思考问题
Mapper类
Mapper类
org.apache.hadoop.mapreduce.Mapper
四个泛型,分别是KEYIN、VALUEIN、KEYOUT、VALUEOUT,
前面两个KEYIN、VALUEIN 指的是map 函数输入的参数key、value 的类型;
后面两个KEYOUT、VALUEOUT 指的是map 函数输出的key、value 的类型。
Mapper有setup(),map(),cleanup()和run()四个方法。
其中setup()一般是用来进行一些map()前的准备工作,
map()则一般承担主要的处理工作,
cleanup()则是收尾工作如关闭文件或者执行map()后的K-V分发等。run()方法提供了setup->map->cleanup()的执行模板。
在MapReduce中,Mapper从一个输入分片中读取数据,然后经过Shuffle and Sort阶段,分发数据给Reducer,在Map端和Reduce端我们可能使用设置的Combiner进行合并,这在Reduce前进行。Partitioner控制每个K-V(键值)对应该被分发到哪个reducer(我们的Job可能有多个reducer),Hadoop默认使用HashPartitioner,HashPartitioner使用key的hashCode对reducer的数量取模得来。
run()方法
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
可以得出,K/V对是从传入的Context(上下文)获取的。
map()方法
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
也看得出输出结果K/V对也是通过Context来完成的
作为map方法输入的键值对,其value值存储的是文本文件中的一行(以回车符为行结束标记),而key值为该行的首字母相对于文本文件的首地址的偏移量。将
这里输入参数key、value 的类型就是KEYIN、VALUEIN,每一个键值对都会调用一次map 函数。在这里,map 函数没有处理输入的key、value,直接通过context.write(…)方法输出了,输出的key、value 的类型就是KEYOUT、VALUEOUT。这是默认实现,通常是需要我们根据业务逻辑覆盖的。
当调用到map时,通常会先执行一个setup函数,最后会执行一个cleanup函数。而默认情况下,这两个函数的内容都是nothing。因此,当map方法不符合应用要求时,可以试着通过增加setup和cleanup的内容来满足应用的需求。
Reducer类
Reducer类
org.apache.hadoop.mapreduce.Reducer
四个泛型,分别是KEYIN、VALUEIN、KEYOUT、VALUEOUT,
前面两个KEYIN、VALUEIN 指的是map 函数输出的参数,即reduce 函数输入的key、value 的类型;
后面两个KEYOUT、VALUEOUT 指的是reduce 函数输出的key、value 的类型。
Reducer有3个主要的函数,分别是:setup(),clearup(),reduce(),run()。
reducer()
@SuppressWarnings("unchecked")
protected void reduce(KEYIN key, Iterable values,
Context context ) throws IOException, InterruptedException {
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
run()
@SuppressWarnings("unchecked")
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKey()) {
reduce(context.getCurrentKey(), context.getValues(), context);
// If a back up store is used, reset it
((ReduceContext.ValueIterator)
(context.getValues().iterator())).resetBackupStore();
}
cleanup(context);
}
}
当调用到reduce时,通常会先执行一个setup函数,最后会执行一个cleanup函数。而默认情况下,这两个函数的内容都是nothing。因此,当reduce不符合应用要求时,可以试着通过增加setup和cleanup的内容来满足应用的需求。
InputFormat类
平时我们写MapReduce程序的时候,在设置输入格式的时候,总会调用形如job.setInputFormatClass(KeyValueTextInputFormat.class);来保证输入文件按照我们想要的格式被读取。
所有的输入格式都继承于InputFormat,这是一个抽象类,其子类有专门用于读取普通文件的FileInputFormat,用来读取数据库的DBInputFormat等等。
其实,一个输入格式InputFormat,主要无非就是要解决如何将数据分割成分片(比如多少行为一个分片),以及如何读取分片中的数据(比如按行读取)。前者由getSplits()完成,后者由RecordReader完成。这些方法的实现都在子类中。
1 public abstract class InputFormat {
2
3 public abstract List getSplits(JobContext context) throws IOException, InterruptedException;
4
5 public abstract RecordReader createRecordReader(InputSplit split,TaskAttemptContext context) throws IOException, InterruptedException;
6
7 }
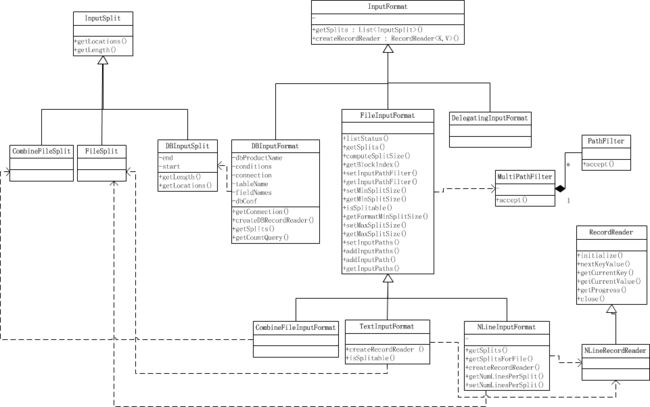
类InputFomat 是负责把HDFS 中的文件经过一系列处理变成map 函数的输入部分的。这个类做了三件事情:
第一, 验证输入信息的合法性,包括输入路径是否存在等;
第二,把HDFS 中的文件按照一定规则拆分成InputSplit,每个InputSplit 由一个Mapper执行;
第三,提供RecordReader,把InputSplit 中的每一行解析出来供map 函数处理;
MapReduce应用开发人员并不需要直接处理InputSplit,因为它是由InputFormat创建。InputFormat负责产生输入分片并将它们分隔成记录。
InputSplit
我们知道Mappers的输入是一个一个的输入分片,称InputSplit。InputSplit是一个抽象类,它在逻辑上包含了提供给处理这个InputSplit的Mapper的所有K-V对。
getLength()用来获取InputSplit的大小,以支持对InputSplits进行排序,而getLocations()则用来获取存储分片的位置列表。
public abstract class InputSplit {
public abstract long getLength() throws IOException, InterruptedException;
public abstract
String[] getLocations() throws IOException, InterruptedException;
}
InputSplit是hadoop定义的用来传送给每个单独的map的数据,InputSplit存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组。生成InputSplit的方法可以通过InputFormat()来设置。
当数据传送给map时,map会将输入分片传送到InputFormat,InputFormat则调用方法getRecordReader()生成RecordReader,RecordReader再通过creatKey()、creatValue()方法创建可供map处理的一个一个的
简而言之,InputFormat()方法是用来生成可供map处理的
FileinputFormat类
FileinputFormat类是所有使用文件作为其数据源的InputFormat实现的基类。
它提供了两个功能:
- 定义哪些文件包含在一个作业的输出中
- 输入文件生成分片的实现。
并把分片分隔成记录的作业由其子类来完成。
FileinputFormat类的输入路径
作业的输入被设定为一组路径,这对限定作业输入提供了很大的灵活性。

如果需要排除特定文件可以使用FileInPutFormat的SetInputPathFilter()方法设置一个过滤器:
FileInPutFormat类的输入分片
给定一组文件,FileInPutFormat是如何把它们转换为输入分片的?
FileInPutFormat只分割大文件。这里的大是值超过HDFS块的大小。而分片通常与HDFS块大小一样,也可以设置不同的Hadoop属性来改变。


下面是该类对getSplits 方法的实现
利用FileInputFormat 的getSplits方法,我们就计算出了我们的作业的所有输入分片了
注意:每一个输入分片启动一个Mapper 任务。
public List getSplits(JobContext job
2 ) throws IOException {
3 long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
4 long maxSize = getMaxSplitSize(job);
5
6 // generate splits
7 List splits = new ArrayList();
8 Listfiles = listStatus(job);
9 for (FileStatus file: files) {
10 Path path = file.getPath();
11 FileSystem fs = path.getFileSystem(job.getConfiguration());
12 long length = file.getLen();
13 BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
14 if ((length != 0) && isSplitable(job, path)) {
15 long blockSize = file.getBlockSize();
16 long splitSize = computeSplitSize(blockSize, minSize, maxSize);
17
18 long bytesRemaining = length;
19 while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
20 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
21 splits.add(new FileSplit(path, length-bytesRemaining, splitSize,
22 blkLocations[blkIndex].getHosts()));
23 bytesRemaining -= splitSize;
24 }
25
26 if (bytesRemaining != 0) {
27 splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining,
28 blkLocations[blkLocations.length-1].getHosts()));
29 }
30 } else if (length != 0) {
31 splits.add(new FileSplit(path, 0, length, blkLocations[0].getHosts()));
32 } else {
33 //Create empty hosts array for zero length files
34 splits.add(new FileSplit(path, 0, length, new String[0]));
35 }
36 }
37
38 // Save the number of input files in the job-conf
39 job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
40
41 LOG.debug("Total # of splits: " + splits.size());
42 return splits;
43 }
那这些计算出来的分片是怎么被map读取出来的呢?就是InputFormat中的另一个方法createRecordReader(),FileInputFormat并没有对这个方法做具体的要求,而是交给子类自行去实现它。
- RecordReader:
RecordReader是用来从一个输入分片中读取一个一个的K -V 对的抽象类,我们可以将其看作是在InputSplit上的迭代器。我们从类图中可以看到它的一些方法,最主要的方法就是nextKeyvalue()方法,由它获取分片上的下一个K-V 对。 - 我们再深入看看上面提到的RecordReader的一个子类: Lin eRecordReader。
LineRecordReader由一个FileSplit构造出来,start是这个FileSplit的起始位置,pos是当前读取分片的位置,end是分片结束位置,in是打开的一个读取这个分片的输入流,它是使用这个FileSplit对应的文件名来打开的。key和value则分别是每次读取的K-V对。然后我们还看到可以利用getProgress()来跟踪读取分片的进度,这个函数就是根据已经读取的K-V对占总K-V对的比例来显示进度的。
其他输入类
CombineFileInputFormat类 能够很好的处理小文件
WholeFileInputFormat类 使用RecordReader将整个文件读为一条记录。TestInputFormat类 Hadoop默认的输入方法,每条记录是一行输入。
键是LongWritable类型,存储该行在整个文件中的字节偏移量。
值是这行的内容,不包括任何行终止符(换行符和回车符),是Text类型的。
SequenceFileInputFormat类 顺序文件格式存储二进制的键值对的序列作为MapReduce的输入时使用。
MultipleInputs类 能妥善处理多种格式输入问题。
DBInputFormat 这种输入格式用于使用JDBC从关系数据库中读取数据。