JVM类加载机制
1 class文件是字节码格式文件
2 Java语言系统自带三个类加载器:
- Bootstrap ClassLoader 启动类加载器
启动类加载器主要是加载核心类库,%JRE_HOME%\lib下的rt.jar、resources.jar、charsets.jar和class等
- Extention ClassLoader 扩展的类加载器
扩展的类加载器,加载目录%JRE_HOME%\lib\ext目录下的jar包和class文件
- AppClass Loader(System AppClass Loader)
加载当前应用的classpath的所有类
-
自定义类加载器(默认父类为AppClassLoader)
可以指定磁盘、内存和网络,AppClass Loader的parent是一个ExtClass Loader实例
Bootstrap classloader是由C/C++编写的,它本身是虚拟机的一部分,JVM启动时通过Bootstrap类加载器加载rt.jar等核心jar包中的class文件
3 双亲委托
一个类加载器查找class和resource时,是通过委托模式进行的,它首先判断这个class是不是已经加载成功,如果没有的话,它并不是自己进行查找而是先通过父加载器。然后递归下去,直到Bootstrap classLoader,如果Bootstrap ClassLoader找到了,直接返回,如果没有找到,则一级一级返回,最后到达自身去查找这些对象,这种机制叫双亲委托
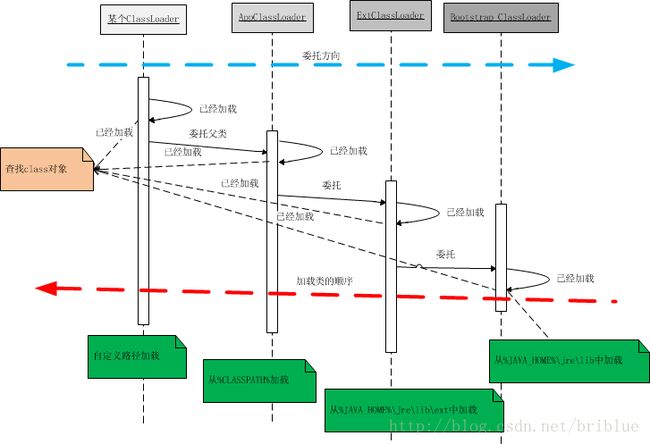
- 一个AppClassLoader查找资源时,先看看缓存是否有,缓存有从缓存中获取,否则委托给父加载器。
- 递归,重复第1部的操作。
- 如果ExtClassLoader也没有加载过,则由Bootstrap ClassLoader出面,它首先查找缓存,如果没有找到的话,就去找自己的规定的路径下,也就是
sun.mic.boot.class下面的路径。找到就返回,没有找到,让子加载器自己去找。 - Bootstrap ClassLoader如果没有查找成功,则ExtClassLoader自己在
java.ext.dirs路径中去查找,查找成功就返回,查找不成功,再向下让子加载器找。 - ExtClassLoader查找不成功,AppClassLoader就自己查找,在
java.class.path路径下查找。找到就返回。如果没有找到就让子类找,如果没有子类会怎么样?抛出各种异常。 - ClassLoader用来加载class文件的。
- 系统内置的ClassLoader通过双亲委托来加载指定路径下的class和资源。
- 可以自定义ClassLoader一般覆盖findClass()方法。
- ContextClassLoader与线程相关,可以获取和设置,可以绕过双亲委托的机制。
4 类的加载机制
类的加载机制分为5个阶段:加载 验证 准备 解析 初始化 使用 卸载
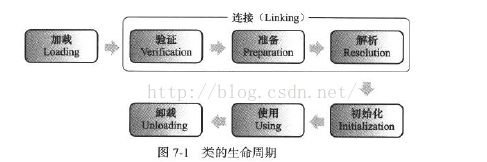
加载:
加载主要是将.class文件(也可以是zip包,网络中获取的二进制字节流)读入到Jvm中,
JVM完成了三件事:
1 通过类的全限定名(包名与类名)获取该类的二进制字节流(Class文件),
2 将字节流所代表的静态存储结构转化为方法区的运行时数据结构 ,
3 在内存中生成一个该类的java.long.class对象,作为方法区这个类的各种数据的访问入口。
验证:
主要确保加载进来的字节流符合JVM规范
准备:
准备主要是为静态变量在方法区分配内存,并设置默认的初始值
解析:
是虚拟机将常量池内的符号引用替换为直接引用的过程
初始化:
主要是根据程序中的赋值语句主动为类变量赋值
Java虚拟机规范中严格规定了有且只有五种情况必须对类进行初始化:
1 使用new字节码指令创建类的实例, 读取或设置一个静态字段的值, 调用一个静态方法的时候
2 通过java.lang.reflect包的方法对类进行反射调用的时候
3 如果发现其父类没有进行过初始化,则首先触发父类初始化
4 当虚拟机启动时,用户需要指定一个主类(包含main()方法的类),虚拟机会首先初始化这个类
JVM
1 程序计数器
线程私有,当前线程所执行的字节码的行号指示器,如果线程正在执行的是一个Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Natvie 方法,这个计数器值则为空(Undefined)。是唯一没有OutOfMemoryError 情况的区域
2 虚拟机栈
线程私有,栈帧存放的是执行的函数的一些数据(栈帧用于存储局部变量表、操作栈、动态
链接、方法出口等信息)
每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
这个区域规定了两种异常状况:
StackOverflowError :当前线程请求的栈深度大于虚拟机所允许的深度
OutOfMemoryError :虚拟机栈可以动态扩展,无法申请到足够的内存时
3 本地方法栈:
本地方法栈是为Native方法服务
4 堆
虚拟机中最大一块内存,它是所有线程共享的内存区域,几乎所有的实例对象都在这块区域中存放,Java堆是垃圾收集器管理的主要区域,也被称做“GC 堆”,分代收集算法:新生代和老年代,再细致点分:Eden 空间、From Survivor 空间、To Survivor 空间
5 方法区 : 称为“永久代”(Permanent Generation)
存放的是类信息、常量、静态变量等方法,各线程共享区域,这块区域回收比较难,运行时常量池(Runtime Constant Pool)是方法区的一部分(1.7以后常量池到堆里面了),oom
垃圾回收算法:
1 标记-清除算法
2 复制算法
3 标记整理算法
通过可达性分析将回收的对象进行标记,标记后再统一回收所有被标记的对象,标记过程其实就是可达性分析
设计模式
1 单利模式 在整个应用中保证只有一个类的实例存在
五种写法 ,懒汉、饿汉、双重检验锁、静态内部类、枚举
饿汉模式因为声明成static和final变量,在第一次加载类到内存中时就会初始化,且创建实例本身是线程安全的(懒汉式在第一次调用的时候才会初始化),通常开发中使用饿汉式,且饿汉是线程安全的,
//饿汉模式,很饿很着急,所以类加载时即创建实例对象
public class Singleton1 {
private static Singleton1 singleton = new Singleton1();
private Singleton1(){
}
public static Singleton1 getInstance(){
return singleton;
}
}
懒汉是非线程安全的,延迟加载,啥时候用啥时候创建实例
//饱汉模式,很饱不着急,延迟加载,啥时候用啥时候创建实例,存在线程安全问题
public class Singleton2 {
private static Singleton2 singleton;
private Singleton2(){
}
public static synchronized Singleton2 getInstance(){
if(singleton == null)
singleton = new Singleton2();
return singleton;
}
}
双重检验锁:是饱汉模式的优化,进行双重判断,当已经创建过实例对象后就无需加锁,提高效率。也是一种推荐使用的方式。
//饱汉模式的双重锁模式,提高效率
public class Singleton3 {
private static Singleton3 singleton;
private Singleton3(){
}
public static Singleton3 getInstance(){
if(singleton == null){
synchronized(Singleton3.class){
if(singleton == null){
singleton = new Singleton3();
}
}
}
return singleton;
}
}
构造函数是否私有化??
不行,单利类的构造函数必须私有化,单利类不能被实例化,单利只能静态调用
为何要检验两次??
有可能延迟加载或者缓存的原因,造成构造多个实例,违反了单利的初衷
静态内部类:
/**
* 静态内部类实现单例模式
* @author CrazyPig
*
*/
public class SpecialSingleton {
// 静态内部类
private static class NestClass {
private static SpecialSingleton instance;
static {
System.out.println("instance = new SingletonTest()");
instance = new SpecialSingleton();
}
}
// 不能直接new
private SpecialSingleton() {
System.out.println("private SingletonTest()");
}
public static SpecialSingleton getInstance() {
System.out.println("SingletonTest getInstance()");
return NestClass.instance;
}
public static void main(String[] args) {
SpecialSingleton instance = SpecialSingleton.getInstance();
SpecialSingleton instance01 = SpecialSingleton.getInstance();
SpecialSingleton instance02 = SpecialSingleton.getInstance();
}
}
2 工厂模式
参考:http://blog.csdn.net/hguisu/article/details/7505909
工厂模式主要是为创建对象提供过度接口,以便创建对象的具体过程屏蔽隔离起来,达到提高灵活性的目的,其核心功能是根据需求生产产品,核心思想是解耦需求 工厂 和 产品 工厂模式根据业务情况不同会有不同的实现方式,分简单工厂,工厂和抽象工厂。
简单工厂模式通过构造时传入的标记来生产产品,不同产品都在同一个工厂中生产
工程模式将工厂类分开,不再将所有产品在同一个工厂中生产
抽象工厂模式是解决工厂模式无法解决产品族和产品等级结构的问题。
工厂模式中,一个工厂生产一个产品,所有产品派生于同一个抽象产品,而抽象工厂模式中,一个工厂生产多个产品,他们是一个生产族,不同的产品族的产品派生于不同的抽象产品
接口有更好的可扩展性和可维护性,更加灵活实现的松散耦合,编程原则中有一条是针对接口编程而不是针对类编程
工厂模式日志记录:
日志记录器接口:抽象产品----具体产品--->数据库日志记录,文件日志记录()
日志记录器工厂接口:抽象工厂---具体工厂--->数据库日志记录器工厂类,文件日志记录工厂类
产品等级结构即产品的继承结构;产品族是指同一个工厂生产的位于不同产品等级结构中的一组产品
3 策略模式
参考:https://www.cnblogs.com/java-my-life/archive/2012/05/10/2491891.html
策略模式将可变的部分从程序中抽象成接口,在该接口下分别封装一系列算法实现
主要是针对一组算法,将每个算法封装到具体共同接口的独立的类中,从而使得它们可以相互替换,使得算法在不影响到客户端的情况下发生变化(定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换,本模式使得算法可独立于使用它的客户而变化)
举例:
假设现在要设计一个贩卖各类书籍的电子商务网站的购物车系统。一个最简单的情况就是把所有货品的单价乘上数量,但是实际情况肯定比这要复杂。比如,本网站可能对所有的高级会员提供每本20%的促销折扣;对中级会员提供每本10%的促销折扣;对初级会员没有折扣。
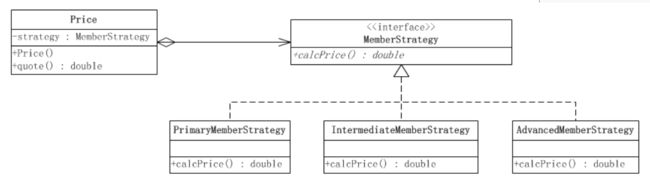
client传入MemberStrategy对象到Price中,Price 调用quote().calePrice()
4 观察者模式 发布订阅者模式
参考:http://blog.csdn.net/itachi85/article/details/50773358
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新,又叫发布订阅者模式
观察者实现由两种方式:推模型和拉模型
举例
微信公众号发布订阅
抽象观察者Observer (Observer)<---具体观察者WeixinUser (ConcrereObserver)
抽象被观察者Subject (Subject)<---具体被观察者SubscriptionSubject (ConcreteSubject)
客户端调用(创建微信用户 订阅公众号 公众号更新发出消息给订阅的微信用户)
android的Adapter
5 代理模式
参考:https://www.cnblogs.com/cenyu/p/6289209.html
提供了对目标对象另外的访问方式;即通过代理对象访问目标对象.这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能
代理模式的关键点是:代理对象与目标对象.代理对象是对目标对象的扩展,并会调用目标对象
静态代理:代理对象与目标对象要实现相同的接口,然后通过调用相同的方法来调用目标对象的方法
代码示例:
接口:IUserDao.java
//接口
public interface IUserDao {
void save();
}
目标对象:UserDao.java
//接口实现 目标对象
public class UserDao implements IUserDao {
public void save() {
System.out.println("----已经保存数据!----");
}
}
代理对象:UserDaoProxy.java
//代理对象,静态代理
public class UserDaoProxy implements IUserDao{
//接收保存目标对象
private IUserDao target;
public UserDaoProxy(IUserDao target){
this.target=target;
}
public void save() {
System.out.println("开始事务...");
target.save();//执行目标对象的方法
System.out.println("提交事务...");
}
}
测试类:App.java
// 测试类
public class App {
public static void main(String[] args) {
//目标对象
UserDao target = new UserDao();
//代理对象,把目标对象传给代理对象,建立代理关系
UserDaoProxy proxy = new UserDaoProxy(target);
proxy.save();//执行的是代理的方法
}
}
动态代理:
动态代理是在程序运行时,运用反射机制动态创建而成 ,
动态代理也叫做:JDK代理,接口代理,
代理对象,不需要实现接口,代理对象的生成,是利用JDK的API,动态的在内存中构建代理对象,
代理对象不需要实现接口,但是目标对象一定要实现接口,否则不能用动态代理
CGlib代理:
上面的静态代理和动态代理模式都是要求目标对象是实现一个接口的目标对象,但是有时候目标对象只是一个单独的对象,并没有实现任何的接口,这个时候就可以使用以目标对象子类的方式类实现代理,这种方法就叫做:Cglib代理
Cglib代理,也叫作子类代理,它是在内存中构建一个子类对象从而实现对目标对象功能的扩展.
举例:
经纪人代理
在Spring的AOP编程中:
如果加入容器的目标对象有实现接口,用JDK代理
如果目标对象没有实现接口,用Cglib代理
Java笔记
1 ArrayList 和Vector两者都是基于索引的,内部由一个数组支持
2 ArrayList和Vector以及HashMap都是fail-fast(线程安全的)
3 如何对一组对象进行排序Arrays.sort() (对象数组),collection.sort() (对象列表),自然排序 comparable和标准的排序Comparctor
4 集合中的collections提供集合框架常用的算法(如排序换个搜索,最大最小值)
5 Colletion接口是List,set,Queue的父级接口
6 垃圾回收器
串行收集器:小数据量的情况
并行收集器:以吞吐量为目的,适用于科学技术和后台处理
并发收集器:对响应时间有高要求,适用于应用服务器
7 新生代:老年代
新生代和老年代的比例为1:2(默认),它们共同组成堆的内存区
8 封装隐藏实现细节,继承扩展已存在的代码模块,多态实现接口重用
9 接口的方法默认是public abstract,接口不可以定义变量即只能定义常量,所以接口的属性默认是public、static、final常量
10 海量数据处理:
有一千万条短信,有重复,以文本形式保存,一行一条,找出重复最少的前10条???
思路:通过哈希表去重并统计出重复次数后,通过堆调整找出重复次数最少的前10条。
SimHash算法是Google公司进行海量网页去重的高效算法,它通过将原始的文本映射为64位的二进制数字串,然后通过比较二进制数字串的差异进而来表示原始文本内容的差异。
分词---hash---加权---合并---降维
有1千万条重复的短信,以文本的形式保存,一行一条,也有重复,请用5分钟时间找出重复最多的前10条短信??
采用内存映射办法。
首先,1千万条短信按现在的短息长度将不会超过1GB空间,使用内存映射文件比较合适,可以一次映射 (如果有更大的数据量,可以采用分段映射),由于不需要频繁使用文件I/O和频繁分配小内存,这将大大提高了数据的加载速度。
其次,对每条短信的第i(i从0到70)个字母按ASCII码进行分组,也就是创建树。i是 树的深度,也是短信第个字母。
这个问题主要是解决两方面的问题:
(1) 内容的加载,
(2)短信内容的比较。
采用内存映射技术可以解决内容加载的性能问题(不仅是不需要调用文件I/O函数,而且也不需要每读出一条短信都要分配一小块内存),而使用树技术可以有效地减少比较测次数。
11 哈希函数
直接定址法:取关键字或关键字的某个线性函数值为哈希地址:H(key)=key 或 H(key)=a·key+b
平方取中法:取关键字平方后的中间几位为哈希地址
除留余数法:取关键字被数p除后所得余数为哈希地址:H(key)=keyMOD p (p≤m)
随机数法等:选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key)=random (key)