在Tornado中支持两种路由系统, 正则路由系统以及二级域名路由系统.
# 默认路由系统, 根据url的不容调用不同的类
application = tornado.web.Application([
(r"/index/(?P\d*)", home.IndexHandle),
], **settings)
#二级路由匹配
application.add_handlers("test.ming.com",[
(r"/index/(?P\d*)", home.IndexHandle)
])
-
(r"/index/(?P这里我们访问时候需要以类似\d*)", home.IndexHandle) http://127.0.0.1/index/2的方式访问, 在get或者post接受处理请求的函数应有page参数来接受访问地址最后的整数(我们稍后将根据这个做一个分页的demo) - 当我们加入二级域名时候, 默认访问网站执行第一个默认路由系统, 仅当我们访问设置的二级域名才会调用对应的处理器(当前代码指的是
test.ming.com的域名)
接下来我们使用基于正则的路由系统来实现网页分页功能.
项目目录
**all.py文件如下: **
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#利用全局变量模拟数据库所有内容
USER_LIST= [
{'username': 'test', 'email': '[email protected]'}
]
#利用循环生成多条数据来模拟大量数据依次便于实现分页效果
for i in range(300):
tmp = {'username': "test - " + str(i), 'email': str(i) + "@vip.com"}
USER_LIST.append(tmp)
**pager.py文件如下: **
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 单独用于实现分页功能的类
class Page:
# current_page表示当前页数, all_item表示总的数据条目
# 初始化时候将当前页数current_page与总页数all_page加入到对象中
def __init__(self, current_page, all_item):
# all_page表示总页数, 每页显示5条数据, more表示余数, 如果大于0则表示应多加一页才能显示完所有的数据
all_page, more = divmod(all_item, 5)
if more > 0:
all_page += 1
self.all_page = all_page
# 捕捉异常, 防止传入非法字符冒充页数, 一旦发生异常则直接将当前页current_page设置为1, 表示默认显示第一页
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
# 如果前传入的页数小于1, 则直接默认为第一页
if current_page < 1:
current_page = 1
self.current_page = current_page
# 根据当前页在每个页面显示11个页码, 此处是开始页码
@property
def start_page(self):
return (self.current_page - 1) * 5
# 结束页码
@property
def end_page(self):
return self.current_page * 5
# 显示的页码对应的html字符串, base_url表示可定制的url跳转路径
def page_str(self, base_url):
# 定义list_page列表用来暂时存储所有的页码字符串
list_page = []
# 如果总页数小于11页, 则直接显示所有页数
if self.all_page < 11:
s = 0
e = self.all_page
# 总页数大于11页时候
else:
# 当前页数小于6则直接显示1到11页
if self.current_page <= 6:
s = 1
e = 11
# 当前页数大于6页时候
else:
# 当前页加上5也之后就大于总页数则直接显示倒数11页
if self.current_page + 5 > self.all_page:
s = self.all_page - 10
e = self.all_page
# 当前页数大于6页并且加上5页并不超过总页数时候, 显示当前页前后5页以及当前页
else:
s = self.current_page - 5
e = self.current_page + 5
# 首页设置
first_page = '首页' % (base_url)
list_page.append(first_page)
# 上一页设置
# 当前页小于等于第一页时候, 点击上一页不做任何操作(这里理论上是不会有小于的情况)
if self.current_page <= 1:
pre_page = '上一页'
# 当前页大于第一页, 点击上一页则直接跳转到上一页
else:
pre_page = '上一页' % (base_url, self.current_page - 1)
list_page.append(pre_page)
# 根据上边条件过滤后的页码起始位置s以及页码终止位置e来生成对应的11条页码对应的html字符串
for p in range(s, e + 1):
if p == self.current_page:
tmp = '%s' % (p, p)
else:
tmp = '%s' % (base_url, p, p)
list_page.append(tmp)
# 下一页设置
# 下一页要大于或者等于最大页数时候, 不做任何操作
if self.current_page >= self.all_page:
next_page = '下一页'
else:
next_page = '下一页' % (base_url, self.current_page + 1)
list_page.append(next_page)
# 尾页设置
last_page = '尾页' % (base_url, self.all_page)
list_page.append(last_page)
# 页面跳转
jump_page = """GO""" % base_url
# 页面跳转的js代码, 本质就是location.href的使用
jspt = """"""
list_page.append(jump_page)
list_page.append(jspt)
return "".join(list_page)
**home.py文件如下: **
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import tornado.web
from commons.all import USER_LIST
from commons.pager import Page
class IndexHandle(tornado.web.RequestHandler):
def get(self, c_page):
# c_page表示url传递过来的当前页数, len(USER_LIST)表示总共有多少条数据
pg = Page(c_page, len(USER_LIST))
#开始页数
start = pg.start_page
#尾页
end = pg.end_page
#当前显示的数据片段
current_list = USER_LIST[start:end]
#传入index并返回对应的下面分页部分的html代码
str_page = pg.page_str('index')
#将当前显示的数据片段, 当前页数以及分页的html代码返回给浏览器
self.render('index.html', list_info=current_list, current_page=pg.current_page, str_page=str_page)
def post(self, c_page):
#获取传入的username的值
username = self.get_argument('username', None)
#获取传入的email的值
email = self.get_argument("email", None)
#生成临时的字典对象, 表示一个完整的数据片段
tmp = {'username': username, 'email': email}
#将该数据片段加入的全局变量USER_LIST, 这里用全局变量模拟数据库获取的数据
USER_LIST.append(tmp)
self.redirect('/index/' + c_page)
**index.html文件如下: **
Title
提交数据
显示数据
用户名
邮箱
{%for tmp in list_info%}
{{tmp['username']}}
{{tmp['email']}}
{%end%}
{%raw str_page%}
**start.py文件如下: **
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import tornado.web,tornado.ioloop
from controllers import home
if __name__ == '__main__':
settings = {
# 模板路径配置
'template_path': 'views',
}
application = tornado.web.Application([
(r"/index/(?P\d*)", home.IndexHandle),
], **settings)
application.listen(80)
tornado.ioloop.IOLoop.instance().start()

运行结果-1

运行结果-2
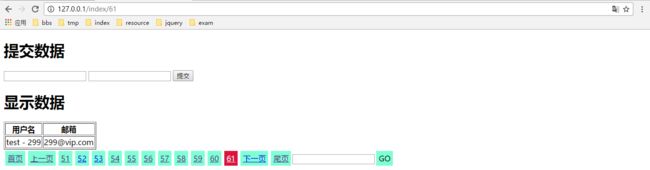
运行结果-3
- 这种基于正则的分页实现实际上是在根据url访问显示的当前页数, 在后台生成当前页以及当前页前后5页的
html字符串, 然后将这些字符串返回给浏览器直接渲染显示