英国人Robert Pitt曾在Github上公布了他的爬虫脚本,导致任何人都可以容易地取得Google Plus的大量公开用户的ID信息。至今大概有2亿2千5百万用户ID遭曝光。
亮点在于,这是个nodejs脚本,非常短,包括注释只有71行。
毫无疑问,nodeJS改变了整个前端开发生态。
本文一步步完成了一个基于promise的nodeJS爬虫程序,收集任意指定作者的文章信息。并最终把爬下来结果以邮件的形式,自动发给目标对象。千万不要被nodeJS的外表吓到,即使你是初入前端的小菜鸟,或是刚接触nodeJS不久的新同学,都不妨碍对这篇文章的阅读和理解。
爬虫的所有代码可以在我的Github仓库找到,日后这个爬虫程序还会进行不断升级和更新,欢迎关注。
nodeJS VS Python实现爬虫
我们先从爬虫说起。对比一下,讨论为什么nodeJS适合/不适合作为爬虫编写语言。
首先,总结一下:
NodeJS单线程、事件驱动的特性可以在单台机器上实现极大的吞吐量,非常适合写网络爬虫这种资源密集型的程序。
但是,对于一些复杂场景,需要更加全面的考虑。以下内容总结自知乎相关问题,感谢@知乎网友,对答案的贡献。
如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,那么用什么语言差异不大。
如果是定向爬取,且主要目标是解析js动态生成的内容 :
此时,页面内容是由js/ajax动态生成的,用普通的请求页面+解析的方法就不管用了,需要借助一个类似firefox、chrome浏览器的js引擎来对页面的js代码做动态解析。如果爬虫是涉及大规模网站爬取,效率、扩展性、可维护性等是必须考虑的因素时候:
- PHP:对多线程、异步支持较差,不建议采用。
- NodeJS:对一些垂直网站爬取倒可以。但由于分布式爬取、消息通讯等支持较弱,根据自己情况判断。
- Python:建议,对以上问题都有较好支持。
当然,我们今天所实现的是一个简易爬虫,不会对目标网站带来任何压力,也不会对个人隐私造成不好影响。毕竟,他的目的只是熟悉nodeJS环境。适用于新人入门和练手。
同样,任何恶意的爬虫性质是恶劣的,我们应当全力避免影响,共同维护网络环境的健康。
爬虫实例
今天要编写的爬虫目的是爬取作者:LucasHC(我本人)在平台上,发布过的所有文章信息,包括每篇文章的:
- 发布日期;
- 文章字数;
- 评论数;
- 浏览数、赞赏数;
等等。
最终爬取结果的输出如下:

同时,以上结果,我们需要通过脚本,自动发送邮件到指定邮箱。收件内容如下:
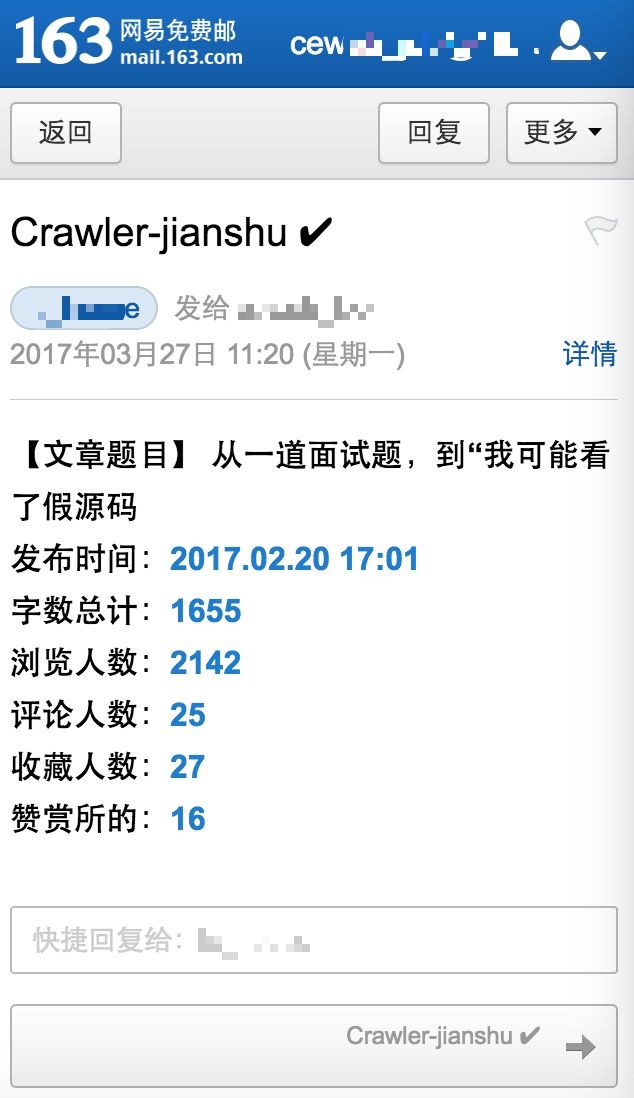
全部操作只需要一键便可完成。
爬虫设计
我们的程序一共依赖三个模块/类库:
const http = require("http");
const Promise = require("promise");
const cheerio = require("cheerio");
发送请求
http是nodeJS的原生模块,自身就可以用来构建服务器,而且http模块是由C++实现的,性能可靠。
我们使用Get,来请求作者相关文章的对应页面:
http.get(url, function(res) {
var html = "";
res.on("data", function(data) {
html += data;
});
res.on("end", function() {
...
});
}).on("error", function(e) {
reject(e);
console.log("获取信息出错!");
});
因为我发现,中每一篇文章的链接形式如下:
完整形式:“http://www.jianshu.com/p/ab2741f78858”,
即 “http://www.jianshu.com/p/” + “文章id”。
所以,上述代码中相关作者的每篇文章url:由baseUrl和相关文章id拼接组成:
articleIds.forEach(function(item) {
url = baseUrl + item;
});
articleIds自然是存储作者每篇文章id的数组。
最终,我们把每篇文章的html内容存储在html这个变量中。
异步promise封装
由于作者可能存在多篇文章,所以对于每篇文章的获取和解析我们应该异步进行。这里我使用了promise封装上述代码:
function getPageAsync (url) {
return new Promise(function(resolve, reject){
http.get(url, function(res) {
...
}).on("error", function(e) {
reject(e);
console.log("获取信息出错!");
});
});
};
这样一来,比如我写过14篇原创文章。那么对每一片文章的请求和处理全都是一个promise对象。我们存储在预先定义好的数组当中:
const articlePromiseArray = [];
接下来,我使用了Promise.all方法进行处理。
Promise.all方法用于将多个Promise实例,包装成一个新的Promise实例。
该方法接受一个promise实例数组作为参数,实例数组中所有实例的状态都变成Resolved,Promise.all返回的实例才会变成Resolved,并将Promise实例数组的所有返回值组成一个数组,传递给回调函数。
也就是说,我的14篇文章的请求对应14个promise实例,这些实例都请求完毕后,执行以下逻辑:
Promise.all(articlePromiseArray).then(function onFulfilled (pages) {
pages.forEach(function(html) {
let info = filterArticles(html);
printInfo(info);
});
}, function onRejected (e) {
console.log(e);
});
他的目的在于:对每一个返回值(这个返回值为单篇文章的html内容),进行filterArticles方法处理。处理所得结果进行printInfo方法输出。
接下来,我们看看filterArticles方法做了什么。
html解析
其实很明显,如果您理解了上文的话。filterArticles方法就是对单篇文章的html内容进行有价值的信息提取。这里有价值的信息包括:
1)文章标题;
2)文章发表时间;
3)文章字数;
4)文章浏览量;
5)文章评论数;
6)文章赞赏数。
function filterArticles (html) {
let $ = cheerio.load(html);
let title = $(".article .title").text();
let publishTime = $('.publish-time').text();
let textNum = $('.wordage').text().split(' ')[1];
let views = $('.views-count').text().split('阅读')[1];
let commentsNum = $('.comments-count').text();
let likeNum = $('.likes-count').text();
let articleData = {
title: title,
publishTime: publishTime,
textNum: textNum
views: views,
commentsNum: commentsNum,
likeNum: likeNum
};
return articleData;
};
你也许会奇怪,为什么我能使用类似jQuery中的$对html信息进行操作。其实这归功于cheerio类库。
filterArticles方法返回了每篇文章我们感兴趣的内容。这些内容存储在articleData对象当中,最终由printInfo进行输出。
邮件自动发送
到此,爬虫的设计与实现到了一段落。接下来,就是把我们爬取的内容以邮件方式进行发送。
这里我使用了nodemailer模块进行发送邮件。相关逻辑放在Promise.all当中:
Promise.all(articlePromiseArray).then(function onFulfilled (pages) {
let mailContent = '';
var transporter = nodemailer.createTransport({
host : 'smtp.sina.com',
secureConnection: true, // 使用SSL方式(安全方式,防止被窃取信息)
auth : {
user : '**@sina.com',
pass : ***
},
});
var mailOptions = {
// ...
};
transporter.sendMail(mailOptions, function(error, info){
if (error) {
console.log(error);
}
else {
console.log('Message sent: ' + info.response);
}
});
}, function onRejected (e) {
console.log(e);
});
邮件服务的相关配置内容我已经进行了适当隐藏。读者可以自行配置。
总结
本文,我们一步一步实现了一个爬虫程序。涉及到的知识点主要有:nodeJS基本模块用法、promise概念等。如果拓展下去,我们还可以做nodeJS连接数据库,把爬取内容存在数据库当中。当然也可以使用node-schedule进行定时脚本控制。当然,目前这个爬虫目的在于入门,实现还相对简易,目标源并不是大型数据。
全部内容只涉及nodeJS的冰山一角,希望大家一起探索。如果你对完整代码感兴趣,请点击这里。
Happy Coding!