Day02的课程要点记录
详细教程地址:
金角大王 - Day1 Python基础1
金角大王 - Day2 Python基础2
银角大王
Python 运算符
一、.pyc是什么?
Python的运行过程
PyCodeObject是Python编译器真正编译成的结果,
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
应该这样来定位PyCodeObject和pyc文件,pyc文件其实是PyCodeObject的一种持久化保存方式。
二、常用的数据类型
2.1 数字
- int(整型)
在32位机器上,整数的位数为32位,取值范围为-231~231-1,即-2147483648~2147483647在64位系统上,整数的位数为64位,取值范围为-263~263-1,即-9223372036854775808~9223372036854775807
type(2**64) # type() 查询数据类型
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。float(浮点)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
2.2 布尔值
真或假
1 或 0(1 == True, 0 == False)
2.3 字符串
万恶的字符串拼接:每次创建字符串时候需要在内存中开辟一块连续的空间,并且一旦需要修改字符串的话,就需要再次开辟空间。所以+每出现一次就会在内从中重新开辟一块空间。
字符串格式化输出:
name = 'will'
print('I am %s' % name)
I am will
%s : 字符串; %d : 整数; %f : 浮点数
三、入门知识拾遗
3.1 bytes类型
Python 3的bytes/str之别 | The bytes/str dichotomy in Python 3
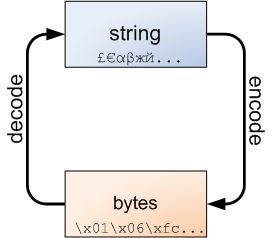
msg = '我爱北京天安门'
print(msg)
print(msg.encode('utf-8'))
print(msg.encode('utf-8').decode('utf-8'))
我爱北京天安门
b'\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8'
我爱北京天安门
3.2 三元运算
result = value1 if 条件 else value2
如果条件为真:result = value1; 如果条件为假:result = value2
a, b, c = 1, 2, 3
d = a if a>b else c
3.3 进制
- 二进制,01
- 八进制,01234567
- 十进制,0123456789
- 十六进制,0123456789ABCDEF 二进制到十六进制转换
四、列表的语法和使用
4.1 定义列表和访问元素(元素下标从0开始计数,也可以倒着取数)
age = 50
names = ['Will', 'Jack', 'Rose', 22, age]
print(names[0], names[1], names[-1], names[-2])
Will Jack 50 22
4.2 切片:取多个元素
>>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"]
>>> names[1:4] # 取下标1至下标4之间的数字,包括1,不包括4
['Tenglan', 'Eric', 'Rain']
>>> names[1:-1] # 取下标1至-1的值,不包括-1
['Tenglan', 'Eric', 'Rain', 'Tom']
>>> names[0:3]
['Alex', 'Tenglan', 'Eric']
>>> names[:3] # 如果是从头开始取,0可以忽略,跟上句效果一样
['Alex', 'Tenglan', 'Eric']
>>> names[3:] # 如果想取最后一个,必须不能写-1,只能这么写
['Rain', 'Tom', 'Amy']
>>> names[3:-1] # 这样-1就不会被包含了
['Rain', 'Tom']
>>> names[0::2] # 后面的2是代表,每隔一个元素,就取一个
['Alex', 'Eric', 'Tom']
>>> names[::2] # 和上句效果一样
['Alex', 'Eric', 'Tom']
4.3 修改
>>> names = ['Will','Jack', 'Rose', 22]
>>> names[2] = 'changed'
>>> names
['Will', 'Jack', 'changed', 22]
4.4 插入
>>> names = ['Will','Jack', 'Rose', 22]
>>> names.insert(2, '我在Rose前面')
>>> names
['Will', 'Jack', '我在Rose前面', 'Rose', 22]
>>> names.insert(4, '又到了Rose后面')
>>> names
['Will', 'Jack', '我在Rose前面', 'Rose', '又到了Rose后面', 22]
4.5 追加
>>> names = ['Will','Jack', 'Rose', 22]
>>> names.append('New')
>>> names
['Will', 'Jack', 'Rose', 22, 'New']
课堂练习1:
写一个列表,列表中包含本组所有成员。
往中间插入两个临组成员的名字
取出第3-8的人列表
删除第7个人
把刚才加入的那2个其他组的人一次性删除
把组长的名字加上组长备注
隔一个人取值
name = ['sublime', 'Will', 'Null', 'D', 'Alvin', '半塘', 'Fedor', 'smoonb', '行者无疆']
print('写一个列表,列表中包含本组所有成员:\n',name)
name.insert(4, '9组:sdo')
name.insert(4, '7组:cicia')
print('\n往中间插入两个临组成员的名字:\n', name)
name2 = name[2:8]
print('\n取出第3-8的人列表:\n', name2)
name.remove('Alvin')
print('\n删除第7个人:\n', name)
del name[4:6]
print('\n把刚才加入的那2个其他组的人一次性删除:\n', name)
name[0] = 'sublime(导师)'
print('\n把导师的名字加上导师备注:\n', name)
print('\n隔一个人取值\n', name[::2]) # 步长
4.6 判断列表中是否存在一个元素
>>> names = ['Will','Jack', 'Rose', 22]
>>> 22 in names
True
4.7 统计
>>> names = ['Will', 3, 5, 3, 6, 3, 5, 3, 8, 'Jack', 'Rose']
>>> names.count(3)
4
4.8 获取下标
>>> names = ['Will', 3, 5, 3, 6, 3, 5, 3, 8, 'Jack', 'Rose']
>>> names.index(3)
1
只返回找到的第一个下标
4.9 扩展
>>> names = ['Alex', 'Betty', 'Clare', 'Dior', 'Ella', 'Fiona']
>>> nums = [1, 2, 3, 4, 5, 6]
>>> names.extend(nums)
>>> names
['Alex', 'Betty', 'Clare', 'Dior', 'Ella', 'Fiona', 1, 2, 3, 4, 5, 6]
4.10 排序与翻转
- 排序(3.0里不同数据类型不能放在一起排序)
>>> name = ['Will','Jack', 'Rose']
>>> name.sort()
>>> name
['Jack', 'Rose', 'Will']
- 翻转
>>> names = ['Alex', 'Betty', 'Clare', 'Dior', 'Ella', 'Fiona']
>>> names.reverse()
>>> names
['Fiona', 'Ella', 'Dior', 'Clare', 'Betty', 'Alex']
4.11 复制
- 浅复制
>>> names = ['Will','Jack', 'Rose', [1, 2, 3, 4]]
>>> names2 = names.copy()
>>> names[3][1] = 'Yes'
>>> names2[3][2] = 'No'
>>> names[0] = 'WILL'
>>> names
['WILL', 'Jack', 'Rose', [1, 'Yes', 'No', 4]]
>>> names2
['Will', 'Jack', 'Rose', [1, 'Yes', 'No', 4]]
- 深复制
深层列表只指向内存地址,一处修改,处处修改。
如果想深复制列表,可以用import copy的copy.deepcopy
4.12 长度
>>> names = ['Will','Jack', 'Rose']
>>> len(names)
3
课堂练习2:
练习方法
copy,deepcopy,reverse,sort,pop,extend,index,count,步长[::2],del
找出有多少个9,把它改成9999
同时找出有多少个34,把它删除
nums = [1, 9, 2, 34, 9, 3, 9, 34, 4, 9, 5, 34, 9, 6, 9, 34, 7, 9, 8, 34, 9, 0]
for i in range(nums.count(9)):
nums[nums.index(9)] = 9999
print(nums)
for i2 in range(nums.count(34)):
nums.remove(34)
print(nums)
五、元组
元组与列表类似,也是存一组数。但是它一旦创建便不能修改。所以又叫只读列表。
语法:
names = ('Alice', 'Betty', 'Clare')
它只有2个方法,一个是count,一个是index。
六、字符串常用操作
6.1 移除空白
.strip() 默认为空格、换行,也可指定
6.2 分割
.split(',') 以,进行分割
6.3 长度
>>> names = 'Alice'
>>> len(names)
5
6.4 索引
>>> names = 'Alice'
>>> names.index('l')
1
6.5 切片
>>> names = 'Alice Aya'
>>> names[2:5]
'ice'
6.6 其他
'|'.join(name) 以|为分隔合并字符串
'' in name 判断是否有空格
.capitalize() 将字符串首字母改为大写
.format() 格式化字符串
.center(40, '-') 定义字符串长度为40,不足的用-填充
.find() 查找是否有某个字符串,如有则返回下标
.isdigit() 是否为数字
.startwith() 是否以某字符串为开始
.endwith() 是否以某字符串为结束
.upper() 将字符串全部转为大写
.lower 将字符串全部转为小写
七、数据运算
a = 9
b = 2
7.1 算数运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加:两个对象相加 | a + b 输出结果 11 |
| - | 减:得到负数或是一个数减去另一个数 | a - b 输出结果 7 |
| * | 乘:两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 18 |
| / | 除:a除以b | a / b 输出结果 4.5 |
| % | 取模:返回出发的余数 | a % b输出结果 1 |
| ** | 幂:返回a的b次幂 | a**b a的b次方,输出结果 81 |
| // | 取整数:返回商的整数部分 | 9//2 输出结果 4, 9.0//2.0 输出结果 4.0 |
7.2 比较运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于:比较对象是否相等 | (a == b) 返回 False |
| != | 不等于:比较对象是否不相等 | (a != b) 返回 True |
| <> | 不等于:比较对象是否不相等 | (a <> b) 返回 True,类似 !=,但不常用 |
| > | 大于:返回a是否大于b | (a > b) 返回 True |
| < | 小于:返回a是否小于b | (a < b) 返回 False |
>= |
大于等于:返回a是否大于等于b | (a >= b) 返回 True |
| <= | 小于等于:返回a是否小于等于b | (a <= b) 返回 False |
7.3 赋值运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
7.4 逻辑运算
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值 | (a and b) 返回 20 |
| or | x or y | 布尔"或" - 如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值 | (a or b) 返回 10 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True | not(a and b) 返回 False |
7.5. 成员运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False | x 在 y 序列中 , 如果 x 在 y 序列中返回 True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True |
7.6 身份运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is是判断两个标识符是不是引用自一个对象 | x is y, 如果 id(x) 等于 id(y) , is 返回结果 1 |
| is not | is not是判断两个标识符是不是引用自不同对象 | x is not y, 如果 id(x) 不等于 id(y). is not 返回结果 1 |
7.7 位运算
a = 0011 1100
b = 0000 1101
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| l | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1 | (a l b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0 | a << 2 输出结果 240 ,二进制解释: 1111 0000 ,a乘以2的2次幂 |
>> |
右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,">>"右边的数指定移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 ,a除以2的2次幂 |
*因markdown表格符号限制,用l代替` |
`* |
7.8 运算优先级
| 运算符 | 描述 |
|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ l | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not or and | 逻辑运算符 |
八、字典的使用
字典一种key - value的数据类型,类似我们上学用的字典,通过笔划、字母来查对应页的详细内容。
字典特性:
- dict是无序的
- key必须是唯一的,所以天生去重
8.1 语法
dict = {
'Euro': {
'UbiSoft': 'AssassinCreed',
'Supercell': 'ClashOfClans'
},
'Japan': {
'Nintendo': 'FireEmblem',
'Capcom': 'BioHazard',
'SquareEnix': 'FinalFantasy'
},
'U.S.A': {
'Blizzard': 'WarCraft',
'E.A': 'TheNeedForSpeed'
}
}
8.2 修改和增加
- 将
Japan中的SquareEnix的值改为DragonQuest
>>> dict['Japan']['SquareEnix'] = 'DragonQuest'
>>> dict
{'U.S.A': {'E.A': 'TheNeedForSpeed', 'Blizzard': 'WarCraft'}, 'Japan': {'Nintendo': 'FireEmblem', 'SquareEnix': 'DragonQuest', 'Capcom': 'BioHazard'}, 'Europe': {'Supercell': 'ClashOfClans', 'UbiSoft': 'AssassinCreed'}}
- 为
U.S.A增加keyEpicGames,valueWarGear
>>> dict['U.S.A']['EpicGames'] = 'WarGear'
>>> dict
{'U.S.A': {'E.A': 'TheNeedForSpeed', 'EpicGames': 'WarGear', 'Blizzard': 'WarCraft'}, 'Japan': {'Nintendo': 'FireEmblem', 'SquareEnix': 'FinalFantasy', 'Capcom': 'BioHazard'}, 'Europe': {'Supercell': 'ClashOfClans', 'UbiSoft': 'AssassinCreed'}}
8.3 删除
删除Japan中的SquareEnix
-
pop方法
>>> dict['Japan'].pop('SquareEnix')
'FinalFantasy'
>>> dict
{'U.S.A': {'E.A': 'TheNeedForSpeed', 'Blizzard': 'WarCraft'}, 'Japan': {'Nintendo': 'FireEmblem', 'Capcom': 'BioHazard'}, 'Euro': {'Supercell': 'ClashOfClans', 'UbiSoft': 'AssassinCreed'}}
del
>>> del dict['Japan']['SquareEnix']
>>> dict
{'U.S.A': {'E.A': 'TheNeedForSpeed', 'Blizzard': 'WarCraft'}, 'Japan': {'Nintendo': 'FireEmblem', 'Capcom': 'BioHazard'}, 'Euro': {'Supercell': 'ClashOfClans', 'UbiSoft': 'AssassinCreed'}}
8.4 查找
- 标准用法
>>> 'U.S.A' in dict
True
获取U.S.A下的Blizzard
-
get方法(如果一个key不存在,返回None)
>>> dict.get('U.S.A').get('Blizzard')
'WarCraft'
- 方法2(如果一个key不存在,会报错)
>>> dict['U.S.A']['Blizzard']
'WarCraft'
>>> dict['U.S.A']['B']
Traceback (most recent call last):
File "", line 1, in
KeyError: 'B'
>>>
8.5 循环
- 方法1(效率高)
>>> for key in dict:
... print(key, dict[key])
U.S.A {'E.A': 'TheNeedForSpeed', 'Blizzard': 'WarCraft'}
Japan {'Nintendo': 'FireEmblem', 'SquareEnix': 'FinalFantasy', 'Capcom': 'BioHazard'}
Euro {'Supercell': 'ClashOfClans', 'UbiSoft': 'AssassinCreed'}
- 方法2 (效率低)
for k,v in info.items(): #会先把dict转成list,数据里大时莫用
print(k,v)
8.6 其他
-
update(dict2中的键值更新至dict,如没有则增加,如有则覆盖键值)
>>> dict2 = {
... 'Japan': {
... 'Capcom': 'StreetFighter'
... },
... 'One': 1,
... 'Two': 2
... }
>>> dict.update(dict2)
>>> dict
{'U.S.A': {'E.A': 'TheNeedForSpeed', 'Blizzard': 'WarCraft'}, 'One': 1, 'Two': 2, 'Japan': {'Capcom': 'StreetFighter'}, 'Europe': {'Supercell': 'ClashOfClans', 'UbiSoft': 'AssassinCreed'}}
-
items将字典转为列表(一般不用)
>>> dict.items()
dict_items([('U.S.A', {'E.A': 'TheNeedForSpeed', 'Blizzard': 'WarCraft'}), ('Japan', {'Nintendo': 'FireEmblem', 'SquareEnix': 'FinalFantasy', 'Capcom': 'BioHazard'}), ('Euro', {'Supercell': 'ClashOfClans', 'UbiSoft': 'AssassinCreed'})])
-
values获取字典中全部的值
>>> dict.values()
dict_values([{'E.A': 'TheNeedForSpeed', 'Blizzard': 'WarCraft'}, {'Nintendo': 'FireEmblem', 'SquareEnix': 'FinalFantasy', 'Capcom': 'BioHazard'}, {'Supercell': 'ClashOfClans', '
UbiSoft': 'AssassinCreed'}])
-
keys获取字典中全部的键
>>> dict.keys()
dict_keys(['U.S.A', 'Japan', 'Euro'])
-
setdefault取一个key的值,不存在则设置默认值或指定值
>>> dict.setdefault('U.S.A')
{'E.A': 'TheNeedForSpeed', 'Blizzard': 'WarCraft'}
>>> dict.setdefault('China')
>>> dict
{'U.S.A': {'E.A': 'TheNeedForSpeed', 'Blizzard': 'WarCraft'}, 'Japan': {'Nintendo': 'FireEmblem', 'SquareEnix': 'FinalFantasy', 'Capcom': 'BioHazard'}, 'Euro': {'Supercell': 'ClashOfClans', 'UbiSoft': 'AssassinCreed'}, 'China': None}
-
fromkeys听说有坑,慎用。
>>> dict.fromkeys([1, 2, 3, 4, 5], 'NoWhere')
{1: 'NoWhere', 2: 'NoWhere', 3: 'NoWhere', 4: 'NoWhere', 5: 'NoWhere'}
-
popitem随机删除键/值(作死)
>>> dict.popitem()
('U.S.A', {'E.A': 'TheNeedForSpeed', 'Blizzard': 'WarCraft'})
九、set集合
待补充
十、终端显示效果
Python实现设置终端显示颜色、粗体、下划线等效果
十一、Day02练习
11.1 购物小程序
用户启动时先输入工资
用户启动程序后打印商品列表
允许用户选择商品
允许用户不断地购买各种商品
购买时检测余额是否足够,如果足够直接扣款,否则打印余额不足。
允许用户主动退出程序,退出时打印已购列表。
11.2 作业需求
- 优化购物程序,购买时允许用户选择购买多少件。
- 允许多用户登录,下一次登录后,继续按上次的余额继续购买(可以充值)
- 允许用户查看之前的购买记录(记录要显示商品购买时间)
- 商品列表分级展示,比如:
第一级菜单
1.家电类
2.服装类
3.手机类
4.车类 - 显示已购买商品时,如果有重复的商品,不打印多行,而是在一行展示。
id p_name num total_price
1 Tesla 2 1600000
2 Coffee 2 30
3 Bike 1 700 - 新知识
文件处理
日期模块datatime
序列化json