%pwd
u'/Users/zhongyaode'
import numpy as np
import pandas as pd
path='/Users/zhongyaode/'
import json
from pandas import Series,DataFrame
#加载数据
db = json.load(open('/Users/zhongyaode/pythonbook/ch07/foods-2011-10-03.json'))
len(db)
6636
#db每个条目中都是一个含有某种食物全部数据的字典, nutrients字段是一个字典列表,
#其中的每个字典对应一种营养成分
db[0].keys()
[u'portions',
u'description',
u'tags',
u'nutrients',
u'group',
u'id',
u'manufacturer']
db[0]['nutrients'][0]
{u'description': u'Protein',
u'group': u'Composition',
u'units': u'g',
u'value': 25.18}
nutrients=DataFrame(db[0]['nutrients'])
nutrients[0:7]
#在将字典列表转换为DataFrame时,可以只抽取其中的一部分字段,这里取出
#食物的名称、分类、编号、以及制造商等信息
info_keys=['description','group','id','manufacturer']
info=DataFrame(db,columns=info_keys)
info[:5]
查看info的统计信息
info.describe()
#查看info字典的基本信息
info.info()
RangeIndex: 6636 entries, 0 to 6635
Data columns (total 4 columns):
description 6636 non-null object
group 6636 non-null object
id 6636 non-null int64
manufacturer 5195 non-null object
dtypes: int64(1), object(3)
memory usage: 207.4+ KB
#通过value_counts查看食物类别的分布情况
pd.value_counts(info.group)[:10]
Vegetables and Vegetable Products 812
Beef Products 618
Baked Products 496
Breakfast Cereals 403
Legumes and Legume Products 365
Fast Foods 365
Lamb, Veal, and Game Products 345
Sweets 341
Fruits and Fruit Juices 328
Pork Products 328
Name: group, dtype: int64
pd.value_counts(info.description)[:3]
Bread, pound cake type, pan de torta salvadoran 1
MISSION FOODS, MISSION Flour Tortillas, Soft Taco, 8 inch 1
Lamb, domestic, shoulder, arm, separable lean and fat, trimmed to 1/8 fat, cooked, broiled 1
Name: description, dtype: int64
#为了对全部营养数据做一些分析,最简单的办法是将所有食物的营养成分整合到一个大表中
#分几步完成,首先,将各食物的营养成分列表转换成为一个DateFrame,并添加一个个表示
#编号的列,然后将该DataFrame添加到一个列表中,最后通过concat将这些东西链接起来
nutrients=[]
for rec in db:
fnuts=DataFrame(rec['nutrients'])
fnuts['id']=rec['id']
nutrients.append(fnuts)
nutrients=pd.concat(nutrients,ignore_index=True)
nutrients.duplicated().sum()
14179
nutrients=nutrients.drop_duplicates()
nutrients.info()
Int64Index: 375176 entries, 0 to 389354
Data columns (total 5 columns):
description 375176 non-null object
group 375176 non-null object
units 375176 non-null object
value 375176 non-null float64
id 375176 non-null int64
dtypes: float64(1), int64(1), object(3)
memory usage: 17.2+ MB
#两个DataFrame对象中都有'group'和'description',为了明确到底谁是谁
#对他们进行重命名
col_mapping={'description':'food','group':'fgroup'}
info=info.rename(columns=col_mapping,copy=False)
info.info()
RangeIndex: 6636 entries, 0 to 6635
Data columns (total 4 columns):
food 6636 non-null object
fgroup 6636 non-null object
id 6636 non-null int64
manufacturer 5195 non-null object
dtypes: int64(1), object(3)
memory usage: 207.4+ KB
col_mapping={'description':'nutrient',\
'group':'nutgroup'}
nutrients[:1]
nutrients=nutrients.rename(columns=col_mapping,copy=False)
#nutrients.info()
#nutrients=nutrients.rename(columns=col_maping,copy=False)
nutrients.info()
Int64Index: 375176 entries, 0 to 389354
Data columns (total 5 columns):
nutrient 375176 non-null object
nutgroup 375176 non-null object
units 375176 non-null object
value 375176 non-null float64
id 375176 non-null int64
dtypes: float64(1), int64(1), object(3)
memory usage: 17.2+ MB
nutrients[:4]
info[0:2]
#将info 和nutrients合并
ndata=pd.merge(nutrients,info,on='id',how='outer')
ndata.info()
Int64Index: 375176 entries, 0 to 375175
Data columns (total 8 columns):
nutrient 375176 non-null object
nutgroup 375176 non-null object
units 375176 non-null object
value 375176 non-null float64
id 375176 non-null int64
food 375176 non-null object
fgroup 375176 non-null object
manufacturer 293054 non-null object
dtypes: float64(1), int64(1), object(6)
memory usage: 25.8+ MB
ndata.ix[30000]
nutrient Glycine
nutgroup Amino Acids
units g
value 0.04
id 6158
food Soup, tomato bisque, canned, condensed
fgroup Soups, Sauces, and Gravies
manufacturer
Name: 30000, dtype: object
#根据营养分类得出的锌中位值
result=ndata.groupby(['nutrient','fgroup'])['value'].quantile(0.5)
%pylab inline
b=result['Zinc, Zn'].order().plot(kind='barh')
Populating the interactive namespace from numpy and matplotlib
/Users/zhongyaode/anaconda/envs/py/lib/python2.7/site-packages/IPython/core/magics/pylab.py:161: UserWarning: pylab import has clobbered these variables: ['info', 'rec']
`%matplotlib` prevents importing * from pylab and numpy
"\n`%matplotlib` prevents importing * from pylab and numpy"
/Users/zhongyaode/anaconda/envs/py/lib/python2.7/site-packages/ipykernel/__main__.py:2: FutureWarning: order is deprecated, use sort_values(...)
from ipykernel import kernelapp as app
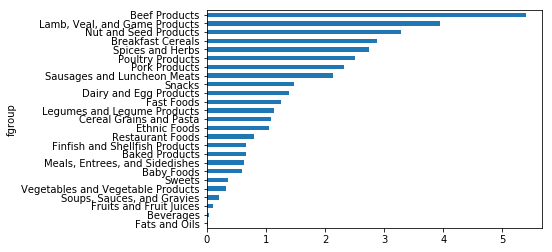
output_40_2.png
#现在可知道,各营养成分最为丰富的食物是什么
by_nutrient=ndata.groupby(['nutgroup','nutrient'])
get_maximum=lambda x:x.xs(x.value.idxmax())
get_minimun=lambda x:x.xs(x.value.idxmin())
max_foods=by_nutrient.apply(get_maximum)[['value','food']]
#让food小点
max_foods=max_foods.food.str[:50]
max_foods[:20]
nutgroup nutrient
Amino Acids Alanine Gelatins, dry powder, unsweetened
Arginine Seeds, sesame flour, low-fat
Aspartic acid Soy protein isolate
Cystine Seeds, cottonseed flour, low fat (glandless)
Glutamic acid Soy protein isolate
Glycine Gelatins, dry powder, unsweetened
Histidine Whale, beluga, meat, dried (Alaska Native)
Hydroxyproline KENTUCKY FRIED CHICKEN, Fried Chicken, ORIGINA...
Isoleucine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Leucine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Lysine Seal, bearded (Oogruk), meat, dried (Alaska Na...
Methionine Fish, cod, Atlantic, dried and salted
Phenylalanine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Proline Gelatins, dry powder, unsweetened
Serine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Threonine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Tryptophan Sea lion, Steller, meat with fat (Alaska Native)
Tyrosine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Valine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Composition Adjusted Protein Baking chocolate, unsweetened, squares
Name: food, dtype: object