隔开, transfer会将同一份数据发送至各个地址,利用这个特性可以实现数据的多重备份) tsdb - enabled: true/false, 表示是否开启向open tsdb发送数据 - batch: 数据转发的批量大小,可以加快发送速度 - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认 - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认 - maxConns: 连接池相关配置,最大连接数,建议保持默认 - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认 - retry: 连接后端的重试次数和发送数据的重试次数 - address: tsdb地址或者tsdb集群vip地址, 通过tcp连接tsdb. -
judge
Judge用于告警判断,agent将数据push给Transfer,Transfer不但会转发给Graph组件来绘图,还会转发给Judge用于判断是否触发告警。Judge监听了一个http端口,提供了一个http接口:/count,访问之,可以得悉当前Judge实例处理了多少数据量。
graph
graph是存储绘图数据的组件。graph组件 接收transfer组件推送上来的监控数据,同时处理query组件的查询请求、返回绘图数据。-
gateway
站在client端的角度,gateway和transfer提供了完全一致的功能和接口。只有遇到网络分区的情况时,才有必要使用gateway组件。
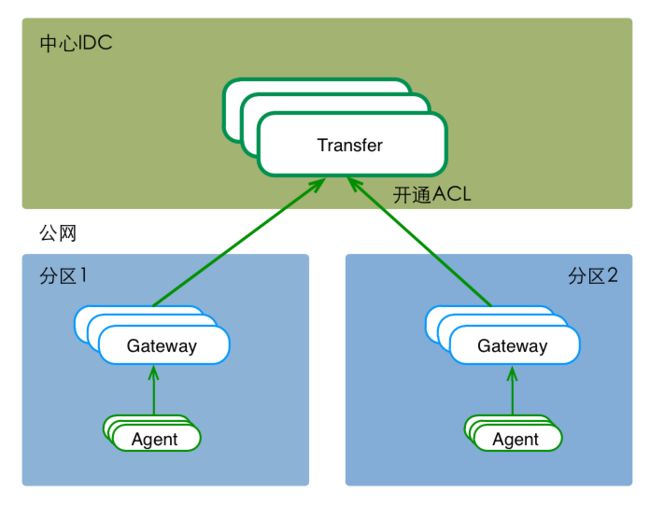 image
image alarm
alarm模块是处理报警event的,judge产生的报警event写入redis,alarm从redis读取处理;-
aggregator
集群聚合模块。聚合某集群下的所有机器的某个指标的值,提供一种集群视角的监控体验。配置说明
{ "debug": true, "http": { "enabled": true, "listen": "0.0.0.0:6055" }, "database": { "addr": "root:@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true", "idle": 10, "ids": [1,-1], # aggregator模块可以部署多个实例,这个配置表示当前实例要处理的数据库中cluster表的id范围 "interval": 55 }, "api": { "hostnames": "http://127.0.0.1:5050/api/group/%s/hosts.json", # 注意修改为你的portal的ip:port "push": "http://127.0.0.1:6060/api/push", # 注意修改为你的transfer的ip:port "graphLast": "http://127.0.0.1:9966/graph/last" # 注意修改为你的query的ip:port } } nodata
nodata用于检测监控数据的上报异常。nodata和实时报警judge模块协同工作,过程为: 配置了nodata的采集项超时未上报数据,nodata生成一条默认的模拟数据;用户配置相应的报警策略,收到mock数据就产生报警。采集项上报异常检测,作为judge模块的一个必要补充,能够使judge的实时报警功能更加可靠、完善。
部署
-
open-falcon plus
安装redis, mysql
yum install -y redis yum install -y mysql-server编译各个模块
mkdir -p $GOPATH/src/github.com/open-falcon cd $GOPATH/src/github.com/open-falcon git clone https://github.com/open-falcon/falcon-plus.git cd $GOPATH/src/github.com/open-falcon/falcon-plus/scripts/mysql/db_schema/ mysql -h 127.0.0.1 -u root -p < uic-db-schema.sql mysql -h 127.0.0.1 -u root -p < portal-db-schema.sql mysql -h 127.0.0.1 -u root -p < graph-db-schema.sql mysql -h 127.0.0.1 -u root -p < dashboard-db-schema.sql mysql -h 127.0.0.1 -u root -p < alarms-db-schema.sql cd $GOPATH/src/github.com/open-falcon/falcon-plus/ # make all modules make all # make specified module make agent # pack all modules make pack export WorkDir="$HOME/open-falcon" mkdir -p $WorkDir tar -xzvf open-falcon-vx.x.x.tar.gz -C $WorkDir cd $WorkDir cd $WorkDir ./open-falcon start # check modules status ./open-falcon check -
dashboard
通过http://xx:8081/访问
git clone https://github.com/open-falcon/dashboard.git docker build -t falcon-dashboard:v1.0 . docker run -itd --name falcon-dashboard --net host \ -e API_ADDR=http://127.0.0.1:8080/api/v1 \ -e PORTAL_DB_HOST=127.0.0.1 \ -e PORTAL_DB_PORT=3306 \ -e PORTAL_DB_USER=root \ -e PORTAL_DB_PASS=xx\ -e PORTAL_DB_NAME=falcon_portal \ -e ALARM_DB_PASS=xx \ -e ALARM_DB_HOST=127.0.0.1 \ -e ALARM_DB_PORT=3306 \ -e ALARM_DB_USER=root \ -e ALARM_DB_NAME=alarms \ falcon-dashboard:v1.0 -
邮件发送接口(可选)
git clone https://github.com/open-falcon/mail-provider.git cd $GOPATH/src/github.com/open-falcon/nodata go get ./... ./control build ./contorl pack使用方法:
curl http://$ip:4000/sender/mail -d "tos=a@a.com,b@b.com&subject=xx&content=yy"
open-falcon的设计理念
-
数据模型
Open-Falcon,采用和OpenTSDB相似的数据格式:
metric、endpoint加多组key valuetags,举两个例子:{ metric: load.1min, endpoint: open-falcon-host, tags: srv=falcon,idc=aws-sgp,group=az1, value: 1.5, timestamp: `date +%s`, counterType: GAUGE, step: 60 } { metric: net.port.listen, endpoint: open-falcon-host, tags: port=3306, value: 1, timestamp: `date +%s`, counterType: GAUGE, step: 60 }metric: 最核心的字段,代表这个采集项具体度量的是什么, 比如是cpu_idle呢,还是memory_free, 还是qps
endpoint: 标明Metric的主体(属主),比如metric是cpu_idle,那么Endpoint就表示这是哪台机器的cpu_idle
timestamp: 表示汇报该数据时的unix时间戳,注意是整数,代表的是秒
value: 代表该metric在当前时间点的值,float64
step: 表示该数据采集项的汇报周期,这对于后续的配置监控策略很重要,必须明确指定。
-
counterType: 只能是COUNTER或者GAUGE二选一,前者表示该数据采集项为计时器类型,后者表示其为原值 (注意大小写)
- GAUGE:即用户上传什么样的值,就原封不动的存储
- COUNTER:指标在存储和展现的时候,会被计算为speed,即(当前值 - 上次值)/ 时间间隔
tags: 一组逗号分割的键值对, 对metric进一步描述和细化, 可以是空字符串. 比如idc=lg,比如service=xbox等,多个tag之间用逗号
-
数据采集
服务监控数据
服务的监控指标采集脚本,通常都是跟着服务的code走的,服务上线或者扩容,这个脚本也跟着上线或者扩容,服务下线,这个采集脚本也要相应下线。公司里Java的项目有不少,研发那边就提供了一个通用jar包,只要引入这个jar包,就可以自动采集接口的调用次数、延迟时间等数据。然后将采集到的数据push给监控,一分钟push一次。目前falcon的agent提供了一个简单的http接口,这个jar包采集到数据之后是post给本机agent。向agent推送数据的一个简单例子,如下:
curl -X POST -d '[{"metric": "qps", "endpoint": "open-falcon-graph01.bj", "timestamp": 1431347802, "step": 60,"value": 9,"counterType": "GAUGE","tags": "project=falcon,module=graph"}]' http://127.0.0.1:1988/v1/push各种开源软件的监控
这都是大用户,比如DBA自己写一些采集脚本,连到各个MySQL实例上去采集数据,完事直接调用server端的jsonrpc(transfer 提供接口)汇报数据,一分钟一次,每次甚至push几十万条数据,比较好的发送方式是500条数据做一个batch,别几十万数据一次性发送。
-
plugin
Plugin可以看做是对agent功能的扩充。对于业务系统的监控指标采集,最好不要做成plugin,而是把采集脚本放到业务程序发布包中,随着业务代码上线而上线,随着业务代码升级而升级,这样会比较容易管理。
编写采集脚本
用什么语言写没关系,只要目标机器上有运行环境就行,脚本本身要有可执行权限。采集到数据之后直接打印到stdout即可,agent会截获并push给server。
使用
- 先将脚本push到git
- curl下agent的接口去获取plugins
curl http://ip:1988/plugin/update- 在dashborad的HostGroup中绑定plugins目录,因为不是所有的plugins都需要在该机器上执行,这里通过目录来区分;agent会通过hbs的接口去获取配置;
-
Tag和HostGroup
tag其实是一种分组方式,当push的数据无法标记tag(比如:我们agent采集的cpu, memory, net等信息),那我们就要将这些数据手工分组了,这就是HostGroup;HostGroup实际上是对endpoint的一种分组;想象一下,一条数据push上来,我们应该怎么判断这条数据是否该报警呢?首先我们需要找到这条数据的
expression,无非就是看expression中的tag是否是当前push上来数据的子集;当没有tag的数据呢?push上来的数据肯定有endpoint, 我们可以根据endpoint查看是哪个HostGroup,HostGroup又是跟template绑定,template中又会配置告警策略;