你在web上的卖衣服网站搜索chamois,在“Shirts下结果为空。你很惊讶,因为你很确定你在邮箱里的纸质目录里看到了一只 chamois Henley (麂皮套头衫),你在目录中查找单元号,然后用它做另一个搜索。果然,这就是 chamois Henley 。此外,你会发现““Henleys”在目录中是作为一种“Shirts”出现的。你喃喃自语道。“如果是在‘‘Henleys’下面,那就应该在‘Shirts’下面。“这东西怎么啦?”

除了这种方法,语义网还提供了一种数据表达式模型,用来表示不同数据项之间的联系。从这个意义上说,它真正地允许数据建模师创建连接更紧密、集成更好、数据一致性约束可以在数据本身中表示的数据。这些数据可以描述应该如何使用它们。
还有一种可选方法,在rdf层之上,语义网还包含了一系列的层来描述数据的一致性约束。这些层次的关键是推理的概念。在语义Web的上下文中,推断仅仅意味着给定一些陈述的信息,我们就可以确定其他相关的信息,我们也可以把这些信息当作已经陈述过的信息来考虑。在henley /Shirts的例子中,我们可以推断任何“henley”类的成员也是“Shirts”类的成员。“推理是处理信息的一种强大机制,它可以涵盖广泛的精细处理。为了使我们的数据更加集成和一致,非常简单的推断通常比复杂的推断更有用。举个简单的例子,在第5章中,我们看到了如何编写一组查询来维护家谱中的关系信息,这些信息最初是否表示为关于孩子、兄弟、姐妹、母亲、儿子等的信息。在语义Web中,通过推理可以完成这种常见的数据一致性完成。尽管从自然界的角度来看,这种推断似乎微不足道(毕竟,难道不是每个人都知道家庭就是这样工作的吗?)
Inference in the Semantic Web
我们可以在数据中添加关系,以约束数据的显示方式。我们希望能够表达“henley”和“Shirts”之间的关系,这将告诉我们“henley”类别中的任何项目也应该在“Shirts”类别中。我们想表达一个关于位置的事实,如果一个连锁酒店在一个特定的位置有一个酒店,那么这个位置是由连锁酒店提供服务的。我们想用太阳系中各种天体的分类来表示行星的清单。
这些关系中的许多关系对于许多范例中的信息建模者来说都很熟悉。让我们以“henley”和“Shirts”之间的关系为例。同义词典的作者熟悉更广泛的术语的概念。“t恤”比“亨利”更宽泛。面向对象程序员习惯于子类或类扩展的概念。“henley”是“Shirts”类的子类,或扩展类。在RDF Schema语言中,我们说“henley”是“Shirts”的子类,下一章将对此进行描述。“说这些话固然好,但它们是什么意思呢?
在许多语境中,义词典对这些词的含义采取非正式的立场。如果您在搜索中使用更广泛的术语,您还将发现所有标记为更窄术语的条目。如果你根据一个宽泛的术语对某事物进行分类,你可能会得到一个更窄的术语列表,从中选择你的分类重点。
面向对象编程和语义网的区别:OOP系统对类关系采取的是一种更正式的(如果是编程的)视图,而不是采用词典和分类法。类型为“Henleys”的对象将响应为类型为“Shirts”的对象定义的所有消息。此外,与此调用相关的操作对于所有“衬衫”都是相同的,除非为“亨利”等定义了更具体的行为。语义Web也采用这些关系的正式视图,但是与OOP中的编程定义不同,语义Web通过推理定义这些事物的含义。
rdfs:subClassOf的推理:

在简单的英语中,这意味着如果一个类A是另一个类B的子类,那么任何A类型的东西也都是B类型的。我们将把这个规则称为类型传播规则。对子类关系的这种非常简单的解释使其成为RDFS建模(以及OWL建模,如后面几章所述)的工作负载。它与编程语言的IF/THEN构造密切相关:如果某个东西是子类的成员,那么它就是超类的成员。
子类的语义Web定义类似于OOP中子类或扩展的定义。在OOP中,一个instanceofsome类以它的超类的tinstances所做的相同方式对相同的方法做出响应。在语义Web术语中,这是因为该实例也是超类的成员,因此必须像任何此类成员一样行事。例如,类“henley”的实例响应“Shirts”中定义的方法的原因是,该实例实际上也是类“Shirts”的成员。“这种相似性只到此为止。例如,当在OOP系统中,子类为超类中定义的方法定义覆盖时,它就会崩溃。在语义Web术语中,“henley”的实例仍然是“Shirts”的实例,应该做出相应的响应。但在大多数OOP语义中,情况并非如此;“henley”的定义优先于“Shirts”,因此“henley”实际上根本不需要表现得像“Shirts”。在语义Web的逻辑中,这是不允许的。
SPARQL and inference
通常,我们使用SPARQL中的construct来描述 RDFS (and OWL) 的推理规则看,比如,因为construct查询指定了新的三元组,基于三元组的图模式,对于类型传播规则,我们可以使用下面的SPARQL CONSTRUCT查询来指定类型传播规则:

SPARQL提供了一种精细而且紧凑的方式来表达这种推理规则。在本书的其余部分中,我们将使用这种SPARQL符号来描述RDFS和OWL中的许多推论。它是一种干净、简洁的方法,可以指定推理,提供大量的SPARQL查询示例,并显示SPARQL与这些其他语义Web语言之间的关系。
使用SPARQL定义推理不仅仅是编写书籍的便利,SPARQL还可以用作推理语言本身的基础。这种推理语言的一种建议称为SPARQL推理符号(SPIN)。SPIN包含了许多使用SPARQL管理推理的构造,但是对于本书的目的,SPIN只是一种方法,它指定了一个特定的构造查询将用作一个特定模型推理的定义。例如,如果我们想说类型传播规则适用于类Shirt的所有成员,我们可以在SPIN中指定它为

变量 ?this在SPIN中有特殊的意义;它引用查询通过spin:rule附加到的类中的一个成员。在本例中,?指的是类中的任何成员:Shirt。我们将不时使用SPIN来详细说明RDFS和OWL中的推理如何与SPARQL中指定的结构相关联。
Virtues of inference-based semantics( 基于推理的语义的优点 )
推理模式是定义数据结构含义的一种优雅方式。但是这种方法真的有用吗?为什么在语义Web中定义构造的含义是一种特别有效的方法?
在像语义网这样的基于推理的系统中,这个问题的答案(无论好坏)是由基本推理模式的交互决定的。在RDF模式语言中,多重继承是如何工作的?只需要应用规则两次。如果A是B的子类,A也是子类,那么A中的任何x都是B和c的成员,不需要讨论,不需要设计决策。在任何上下文中,子类的含义都用一个简单的规则给出了优雅的表达:类型传播规则。推理系统的这一特性特别适合语义Web上下文,在语义Web上下文中,当来自多个源的数据被合并时,必然会出现新的关系组合。
Where Are the Smarts?
EXAMPLE Simple RDFS Query

Asserted triples versus inferred triples ( 断言三元组与推断三元组 )
将推理和查询视为单独的过程通常很方便,在这个过程中,推理引擎根据一组特定的推理规则生成所有可能的推理三元组。然后,在一个单独的传递中,一个普通的SPARQL查询引擎运行在结果的增强三元组存储之上。然后,将断言三元组与推断三元组进行比较就变得有意义了。
断言三元组,顾名思义,是在原始RDF存储中断言的三元组。如果存储由来自多个源的合并三元组填充,则断言所有三元组。推断三元组是由控制特定推理引擎的推理规则之一推断的附加三元组。当然,对于推理引擎来说,推断已经断言的三元组是可能的。在这种情况下,我们仍然认为这三种说法是肯定的。需要注意的是,推断的三元组和断言的三元组之间没有逻辑上的区别,如果断言了相同的三元组,推理引擎将从推断的三元组中得出完全相同的结论。
断言三元组和推断三元组的例子:对于简单的类型传播规则,这两个三元组也有区别。假设我们有以下的三元组存储在三元组存储器中。
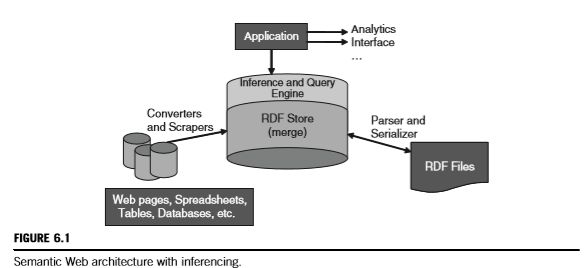
shop:Henleys rdfs:subClassOf shop:Shirts.
shop:Shirts rdfs:subClassOf shop:MensWear.
shop:Blouses rdfs:subClassOf shop:WomensWear.
shop:Oxfords rdfs:subClassOf shop:Shirts.
shop:Tshirts rdfs:subClassOf shop:Shirts.
shop:ChamoisHenley rdf:type shop:Henleys.
shop:ClassicOxford rdf:type shop:Oxfords.
shop:ClassicOxford rdf:type shop:Shirts.
shop:BikerT rdf:type shop:Tshirts.
shop:BikerT rdf:type shop:MensWear.
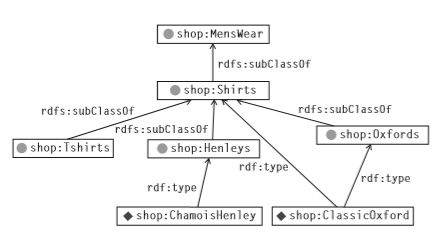
一个只执行类型传播规则的推理查询引擎将得出以下推论:
shop:ChamoisHenley rdf:type shop:Shirts.
shop:ChamoisHenley rdf:type shop:MensWear.
shop:ClassicOxford rdf:type shop:Shirts.
shop:ClassicOxford rdf:type shop:MensWear.
shop:BikerT rdf:type shop:Shirts.
shop:BikerT rdf:type shop:MensWear.
其中一些三元组也得到了确定;查询将在其上进行的完整三元组如下,其中推断出的三元组用斜体表示:

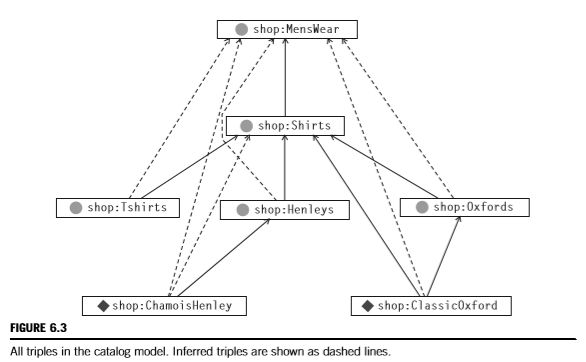
模型中的所有三元组,包括断言的和推断的,如图6.3所示。我们使用的约定是,断言的三元组打印为实线,推断的三元组打印为虚线。这种约定贯穿全书。
当我们从多个来源获取信息时,这些信息会变得更加微妙,其中每个来源本身都是一个包含推理引擎的系统。大多数RDF实现都提供了一种功能,通过这种功能,可以在三元组存储中直接断言新的三元组。这使得应用程序可以很容易地断言任何或所有推断的三元组。如果这些三元组随后被序列化(比如inRDF/XML)并在Web上共享,另一个应用程序可以将它们与其他源合并,并得出进一步的推论。在类似这样的复杂情况下,断言和推断的简单区别可能过于粗糙,无法有效地描述系统中正在发生的事情。
When Does Inferencing Happen?
RDFS和OWL标准定义了哪些推论是有效的,给出了特定的三元组模式。但是推断是什么时候发生的呢?推理完成了吗?如果有的话,推断三元组存储在哪里以及如何存储?他们有多少人?
这些问题完全超出了RDFS和OWL定义的范围,但是对于任何符合这些标准的实现来说,它们显然是非常重要的。因此,这些问题的答案在不同的实现中可能会有所不同,这一点也不奇怪。最简单的方法是将所有三元组存储在一个存储库中,不管它们是断言的还是推断的。一旦确定了模式,任何推断的三元组都将插入到存储中。我们将此称为缓存推理,因为所有推理都与数据一起存储(“缓存”)。这种方法描述和实现起来非常简单,但是存在三重存储中三元组爆炸的风险。在另一个极端,实现实际上永远不会在任何持久性存储中存储任何推断的三元组。推理只在响应查询时进行。我们将其称为即时推断,因为推断是在最近可能的时刻计算的。查询响应的生成方式尊重所有适当的推理,但不保留任何推断的三元组。这种方法有复制推理工作的风险,但就持久性存储而言,它非常节省。这些不同的方法在变更管理方面具有重要的影响。如果一个数据源发生了变化,也就是说,一个新的三元组被添加到某个数据存储中,或者一个三元组被删除,会发生什么?持久保存推论的策略必须决定还必须删除哪些推论的三元组。这提出了一个难题,因为有可能有许多方法可以推断出三元组。仅仅因为一个推论被删除了一个三元组而削弱了,这是否意味着删除这个三元组是合适的呢?在查询时重新计算所有推理的方法不需要面对这个问题。“及时”推理的一个重要变体是根本不进行显式推理。在关于衬衫子类的示例中,我们已经看到查询如何显式地表达它想要的数据,而完全不依赖于模型的推理语义。正如我们在下一节中看到的,即使在没有显式推理的情况下,模型的推理解释对于组织和理解语义应用程序仍然很重要。
Inferencing as specification
在本章的开始,我们查看了一个查询来查找目录中的所有衬衫,显式地跟踪所有rdfs:subClassOf 的子类:
SELECT ?item
WHERE {?class :subClassOf* :Shirts .
?item a ?class . }
这个选择是为了支持一个搜索操作——“找到我所有的麂皮衬衫。”“这个查询根本没有任何对推理的显式引用;它返回它的答案,不涉及推断的三元组与断言的三元组;它只处理断言的数据。但是我们如何知道这个查询返回的条目是衬衫呢?
同样的问题在Java等程序中也会被问到,如果我们写一个收集所有T恤的子集成员的程序,我们怎么指导我们收集的东西是T恤?如果我们在用户搜索的结果中返回其中一件东西,我们是否有理由认为它本身就是一件衬衫呢?这就是语义模型在解释数据中的作用:它可以告诉我们写的查询是否正确。在这个例子中,我们的模型告诉我们每一个Henley都是T恤,因为Henlety类是T恤类的一个子类。该模型及其形式化语义保证该查询的所有结果都是衬衫。
从这个意义上说,模型是一个规范。任何关于特定查询的适当性的讨论都可以求助于模型进行仲裁——这个查询与模型一致吗?在本例中,模型告诉我们,这个查询的任何结果都是衬衫,因此将它们视为衬衫是合适的。当模型是用一种能够进行自动推理的语言(如RDFS、RDFS- plus或OWL)编写的时候,它变得特别有用——规范被称为可执行的。这意味着我们可以运行一个程序,它将确切地告诉我们模型的含义。在上面展示断言和推断三元组的示例中,我们展示了这种功能的结果,结果是所有衬衫(任何类型)的列表。
在构建应用程序时,我们可能决定使用通用推理功能,或者决定使用扩展查询(如这里显示的查询),或者使用其他语言编写程序。规范(甚至是可执行的规范)告诉我们程序或查询应该做什么;它没有告诉我们应该怎么做。无论这种实现选择如何,模型都扮演着证明查询或程序合理性的中心角色。如果许多人开发不同的系统(甚至使用不同的技术方法),他们提供的结果将是一致的,如果他们都反对相同的模型。
Summary
RDF提供了一种表示数据的方法,这样来自多个源的信息就可以组合在一起,并像处理来自单个源的信息一样处理它们。但当我们想要使用这些数据时,这些数据来源的差异就显现出来了。例如,我们希望能够编写一个能够从所有集成数据源获取相关数据的查询。语义Web以建模语言的形式提供了一种解决此问题的方法,其中可以描述数据源之间的关系。一个建模结构的意义是由可以从中抽取的模式给出的。信息集成可以通过在查询过程之前或过程中调用推理来实现;查询不仅返回断言的数据,还返回推断的信息。此推断信息可以使用多个数据源。我们已经看到,即使是非常简单的推理也可以为数据集成提供价值。但究竟需要什么样的推论呢?这个问题没有一个普遍的答案。语义Web标准确定了许多不同层次的表达能力,每个层次都支持不同的推论,并针对不同层次的复杂数据处理(dataintegrationoveremanticweb)进行了设计。
在接下来的章节中,我们将探讨三个特定的推理层次。它们只是在每种语言所允许的推论方面有所不同。RDFS(第6章)是W3C定义和维护的建议。它使用少量的推理规则,这些规则主要处理类与子类之间的关联以及类与属性之间的关联。RDFS-PLUS(第7章)是我们为本书定义的一种模式。我们发现一组特定的推理模式在教学上(作为对OWL更复杂的推理模式的温和介绍)和实践上(作为其本身的一个有用的集成工具)都很有用。RDFS- plus构建在RDFS之上,以包含对属性和相等概念的约束。OWL(第9章和第10章)是W3C定义和维护的一项建议,它进一步构建了基于允许的属性值描述类的规则。所有这些标准都使用推理的概念来描述模型的含义;它们所支持的推论是不同的。
Fundamental concepts
Inferencing—The process by which new triples are systematically added to a graph based on patterns in existing triples.
Asserted triples—The triples in a graph that were provided by some data source.
Inferred triples—Triples that were added to a model based on systematic inference patterns.
Inference rules—Systematic patterns defining which of the triples should be inferred.
Inference engine—A program that performs inferences according to some inference rules. It is often integrated with a query engine.