Livy是一个开源的REST 接口,用于与Spark进行交互,它同时支持提交执行代码段和完整的程序。
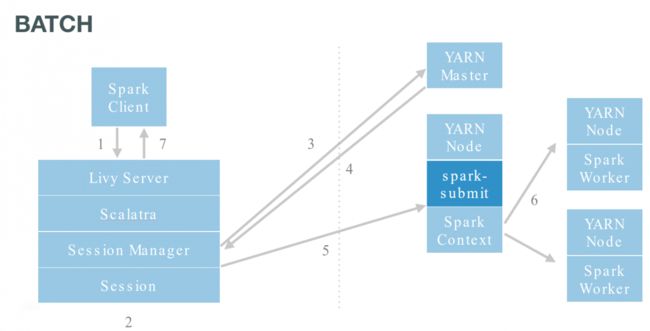
image.png
Livy封装了spark-submit并支持远端执行。
启动服务器
执行以下命令,启动livy服务器。
./bin/livy-server
这里假设spark使用yarn模式,所以所有文件路径都默认位于HDFS中。如果是本地开发模式的话,直接使用本地文件即可(注意必须配置livy.conf文件,设置livy.file.local-dir-whitelist = directory,以允许文件添加到session)。
提交jar包
首先我们列出当前正在执行的任务:
curl localhost:8998/sessions | python -m json.tool % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 34 0 34 0 0 2314 0 --:--:-- --:--:-- --:--:-- 2428
{
"from": 0,
"sessions": [],
"total": 0
}
然后提交jar包,假设提交的jar包位于hdfs中,路径为/usr/lib/spark/lib/spark-examples.jar
curl -X POST --data '{"file": "/user/romain/spark-examples.jar", "className": "org.apache.spark.examples.SparkPi"}' -H "Content-Type: application/json" localhost:8998/batches
{"id":0,"state":"running","log":[]}
返回结果中包括了提交的ID,这里为0,我们可以通过下面的命令查看任务状态:
curl localhost:8998/batches/0 | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 902 0 902 0 0 91120 0 --:--:-- --:--:-- --:--:-- 97k
{
"id": 0,
"log": [
"15/10/20 16:32:21 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.1.30:4040",
"15/10/20 16:32:21 INFO scheduler.DAGScheduler: Stopping DAGScheduler",
"15/10/20 16:32:21 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!",
"15/10/20 16:32:21 INFO storage.MemoryStore: MemoryStore cleared",
"15/10/20 16:32:21 INFO storage.BlockManager: BlockManager stopped",
"15/10/20 16:32:21 INFO storage.BlockManagerMaster: BlockManagerMaster stopped",
"15/10/20 16:32:21 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!",
"15/10/20 16:32:21 INFO spark.SparkContext: Successfully stopped SparkContext",
"15/10/20 16:32:21 INFO util.ShutdownHookManager: Shutdown hook called",
"15/10/20 16:32:21 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-6e362908-465a-4c67-baa1-3dcf2d91449c"
],
"state": "success"
}
此外,还可以通过下面的api,获取日志信息:
curl localhost:8998/batches/0/log | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5378 0 5378 0 0 570k 0 --:--:-- --:--:-- --:--:-- 583k
{
"from": 0,
"id": 3,
"log": [
"SLF4J: Class path contains multiple SLF4J bindings.",
"SLF4J: Found binding in [jar:file:/usr/lib/zookeeper/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]",
"SLF4J: Found binding in [jar:file:/usr/lib/flume-ng/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]",
"SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.",
"SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]",
"15/10/21 01:37:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable",
"15/10/21 01:37:27 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032",
"15/10/21 01:37:27 INFO yarn.Client: Requesting a new application from cluster with 1 NodeManagers",
"15/10/21 01:37:27 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)",
"15/10/21 01:37:27 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead",
"15/10/21 01:37:27 INFO yarn.Client: Setting up container launch context for our AM",
"15/10/21 01:37:27 INFO yarn.Client: Setting up the launch environment for our AM container",
"15/10/21 01:37:27 INFO yarn.Client: Preparing resources for our AM container",
....
....
"15/10/21 01:37:40 INFO yarn.Client: Application report for application_1444917524249_0004 (state: RUNNING)",
"15/10/21 01:37:41 INFO yarn.Client: Application report for application_1444917524249_0004 (state: RUNNING)",
"15/10/21 01:37:42 INFO yarn.Client: Application report for application_1444917524249_0004 (state: FINISHED)",
"15/10/21 01:37:42 INFO yarn.Client: ",
"\t client token: N/A",
"\t diagnostics: N/A",
"\t ApplicationMaster host: 192.168.1.30",
"\t ApplicationMaster RPC port: 0",
"\t queue: root.romain",
"\t start time: 1445416649481",
"\t final status: SUCCEEDED",
"\t tracking URL: http://unreal:8088/proxy/application_1444917524249_0004/A",
"\t user: romain",
"15/10/21 01:37:42 INFO util.ShutdownHookManager: Shutdown hook called",
"15/10/21 01:37:42 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-26cdc4d9-071e-4420-a2f9-308a61af592c"
],
"total": 67
}
还可以在命令行中添加参数,例如这里计算一百次:
curl -X POST --data '{"file": "/usr/lib/spark/lib/spark-examples.jar", "className": "org.apache.spark.examples.SparkPi", "args": ["100"]}' -H "Content-Type: application/json" localhost:8998/batches
{"id":1,"state":"running","log":[]}
如果想终止任务,可以调用以下API:
curl -X DELETE localhost:8998/batches/1
{"msg":"deleted"}
当重复调用上述接口时,什么也不会做,因为任务已经删除了:
curl -X DELETE localhost:8998/batches/1
session not found
提交Python任务
提交Python任务和Jar包类似:
curl -X POST --data '{"file": "/user/romain/pi.py"}' -H "Content-Type: application/json" localhost:8998/batches
{"id":2,"state":"starting","log":[]}
检查任务状态:
curl localhost:8998/batches/2 | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 616 0 616 0 0 77552 0 --:--:-- --:--:-- --:--:-- 88000
{
"id": 2,
"log": [
"\t ApplicationMaster host: 192.168.1.30",
"\t ApplicationMaster RPC port: 0",
"\t queue: root.romain",
"\t start time: 1445417899564",
"\t final status: UNDEFINED",
"\t tracking URL: http://unreal:8088/proxy/application_1444917524249_0006/",
"\t user: romain",
"15/10/21 01:58:26 INFO yarn.Client: Application report for application_1444917524249_0006 (state: RUNNING)",
"15/10/21 01:58:27 INFO yarn.Client: Application report for application_1444917524249_0006 (state: RUNNING)",
"15/10/21 01:58:28 INFO yarn.Client: Application report for application_1444917524249_0006 (state: RUNNING)"
],
"state": "running"
}
获取日志信息:
curl localhost:8998/batches/2/log | python -m json.tool