2015蒙特利尔深度学习暑期学校之自然语言处理篇
2015-08-28郭江哈工大SCIR
8月3日至8月12日在蒙特利尔举办的深度学习署期学校中,来自不同领域的深度学习顶尖学者 (Yoshua Bengio, Leon Bottou, Chris Manning等)分别作了精彩的报告。报告内容的覆盖面非常广,从基本神经网络介绍、深度网络的训练技巧、理论分析到工具使用、以及在不同问题中的应用等。所有报告的slides均可从本次暑期学校主页(https://sites.google.com/site/deeplearningsummerschool/home)下载。
本文内容主要总结自Marek Rei(剑桥大学助理研究员)对于本次署期学校所撰写的博文:26 Things I Learned in The Deep Learning Summer School (http://www.marekrei.com/blog/26-things-i-learned-in-the-deep-learning-summer-school/) 中与自然语言处理相关的内容(12项)。希望能为像笔者一样无缘现场聆听的同学们提供一个简要的概述。
1. The need for distributed representations
分布表示或许是表示学习在自然语言处理中最重要的概念。简单来理解就是将我们需要记忆、识别的概念或者其他目标表示成由多个激活值所组成的向量,该向量中的每一维可表达某种隐含的意义。下图是Yoshua Bengio自称报告中最重要的一页:
假设我们有一个分类器需要对人进行以下三个属性的分类:男/女,戴眼镜/不戴眼镜,高/矮。如果使用传统的类别表示,由于需判定的类别数目是8类(2*2*2),为了训练该分类器,则需要属于所有这8个类的足够训练数据。如果采用分布表示,将每个属性用独立的一维信息来表达,即使训练数据中没有出现过某个类(比如:男、高、戴眼镜),分类器也能够对该类进行识别。
当然,分布表示的意义不仅于此,其对记忆对象(如:词)相似性表达的重要意义,在自然语言处理中显得更为重要。
2. Local minima are not a problem in high dimensions
Yoshua Bengio研究组通过实验发现,在训练高维(参数)神经网络时,几乎不会遇到局部极小点(这与我们以往的直觉相背),但会存在鞍点,而这些鞍点只在某些维度上是局部极小的。鞍点会显著减缓神经网络的训练速度,直到在训练过程中找到正确的逃离方向。从下图可以明显看出这种现象,每当到达一个鞍点,都会“震荡”多次最终逃逸。
Bengio提供了一个浅显易懂的解释:我们假设在某个维度上,一个点是局部极小点的概率为p。那么这个点在1000维的空间下是局部极小点的概率则为p^1000,是一个典型的小概率事件。而该点在少数几个维度上局部极小的概率则相对较高。在参数优化过程中,当到达这些点的时候训练速度会明显变慢,直到找到正确的方向。
另外,概率p会随着损失函数逐渐接近全局最优点而不断增大。这意味着,当网络收敛到一个真正的局部极小点时,通常可以认为该点已经离全局最优足够接近了。
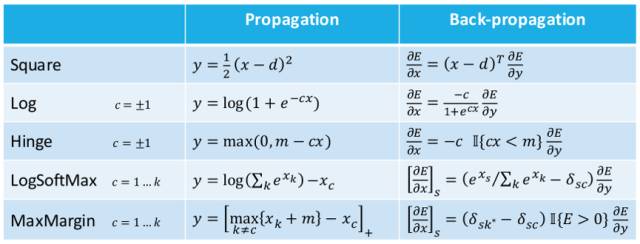
3. Derivatives derivatives derivatives
Leon Bottou总结了不同激活函数以及损失函数以及它们所对应的梯度求解公式。
4. Weight initialisation strategy
目前大家比较推荐的网络权值初始化策略是在某区间[-b, b]之内随机采样。其中,b的大小取决于连接它的两层神经网络的神经元数目:
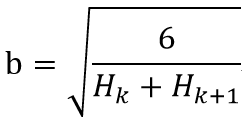
5. Neural net training tricks
在Hugo Larochelle的报告中提到的:
对于实值输入进行正则化
在训练过程中不断减小学习率(针对SGD而言)
使用mini-batch,梯度更加稳定
使用momentum
6. Gradient checking
当自己实现的反向传播不work的时候,99%的可能性在于梯度计算存在错误。这时候需要利用梯度检查技术(gradient checking)。思想很简单,验证通过数值方法计算出来的梯度(微分原始定义)以及程序中的梯度求解结果是否足够接近,即:
7. Syntax or no syntax? (aka, “is syntax a thing?”)
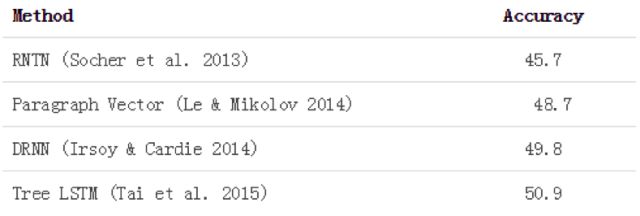
在基于词汇分布表示的语义组合(semantic composition)研究中,构建于句法结构之上的递归网络模型一直被认为是一种较为理想的方式,比如Richard Socher等提出的递归神经张量网络 (Socher et al., EMNLP 2013)模型 (RNTN)。有趣的是,2014年Quoc Le与Tomas Mikolov (NIPS)提出的paragraph vector在不考虑任何句法结构信息的情况下,超越了RNTN在情感分析任务上的效果。这个结果不由令人质疑句法结构(以及其他传统自然语言处理所带来的语法信息)在语义组合中的必要性。
幸运的是,我们不必因此而对传统自然语言处理技术失去信心。Irsoy and Cardie (NIPS, 2014)以及Tai et al. (ACL, 2015)通过结合深度神经网络与句法结构,再次超越了paragraph vector,重新证明了句法信息的有效性。
相关模型在斯坦福情感分析数据集上的结果如下表:
8. The state of dependency parsing
在Chen and Manning (EMNLP, 2014)提出基于神经网络的依存句法分析之后,今年的ACL涌现出不少改进的工作。其中Google的模型将PTB上的结果推到了94.3(UAS)/92.4(LAS)。相关模型的性能比较如下:
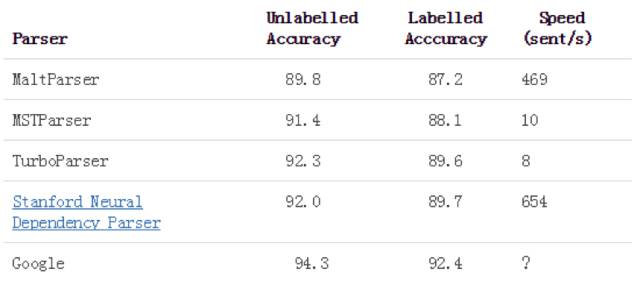
当然,表中所列的parser并不完整,比如RGBParser, Zpar等均未列其中。
9. Multimodal linguistic regularities
想必大家对word embedding中所蕴含的语义关系类比性质(如“king – man + woman = queen”)已经非常熟悉。那么在图像中是否也存在类似的现象呢?Kiros et al., (TACL 2015) 讨论了这个有趣的发现,见下图:

10. Everything is language modelling
Phil Blunsom在他的报告中提到所有的自然语言处理任务均可表达为语言模型。我们所要做的就是将输入(序列)与输入(序列)拼在一起,然后预测合并之后序列的概率。比如
机器翻译:P(Les chiens aiment les os || Dogs love bones)
问答:P(What do dogs love? || bones)
对话:P(How are you? || Fine thanks. And you?)
对于问答和对话任务而言,还需要以一定的基本知识作为条件。这种思路不仅可以用于两个词序列的情况,在输出是标签(类别)或者其他结构化信息(如句法树)时也非常自然。
当然这个观点在传统自然语言处理研究者眼中是有待推敲或质疑的,但是在训练数据非常充分的任务中,它确实能够取得较好的实验结果。
11. SMT had a rough start
这是一个有趣的小八卦。1988年Frederick Jelinek将第一篇统计机器翻译的文章投往COLING时,收到的(匿名)审稿意见如下:
“The validity of a statistical (information theoretic) approach to MT has indeed been recognized, as the authors mention, by Weaver as early as 1949. And was universally recognized as mistaken by 1950 (cf. Hutchins, MT – Past, Present, Future, Ellis Horwood, 1986, p. 30ff and references therein). The crude force ofCOMPUTERS is not science. The paper is simply beyond the scope of COLING.”
12. The state of Neural Machine Translation
下图是一个非常简单的神经网络翻译模型示意。encoder将源语言句子中的每个词向量相加得到句子表示,decoder是一个条件语言模型,在源语言句子表示以及当前已经生成词的基础之上预测下一个词的概率分布。这种框架之下很自然衍生出更为复杂也更具表达能力的模型,比如encoder/decoder均可采用(多层)LSTM。
然而,目前的神经网络翻译模型在性能上并没有超越最好的传统机器翻译模型。如Sutskever et al., (NIPS, 2014)报告的性能:
主编:刘挺
编辑部主任:郭江
执行编辑:李家琦
编辑:徐俊,李忠阳,俞霖霖
本期编辑:李忠阳