### main函数执行之前做了什么?(iOS)
& dyld 是Apple 的动态链接器;在 xnu 内核为程序启动做好准备后,就会将 PC 控制权交给 dyld 负责剩下的工作 (dyld 是运行在 用户态的, 这里由 内核态 切到了用户态)。
1)dyld 开始将程序二进制文件初始化
2)交由ImageLoader 读取 image,其中包含了我们的类,方法等各种符号(Class、Protocol 、Selector、 IMP)
3)由于runtime 向dyld 绑定了回调,当image加载到内存后,dyld会通知runtime进行处理
4)runtime 接手后调用map_images做解析和处理
5)接下来load_images 中调用call_load_methods方法,遍历所有加载进来的Class,按继承层次依次调用Class的+load和其他Category的+load方法
6)至此 所有的信息都被加载到内存中
7)最后dyld调用真正的main函数
注意:dyld会缓存上一次把信息加载内存的缓存,所以第二次比第一次启动快一点
### KVO实现原理
1.KVO是基于runtime机制实现的
2.当某个类的属性对象第一次被观察时,系统就会在运行期动态地创建该类的一个派生类,在这个派生类中重写基类中任何被观察属性的setter 方法。派生类在被重写的setter方法内实现真正的通知机制
3.如果原类为Person,那么生成的派生类名为NSKVONotifying_Person
4.每个类对象中都有一个isa指针指向当前类,当一个类对象的第一次被观察,那么系统会偷偷将isa指针指向动态生成的派生类,从而在给被监控属性赋值时执行的是派生类的setter方法
5.键值观察通知依赖于NSObject 的两个方法: willChangeValueForKey: 和 didChangevlueForKey:;在一个被观察属性发生改变之前, willChangeValueForKey:一定会被调用,这就 会记录旧的值。而当改变发生后,didChangeValueForKey:会被调用,继而 observeValueForKey:ofObject:change:context: 也会被调用。
### ASCII码表的一般规律
& 16进制的0x30到0x39表示数字0到数字9;
& 16进制的0x61到0x7A表示小写字母a到z;
& 16进制的0x41到0x5A表示大写字母A到Z;
记住: jpg的头部是
### TCP的几种状态
在TCP层,有个FLAGS字段,这个字段有以下几个标识:SYN, FIN, ACK, PSH, RST, URG.
其中,对于我们日常的分析有用的就是前面的五个字段。
它们的含义是:
SYN表示建立连接,
FIN表示关闭连接,
ACK表示响应,
PSH表示有 DATA数据传输,
RST表示连接重置。
### 信号量
dispatch_semaphore的使用场景是处理并发控制.
dispatch_semaphore_create => 创建一个信号量
dispatch_semaphore_signal => 发送一个信号
dispatch_semaphore_wait => 等待信号
& 系统中规定当信号量值为0时,必须等待,知道信号量值不为零才能继续操作。
我们的信号量也可以实现同样的功能。 首先,创建一个信号量。 dispatch_semaphore_t semaphore = dispatch_semaphore_create(0); 创建方法里会传入一个long型的参数,这个东西你可以想象是一个库存。有了库存才可以出货。 dispatch_semaphore_wait,就是每运行一次,会先清一个库存,如果库存为0,那么根据传入的等待时间,决定等待增加库存的时间,如果设置为DISPATCH_TIME_FOREVER,那么意思就是永久等待增加库存,否则就永远不往下面走。
dispatch_semaphore_signal,就是每运行一次,增加一个库存.
// 某个信号进行等待, timeout:等待时间,永远等待为 DISPATCH_TIME_FOREVER
dispatch_semaphore_wait(<#dispatch_semaphore_t dsema#>, <#dispatch_time_t timeout#>)
等待信号,具体操作是首先判断信号量desema是否大于0,如果大于0就减掉1个信号,往下执行;
如果等于0函数就阻塞该线程等待timeout(注意timeout类型为dispatch_time_t)时,其所处线程自动执行其后的语句。
### TCP连接的三次握手
第一次握手:客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包,即SYN+ACK包,此时服务器进入SYN+RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次状态。
### 字典实现原理
一:字典原理
NSDictionary(字典)是使用hash表来实现key和value之间的映射和存储的
方法:- (void)setObject:(id)anObject forKey:(id)aKey;
Objective-C中的字典NSDictionary底层其实是一个哈希表
二:哈希原理
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
哈希概念:哈希表的本质是一个数组,数组中每一个元素称为一个箱子(bin),箱子中存放的是键值对。
三:哈希存储过程
1.根据 key 计算出它的哈希值 h。
2.假设箱子的个数为 n,那么这个键值对应该放在第 (h % n) 个箱子中。
3.如果该箱子中已经有了键值对,就使用开放寻址法或者拉链法解决冲突。
在使用拉链法解决哈希冲突时,每个箱子其实是一个链表,属于同一个箱子的所有键值对都会排列在链表中。
哈希表还有一个重要的属性: 负载因子(load factor),它用来衡量哈希表的空/满程度,一定程度上也可以体现查询的效率,计算公式为:
负载因子 = 总键值对数 / 箱子个数
负载因子越大,意味着哈希表越满,越容易导致冲突,性能也就越低。因此,一般来说,当负载因子大于某个常数(可能是 1,或者 0.75 等)时,哈希表将自动扩容。
哈希表在自动扩容时,一般会创建两倍于原来个数的箱子,因此即使 key 的哈希值不变,对箱子个数取余的结果也会发生改变,因此所有键值对的存放位置都有可能发生改变,这个过程也称为重哈希(rehash)。
哈希表的扩容并不总是能够有效解决负载因子过大的问题。假设所有 key 的哈希值都一样,那么即使扩容以后他们的位置也不会变化。虽然负载因子会降低,但实际存储在每个箱子中的链表长度并不发生改变,因此也就不能提高哈希表的查询性能。
基于以上总结,细心的朋友可能会发现哈希表的两个问题:
1.如果哈希表中本来箱子就比较多,扩容时需要重新哈希并移动数据,性能影响较大。
2.如果哈希函数设计不合理,哈希表在极端情况下会变成线性表,性能极低。
HashMap 的实例有两个参数影响其性能:初始容量和加载因子。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子 (.75) 在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
很多人都有这个疑问,为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高,我以2的4次方举例,来解释一下为什么数组大小为2的幂时hashmap访问的性能最高。本文主要描述了HashMap的结构,和hashmap中hash函数的实现,以及该实现的特性,同时描述了hashmap中resize带来性能消耗的根本原因,以及将普通的域模型对象作为key的基本要求。尤其是hash函数的实现,可以说是整个HashMap的精髓所在,只有真正理解了这个hash函数,才可以说对HashMap有了一定的理解。
① hashmap是用链地址法进行处理,多个key 对应于表中的一个索引位置的时候进行链地址处理,hashmap其实就是一个数组+链表的形式。
② 当有多个key的值相同时,hashmap中只保存具有相同key的一个节点,也就是说相同key的节点会进行覆盖。
③在hashmap中查找一个值,需要两次定位,先找到元素在数组的位置的链表上,然后在链表上查找,在HashMap中的第一次定位是由hash值确定的,第二次定位由key和hash值确定。
④节点在找到所在的链后,插入链中是采用的是头插法,也就是新节点都插在链表的头部。
⑤在hashmap中上图左边绿色的数组中也存放元素,新节点都是放在左边的table中的,这个在上图中为了形象的表现链表形式而没有使用。
### 结构体字节大小问题
原则1:数据成员对齐规则:结构(struct或联合union)的数据成员,第一个数据成员放在offset为0的地方,
后面每个数据成员存储的起始位置要从该成员(自身)大小的整数倍开始(如int在32位机为4字节,则要从4的整数倍地址开始存储)。
原则2:结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。
(struct a里存有struct b,b里有char,int,double等元素,那b应该从8的整数倍开始存储。)
原则3:计算工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。
例1:struct A{
int a;
double b;
float c;
};
struct B{
char e[2];
int f;
double g;
short h;
struct A i;
};
sizeof(A) = 24; int为4,double为8,float为4,总长为8的倍数,补齐,所以整个A为24。
sizeof(B) = 48;
### 函数execve
execve函数调用可以执行一个指定的程序,但一旦执行了execve函数之后,调用execve的进程空间就被指定的程序
占据了.所以execve并不产生新的进程,只是将进程空间替换而已.
char *ss = {"a","123",NULL};//命令行参数
execve("a",ss,NULL);
### 函数wait
父进程调用wait之后会阻塞,直到子进程结束之后才返回,wait函数的参数就是子进程的退出码.
// fork后的父进程和子进程之间执行是随机的,无序的,互相不干扰,因为他们是两个不同的进程.
// 变量的地址为偏移地址,而不是绝对地址.首地址不一样,修改变量不会影响另一个变量.
// 孤儿进程:子进程活着,父进程死了,这个时候对于子进程来讲父进程就变成了init.
// 父进程活着,子进程死了,子进程就成了僵死进程,等父进程收尸。父进程退出的话,僵死的子进程也就没有了。
// 父进程和子进程会共享打开的文件描述符.
### 函数fork
#include
pid_t fork(void);
// fork调用就是执行自己,内存中会出现一模一样的两个进程
// fork执行成功,向父进程返回子进程的pid,子进程内部执行fork返回0<若返回0则说明代码运行在子进程上>
// fork创建的新进程是和父进程一样的副本(除了pid不一样)<变量int m会被克隆到子进程的内存空间,变量是两份>
// 子进程没有继承父进程的超时设置,父进程创建的文件锁.

### 进程和线程
进程是一个正在执行程序的实例.// 一个PID标识一个进程
程序----就是你磁盘上的那个文件而已,它是静态的.
进程----一旦这个程序备操作系统加载到内存,开始执行了,那么他就是进程
// 时间片模型
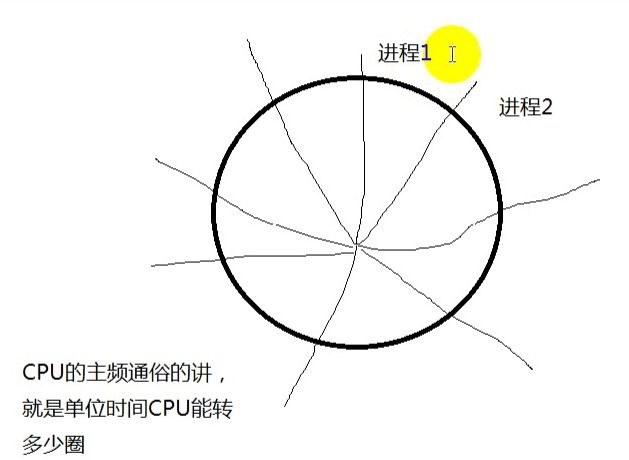
# 倒过来读,就很容易理解声明.
int *pt;//指向int型的指针
const int * pci;//指向const int的指针就是指向整数常量的指针
int* const p;// 指向int型变量的常量指针,指针地址不可修改.
void (*foo)(int num);//指向参数为int,返回值为void的函数的指针,函数指针
void *foo(int num);//返回值为指针的函数
int* arr[5];//指针数组,数组中每一个元素都是指针
int (*p)[10] ;// 数组指针,p指向的是一个带10个int型元素的数组
### 编程高阶
-(int)executeWithCommand:(NSString *)cmd {
NSLog(@"%@",cmd);
NSArray *cmds = [cmd componentsSeparatedByString:@" "];
int argc = (int)cmds.count;
char** argv = (char**)malloc(sizeof(char*)*argc);
for(int i = 0;i < argc; i++) {
argv[i]=(char*)malloc(sizeof(char)*1024);
strcpy(argv[i],[[cmds objectAtIndex:i] UTF8String]);
}
int ret = ycmagickmain(argc, argv);
for(int i=0;i < argc;i++){
free(argv[i]);
free(argv);
return ret;
}
### 单链表 & 二叉树
typedef struct ListElmt_ {
void *data;
struct ListElmt_ *next;
} ListElmt;
typedef struct BiTreeNode_ {
void *data;
struct BiTreeNode_ *left;
struct BiTreeNode_ *right;
} BiTreeNode;
### memset函数
void *memset(void *s, int ch, size_t n);
函数解释:将s中当前位置后面的n个字节 (typedef unsigned int size_t )用 ch 替换并返回 s 。
memset:作用是在一段内存块中填充某个给定的值,它是对较大的结构体或数组进行清零操作的一种最快方法
### memcpy函数
void *memcpy(void *dest, const void *src, size_t n);
从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中.
函数返回指向dest的指针.
### sprintf函数
功能 把格式化的数据写入某个字符串缓冲区。
原型 int sprintf( char *buffer, const char *format, [ argument] … );
参数列表
buffer:char型指针,指向将要写入的字符串的缓冲区。
format:格式化字符串。
[argument]...:可选参数,可以是任何类型的数据。
返回写入buffer 的字符数,出错则返回-1. 如果 buffer 或 format 是空指针,且不出错而继续,函数将返回-1,并且 errno 会被设置为 EINVAL。
### 文件操作相关函数
函数原型:FILE * fopen(const char * path,const char * mode);
返回值:文件顺利打开后,指向该流的文件指针就会被返回。如果文件打开失败则返回NULL,并把错误代码存在errno中。
一般而言,打开文件后会做一些文件读取或写入的动作,若打开文件失败,接下来的读写动作也无法顺利进行,所以一般在fopen()后作错误判断及处理。
参数说明:
参数path字符串包含欲打开的文件路径及文件名,参数mode字符串则代表着流形态。
mode有下列几种形态字符串:
“r” 以只读方式打开文件,该文件必须存在。
“r+” 以可读写方式打开文件,该文件必须存在。
”rb+“ 读写打开一个二进制文件,允许读写数据,文件必须存在。
“w” 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
“w+” 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
“a” 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。(EOF符保留)
”a+“ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。 (原来的EOF符不保留)
函数原型:int fclose( FILE *fp );
返回值:如果流成功关闭,fclose 返回 0,否则返回EOF(-1)。(如果流为NULL,而且程序可以继续执行,fclose设定error number给EINVAL,并返回EOF。)
函数原型 size_t fread ( void *buffer, size_t size, size_t count, FILE *stream) ;
buffer 用于接收数据的内存地址
size 要读的每个数据项的字节数,单位是字节
count 要读count个数据项,每个数据项size个字节.
stream 输入流
返回值
返回真实写入的项数,若大于count则意味着产生了错误。另外,产生错误后,文件位置指示器是无法确定的。若其他stream或buffer为空指针,或在unicode模式中写入的字节数为奇数,此函数设置errno为EINVAL以及返回0.
size_t fwrite(const void* buffer, size_t size, size_t count, FILE* stream);
注意:这个函数以二进制形式对文件进行操作,不局限于文本文件
返回值:返回实际写入的数据块数目
(1)buffer:是一个指针,对fwrite来说,是要获取数据的地址;
(2)size:要写入内容的单字节数;
(3)count:要进行写入size字节的数据项的个数;
(4)stream:目标文件指针;
(5)返回实际写入的数据项个数count。
int fseek(FILE *stream, long offset, int fromwhere);函数设置文件指针stream的位置。
如果执行成功,stream将指向以fromwhere为基准,偏移offset(指针偏移量)个字节的位置,函数返回0。如果执行失败(比如offset超过文件自身大小),则不改变stream指向的位置,函数返回一个非0值。
/* 读一个文件,open,close是系统函数,fopen,fclose是库函数,建议用库函数 */
int fd = open("a.txt",O_RDONLY);
char buf[100] = {0};
while(read(fd,buf,sizeof(buf)-1) > 0)
{
printf("%s",buf);
memset(buf,0,sizeof(buf));
}
// 写文件
write(fd,buf,strlen(buf));
close(fd);//记得关闭文件
### 数据库编程
1:)连接到数据库
MYSQL *mysql_real_connect(MYSQL *pmvsql,const char* hostname,
const char* username,const char* passwd,const char* dbname,0,0,0);
//函数成功返回指向MySql连接的指针,失败返回NULL
2:)执行SQL语句的函数
int mysql_query(MYSQL* pmysql,const char* sql);
//成功返回0;
注: 编写mysql程序,连接到server之后,应该执行sql语句:SET NAMES utf8;
3:)获取查询结果
MYSQL_RES* mysql_store_result(MYSQL* pmysql);
// 成功返回一个查询结果指针,查询无结果或者错误返回NULL
// 需调用mysql_free_result(MYSQL_RES *res) 来释放相关资源.
4:)查看查询结果
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result);
// MYSQL_ROW row相当于一个一行数据.
// row[0]表示第一列;
### mysql进阶
1:)查询语句
select [ALL|DISTINCT]结果项列表 from子句 where子句 group子句 having子句 order子句 limit子句
// 上面子句的相对顺序不能打乱,实际上,在其内部计算的过程中,也是按此先后顺序进行的.
// [all | distinct] 显示全部重复项(默认) 或 消除重复项
// from 数据来源,表,也可以是表的结合关系
// where 条件
// group by 分组
// having 对分组设定过滤条件
// order by 对前面取得的数据来指定按某个字段的大小进行排序. ASC(正序,默认) DESC(倒序)
// 如果指定多个字段排序,则其含义是,在前一个字段排序中相同的那些数据里,再按后一字段的大小进行排序.
// limit [起始行号 start],[要取出的行数 num] --用于分页
// 显示取得第n页数据: select *from t_name limit ($n-1)*$pageSize,$pageSize
2:)数据库设计3范式
第一范式(1NF):原子性,数据不可再分
一个表中的数据(字段值)不可再分
第二范式(2NF):唯一性,消除部分依赖
一个表中的每一行必须唯一可区分,且非主键字段值完全依赖主键字段值
第三范式(3NF):独立性,消除传递依赖
使一个表中的任何一个非主键,完全独立地依赖于主键,而不能又依赖于另外的非主键
3:)连接查询
基本形式:
from 表1 [连接方式] join 表2 [on 连接条件];连接的结果可以当作一个“表”来使用。
交叉连接:
from 表1 [cross] join 表2 ;连接的结果其实是两个表中的所有数据“两两对接”。这种连接也叫做“笛卡尔积”
内连接:
from 表1 [inner] join 表2 on 连接条件。inner关键字可以省略,也可以用cross代替。on连接条件无非是设定在连接后所得到的数据表中,设定一个条件以取得所需要的数据。通常连接都是指两个有关联的表,则连接条件就是这两个表的关联字段的一个关系(通常都是相等关系)
左[外]连接:
from 表1 left [outer] join 表2 on 连接条件;将左边的表的数据跟右边的表的数据以给定的条件连接,并将左边的表中无法满足条件的数据(行)也一并取得——即左边的表的数据肯定都取出来了
右[外]连接:
from 表1 right [outer] join 表2 on 连接条件;将左边的表的数据跟右边的表的数据以给定的条件连接,并将右边的表中无法满足条件的数据也一并取得——即右边的表的数据肯定都取出来了
4:)联合查询
含义:将两个“字段一致”的查询语句所查询到的结果以“纵向堆叠”的方式合并到一起,成为一个新的结果集。
形式:
select语句1 union [ALL | DISTINCT] select语句2:
说明:
两个select语句的查询结果的字段需要保持一致:个数必须相同,对应顺序上的字段类型也应该相同
ALL | DISTINCT表示两表的数据联合后是否需要消除相同行(数据)。ALL表示不消除(全部取得),DISTINCT表示要消除。默认不写就会消除
应该将这个联合查询的结果理解为最终也是一个“表格数据”,且默认使用第一个select语句中的字段名
如果第一个select语句中的列有别名,则order by子句中就必须使用该别名
### TCP通信
1:)套接字使用的步骤
初始化 -> 连接 -> 发送(接收)数据 -> 关闭套接字.
2:)函数socket()
int socket(int domain,int type,int protocol);
//protocol一般取0,函数返回值是成功返回套接字描述符,
//失败返回-1,domain一般取AF_INET,
//type: SOCK_STREAM使用TCP,SOCK_DGRAM使用UDP不可靠连接.
外部依赖: #include
#include
3:)函数bind()
int bind(int sockfd,const struct sockaddr *my_addr,socklen_t addrlen);
// bind将进程与一个套接字联系起来,通常用于服务器进程为接入客户连接建立一个套接口;
// sockfd是socket函数调用返回的套接口值,
// my_addr是结构sockaddr的地址
// addrlen设置了my_addr能容纳的最大字节数.
4:)函数listen()
int listen(int sockfd,int backlog)
// 服务端调用该函数来监听指定端口的客户端连接
// sockfd还是socket标示符
// backlog 最大并发数
5:)函数accept()
int accept(int sockfd,struct sockaddr *addr,socklen_t *addrlen);
// 当有客户端连接到服务端,它们会排入队列,直到服务端准备好处理他们为止;
// accept会返回一个新的套接口,同时原来的套接口继续listen.
// accept会阻塞,直到有客户端连接.
6:)函数connect()
int connect(int sockfd,const struct sockaddr *serv_addr,socklen_t addrlen);
// 客户端调用connect与服务端进行连接.
// $0表示的是客户端的socket.
7:)函数send() --发送数据
ssize_t send(int s,const void* buf,size_t len,int flags);
// s是已经建立连接的套接口
// buf是要发送数据内存buffer
// len指明buffer的大小
// flags取0.
// 成功,返回发送的字节数,
函数recv与send类似:
ssize_t recv(int s,void *buf,size_t len,int flags);
最后,记得要调用close(int sockfd)来关闭socket;
### epoll函数使用举例
struct epoll_event ev,events[100];//数组用于回传要处理的事件
int epfd = epoll_create(100);//可以放100个socket
ev.data.fd = listen_st;//设置与要处理的事件相关的文件描述符
ev.events = EPOLLIN | EPOLLERR | EPOLLHUP(挂起);//设置要处理的事件类型
epol_ctl(epfd,EPOLL_CTL_ADD,listen_st,&ev);//注册epoll事件
int nfds = epoll_wait(epfd,events,100,-1);//等待epoll事件的发生
### 共享库so
// so文件在linux为共享库
// 编译时gcc需要加-fPIC,使gcc产生与位置无关的代码[具体函数入口位置由主调进程处理]
// 链接时gcc使用-shared选项,指示生成一个.so文件
// 库文件格式为lib*.so
// 提供一个与该共享库配套的头文件[声明so文件中的函数]
// .bash_profile 中添加 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:.
// 使得程序链接时会在当前目录下寻找so文件
// gcc -L. -ltest -o hello hello.o [-L.表示在当前目录寻找so文件,-ltest表示链接libtest.so]
// 在.h文件中增加__cplusplus的预编译指令,就可被C++调用这个库了
### so文件配套的头文件举例
#ifndef TEST_H_
#define TEST_H_
#ifdef __cpluscplus
extern "C"
{
#endif
int max(int a,int b);
int add(int a,int b);
#ifdef __cplusplus
}
#endif
#endif
### 有名管道FIFO
$ mkfifo fifo1 # 创建有名管道fifo1
// 有名管道具有持久性
// 有名管道可在任意两个进程间通信
### 信号
1:)信号通常用来向一个进程通知事件
信号是不可提前预知的,所以信号是异步的.
比如硬件异常,非法内存引用,在键盘上按一个键等都会发出信号.
ctrl+c --> 发出SIGINT信号
2:)通过fork函数产生的进程与父进程处理信号一样.
捕捉信号:signal函数
3:)守护进程的创建
- 父进程中执行fork后,执行exit退出
- 在子进程中调用setsid.
- 让根目录/ 成为子进程的工作目录[会调用chdir函数]
- 把子进程的umask设为0 [ umask(0) ]
- 关闭任何不需要的文件描述符
//与守护进程通信,则需要向守护进程发信号
### Shell脚本
1:)shell脚本举例
#!/bin/sh
WHOAMI='whoami'
PID= `ps -u $WHOAMI | grep signd | awd '{print $1}'`
if (test "$PID" = "") then
./signd
fi
2:)
### man命令的使用
// atoi函数需要引入什么头文件,不用去死记, $man atoi 查看一下就知道了
// 比如gcc命令的使用 ,$man gcc
### 棋盘坐标的计算
* 棋盘坐标的计算首先要搞清楚棋盘坐标原点在屏幕坐标系中的坐标是多少,
* 再一个需要弄清楚棋盘上落点之间的间隔是多少;最终计算出每个棋子的屏幕坐标;
* 棋子的坐标 = 棋子在棋盘的单位坐标*棋子的直径+棋盘坐标系相对于屏幕坐标系的偏移量.
* 因为在表结构中红棋的id始终在前边,所以不管红棋在下边还是黑棋在下边,都是先摆红棋,再摆黑棋.
### 判断是否点击了某个象棋
void Scene::ccTouchEnded(CCTouch *pTouch,CCEvent *e)
{
CCPoint ptClickUp = pTouch->getLocation();//获取手指离开屏幕的瞬时坐标
if(_red->boundingBox().containsPoint(ptClickUp)){
//表示精灵被点击
this->_redSprClicked = true;
}
}
### 象棋的碰撞检测
scheduleUpdate();//启动定时器,会每一帧调用update方法
void udpate(float delta){
//精灵默认的锚点是在它的中心
//一般情况下,是判断两个精灵的矩形是否有相交的部分,因为这里有旋转,所以不能用这个.
//象棋是圆形,只需判断两个圆的圆心距是否小于r1+r2
float x1 = m_sp1->getPositionX();
float x2 = m_sp2->getPositionY();
if(abs(x1-x2)getContentSize().width*0.5
//两个精灵发生碰撞
//开始游戏,进入主场景
CCDirector::sharedDirector->replaceScene(SceneGame::scene());
}
}
=====================================================================================
/* 函数 */
### memset函数
原型:extern void *memset(void *buffer, char c, int count);
用法:#include
功能:把buffer所指内存区域的前count个字节设置成字符c。
说明:返回指向buffer的指针
### strcpy函数实现
char *strcpy(char *strDest, const char *strSrc)
{
assert((strDest!=NULL) && (strSrc !=NULL)); // 2分
char *address = strDest; // 2分
while( (*strDest++ = * strSrc++) != ‘\0’ ) // 2分
NULL ;
return address ; // 2分
}
### inet_addr函数
/* Convert Internet host address from numbers-and-dots notation in CP
into binary data in network byte order. */
extern in_addr_t inet_addr (const char *__cp) __THROW;
eg: inet_addr("192.168.1.23");
### setsockopt函数
int setsockopt(int s,int level,int optname,const void* optval,socklen_t optlen);
// 设置套接口,SO_REUSEADDR指示系统地址可重用.
int on = 1;
setsockopt(st,SOL_SOCKET,SO_REUSEADDR,&on,sizeof(on));
### read函数
read(STDIN_FILENO,s,sizeof(s));//从键盘读取字符串,并缓存到s中
write(STDOUT_FILENO,buf,strlen(buf));//向控制台写数据
### fcntl函数
int fcntl(int fd,int cmd,.../* arg */);
//该函数可以将文件或socket描述符设置为阻塞或非阻塞状态
//fd是要设置的文件描述符或socket
//cmd F_GETFL为得到目前状态,F_SETFL为设置状态
//宏定义0_NOBLOCK表示非阻塞,0代表阻塞
//返回值为描述符当前状态
### epoll_*函数
epoll相当于一个游泳池.
epoll_create() --用来创建一个epoll文件描述符;需要调用close()来关闭epoll句柄.
epoll_ctl() --用来修改需要侦听的文件描述符或事件;
epoll_wait() --接收发生在被侦听的描述符上的,用户感兴趣的IO事件;
int epoll_ctl(int epfd,int op,int fd,struct epoll_event *event);
// epfd是epoll_create的返回值
// op EPOLL_CTL_ADD:注册新的fd到epfd中
// fd是socket描述符
// event 通知内核需要监听什么事件
int epoll_wait(int epfd,struct epoll_event *events,int maxevents,int timeout);
// epfd是epoll_create的返回值
// epoll_events里面将存储所有的读写事件
// maxevents是当前需要监听的所有socket句柄数
// timeout -1表示一直等下去
### fork函数
#include
pid_t fork(void);//进程克隆
fork执行成功,向父进程返回子进程的pid,并向子进程返回0,函数返回0表示的是子进程;
fork创建的新进程是和父进程一样的副本.(除了PID和PPID);
提示: 获取pid的方法 --> getpid(),getppid()
### execve函数
int execve(const char* path,const char *arg,char * const envp[]);
fork创建了一个新的进程,产生一个新的PID;
execve用被执行的程序完全替换了调用进程的映像;
execve启动一个新程序,替换原有进程,所以被执行的进程pid不变;
path -- 要执行的文件完整路径
arg -- 传递给程序完整参数列表
envp -- 指向执行execed程序的环境指针,可以设为NULL
### getcwd函数
char* getcwd(char* buf,size_t size);
该函数把当前工作目录的绝对路径名复制到buf中,size指示buf的大小.
### opendir函数
DIR *opendir(const char* pathname);//打开pathname指向的目录文件
struct dirent *readdir(DIR *dir);//读出目录文件内容
int closedir(DIR *dir);
### getlogin函数
getlogin()函数返回程序的用户名;
struct passwd* getpwnam(const char* name);//返回/etc/passwd文件中与该登录名相应的一行完整信息
### system函数
int system(const char* cmd);
//该函数传递给/bin/.sh/cmd中可以包含选项和参数
//如果没有找到/bin/sh 函数返回127,
### wait函数
pid_t wait(int *status);//阻塞调用,直到子进程退出,wait才返回
pid_t waitpid(pid_t pid,int *status,int options);
// wait和waitpid函数收集子进程的退出状态
// status保存子进程的退出状态
// pid为等待进程的pid
// 父进程没有调用wait函数,子进程就退出了,这个时候子进程就成了僵死进程
### exit函数
int exit(int status);
// 导致进程正常终止,并且返回给父进程的状态
// 无论进程为何终止,最后都执行相同的代码,关闭文件,释放内存资源
// void abort()函数会导致程序异常终止
### kill函数
int kill(pid_t pid,int sig);
// kill函数杀死一个进程,由pid指定
// sig表示信号
### pipe函数
int pipe(int filedes[2]);
// 如果成功建立了管道,则会打开两个文件描述符,一个用于读数据,一个用于写数据
// 关闭管道用close函数
### mkfifo函数
int mkfifo(const char* pathname,mode_t mode);
// 创建fifo,函数执行成功返回0
// pathname代表fifo的名称
// mode表示读写权限,比如777
// unlink(const char*) 函数删除fifo
### shmget函数
int shmget(key_t key,size_t size,int shm_flg);
// 创建共享内存区
// 参数key既可以是IPC_PRIVATE,也可以是ftok函数返回的一个关键字
// size指定段的大小,shm_flg表示权限0xxx
// 函数成功则返回段标示符
// 两个进程要共享一块内存,实际上是一块内存分别映射到两个进程,由操作系统对这块内存进行同步
// $ipcs -m #查看共享内存
### shmat函数
void* shmat(int shmid,const void* shmaddr,int shmflg);
// 附加共享内存区
// shmid为要附加的共享内存区标示符
// shmaddr一般置为0,由系统分配地址
// shmflg可以是SHM_RDONLY只读
// 函数成功则返回被附加了段的地址
// 函数shmdt(const void* shmaddr)是将附加在shmaddr的段从调用进程的地址空间分离出去
### signal函数
signal(int signo,void (*func))
// signo 信号名
// func 回调函数的名称
int sigaction(int signo,const struct sigaction *act,struct sigaction *oact)
该函数是signal的升级版,会检查或修改与指定信号相关联的处理动作
### raise函数
int raise(int signo);
// 发送信号,raise函数一般用于进程向自身发送信号.
unsigned int alarm(unsigned int seconds);
// 设置定时器,当时间到了则发出SIGALARM信号
### sleep函数
unsigned int sleep(unsigned int seconds);
// seconds指定睡眠时间
// 到时间后函数返回.
### openlog函数
void openlog(const char* ident,int option,int facility);//打开日志
void syslog(int priority,const char* format,...);//写入日志
void closelog();//关闭日志
### pthread_create函数
int pthread_create(pthread_t *thread,const pthread_attr_t *attr,
void* (*start_routine)(void*),void *arg)
// 线程创建函数,[在进程中只有一个控制线程,主线程return,整个进程就终止]
// thread是新线程的ID,
// attr_t 线程属性
// start_routine回调函数
// arg是线程启动的附加参数
// 函数成功则返回0
// gcc链接时要加-lpthread
注: 多个线程创建后线程的运行顺序具有随机性;
### pthread_exit函数
void pthread_exit(void* arg);
// 单个线程退出函数
// 任一线程调用exit函数,整个进程就会终止
// arg会被其他线程调用,比如pthread_join捕捉
// 线程中不要用信号来处理逻辑,这样会使得程序变得很复杂
### pthread_join函数
int pthread_join(pthread_t th,void** thr_return);
// 该函数用于挂起当前线程,直至th指定的线程终止才返回
// 如果另一个线程返回值不为空则保存在thr_return中
### pthread_detach函数
int pthread_detach(pthread_t th);
// 使线程处于被分离状态
// 对于被分离状态的线程,调用pthread_join无效
// 如果不等待一个线程,同时对该线程的返回值不感兴趣,可以设置为该线程为被分离状态
// 自己不能使自己成为分离状态,只能由其他线程调用pthread_detach
### pthread_cancel函数
// pthread_cancel函数允许一个线程取消th指定的另一个线程
// 函数成功则返回0
// pthread_equal函数判断两个线程是否是同一个线程
### pthread_attr_init函数
int pthread_attr_init(pthread_attr_t *attr);
// pthread_attr_init函数初始化attr结构[线程属性]
// pthread_setdetachstate(&attr,PTHREAD_CREATE_DETACHED);#线程创建时则为被分离状态
// pthread_attr_destroy函数释放attr内存空间
=========================================================================