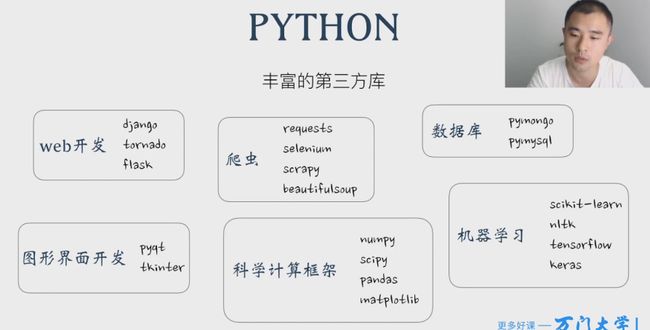
Jupyter Notebook 利器
入门基础
windows一键安装:3.5.2版本
第三方包:windows平台:pip install package(+包名)
因为防火墙问题,直接输入命令会失败
+verbose会讲如何失败
在windows命令器中输入:
pip install pandas(这个包名)
pip --verbose install pandas(打印失败原因)
pip list(列出本地已经安装的包)
一般用这种代码
pip install -i --trusted-host http://pypi.douban.com/simple/ pandas
win10可能有坑:红字,cannot detect archive format
实在不行直接谷歌或者百度这个包然后来下载
环境搭建:notebook
如何学好编程
基础部分:
- 基本语法
- 数据结构
- 输入输出
- 异常处理
进阶提高:
- 常用算法
- 数据库访问
- 面向对象
-其他
基本语法
- 基本数据类型
- 对象的定义和声明
- 循环和判断:for,foreach,if,while,do
- 逻辑运算
- 位运算
数据结构
- 数组
- 字符串
- 系统标准库自带类型
- 如何实现常用数据结构:链表、堆栈、二叉树
输入输出
- 标准输入输出:print,echo,input
- 文件读写:文本(行读写)/二进制(偏移量+大小)
- 格式化字符串
异常
- 抛出和捕捉异常:try/catch,try/except
- 异常和错误的区别以及应用
pass:什么都不做,有时候需要做填充,解决语义的歧义
continue:跳出当前循环
:指数运算 102 =100
//:除法,且只留整数
not:取反
<<:左移位
:右移位(二进制)
16<<2(左移两位4)64
30<<3(左移三位8)240
100>>3(右移3位/8,取整数)
二进制:0b开头,八进制0o开头
Python 语法基础
- 输出
print("") - 注释
-
注释法
print("")
-
三引号注释法
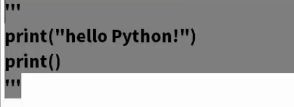 image.png
image.png
-
标识符
 image.png
image.png 变量
-
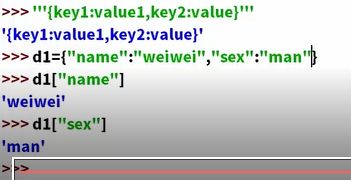
数据类型
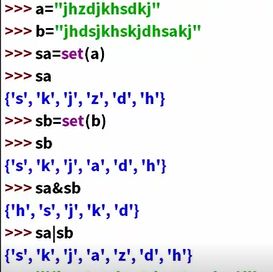
数,字符串,列表(list)a=["my","name"],元组(tuple)cde=("my","name"),cde[0]=my,元组和列表的区别:元组不能修改元素,列表可以修改元素,集合(set),字典(dictionary)
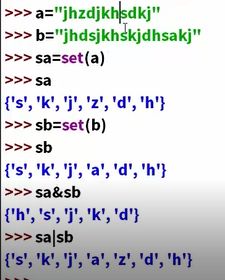 image.png
image.png
- 运算符
-
-
- / %(求余数) //求模
-
-
缩进
 image.png
image.png
 image.png
image.png
Python控制流
三种基本控制流:
- 顺序结构(做事情一直把他做下去)
- 条件分支结构(利用if来实现)
- 循环结构()
if语句
while语句(循环)
for语句(循环)(遍历列表的内容)


中断结构
中途退出的一种结构,常有break语句与continue语句。


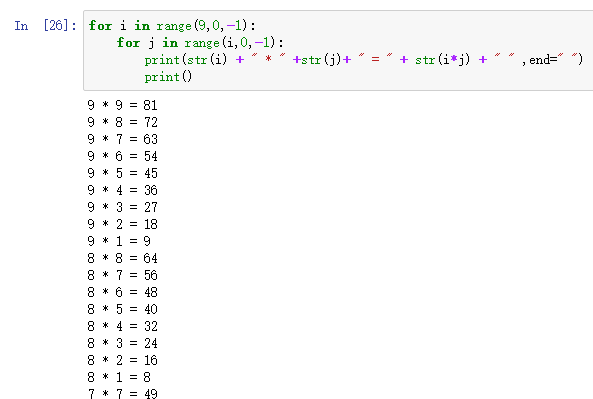
输出乘法口诀:

逆向乘法口诀作业
为什么要强制转换,因为*是字符,要相同的才能想加的,所以要转化
range(start, end, scan)
for i in range(9,0,-1):
for j in range(i,0,-1):
print(str(i) + " * " +str(j)+ " = " + str(i*j) + " " ,end=" ")
print()

注意最后一个print的位置,要与第二个for对齐才能这样输,反例
Python函数详解
函数的本质是功能的封装。
局部变量与全局变量
作用域:生效范围,全局变量:作用域从头到尾,局部变量:作用域在局部

把函数里面的局部变量变为全局变量

排错的时候可以利用二分段法(在中间,把后面注释掉,加一个print)
函数的定义与调用
def定义函数,一般命名不要用拼音
def abc():
函数的参数

实实在在将10和19传递给a,b。ab相当于形参

Python的模块
可以理解成函数的一个升级版本,模块按类别来分类(类似java的类),把一类的功能都放在一个模块里面。
系统自带的模块在lib目录中。
模块的导入
- import 模块名
- from...import...(from模块,import模块里的某一个方法)
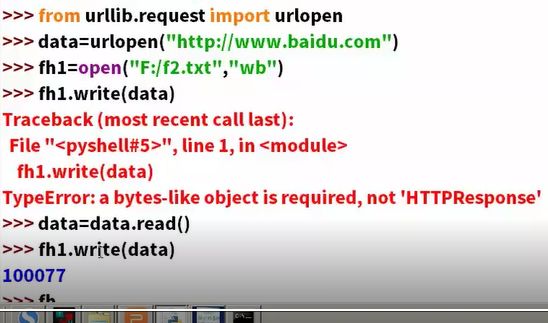
不能跨层导入,要一层层导入,(urlopen在request下面)。
import urllib
from urllib.request import urlopen
data1=urllib.request.urlopen("http://www.baidu.com").read()
print(len(data1))
第一种导入方法

第二种
一开始就定位到相关的文件
from urllib import request
data3=request.urlopen("http://jd.com").read()
print(len(data3))
自定义模块
函数需要返回值,我们用return,执行完这个函数这个函数的整体就成了return的值。
文件操作概述
用Python做文件的打开,关闭,读取,写入等操作,例如合并多个excel表格文件的内容。


Python异常处理

try:试着去执行这一块代码


open("","a")
wb代表二进制写入
open(路径+文件名,读写模式)
读写模式:r只读,r+读写,w新建(会覆盖原有文件),a追加,b二进制文件.常用模式
如:'rb','wb','r+b'等等
读写模式的类型有:
rU 或 Ua 以读方式打开, 同时提供通用换行符支持 (PEP 278)
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
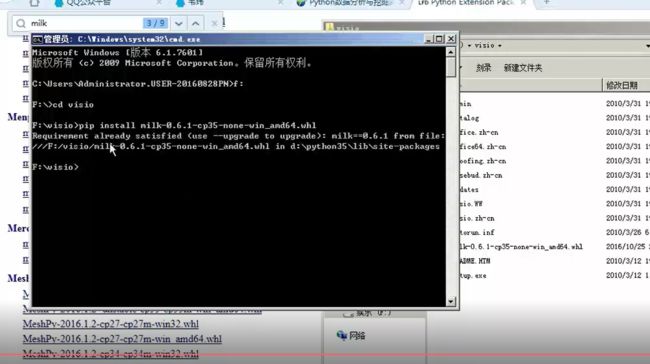
爬虫初识

cp指的是版本,直接搜索就行。
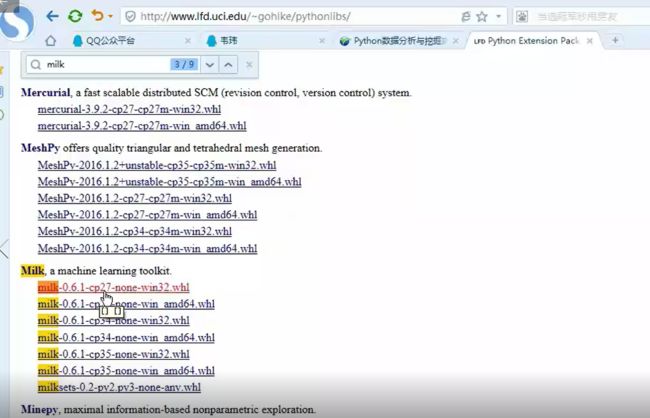
下载之后的安装:cmd下,进入下载的包的位置
网络爬虫原理
- 通用爬虫
- 聚焦爬虫:有一个过滤环节,有一个筛选环节
正则表达式

非打印字符:\n换行,\t制表符
格式:第一个是规则,第二个是目标

通用字符:
- \w能匹配任意一个字母数字或者下划线
- \d匹配任意一个十进制数
- \s匹配任意一个空白字符
- \W匹配小w相反的东西,匹配任意一个除了字母数字下划线以外的字符
-
\D与\d同样也相反
 image.png
image.png
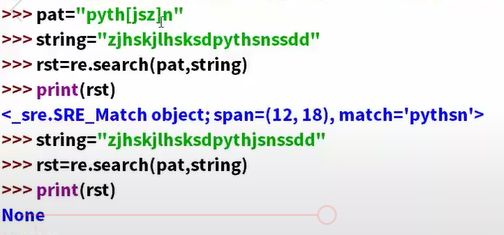
原子表,用来定义平等的原子。用[],[jsz]三个原子,都是平等的,有其中一个就ok,只能其中一位匹配不能多位匹配。
元字符

- .能够匹配任意的字符
- ^匹配字符串开始的位置
- $匹配字符串结束的位置
- *匹配一次或者多次还有0次例如s(右上角星号)匹配ss sss s
- ?匹配0次或者1次
- +匹配一次或多次没有0次
- {3}前面的原子恰好出现3次,t{6}恰好有6个- t(连在一起的) t{6,}(恰好至少出现了6次)
s{4,7}至少出现4次,至多出现7次。 - |,t|s(二选一)
-
()
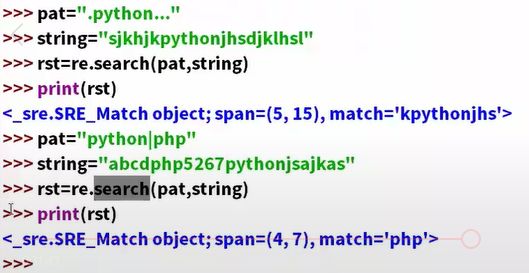 image.png
image.png
学到模式修正符

模式修正符:
- I 可以让正则表达式忽略大小写
- M 多行匹配
- L 本地化识别匹配
- U根据unique字符解析字符
-
S让.的匹配也匹配上换行符
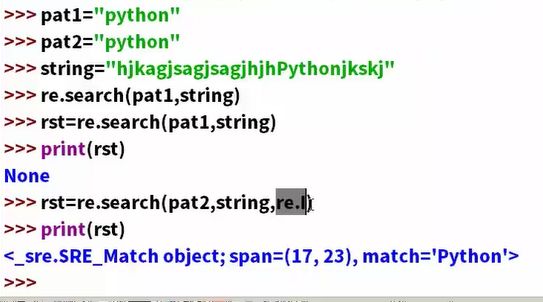 image.png
image.png
贪婪模式,懒惰模式
p.y:贪婪模式,尽可能多的去匹配。 中间的字符是什么,有多少都是ok的。.替换任意通用字符, 0,1,多个
p.*?y:懒惰模式,够用就溜了
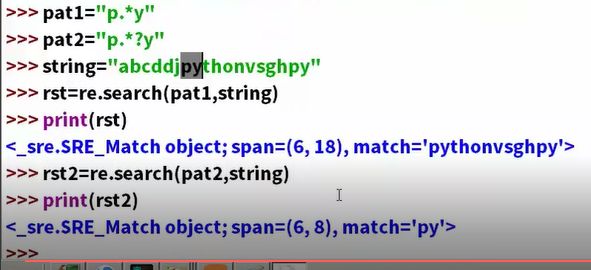
懒惰模式:精确定位
贪婪模式:定位更广
正则表达式函数

match:是从头开始搜索,一开始就要满足才可以。
search:满足头的东西可以出现任意位置。但只给一个结果。
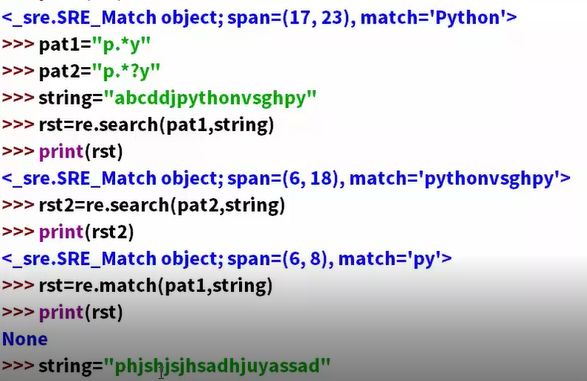
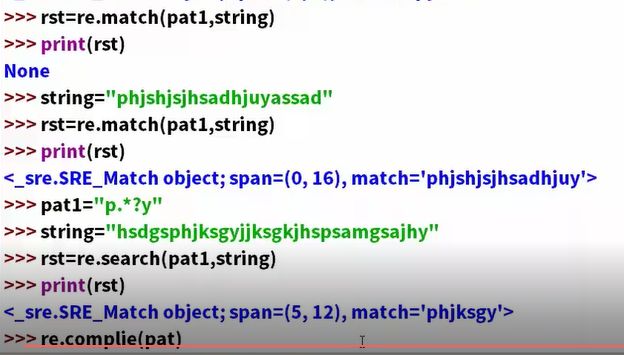
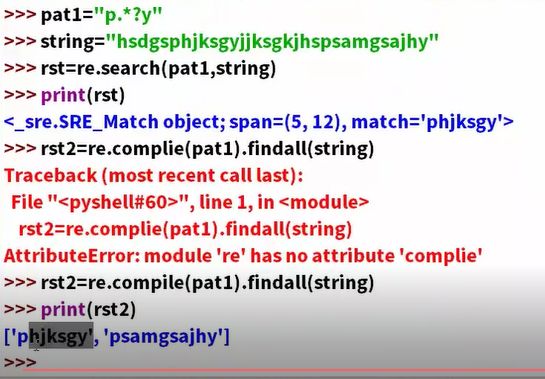
引入一个全局匹配complie
re.compile(对应的表达式).findall(待搜索字符)
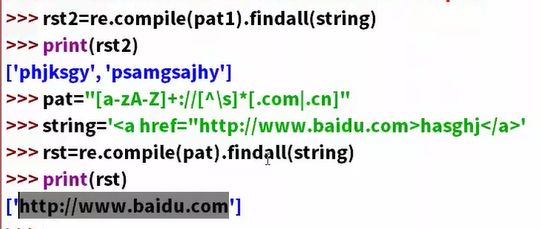
写在[ ]表示非,只要是””这个字符是在中括号”[]”中被使用的话就是表示字符类的否定,如果不是的话就是表示限定开头。我这里说的是直接在”[]”中使用,不包括嵌套使用。
其实也就是说”[]”代表的是一个字符集,”^”只有在字符集中才是反向字符集的意思。

左右不需要输出来,打一个小括号,只输出这个小括号里面的东西。

单双引号区别:

第二次作业爬取图书馆
import urllib.request
data=urllib.request.urlopen("https://read.douban.com/provider/all").read()
import re
data=data.decode("utf-8")
pat1='(.*?)'
mydata=re.compile(pat1).findall(data)
print(mydata)
写入

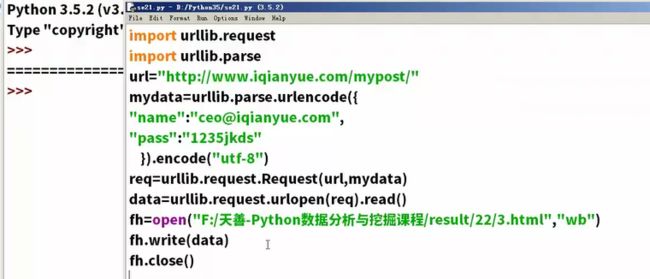
Urllib库实战
- urlretrieve(要爬的参数,本地地址):直接将某个网页爬到本地
- urlcleanup:清除由于urlretrieve产生的缓存。
- info:显示当前环境的一些信息
- getcode:当前网页状态码,返回200(网页返回正确),403禁止访问。
-
geturl:现在爬的是哪个网页
 image.png
image.png
超时测试:


自动模拟http请求


url直接爬还不支持https,要写成http

涉及到汉字的编码问题

post
请求:(地址,数据)
爬虫异常处理
200是正常进行

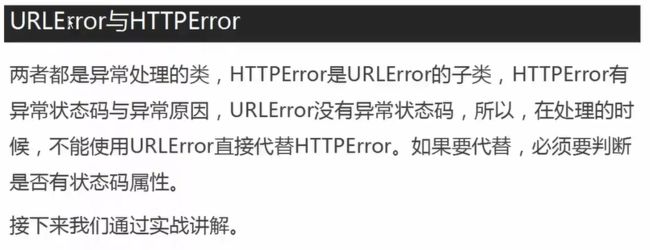
urlerror:
- 连不上服务器
- 远程Url不存在
- 本地没有网络
- 触发了http子类
防屏蔽了,因为没有模拟浏览器登陆
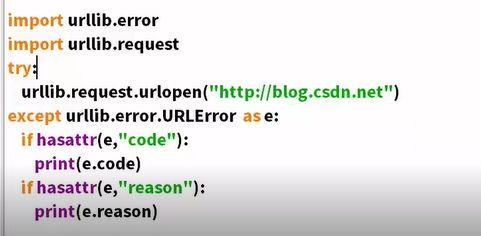
浏览器伪装技术
修改请求的报头
网页先用F12然后找 ,发生一次访问操作,点network,点header 在找到user-agent
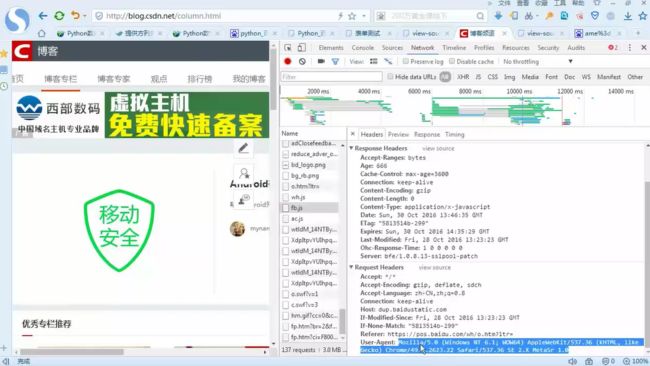
然后复制进去
build_opener创建一个报头

爬新闻程序
有些网站utf-8有问题,可以在后面加一个ignore
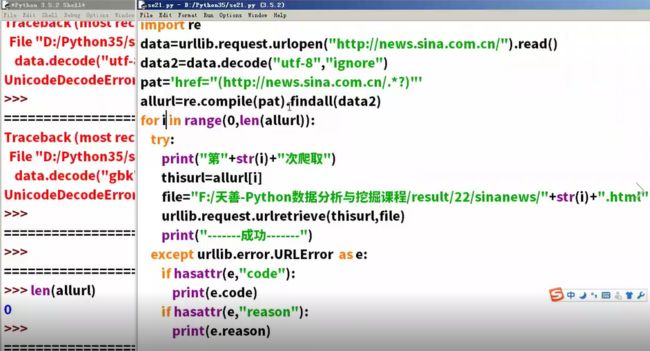
第三次作业

作业代码:
import re
import urllib.request
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
data=opener.open("https://www.csdn.net/").read()
data2=data.decode("utf-8","ignore")
pat='href="(https://.*?)"'
allurl=re.compile(pat).findall(data2)
for i in range(0,len(allurl)):
try:
print("第"+str(i)+"次爬取")
thisurl=allurl[i]
file="F:/python/test"+str(i)+".html"
urllib.request.urlretrieve(thisurl,file)
print("成功")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
爬虫防屏蔽手段之代理服务器

因为用自己的很有可能被ip封锁,所以需要代理服务器
ProxyHandler{“http”;“代理ip及其端口”}
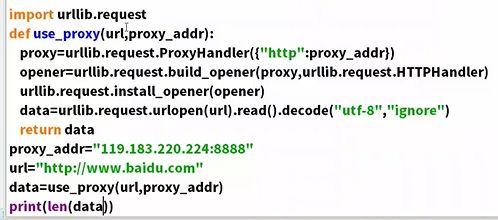
多次换代理ip,变换成一个列表,用循环就行
图片爬虫
-
爬取淘宝图片
图片核心一直找不到,可以多换换浏览器看看。
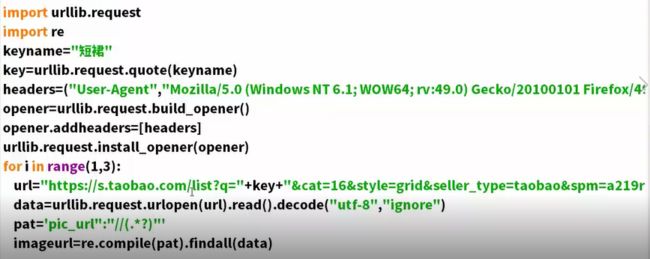 image.png
image.png
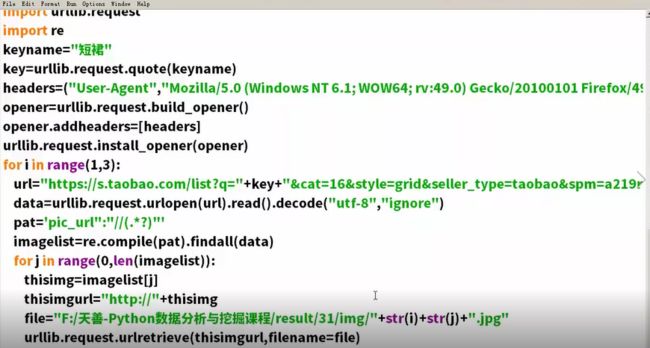
将图片显示出来
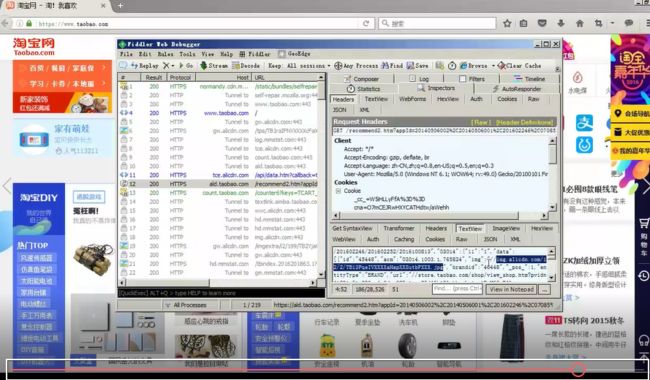
找有js文件的地方,来看抓包的源码
第四次作业爬取千图网
import urllib.request
import re
keyname="5244251"
key=urllib.request.quote(keyname)
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
urllib.request.install_opener(opener)
page=['','?page=02','?page=03']
for i in range(0,3):
url="http://www.58pic.com/c/"+keyname+str(page[i])
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
pat="background:url\('(.*?)'"
imagelist=re.compile(pat).findall(data)
for j in range(0,len(imagelist)):
try:
thisimg=imagelist[j]
thisimgurl=thisimg
file="F:/python/test/"+str(i)+str(j)+".jpg"
urllib.request.urlretrieve(thisimgurl,filename=file)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
几个tips:假如正则匹配时候有括号,但本来括号用正则是选取里面内容的,所以需要用转义字符。"background:url('(.*?)'" 用\进行转义
空字符直接用一个空格表示:
找图片的方式:
- 换不同的浏览器,找原图的特殊字符。视频23,第32分钟有讲解
- 找缩略图与原图链接之间的匹配关系。
淘宝爬图片
import urllib.request
import re
keyname="q=%E6%96%87%E8%83%B8"
key=urllib.request.quote(keyname)
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
urllib.request.install_opener(opener)
page=['','&s=44','&s=88']
for i in range(0,3):
url="https://s.taobao.com/search?"+keyname+str(page[i])
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
pat='pic_url":"(.*?)","detail_url'
imagelist=re.compile(pat).findall(data)
for j in range(0,len(imagelist)):
try:
thisimg=imagelist[j]
thisimgurl='http:'+thisimg
file="F:/python/test/"+str(i)+str(j)+".jpg"
urllib.request.urlretrieve(thisimgurl,filename=file)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
Python抓包分析

因为数据很有可能隐藏其中
右边分为response和request。上面是request(发送的请求)response(收到的回复)
复制出评论页,rate,右键copy,just url
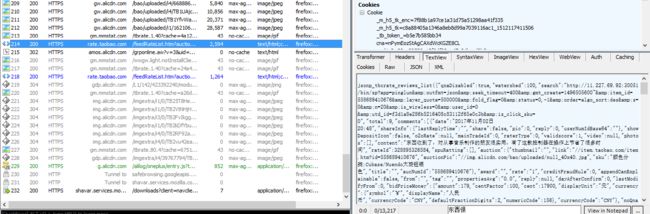
腾讯视频评论的抓取


print(eval("u\'"+comdata[0]+"\'"))
相当于是 固定住u' ,后面在固定住'。
微信爬虫
time模块(延时模块)
代码:
#http://weixin.sogou.com/
import re
import urllib.request
import time
import urllib.error
import urllib.request
#自定义函数,功能为使用代理服务器爬一个网址
def use_proxy(proxy_addr,url):
#建立异常处理机制
try:
req=urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0')
proxy= urllib.request.ProxyHandler({'http':proxy_addr})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(req).read()
return data
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
#若为URLError异常,延时10秒执行
time.sleep(10)
except Exception as e:
print("exception:"+str(e))
#若为Exception异常,延时1秒执行
time.sleep(1)
#设置关键词
key="Python"
#设置代理服务器,该代理服务器有可能失效,读者需要换成新的有效代理服务器
proxy="127.0.0.1:8888"
#爬多少页
for i in range(0,10):
key=urllib.request.quote(key)
thispageurl="http://weixin.sogou.com/weixin?type=2&query="+key+"&page="+str(i)
#a="http://blog.csdn.net"
thispagedata=use_proxy(proxy,thispageurl)
print(len(str(thispagedata)))
pat1='=re.compile(pat1,re.S) 为了让(.*?)也匹配上换行符
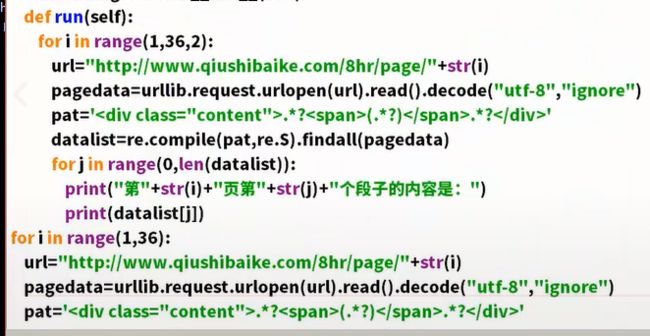
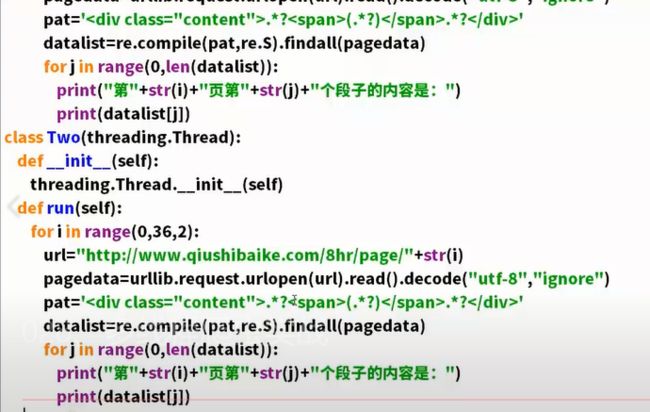
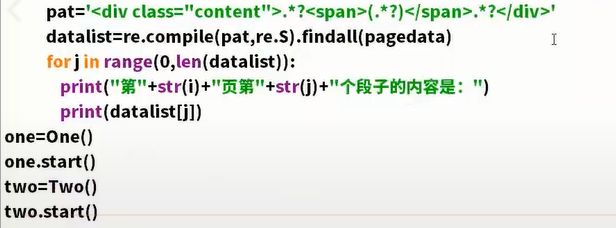
多线程爬虫
程序并行执行。
threading模块,可以多线程。
class A(threading.Thread)创建A这个多线程。
A里面必须要两个函数。
上面的方法是初始化线程。
后面的方法是具体的用法。
要开启线程,先要实例化线程
t1=A()
t1.start()启动这个线程

分别爬奇数,一个偶数。

Scrapy框架
利用做大型的爬虫项目
Scrapy框架常见命令实战
常见命令:
在cmd输入:scrapy -h(看有哪些功能)
scrapy fetch -h(看这个功能的帮助)
scrapy fetch http://www.baidu.com
(会显示出过程)
scrapy fetch http://www.baidu.com --nolog
(不显示过程)
- fetch显示爬取过程
- run spider(运行一个爬虫文件,不需要建一个工程)
-
shell(启动scrapy交互终端,通常测试会用到)
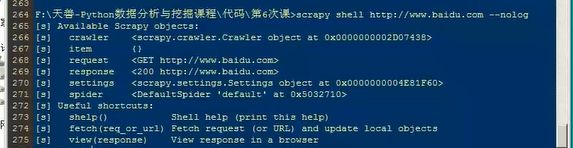 image.png
image.png
在交互终端可以提取一些相应的信息
- startproject(创建爬虫项目)后面接项目名
- version查看对应的版本信息
-
view(下载这个网页并查看)
 image.png
image.png
除了全局命令,还有项目命令,要进入项目文件夹之后才能看到。
- bench测试本机性能
一些文件功能
- init初始化文件
- pipelines,爬取之后的处理

在爬虫工程建爬虫文件,-l:看母版
basic:基本爬虫
crawl:自动爬虫
xmlfeed:基于xml文件
csvfeed:基于csv文件
http协议名 www主机名 主机名例如: baidu.com
格式:
scrapy genspider -t 模板名(basic) peter(文件名) baidu.com(域名)
-
check(后面说到的都是项目命令)
 image.png
image.png crawl(用的非常多,运行某个爬虫)
list(展示当前项目下可以使用的爬虫文件)
edit(直接打开编辑器对爬虫编辑,linux环境下可以)
parse(获取某个网页)
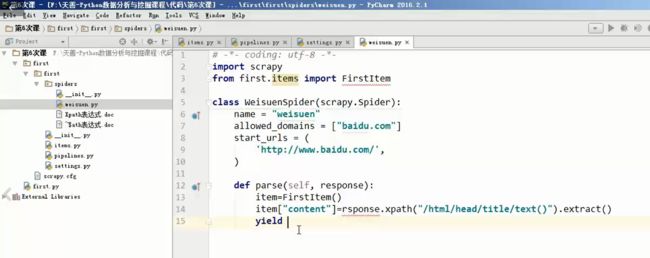
第一个scrapy爬虫
XPath表达式(适合用标签的)
/ 代表从顶端开始寻找一个标签
/html(寻找这个标签里面的东西)
/html/head/title

//表示寻找所有的标签
text():用来提取文字信息
@:提取标签的属性信息:
标签[@属性=值]
先写items、pipelines、settings再写py程序
scrapy.Field创建容器
Scrapy自动爬虫

allow:设置那个标签
callback回调函数
follow:是否跟随:是否跟着爬下去
在setting里面接触useragent注释(让除了第一次以外每一次爬都是从useragent来的)

这个地方的要用yield返回。如果是return的话,返回几次就会崩溃掉。
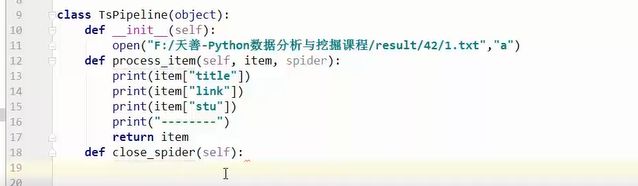
init默认的初始化方法,这个类会一开始执行它。
close是最后执行的
自动登录
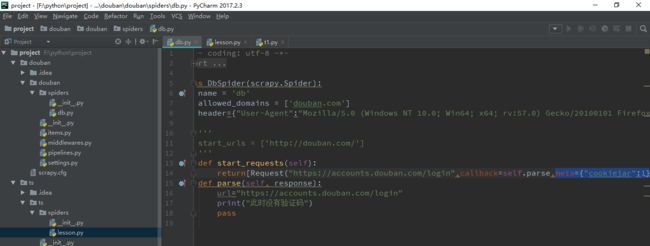
把cookiejar设为1,保留登录状态。
当当网爬取
引入数据库
用的是本机,本机数据库
db= 选择数据库
insert into插入信息(表名)
conn.query执行语句
补充内容
-
jason数据:键值对
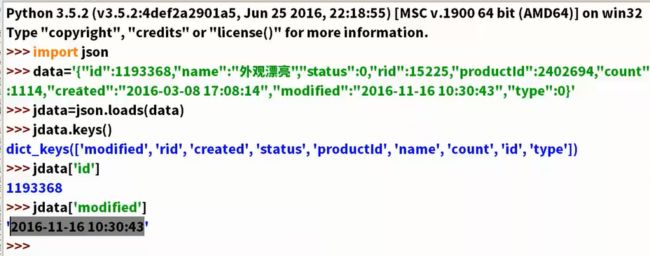 image.png
image.png 构建分布式爬虫需要用的:redis(分布式的集群),scrapy-redis(结合scrapy与redis),scrapy
关闭cookie追踪防止爬虫发现的一种方法
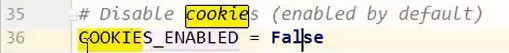
u字符的翻译查看
快速了解数据分析与数据挖掘技术
数据挖掘的步骤
目标:获得什么样的目标等等
获取数据:爬虫采集
四类建模模型:分类,聚类,关联,预测


数据挖掘相关模块

- numpy模块,有数组支持(python默认是没有数组支持,之前一般用list列表进行,当数据量大了,列表处理很慢,也是基础模块)
- pandas很基础,基本数据相关都需要用到

选择numpy+mkl这个包,不是单独numpy单独的包
相关模块的基本使用

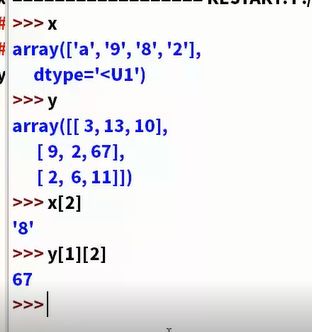
模块的一些基本操作
numpy模块(取别名,import numpy as aa)
- 不知道格式的字符串排在最后
- 三维数组排序(排数组里面元素排)
-
切片 数组[起始下标:最终下标+1]
省略不写代表衍生到头
 image.png
image.png
pandas模块
- Series概念,指某一串数字(一串数字叫做一个series数字)有索引(不指定的话就是0,1,2...等排下去;指定索引加上index数组)
-
DataFrame类似表格,代表行列整合出来的数据,指定列名(加一个columns),还可以通过字典的方式,pandas中数字不够会自动填充的,填充为它本身
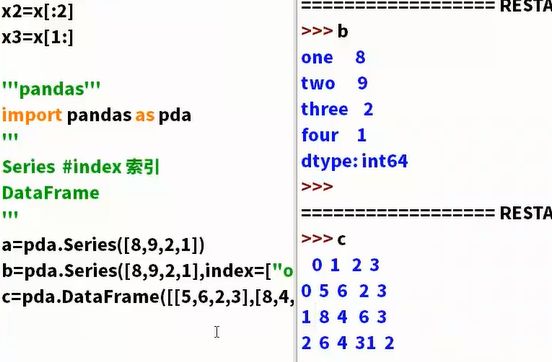 image.png
image.png

结果输出

head和tail


-
describe:统计数据情况,按列统计,count(计数,多少个元素,one这一列有三个元素);mean(平均数);std(标准差);25%,50%,75%代表分位数(前25%的分位数,前50%分位数等)
 image.png
image.png -
数据转置(行列转换)
d.T
 image.png
image.png
数据导入学习

按照排序,放数据表头第一个元素(按这个元素所有的分类的大小排序)降序利用:des和ascending=False
read_table:导入文本数据
- sql导入,设置connect,然后设置查询语句
- html读取是读取网页标签里的table标签。
-
导入数据,只导入数据部分不导入文字部分
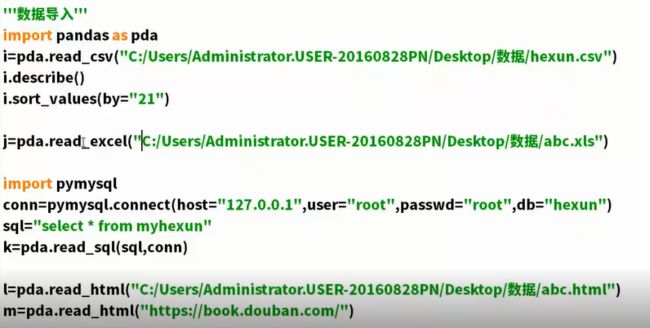 image.png
image.png
 image.png
image.png
matplotlib基础
#折线图/散点图plot
import matplotlib.pylab as pyl
import numpy as npy
x=[1,2,3,4,8]
y=[5,7,2,1,5]
#pyl.plot(x,y)#plot(x轴数据,y轴数据,展现形式)#多个plot的话会直接叠加上去
#pyl.show()
#默认为折线图,设置为o就是散点图
#pyl.plot(x,y,'o')
#pyl.show()
#改变散点的颜色
#pyl.plot(x,y,'oc') #不仅仅是青色还是散点图
#颜色
'''
c:青色;r:红色; m:品红;g:绿色; b:蓝色
y黄色 k黑色 w白色
'''
#形式
'''
直线 -
虚线 --
-.(就是-.形式)
:(细小虚线)
'''
'''
pyl.plot(x,y,'mp')
pyl.show()
'''
#点的样式(表示散点的类型,就不用重复用散点符号o)
'''
s方形 h/H六角形 *星形 +加号 x(x)型 d/D菱形 p五角形
'''
#起名字,或者给x,y轴加名字
'''
pyl.plot(x,y)
x2=[1,3,6,8,10,12,19] 多条曲线的绘制
y2=[1,6,9,10,19,23,35]
pyl.plot(x2,y2)
pyl.title("show")
pyl.xlabel("peter")
pyl.ylabel("hah")
pyl.xlim(0,20) 给xy轴设定范围
pyl.ylim(1,18)
pyl.show()
'''
#随机数的生成
import numpy as npy
data=npy.random.random_integers(1,20,10)#整数的随机数(最小值,最大值,个数)
#生成具有正态分布的随机数(两个重要的参数:平均数和标准差,在平均数附近的人数很多,大概判断为正态分布)
#npy.random.normal(均数,西格玛(越小越陡,越大越平缓,生成的个数)
#同一个区域
#直方图hist
'''
data3=npy.random.normal(10.0,1.0,10000)
pyl.hist(data3)
pyl.show
'''
'''
data4=npy.random.random_integers(1,25,1000)
pyl.hist(data4)
pyl.show
'''
'''
data4=npy.random.random_integers(1,25,1000)
sty=npy.arange(2,17,4)#(横坐标起始,横坐标末端,间隔)
pyl.hist(data4,sty)
pyl.hist(data4,sty,histtype='stepfilled')(取消轮廓)
pyl.hist(data4,histtype='stepfilled')(取消间隔限制)
pyl.show()
'''
#子图(在同一张图片中绘制多张图片)
#pyl.subplot(4,4,3)(行,列,当前区域())subplot将整个绘图区域等分为行*列个子区域,
然后按照从左到右,从上到下的顺序对每个子区域进行编号,左上的子区域的编号为1
#pyl.show()
#在子图中绘图
pyl.subplot(2,2,1)#绘制一个两行一列的图片
#在这个区域里面写得代码会在第一个区域里面绘制
x1=[1,2,3,4,5]
y1=[5,3,5,23,5]
pyl.plot(x1,y1)
pyl.subplot(2,2,2)
#同样输入第二个区域的图片数据
x2=[5,2,3,8,6]
y2=[7,9,12,12,3]
pyl.plot(x2,y2)
pyl.subplot(2,1,2)
#第三个区域
x3=[5,6,7,10,19,20,29]
y3=[6,2,4,21,5,1,5]
pyl.plot(x3,y3)
pyl.show()
读取和讯博客的数据并可视化分析
import pandas as pda
import numpy as npy
import matplotlib.pylab as pyl
data=pda.read_csv("F:/Python/代码/源码/第5周/hexun.csv")
#data.shape()#看有多少行多少列 雷士descrip
#data.values[][]#[第几行][第几列]自动变成数组
data.values #所有
data.values[1] #实际第二行
data.values[1][1]#具体的那个数
#本来五行 id 名字 网址 阅读数 评论数
#分析所有的数据中阅读数与评论数之间的关系
data2=data.T #转置行变列
y1=data2.values[3] #把这一块完全取出来
x1=data2.values[4]#获取评论数
#pyl.plot(x1,y1)
#pyl.show()
#分析id与阅读数之间的关系
x2=data2.values[0]#获取id
pyl.plot(x2,y1)
pyl.show()
数据板块作业:

数据探索与清洗
数据探索核心:
- 数据质量分析(跟数据清洗密切联系)
- 数据特征分析(分布,对比,周期性,相关性,常见统计量)
数据清理的步骤
- 先看数据有无缺失,describe统计所有有值的数据,len可以统计出没有值的数据,两者相对比。或者通过0数据发现缺失值(一些价格等数据不会为0,评论数这些可以不为0)
-
插补方式:均值
 image.png
image.png
#导入数据
import pymysql
import numpy as npy
import pandas as pda
import matplotlib.pylab as pyl
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="csdn")
sql="select*from taob"
data=pda.read_sql(sql,conn)
print(data.describe())
#数据清洗
#发现缺失值
#price字段有缺失,利用插补法处理(36是中位数)
x=0
data["price"][(data["price"]==0)]=None #在price这个标签里面只要里面的内容=0,就赋值为空
for i in data.columns:
for j in range(len(data)):
if(data[i].isnull())[j]:
data[i][j]="36"
x+=1
print(x)
#异常值处理,画散点图(纵轴用评论数,横轴用价格)
#得到价格
data2=data.T
price=data2.values[2]
#得到评论数据
comt=data2.values[3]
pyl.plot(price,comt,'o')
pyl.show
#异常值处理(评论数异常200000以上,价格异常大于2300)
line=len(data.values) #取出的是行数,data.values有所有的,加len得到行数
col=len(data.values[0]) #第0行加len,拿到列数
da=data.values
for i in range(0,line):
for j in range(0,col):
if(da[i][2]>2300):
print(da[i][j])
da[i][2]="36"
if(da[i][3]>20000):
print(da[i][j])
da[i][2]="58"
da2=da.T
price=da2[2]
comt=da2[3]
pyl.plot(price,comt,'0')
pyl.show()
#分布分析
#得到价格的最大值最小值
pricemax=da2[2].max() #(价格是在第二行)
pricemin=da2[2].min()
#评论的最大值最小值
commentmax=da2[3].max() #(评论是在第三行)
commentmin=da2[3].min()
#极差:最大值-最小值
pricerg=pricemax-pricemin
commentrg=commentmax-commentmin
#组距:极差/组数(自己随便定)
pricedst=pricerg/12
commentdst=commentrg/12
#画出价格的直方图
pricesty=npy.arange(pricemin,pricemax,pricedst)
pyl.hist(da2[2],pricesty)
pyl.show()
#画出评论的直方图
commentsty=npy.arange(commentmin,commentmax,commentdst)
pyl.hist(da2[3],commentsty)
pyl.show()
数据集成

同名不同意(一张表title代表商品,另一张表title不代表商品)
同意不同名

数据规约
-
简单变换
 image.png
image.png -
数据规范化
 image.png
image.png
离差标准化:消除单位影响
import pymysql
import pandas as pda
import numpy as npy
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="csdn")
sql="select price,comment from taob"
data=pda.read_sql(sql,conn)
#离差标准化 直接使用data2处理就可以了
data2=(data-data.min())/(data.max()-data.min())
print(data2)
#标准差标准化(也叫零-均值标准化):有正负,一半一半,他们的平均数为0,标准差为1
data3=(data-data.mean())/data.std()
print(data3)
#小数定标规范化
k=npy.ceil(npy.log10(data.abs().max())) #ceil是取整数(3.1取到4,3.6取到4)
data4=data/10**k
- 离散化(将连续数据变成离散数据,把0-10的数据归为一类,10-20归为一类)
- 等宽离散化(将属性的值分为具有相同宽度的区间)
- 等频率离散化(相同数量的记录放进去,把相同频率的点放在一个区间)
- 一维聚类离散化(将属性的值先用聚类算法)
#连续性数据离散化
#等宽离散化
data5=data[u"price"].copy() #拷贝一份,加u固定数据
data6=data5.T
data7=data6.values
#cut 函数
# pda.cut(data,k,label=["便宜","适中","有点贵","天价"])
#k等分为几分,如果k=4,四份;也可以用数组[3,6,10,19],label每个区域的标签名字
k=3
c1=pda.cut(data7,k,label=["便宜","适中","有点贵"])
print(c1)
#非等宽离散化
k=[0,50,100,300,500,2000,data7.max()]
c2=pda.cut(data7,k,label=["非常便宜","便宜","适中","有点贵","很贵","非常贵"])
print(c2)
属性构造
例如根据一个博客的评论数和点击数,构造一个点评比等
#属性构造
import pymysql
import pandas as pda
import numpy as npy
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="hexun")
sql="select * from myhexun"
data8=pda.read_sql(sql,conn)
print(data8)
ch=data8[u"comment"]/data8[u"hits"]
data[u"评点比"]=ch
#把这个评点比写进文件
file="./hexun.xls"
data8.to_excel(file,index=False)#索引index=无
规约
规约=精简
- 属性规约(采用降维度,丢掉一些属性)
- 数值规约(化范围0-100,100-200)
主成分分析
- 主要用来属性规约
- PCA算法(主要用来属性降维,在尽量保持数据本质的情况下将数据维数降低,将n维特征映射到K维上,k是有正交特征,k维特征也称为组元)
#属性构造
import pymysql
import pandas as pda
import numpy as npy
from sklearn.decomposition import PCA
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="hexun")
sql="select hits,comment from myhexun"
data9=pda.read_sql(sql,conn)
print(data9)
ch=data9[u"comment"]/data9[u"hits"]
data[u"评点比"]=ch
#主成分分析进行中
pca1=PCA()
pca1.fit(data9) #利用pca来处理data9
Characteristic=pca1.components #返回模型中各个特征向量
print(Characteristic)
#各个成分中各自方差的百分比,贡献率
rate=pca1.explained_variance_ratio_
print(rate)
#主成分分析
pca2=PCA(2) #()内为希望的维数
pca2.fit(data9)
reduction=pca2.transform(data9) #降维
print(reduction)
recovery=pca2.inverse_transform(reduction) #对其还原
print(recovery)
文本挖掘
跟数据有关
遇到的问题:由于目标计算机积极拒绝,无法连接
一般txt不能分析的话,新建一个txt另存为utf-8,如果还是不行,存为一个html网页用urllib爬出来,在读取
import jieba
sentence="我喜欢上海东方明珠"
w1=jieba.cut(sentence,cut_all=True)#第一个参数要分词的话,第二个参数:分词模式:全模式(分词很全,可能叠加)
#遇到generator要用循环把他变出
for item in w1:
print(item)
'''
#把cut_all改成false 精准模式(根据优先级)
w2=jieba.cut(sentence,cut_all=False)
for item in w2:
print(item)
#第三种 搜索引擎模式(利用搜索引擎的原理)
w3=jieba._lcut_for_search(sentence)
for item in w3:
print(item)
#默认的分词模式(默认采用精准模式)
w4=jieba.cut(sentence)
for item in w4:
print(item)
#词性标注 利用posseg方法
import jieba.posseg
w5=jieba.posseg.cut(sentence)
#.flag词性
#.word词语
for item in w5:
print(item.word+"---"+item.flag)
'''
'''
a:形容词
c:连词
d:副词
e:叹词
f:方位语
i:成语
m:数词
n:名词
nr:人名
ns:地名
nt:机构团体
nz:其他专有名词
p:介词
r:代词
t:时间
u:助词
v:动词
vn:名动词
w:标点符号
un:未知词语
'''
'''
#新建词典之后,词典加载(新加词典记得更改为utf-8)
jieba.load_userdict("") #新加的词典目录,不是持久化存储的,每一个需要添加一次
sentence2="天善智能是一个很好的机构"
w6=jieba.posseg.cut(sentence2)
for item in w6:
print(item.word+"---"+item.flag)
#更改词频,两种方式
sentence="我喜欢上海东方明珠"
w7=jieba.cut(sentence)
for item in w7:
print(item)
#发现上海,东方是两个词语,我们想要得到上海东方,结合在一起
#add_word把词语添加在字典中,我们要修改词频(有点问题)
jieba.suggest_freq("上海东方",True)
w8=jieba.cut(sentence)
for item in w8:
print(item)
#返回文本中词频高的词语,关键词
import jieba.analyse
sentence3="我喜欢上海东方明珠"
tag=jieba.analyse.extract_tags(sentence3,3) #第二个参数,提取词频高的前几个参数,默认20个
print(tag)
#返回词语的位置
w9=jieba.tokenize(sentence)
for item in w9:
print(item)
#以搜索引擎的模式来返回词语的位置
w10=jieba.tokenize(sentence,mode="search")
for item in w10:
print(item)
'''
#分析血尸的词频,一开始无法打开,加上utf-8还无法打开之后
#直接新建一个文本文档,全部复制过去,另存为的时候调为utf-8
#编码问题解决方案
import urllib.request
data=urllib.request.urlopen("http://127.0.0.1/dmbj.html").read.decode("utf-8","ignore")
tag=jieba.analyse.extract_tags(data,20)
print(tag)
Mysql爬虫补充
spider dangdang代码部分(注意Dangdangitem包的引用)
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from dangdang.dd.items import DangdangItem
class DdSpider(scrapy.Spider):
name = "dd"
allowed_domains = ["dangdang.com"]
start_urls = (
'http://www.dangdang.com/',
)
def parse(self, response):
item=DangdangItem()
item["title"]=response.xpath("//a[@class='pic']/@title").extract()
item["link"] = response.xpath("//a[@class='pic']/@href").extract()
item["comment"] = response.xpath("//a[@name='itemlist-review']/text()").extract()
yield item
for i in range(2,101):
url="http://category.dangdang.com/pg"+str(i)+"-cp01.54.06.00.00.00.html"
yield Request(url,callback=self.parse)
pipeline代码部分
# -*- coding: utf-8 -*-
import pymysql
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class DangdangPipeline(object):
def process_item(self, item, spider):
conn = pymysql.connect(host="127.0.0.1", user="root", passwd="123456", db="dd")
for i in range(0,len(item["title"])):
title=item["title"][0]
link=item["link"][0]
comment=item["comment"][0]
#编码的问题解决方案
conn.set_charset("utf8")
cursor=conn.cursor()
cursor.execute('SET NAMES utf8;')
cursor.execute('SET CHARACTER SET utf8;')
cursor.execute('SET character_set_connection=utf8;')
#sql插入的格式
sql="insert into goods(title,link,comment) values('"+title+"','"+link+"','"+comment+"')"
conn.query(sql)
conn.commit()
conn.close()
return item
Navicat用法:
crtl+s 保存退出
Mysql基本的语句:
进入:F:\MySQL\mysql-5.7.20-winx64\bin>mysql -u root -p
mysql> use dd
Database changed
mysql> select * from goods(映射goods表内所有的内容)
sql语句中输入的时候想要退出 ;+enter
反思:耐心看cmd里面的error
文本相似度分析
TF-IDF:用来评估一个词对于文件的
重要性。与出现的次数成正比,用来相似度的计算。
稀疏向量和稀疏矩阵
相似度分析的步骤
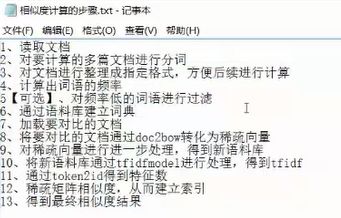
#文本相似度计算,以词语为单位,分词
from gensim import corpora,models,similarities
import jieba
from collections import defaultdict
#1 得到文档的内容
doc1="F:/Python/test/peter/d1.txt"
doc2="F:/Python/test/peter/d2.txt"
d1=open(doc1).read()
d2=open(doc2).read()
#2 分词
data1=jieba.cut(d1)
data2=jieba.cut(d2)
#3 整理为指定格式"词语1 词语2 词语3....词语n"整理成这种格式
data11=""
for item in data1:
data11+=item+" "
data21=""
for item in data2:
data21+=item+" "
#如果有第三个文档直接加在后面就行
documents=[data11,data21]
#4 计算词语的频率(没看懂)
texts=[[word for word in document.split()]
for document in documents]
frequency=defaultdict(int)
for text in texts:
for token in text:
frequency[token]+=1
#5 过滤掉部分低频词汇
texts=[[word for word in text if frequency[token]>=1]
for text in texts]
#6 建立词典
dictionary=corpora.Dictionary(texts)
dictionary.save("F:/Python/test/peter/wenben2.dict")
#7 加载要对比的文档
doc3="F:/Python/test/peter/d3.txt"
d3=open(doc3).read()
data3=jieba.cut(d3)
data31=""
for item in data3:
data31+=item+" "
new_doc=data31
#8 变为稀疏向量,可以直接使用doc2bow
new_vec=dictionary.doc2bow(new_doc.split())
#9 依据稀疏向量进一步处理得到语料库
corpus=[dictionary.doc2bow(text) for text in texts]
#10 通过models处理,得到tfidf
tfidf=models.TfidfModel(corpus)
corpora.MmCorpus.serialize("F:/Python/test/peter/d3.mm",corpus)
#11 通过tfidf得到特征向量
featureNum=len(dictionary.token2id.keys())
#12 稀疏矩阵相似度,建立索引
index=similarities.SparseMatrixSimilarity(tfidf[corpus],num_features=featureNum)
sim=index[tfidf[new_vec]]
print(sim)

从后到左,从后往前
目前的问题
pca 稀疏向量 127.0.0.1
Python数据建模

模型的建立依赖算法
Python数据分类实现过程

常见的分类算法

KNN算法
总的原则:物以类聚,人以群分。判断这一个事情的特征进行分类。
计算所有点到M点的距离,找出距离最近的点,KNN(中的k是指选择几个点,k=4,选择最近的4个点,图中选出cbgn,看哪个类别占的越多,就把他归为那一类)
knn算法实现步骤
- 处理数据
- 数据向量化
- 计算欧几里得距离
- 按照距离分类
from numpy import *
import operator
def knn(k,testdata,traindata,labels):
traindatasize=traindata.shape[0] #取到行数,1取列数
dif=tile(testdata,(traindatasize,1))-traindata#转换维度(范本有四个点,这边让他变成4个点)计算出差值
#对已经存在的数组进行维度拓展,tile(要拓展的数组,重复多少次)
#从纵方向拓展tile(a,(size,1)) 改成1,size是重复几次
#计算差值平方
sqdif=dif**2
sumsqdif=sqdif.sum(axis=1) #每一行求和
distance=sumsqdif**0.5
sortdistance=distance.argsort() #排序,他的结果是每一位的序号
count={}
for i in range(0,k):
vote=labels[sortdistance[i]] #labels相当于一个字典
count[vote]=count.get(vote,0)+1
sortcount=sorted(count.items(),key=operator.itemgetter(1),revers=True)#reverse=true 降序
sortcount[0][0]
参考文章
https://www.cnblogs.com/ybjourney/p/4702562.html
手写体数字的识别
读取每个像素,如果是黑色的就用数字1表示在这个像素上面
利用pillow模块处理模块
from numpy import *
import operator
def knn(k,testdata,traindata,labels):
traindatasize=traindata.shape[0] #取到行数,1取列数
dif=tile(testdata,(traindatasize,1))-traindata#计算出差值
#对已经存在的数组进行维度拓展,tile(要拓展的数组,重复多少次)
#从纵方向拓展tile(a,(size,1)) 改成1,size是重复几次
#计算差值平方
sqdif=dif**2
sumsqdif=sqdif.sum(axis=1) #每一行求和
distance=sumsqdif**0.5
sortdistance=distance.argsort() #排序,他的结果是每一位的序号
count={}
for i in range(0,k):
vote=labels[sortdistance[i]] #labels相当于一个字典
count[vote]=count.get(vote,0)+1
sortcount=sorted(count.items(),key=operator.itemgetter(1),revers=True)#reverse=true 降序
sortcount[0][0]
#图片处理
#先将所有图片转化为固定宽高(用图片软件就行),然后再转化为文本
from PIL import Image
from numpy import *
from os import listdir
im=Image.open("C:/Users/me/Pictures/weixin3.jpg")#图片地址
fh=open("C:/Users/me/Pictures/weixin3.txt","a") #追加的模式
im.save("C:/Users/me/Pictures/weixin.bmp") #保存为一个新的图片
width=im.size[0]#图片宽和高size[0] 宽
height=im.size[1]
k=im.getpixel((1,9)) #获取像素(那个坐标点)颜色
#例如返回RGB(255,255,255),白色的,加入三者之和为0,则黑色
for i in range(0,width):
for j in range(0,height):
cl=im.getpixel((i,j))
clall=cl[0]+cl[0]+cl[0]
if(clall==0):
#黑色
fh.write("1")
else:
fh.write("0")
fh.write("\n")
fh.close()
#加载数据
def datatoarray(fname):
arr=[]
fh=open(fname)
for i in range(0,32):
thisline=fh.readline()
for j in range(0,32):
arr.append(int(thisline[j]))
return arr
#建立一个函数取文件前缀
def seplabel(fname):
filestr=fname.split(".")[0]
label=int(filestr.split(".")[0])
return label
#建立训练数据
def traindata():
labels=[]
#listdir("文件夹名字")可以的到一个文件夹下所有的文件名
trainfile=listdir("")
num=len(trainfile)
#行的长度为1024(列),每一行存储一个文件
#用一个数组存储所有的训练数据,行:文件总数,列:1024
#zeros((2,5))生成两行五列的0
trainarr=zeros((num,1024)) #相当于一个初始化
for i in range(0,num):
thisfname=trainfile[i]
thislabel=seplabel(thisfname)
labels.append(thislabel)
trainarr[i,:]=datatoarray("traindata/"+thisfname) #理解为为i行上写上以下的的内容
return trainarr,labels
#用测试数据调用KNN算法去测试,看是否能够准确识别
def datatest():
trainarr,labels=traindata() #拿到训练集
testlist=listdir("testdata")
tnum=len(testlist)
for i in range(0,tnum):
thistestfile=testlist[i] #得到当前测试文件
testarr=datatoarray("testdata/" + thistestfile)
rknn = knn(3, testarr, trainarr, labels)
print(rknn)
datatest()
#抽某一个测试文件出来进行试验
trainarr,labels=traindata()
thistestfile=""
testarr=datatoarray(""+thistestfile)
rknn=knn(3,testarr,trainarr,labels)
print(rknn)
逻辑回归
做不出来,可能是sklearn包有问题导致的
"""
'''''1. data1 是40名癌症病人的一些生存资料,
其中,X1表示生活行动能力评分(1~100),
X2表示病人的年龄,X3表示由诊断到直入研究时间(月);
X4表示肿瘤类型,X5把ISO两种疗法(“1”是常规,“0”是试验新疗法);
Y表示病人生存时间(“0”表示生存时间小于200天,
“1”表示生存时间大于或等于200天)
试建立Y关于X1~X5的logistic回归模型'''
#######################################################
#读取整理数据
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
from sklearn.linear_model import RandomizedLogisticRegression as RLR
data=pd.read_table('data1.txt',encoding='gbk')
data
x=data.iloc[:,1:6].as_matrix()
y=data.iloc[:,6].as_matrix()
rlr = RLR() #建立随机逻辑回归模型,筛选变量
rlr.fit(x, y) #训练模型
rlr.get_support() #获取特征筛选结果,也可以通过.scores_方法获取各个特征的分数
print(u'通过随机逻辑回归模型筛选特征结束。')
print(u'有效特征为:%s' % ','.join(data.columns[rlr.get_support()]))
x = data[data.columns[rlr.get_support()]].as_matrix() #筛选好特征
lr = LR() #建立逻辑回归模型
lr.fit(x, y) #用筛选后的特征数据来训练模型
print(u'逻辑回归模型训练结束。')
print(u'模型的平均正确率为:%s' % lr.score(x, y)) #给出模型的平均正确率,本例为0.75
贝叶斯算法

import numpy
class Bayes:
def _init_(self): #初始化这个类,最开始执行
#初始化参数length
self.length=-1 #length=-1 表示未经过训练,如果经过训练肯定是有数据的则大于等于0
self.labelcount=dict()
self.vectorcount=dict()
def fit(self,dataSet:list,labels:list): #数据集,标签集
if(len(dataSet)!=len(labels)):
raise ValueError("输入的测试数组与类别数组长度不一致")
self.length=len(dataSet[0]) #测试数据特征值的长度
labelsnum=len(labels) #得到所有类别的数量
norlabels=set(labels) #得到不重复类别的数量
for item in norlabels:
thislabel=item #得到当前类别,看当前类别一共有多少的数据
self.labelcount[thislabel]=labels.count(thislabel)/labelsnum #求当前类别占总数的比例
for vector,label in zip(dataSet,labels): #相当于是两个一起的循环 例如 [[A,100010].[B.110001]]的循环
if(label not in self.vectorcount): #一开始为空,只要不在都往里面填入,但不要重复的,就可以写成 [A,100010,100011] [B,101000]
self.vectorcount[label]=[]
self.vectorcount[label].append(vector)
print("训练结束")
return self
def btest(self,TestData,labelsSet):
if(self.length==-1):
raise ValueError("还未训练")
#计算当前testdata分别为各个类别的概率
IbDict=dict()
for thisIb in labelsSet:
p=1
alllabel=self.labelcount[thisIb] #先求出这个标签的总占比
allvector=self.vectorcount[thisIb] #拿到这个标签对应的数据[A,100010,100011] ([B,101000]这个就没有了)
vnum=len(allvector) #数据集的个数
allvector=numpy.array(allvector).T
for index in range(0,len(TestData)):
vector=list(allvector[index])
p*=vector.count(TestData[index])/vnum #相当于+= 累乘
IbDict[thisIb]=p*alllabel
thislabel=sorted(IbDict,key=lambda x:IbDict[x],reverse=True)[0]
return thislabel
决策树算法
ID3 看信息的价值
C4.5
CART
信息熵的计算
log以2为底
去分析得到信息增益
import pandas as pda
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from sklearn.tree import DecisionTreeClassifier as DTC
fname="F:/Python/code/code/8/xiaoliang.csv"
dataf=pda.read_csv(fname,encoding="gbk")
x=dataf.iloc[:,1:5].as_matrix()
y=dataf.iloc[:,5].as_matrix()
#遍历x这个二维数组
for i in range(0,len(x)):
for j in range(0,len(x[i])):
thisdata=x[i][j]
if(thisdata=="是" or thisdata=="多" or thisdata=="高"):
x[i][j]=int(1)
else:
x[i][j] = -1
for i in range(0,len(y)):
thisdata=y[i]
if(thisdata=="高"):
y[i]=1
else:
y[i]=-1
"""
#容易错的地方: 如下直接使用
#建立决策树
from sklearn.tree import DecisionTreeClassifier as DTC
dtc=DTC(criterion="entropy") #将参数设置为信息熵的模式
dtc.fit(x,y) #此时训练就会出错,y是一维而且不是数字类型
"""
#正确的做法:转化好格式,将x,y转化为数据框,然后再转化为数组并指定格式
xf=pda.DataFrame(x) #把数据转化为数据框
yf=pda.DataFrame(y)
x2=xf.as_matrix().astype(int) #指定形式和格式,不让他们有那个type=object
y2=yf.as_matrix().astype(int)
dtc=DTC(criterion="entropy")
dtc.fit(x2,y2)
#可视化决策树
with open("F:/Python/code/code/8/dtc.dot","w") as file: #打开建立这个文件
export_graphviz(dtc,feature_names=["combat","num","promotion","datum"],out_file=file)#(决策树的名称,特征的名称,out_file=指定输出文件)
#利用程序直接预测销量高低,格式要保持与x2一致,构建一个二维数组
x3=npy.array([1,-1,-1,1],[1,1,1,1],[-1,1,-1,1])
result=dtc.predict(x3)
print(result)
决策树往左看是负能量,往右看是正能量
如图promotion【8,3】 说明8个没有促销,3个有
信息熵表示信息增益,越大表示占越大权重,更有用
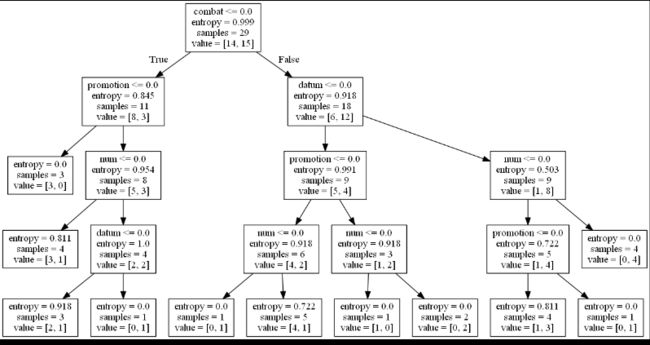
聚类
指定聚类的个数,自动将数据分为那么多类。
聚类三法
划分法(主要利用划分的方法聚类)、层次分析法(从上到下,从下到上两种)、密度分析法(观察数据密度,大于某个阈值,比较好的)、网格法、模型法。
kmeans算法属于划分法。
k个点就表示k类别
kmeans的步骤

#通过程序实现对录取学生的聚类
#通过程序实现淘宝商品的聚类
import numpy as npy
from sklearn.cluster import Birch
from sklearn.cluster import KMeans
import pandas as pda
import matplotlib.pylab as pyl
fname="F:/Python/code/code/8/luqu2.csv"
dataf=pda.read_csv(fname)
x=dataf.iloc[:,1:4].as_matrix()
kms=KMeans(n_clusters=4,n_jobs=2,max_iter=500) #(指定聚类的个数,指定线程数,最大的循环次数)
y=kms.fit_predict(x)
print(y) #y为多少表示为在第几类
#画图 x代表学生序号 y代表学生类别
s=npy.arange(0,len(y))
pyl.plot(s,y,"o")
pyl.show()
#商品的聚类
import pymysql
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="tb")
sql="select price,comment from goods limit 30" #选择读出的字段,从哪个表,限制读出来的数量
dataf=pda.read_sql(sql,conn)
x=dataf.iloc[:,:].as_matrix()
kms=KMeans(n_clusters=3) #(指定聚类的个数,指定线程数,最大的循环次数)
y=kms.fit_predict(x)
print(y) #y为多少表示为在第几类
for i in range(0,len(y)):
if(y[i]==0): #绘制第0类
pyl.plot(dataf.iloc[i:i+1,0].as_matrix(),dataf.iloc[i:i+1,1].as_matrix(),"*r")
elif(y[i]==1):
pyl.plot(dataf.iloc[i:i+1,0].as_matrix(),dataf.iloc[i:i+1,1].as_matrix(),"sy")
elif(y[i]==2):
pyl.plot(dataf.iloc[i:i+1,0].as_matrix(),dataf.iloc[i:i+1,1].as_matrix(),"pk")
pyl.show()
贝叶斯应用
import numpy
from numpy import *
from os import listdir
import numpy as npy
class Bayes:
def __init__(self): #初始化这个类,最开始执行(四个杠,不要写错)
#初始化参数length
self.length=-1 #length=-1 表示未经过训练,如果经过训练肯定是有数据的则大于等于0
self.labelcount=dict()
self.vectorcount=dict()
def fit(self,dataSet:list,labels:list): #数据集,标签集
if(len(dataSet)!=len(labels)):
raise ValueError("输入的测试数组与类别数组长度不一致")
self.length=len(dataSet[0]) #测试数据特征值的长度
labelsnum=len(labels) #得到所有类别的数量
norlabels=set(labels) #得到不重复类别的数量
for item in norlabels:
thislabel=item #得到当前类别,看当前类别一共有多少的数据
self.labelcount[thislabel]=labels.count(thislabel)/labelsnum #求当前类别占总数的比例
for vector,label in zip(dataSet,labels): #相当于是两个一起的循环 例如 [[A,100010].[B.110001]]的循环
if(label not in self.vectorcount): #一开始为空,只要不在都往里面填入,但不要重复的,就可以写成 [A,100010,100011] [B,101000]
self.vectorcount[label]=[]
self.vectorcount[label].append(vector)
print("训练结束")
return self
def btest(self,TestData,labelsSet):
if(self.length==-1):
raise ValueError("还未训练")
#计算当前testdata分别为各个类别的概率
IbDict=dict()
for thisIb in labelsSet:
p=1
alllabel=self.labelcount[thisIb] #先求出这个标签的总占比
allvector=self.vectorcount[thisIb] #拿到这个标签对应的数据[A,100010,100011] ([B,101000]这个就没有了)
vnum=len(allvector) #数据集的个数
allvector=numpy.array(allvector).T
for index in range(0,len(TestData)):
vector=list(allvector[index])
p*=vector.count(TestData[index])/vnum #相当于+= 累乘
IbDict[thisIb]=p*alllabel
thislabel=sorted(IbDict,key=lambda x:IbDict[x],reverse=True)[0]
return thislabel
#加载数据
def datatoarray(fname):
arr=[]
fh=open(fname)
for i in range(0,32):
thisline=fh.readline()
for j in range(0,32):
arr.append(int(thisline[j]))
return arr
#建立一个函数取文件前缀
def seplabel(fname):
filestr=fname.split(".")[0]
label=int(filestr.split("_")[0])
return label
#建立训练数据
def traindata():
labels=[]
#listdir("文件夹名字")可以的到一个文件夹下所有的文件名
trainfile=listdir("F:/Python/code/code/7/testandtraindata/traindata")
num=len(trainfile)
#行的长度为1024(列),每一行存储一个文件
#用一个数组存储所有的训练数据,行:文件总数,列:1024
#zeros((2,5))生成两行五列的0
trainarr=zeros((num,1024)) #相当于一个初始化
for i in range(0,num):
thisfname=trainfile[i]
thislabel=seplabel(thisfname)
labels.append(thislabel)
trainarr[i,:]=datatoarray("F:/Python/code/code/7/testandtraindata/traindata/"+thisfname) #理解为为i行上写上以下的的内容
return trainarr,labels
bys=Bayes()
#训练数据
train_data,labels=traindata()
bys.fit(train_data,labels)
#测试
thisdata=datatoarray("F:/Python/code/code/7/testandtraindata/traindata/8_90.txt")
labelsall=[0,1,2,3,4,5,6,7,8,9]
#识别单个手写体数字
'''
result=bys.btest(thisdata,labelsall)
print(result)
'''
#识别多个手写体数字
testfileall=listdir("F:/Python/code/code/7/testandtraindata/testdata")
num=len(testfileall)
for i in range(0,num):
thisfilename=testfileall[i] #得到当前文件名
thislabel=seplabel(thisfilename)
thisdataarray=datatoarray("F:/Python/code/code/7/testandtraindata/testdata/"+thisfilename)
label=bys.btest(thisdataarray,labelsall)
#print("该数字是:"+str(thislabel)+",识别出来的是"+str(label))
#计算错误率
x=0
if (label!=thislabel):
x+=1
print(x)
print("错误率是:",str(float(x)/float(num))
人工神经网络
在分类用的很多
- BP神经网络:会根据误差做一些计算,如图第一层两个节点(输入层),第二层五个节点(隐藏层),第三层一般只有一个节点(输出层)。 每一个输入层的点在第二层进行计算,权值变动=学习率误差输出
人工神经网络实战
一些问题:
- 1、The nb_epoch argumenthas been renamed epochs everywhere.所以神经网络的训练次数需要用epochs来定义,不再是nb_epoch 。
以前写法:
model.fit(X_train, y_train,validation_data=(X_test, y_test), nb_epoch=69, batch_size=200, verbose=2)
正确写法:
model.fit(X_train, y_train,validation_data=(X_test, y_test), epochs=69, batch_size=200, verbose=2) - import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
image.png
课程销量预测代码
#bp人工神经网络的实现
#1.读取数据
#2.keras.models Sequential (建立模型)/keras.layer.core 下面的Dense Activation(添加激活函数)主要建立输入层和输出层
#3.sequential建立模型
#4.dense建立层
#5.activation激活函数
#6.compile模型编译
#7.fit训练(学习)
#8.验证(测试,分类预测)
#读取数据
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import pandas as pda
fname="/Users/yuanxin/Desktop/lesson.csv"
dataf=pda.read_csv(fname,encoding="gbk")
x=dataf.iloc[:,1:5].as_matrix()
y=dataf.iloc[:,5].as_matrix()
for i in range(0,len(x)):
for j in range(0,len(x[i])):
thisdata=x[i][j]
if(thisdata=="是" or thisdata=="多" or thisdata=="高"):
x[i][j]=int(1)
else:
x[i][j]=0
for i in range(0,len(y)):
thisdata=y[i]
if(thisdata=="高"):
y[i]=1
else:
y[i]=0
#下面四行是一个固定的套路,需要转化好格式,前两步将x,y转化为数据框,然后两步转化为数组并指定格式
xf=pda.DataFrame(x)
yf=pda.DataFrame(y)
x2=xf.as_matrix().astype(int)
y2=yf.as_matrix().astype(int)
#利用人工神经网络模型
from keras.models import Sequential
from keras.layers.core import Dense,Activation
model=Sequential()
model.add(Dense(10,input_dim=4)) #第一个表示输入层数,一般没什么要求;inputdim代表有多少个特征
model.add(Activation("relu"))#用acti建立激活函数,relu这个函数准确率比较高
#上面做完了输入层 现在做输出层
#输出层
model.add(Dense(1,input_dim=1)) #一般输出的话就用一个输出层,特征就一个
model.add(Activation("sigmoid")) #因为结果是二元的,所以我们用二元分类sigmod
#模型的编译
model.compile(loss="binary_crossentropy",optimizer="adam") #loss是损失函数,一般二元的就用这种;optimizer求解方法,常用adam;
#训练
model.fit(x2,y2,epochs=1000,batch_size=100) #epochs 学习的次数,batch_size?
#预测分类
rst=model.predict_classes(x).reshape(len(x))
x=0
for i in range(0,len(x2)):
if(rst[i]!=y[i]): #跟原来的结果做比较
x+=1
print(1-x/len(x2))
import numpy as npy
x3=npy.array([[1,-1,-1,1],[1,1,1,1],[-1,1,-1,1]])
rst=model.predict_classes(x3).reshape(len(x3))
print("其中第一门课的预测结果为:"+str(rst[0]))
手写体识别代码
#使用人工神经网络实现手写体数字识别
#数据的读取与整理
#加载数据
from numpy import *
import operator
from os import listdir
import numpy as npy
import pandas as pda
import numpy
def datatoarray(fname):
arr=[]
fh=open(fname)
for i in range(0,32):
thisline=fh.readline()
for j in range(0,32):
arr.append(int(thisline[j]))
return arr
#建立一个函数取文件名前缀
def seplabel(fname):
filestr=fname.split(".")[0]
label=int(filestr.split("_")[0])
return label
#建立训练数据
def traindata():
labels=[]
trainfile=listdir("/Users/yuanxin/Desktop/traindata/")
num=len(trainfile)
#长度1024(列),每一行存储一个文件
#用一个数组存储所有训练数据,行:文件总数,列:1024
trainarr=zeros((num,1024))
for i in range(0,num):
thisfname=trainfile[i]
thislabel=seplabel(thisfname)
labels.append(thislabel)
trainarr[i,:]=datatoarray("/Users/yuanxin/Desktop/traindata/"+thisfname)
return trainarr,labels
trainarr,labels=traindata()
#固定格式用
xf=pda.DataFrame(trainarr) #先转成数据框
yf=pda.DataFrame(labels)
tx2=xf.as_matrix().astype(int) #转成数组
ty2=yf.as_matrix().astype(int)
#使用人工神经网络模型
from keras.models import Sequential
from keras.layers.core import Dense,Activation
model=Sequential()
#输入层
model.add(Dense(10,input_dim=1024))
model.add(Activation("relu"))
#输出层
model.add(Dense(1,input_dim=1))
model.add(Activation("sigmoid"))
#模型的编译
model.compile(loss="mean_squared_error",optimizer="adam")
#训练
model.fit(tx2,ty2,nb_epoch=10000,batch_size=6)
#预测分类
rst=model.predict_classes(tx2).reshape(len(tx2))
x=0
for i in range(0,len(tx2)):
if(rst[i]!=ty2[i]):
x+=1
print(1-x/len(tx2))
输入层的层数无所谓
输出层可以根据数据量一般也就是10层
Apriori算法
关联分析:分析出关联性比较大的商品。
可以在超市里面把关联性高的商品摆放在一起。
Apriori也是一种关联性分析的算法。
Apriori中:
- 支持度:两件事物同时发生的概率 Support(A=>B)=P(A and B)
- 置信度:若A发生,B发生的概率 Confidence(A=>B)=P(B|A)
Apriori算法的实现:
- 设定阈值:最小支持度,最小置信度
-
计算,置信度和支持度。支持度利用发生的频率去除概率。
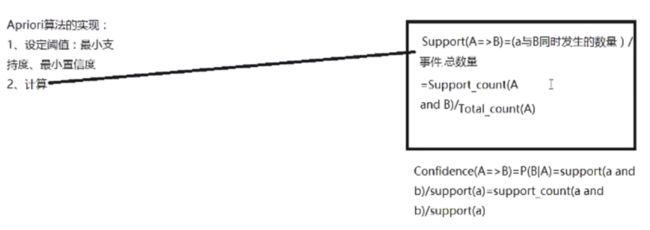 image.png
image.png - 筛选
- 继续计算
关于series的解释
https://www.cnblogs.com/sirkevin/p/5741853.html
课程关联性代码
#计算学员购买课程的关联性
from apriori import *
import pandas as pda
import xlrd
filename="/Users/yuanxin/Desktop/lesson_buy.xls"
dataframe=pda.read_excel(filename,header=None) #header=none表示没有表头
print(dataframe)
dataframe1=dataframe.as_matrix()
print(dataframe1)
#转化一下数据(因为有中文汉字不好分析,所以要转化成矩阵)
change=lambda x:pda.Series(1,index=x[pda.notnull(x)])
#理解为依次去作为索引,先让java为索引去查,有的就置1,然后是php去查,有置为1.根据字母顺序来做的索引
#lamda是指 给一个数据x,他按照转换规则给出数据。规则(有数据为1)
mapok=map(change,dataframe.as_matrix())
data=pda.DataFrame(list(mapok)).fillna(0)
print(data)
#临界支持度、置信度设置
spt=0.2
cfd=0.5
#使用apriori算法计算关联结果
find_rule(data,spt,cfd)
自己电脑python环境的一些问题以及解释
- pycharm也是可以直接下载包的,终端的pip3 install是为idle服务,而不是为pycharm。http://www.360doc.com/content/16/0827/13/35922414_586284807.shtml
- idle增添源文件的方法,找到路径直接放进去。
import sys
>>> print(sys.path)
['/Users/yuanxin/Desktop', '/Users/yuanxin/Documents', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages']
新浪微博的几种爬虫方式
- 接口
- 传统爬虫
charles抓包
http://blog.csdn.net/u010187139/article/details/51986854
https:一般会是unknown 抓不到https的 ,在这里面添加设置
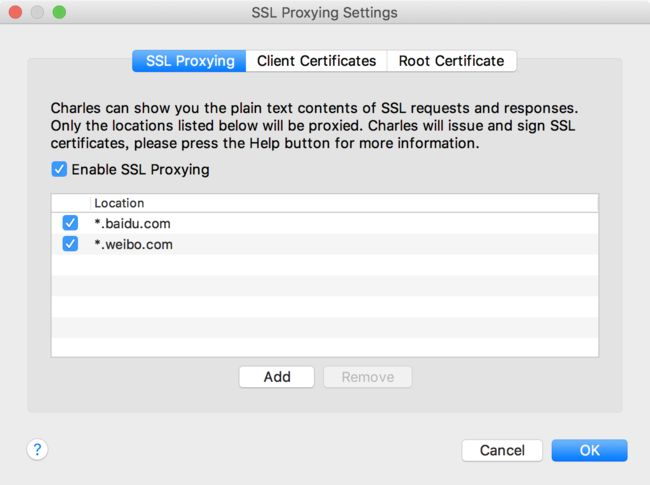
下图是可以只抓取特定的网站以及除了什么网站之外都抓。 格式
" *.baidu.com "
一个新的知识点,布隆比较器。(很轻易检查容器类是否有重复的东西)http://blog.csdn.net/jiaomeng/article/details/1495500
phantomjs
安装selenium,可以利用python操作phantomjs这个