介绍
牛人就是牛啊,不服不行。君不见Face++(旷视科技)在将Sun,Jian招入门下后,Face++在视觉科研领域的狂飙突进吗?今年的MS COCO大赛中他们更是一举拿下了六项比赛中的四项冠军。
ShuffleNet就是出自Face++的作品,华人世界的绝对骄傲!它同这一系列介绍的其它几个模型类似,同样致力于在保证模型精确度的基本上减少其计算量以使得训练得到的CNN模型可以部署在计算能力并不强大的移动设备上面。科技很多时候只有与市场需求接合起来才能发挥出迷人的魅力。
它直接对标的是Google同年提出的亦在移动设备上得到较好应用的MobileNet。MobileNet我们之前介绍过,主要通过使用Depthwise CNN与Pointwise CNN来减少传统CNN所需的密集计算。ShuffleNet对一般用作bottleneck模块的1x1 CNN计算作了更多思考,从而提出了使用Group-wise CNN与Shuffle module结合的思想来优化1x1 conv的bottleneck模块,有效地节省理论所需的计算,从而在一定算力的限定内,实现尽可能高的分类准确率。
ShuffleNet
结合了Channel Shuffle的Group convolutions
现在的精简CNN网络设计中使用Group convolutions已经成为一种趋势,它可有效地减少传统CNN所需的密集计算的运算量。但同时由于Groups之间彼此并不share feature map特征,这样就会导致每个filter只对限定的一部分输入特征可见,最终使得输出特征集合的表达能力大大降低(省计算与加强表达能力是个鱼与熊掌的选择问题啊)。
为了有效地对冲Groups convolution使用导致的Groups间特征互不相通的负面影响,作者提出了在Group convolution计算后对输出的output feature maps进行shuffle处理,以使得接下来的Group convolution filters可在每个group所输出的部分channels构成的集合上进行计算。
下图有力地表达了它的这一作用。

ShuffleNet Unit
当下CNN设计中都会先构成一种新颖的module,进而在对此module进行不断叠加,构成最终的新颖CNN网络。当然在构建网络时,不断阶段(而对不同大小的feature maps)可使用module的若干变形。像Inception module之于Googlenet系列网络,Depthwise Conv + Pointwise Conv组成的module之于MobileNet网络,或者Gate + residual block的组合module之于SkipNet等等无不是如此。
ShuffleNet自己也有其基本的Unit,在论文中被简单称为是ShuffleNet Unit。
我们前面已说过,ShuffleNet主要想对1x1 conv所构成的bottleneck模块进行优化,因此它的整体unit设计主要是从之前的Xception等网络中演变而来。
下图中我们能看出Groupwise convolution + shuffle的这种组合对传统1x1 conv bottleneck模块的代替使用。
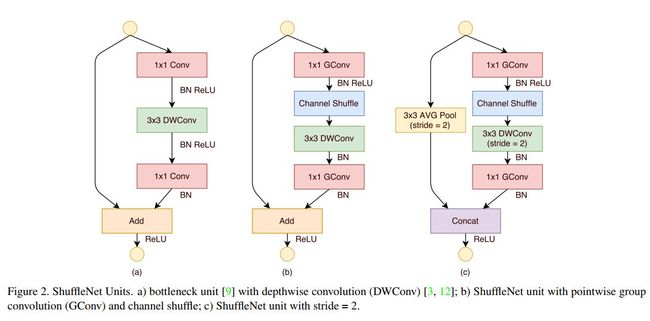
上图中,图a为传统的单单使用depthwise conv将3x3 conv优化过了的residual module(使用了bottleneck),在此结构中,1x1 conv将成为主要的计算消耗来源(在ResNxt中约占其94%的计算);图b中则为本文中提出的结合了groupd wise conv + shuffle而进行的1x1 conv bottleneck。对residual module中进行elementwise前所用的1x1 conv ( expand module,主要为了使得输出特征数目与原初输入特征集合数目相同)亦用了group wise conv的优化(直观上此处亦可以使用shuffle操作,但因为马上要进行接下来输出,故作用并不明显,作者实验也证明了这一点,故真正构建网络时并不在这个1x1 group wise conv之后再接shuffle操作。)。
ShuffleNet网络结构
下表中为作者尝试过的几种ShuffleNet结构与配置。可见作者试着探索了几种不同的group wise conv中group的数目。
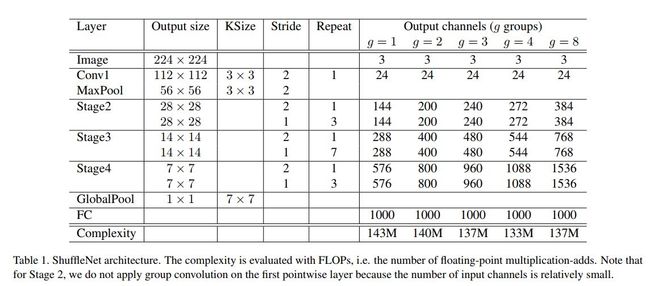
它的构成整体上还是比较有规律的。可以看出上节介绍过的shuffleNet unit是构建它的基石。表中作者在变动groups数目时,保证了网络整体所用的计算量基本相似,这样当groups更多时,显然我们就能使用更多个channels的feature maps。结果表明,groups数目的模块可带来网络表达能力(以及最终分类准确率)的稳定提高。
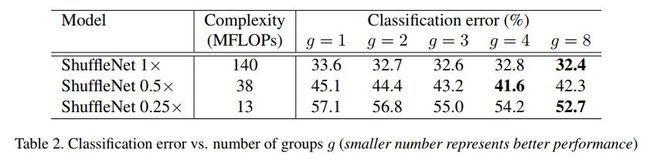
另外还可以将channels数目视为网络构建的另一个可调参数。在下表中我们可以看出,随channels数目减小,网络的分类准确率开始下降(这个自然了,同样的结构下,显然愈小的CNN表达能力愈弱),但groups数目的增加却能在保证计算力相似的情况下有效提升ShuffleNet的分类能力。
实验结果
下表中为ShuffleNet与其它现代CNN网络在使用相似计算力的情况下在分类准确率上的比较。
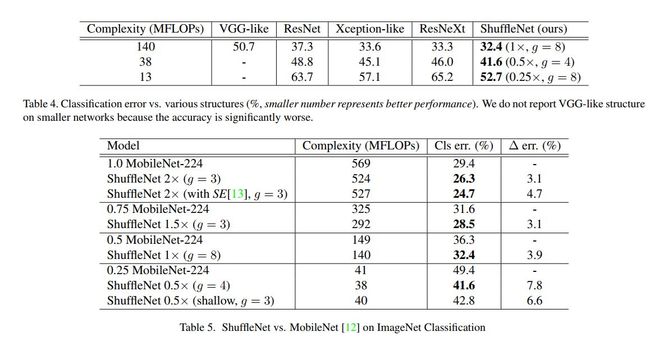
下表中反映了与其它CNN相比,ShuffleNet在达到相似分类准确率时在计算速度上所具有的优势。

代码分析
下面为Shuffle操作的一种实现。可见它大多是一种memory copy操作,典型的membory bind的一种计算。它会对我们部署模型所用的mobile device的memory带宽有一定需求。
template
void ShuffleChannelLayer::Resize_cpu(Dtype *output, const Dtype *input, int group_row, int group_column, int len)
{
for (int i = 0; i < group_row; ++i) // 2
{
for(int j = 0; j < group_column ; ++j) // 3
{
const Dtype* p_i = input + (i * group_column + j ) * len;
Dtype* p_o = output + (j * group_row + i ) * len;
caffe_copy(len, p_i, p_o);
}
}
}
template
void ShuffleChannelLayer::Forward_cpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
const int num = bottom[0]->shape(0);
const int feature_map_size = bottom[0]->count(1);
const int sp_sz = bottom[0]->count(2);
const int chs = bottom[0]->shape(1);
int group_row = group_;
int group_column = int(chs / group_row);
CHECK_EQ(chs, (group_column * group_row)) << "Wrong group size.";
Dtype* temp_data = temp_blob_.mutable_cpu_data();
for(int n = 0; n < num; ++n)
{
Resize_cpu(temp_data+n*feature_map_size, bottom_data +n*feature_map_size, group_row, group_column, sp_sz);
}
caffe_copy(bottom[0]->count(), temp_blob_.cpu_data(), top_data);
}
template
void ShuffleChannelLayer::Backward_cpu(const vector*>& top,
const vector& propagate_down,
const vector*>& bottom) {
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
const int num = bottom[0]->shape(0);
const int feature_map_size = bottom[0]->count(1);
const int sp_sz = bottom[0]->count(2);
const int chs = bottom[0]->shape(1);
int group_row = int(chs / group_);
int group_column = group_;
Dtype* temp_diff = temp_blob_.mutable_cpu_diff();
for(int n = 0; n < num; ++n)
{
Resize_cpu(temp_diff + n * feature_map_size, top_diff+n*feature_map_size, group_row, group_column, sp_sz);
}
caffe_copy(top[0]->count(), temp_blob_.cpu_diff(), bottom_diff);
}
}
下面为ShuffleNet Unit在caffe protocol中的表示。
layer {
name: "resx2_conv1"
type: "Convolution"
bottom: "resx1_concat"
top: "resx2_conv1"
convolution_param {
num_output: 60
kernel_size: 1
stride: 1
pad: 0
group: 3
bias_term: false
weight_filler {
type: "msra"
}
}
}
layer {
name: "resx2_conv1_bn"
type: "BatchNorm"
bottom: "resx2_conv1"
top: "resx2_conv1"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
}
layer {
name: "resx2_conv1_scale"
bottom: "resx2_conv1"
top: "resx2_conv1"
type: "Scale"
scale_param {
filler {
value: 1
}
bias_term: true
bias_filler {
value: 0
}
}
}
layer {
name: "resx2_conv1_relu"
type: "ReLU"
bottom: "resx2_conv1"
top: "resx2_conv1"
}
layer {
name: "shuffle2"
type: "ShuffleChannel"
bottom: "resx2_conv1"
top: "shuffle2"
shuffle_channel_param {
group: 3
}
}
layer {
name: "resx2_conv2"
type: "ConvolutionDepthwise"
bottom: "shuffle2"
top: "resx2_conv2"
convolution_param {
num_output: 60
kernel_size: 3
stride: 1
pad: 1
bias_term: false
weight_filler {
type: "msra"
}
}
}
layer {
name: "resx2_conv2_bn"
type: "BatchNorm"
bottom: "resx2_conv2"
top: "resx2_conv2"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
}
layer {
name: "resx2_conv2_scale"
bottom: "resx2_conv2"
top: "resx2_conv2"
type: "Scale"
scale_param {
filler {
value: 1
}
bias_term: true
bias_filler {
value: 0
}
}
}
layer {
name: "resx2_conv3"
type: "Convolution"
bottom: "resx2_conv2"
top: "resx2_conv3"
convolution_param {
num_output: 240
kernel_size: 1
stride: 1
pad: 0
group: 3
bias_term: false
weight_filler {
type: "msra"
}
}
}
layer {
name: "resx2_conv3_bn"
type: "BatchNorm"
bottom: "resx2_conv3"
top: "resx2_conv3"
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
param {
lr_mult: 0
decay_mult: 0
}
}
layer {
name: "resx2_conv3_scale"
bottom: "resx2_conv3"
top: "resx2_conv3"
type: "Scale"
scale_param {
filler {
value: 1
}
bias_term: true
bias_filler {
value: 0
}
}
}
layer {
name: "resx2_elewise"
type: "Eltwise"
bottom: "resx1_concat"
bottom: "resx2_conv3"
top: "resx2_elewise"
eltwise_param {
operation: SUM
}
}
layer {
name: "resx2_elewise_relu"
type: "ReLU"
bottom: "resx2_elewise"
top: "resx2_elewise"
}
参考文献
- ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices, Xiangyu-Zhang, 2017
- https://github.com/MG2033/ShuffleNet