定义
关联分析是一种简单、实用的分析技术,就是发现存在于大量数据集中的关联性或相关性,从而描述了一个事物中某些属性同时出现的规律和模式。
关联分析是从大量数据中发现项集之间有趣的关联和相关联系。关联分析的一个典型例子是购物篮分析。该过程通过发现顾客放人其购物篮中的不同商品之间的联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买,这种关联的发现可以帮助零售商制定营销策略。其他的应用还包括价目表设计、商品促销、商品的排放和基于购买模式的顾客划分。
可从数据库中关联分析出形如“由于某些事件的发生而引起另外一些事件的发生”之类的规则。如“67%的顾客在购买啤酒的同时也会购买尿布”,因此通过合理的啤酒和尿布的货架摆放或捆绑销售可提高超市的服务质量和效益。又如“‘C语言’课程优秀的同学,在学习‘数据结构’时为优秀的可能性达88%”,那么就可以通过强化“C语言”的学习来提高教学效果。
相关概念
支持度与置信度
关联规则可以描述成:项集 → 项集。项集X出现的事务次数(亦称为support count)定义为:
σ(X)=|ti|X⊆ti,ti∈T|
其中,ti表示某个事务(TID),T表示事务的集合。关联规则X⟶Y的支持度(support):
support(X⟶Y)=σ(X∪Y)|T|
支持度刻画了项集X∪Y的出现频次。置信度(confidence)定义如下:
confidence(X⟶Y)=σ(X∪Y)σ(X)
对概率论稍有了解的人,应该看出来:置信度可理解为条件概率p(Y|X),度量在已知事务中包含了X时包含Y的概率。
对于靠谱的关联规则,其支持度与置信度均应大于设定的阈值。那么,关联分析问题即等价于:对给定的支持度阈值min_sup、置信度阈值min_conf,找出所有的满足下列条件的关联规则:
支持度>=min_sup
置信度>=min_conf
把支持度大于阈值的项集称为频繁项集(frequent itemset)。因此,关联规则分析可分为下列两个步骤:
- 生成频繁项集F=X∪Y;
- 在频繁项集F中,找出所有置信度大于最小置信度的关联规则X⟶Y。
举个例子:
| TID | Items |
|---|---|
| 001 | Cola, Egg, Ham |
| 002 | Cola, Diaper, Beer |
| 003 | Cola, Diaper, Beer, Ham |
| 004 | Diaper, Beer |
TID代表交易流水号,Items代表一次交易的商品。我们对这个数据集进行关联分析,可以找出关联规则{Diaper}→{Beer}。
它代表的意义是:购买了Diaper的顾客会购买Beer。这个关系不是必然的,但是可能性很大,这就已经足够用来辅助商家调整Diaper和Beer的摆放位置了,例如摆放在相近的位置,进行捆绑促销来提高销售量。
1、事务:每一条交易称为一个事务,例如示例1中的数据集就包含四个事务。
2、项:交易的每一个物品称为一个项,例如Cola、Egg等。
3、项集:包含零个或多个项的集合叫做项集,例如{Cola, Egg, Ham}。
4、k−项集:包含k个项的项集叫做k-项集,例如{Cola}叫做1-项集,{Cola, Egg}叫做2-项集。
5、支持度计数:一个项集出现在几个事务当中,它的支持度计数就是几。例如{Diaper, Beer}出现在事务 002、003和004中,所以它的支持度计数是3。
6、支持度:支持度计数除于总的事务数。例如上例中总的事务数为4,{Diaper, Beer}的支持度计数为3,所以它的支持度是3÷4=75%,说明有75%的人同时买了Diaper和Beer。
7、频繁项集:支持度大于或等于某个阈值的项集就叫做频繁项集。例如阈值设为50%时,因为{Diaper, Beer}的支持度是75%,所以它是频繁项集。
8、前件和后件:对于规则{Diaper}→{Beer},{Diaper}叫做前件,{Beer}叫做后件。
9、置信度:对于规则{Diaper}→{Beer},{Diaper, Beer}的支持度计数除于{Diaper}的支持度计数,为这个规则的置信度。例如规则{Diaper}→{Beer}的置信度为3÷3=100%。说明买了Diaper的人100%也买了Beer。
10、强关联规则:大于或等于最小支持度阈值和最小置信度阈值的规则叫做强关联规则。关联分析的最终目标就是要找出强关联规则[1] 。
挖掘过程
频繁项集挖掘
在进行频繁项集挖掘之前,我们需要根据现有数据的项集items得到所有可能的项集组合。假设现在有个只包含a,b,c,d四个项集的事务,其可能的项集组合如下:

根据支持度的定义,得到如下的先验定理:
- 定理1:如果一个项集是频繁的,那么其所有的子集(subsets)也一定是频繁的。
这个比较容易证明,因为某项集的子集的支持度一定不小于该项集。
- 定理2:如果一个项集是非频繁的,那么其所有的超集(supersets)也一定是非频繁的。
定理2是上一条定理的逆反定理。根据定理2,可以对项集树进行如下剪枝:

频繁项集的挖掘算法思路大致如下:

关联规则挖掘
关联规则是由频繁项集生成的,即对于Fk,找出项集hm,使得规则fk−hm⟶hm的置信度大于置信度阈值。同样地,根据置信度定义得到如下定理:
- 定理3:如果规则X⟶Y−X不满足置信度阈值,则X的子集X′,规则X′⟶Y−X′也不满足置信度阈值。
根据定理3,可对规则树进行如下剪枝:

生成关联规则的算法如下:

频繁项集算法
Apriori
Apriori算法过程
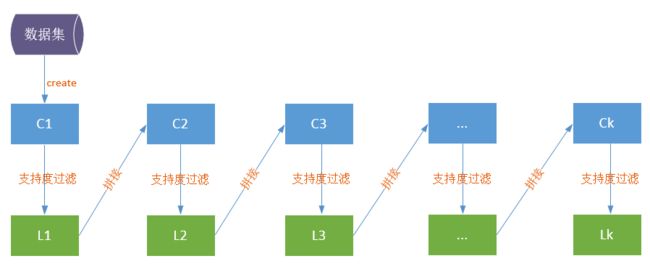
挖掘频繁项集的过程如上图所示:
1. 由数据集生成候选项集C1(1表示每个候选项仅有一个数据项);再由C1通过支持度过滤,生成频繁项集L1(1表示每个频繁项仅有一个数据项)。
2. 将L1的数据项两两拼接成C2。
3. 从候选项集C2开始,通过支持度过滤生成L2。L2根据Apriori原理拼接成候选项集C3;C3通过支持度过滤生成L3……直到Lk中仅有一个或没有数据项为止。
Apriori算法的代码实现:
package com.qqmaster.com.machineLearning;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import com.qqmaster.com.machineLearning.node.AprioriNode;
public class Algorithm_Apriori {
public static void main(String[] args) {
List data = new ArrayList();
String[] names = {"p1", "p2", "P3", "P4", "P5"};
AprioriNode.attNames = names;
AprioriNode d0 = new AprioriNode();
boolean[] f0 = {true,true,false,false,true};
d0.setFeatures(f0);
AprioriNode d1 = new AprioriNode();
boolean[] f1 = {false,true,false,true,false};
d1.setFeatures(f1);
AprioriNode d2 = new AprioriNode();
boolean[] f2 = {false,false,true,true,false};
d2.setFeatures(f2);
AprioriNode d3 = new AprioriNode();
boolean[] f3 = {true,true,false,true,false};
d3.setFeatures(f3);
AprioriNode d4 = new AprioriNode();
boolean[] f4 = {true,false,true,false,false};
d4.setFeatures(f4);
AprioriNode d5 = new AprioriNode();
boolean[] f5 = {false,true,true,false,false};
d5.setFeatures(f5);
AprioriNode d6 = new AprioriNode();
boolean[] f6 = {true,false,true,false,false};
d6.setFeatures(f6);
AprioriNode d7 = new AprioriNode();
boolean[] f7 = {true,true,true,false,true};
d7.setFeatures(f7);
AprioriNode d8 = new AprioriNode();
boolean[] f8 = {true,true,true,false,false};
d8.setFeatures(f8);
AprioriNode d9 = new AprioriNode();
boolean[] f9 = {true,false,true,false,true};
d9.setFeatures(f9);
data.add(d0);
data.add(d1);
data.add(d2);
data.add(d3);
data.add(d4);
data.add(d5);
data.add(d6);
data.add(d7);
data.add(d8);
data.add(d9);
for(double support = 0.1;support <= 0.9; support += 0.1){
System.out.println("support -> " + support);
Algorithm_Apriori apriori = new Algorithm_Apriori();
System.out.println("\nFrequent Items -> " + apriori.aprior(data, support));
System.out.println("\n--------------------------------\n");
}
}
/**
* Aprior 算法入口
*
* @param data
* @param support
* @return
*/
public List> aprior(List data, double support){
List> freqItems = new ArrayList>();
//1. 获取meta items
List> metaItems = metaFreqItems(data, support);
//2. 迭代的获取item集合超集合。
do{
freqItems.addAll(metaItems);
System.out.println("step--" + freqItems);
metaItems = supFreItems(data, metaItems, support);
}while(metaItems != null && !metaItems.isEmpty());
return freqItems;
}
/**
* 初始化meta item项集,并根据support进行筛选,剪枝
*
* @param data
* @param support
* @return
*/
private List> metaFreqItems(List data,
double support){
List> metaItems = new ArrayList>();
for(int i=0; i < AprioriNode.attNames.length; i++){
Set set = new HashSet();
set.add(i);
metaItems.add(set);
}
rmWithSupport(data, metaItems,support);
return metaItems;
}
/**
*
* @param data
* @param supFreItems
* @param support
* @return
*/
private List> supFreItems(List data,
List> subFreItems,
double support){
if(subFreItems == null || subFreItems.size()<=1){
return null;
}
int size = subFreItems.size();
List> list = new ArrayList>();
for(int i = 0; i < size - 1; i++){
for(int j = i + 1; j < size; j++){
Set s = mergeSet(subFreItems.get(i),
subFreItems.get(j));
if(s!=null)
if(!list.contains(s))
list.add(s);
}
}
rmWithSupport(data,list,support);
return list;
}
/**
* 求两个集合的并集
*
* @param set1
* @param set2
* @return
*/
private Set mergeSet(Set set1, Set set2){
if(set1 == null || set2 == null)
return null;
Set newSet = new HashSet<>(set1);
set2.forEach(it -> {
newSet.add(it);
});
if(newSet.size() > set1.size() + 1)
return null;
return newSet;
}
/**
* 根据支持度,移除不满足支持度的项集
*
* @param data
* @param items
* @param support
* @return
*/
private void rmWithSupport(List data,
List> items,
double support){
for(int i = items.size() - 1; i >= 0; i--){
if(support(data, items.get(i)) < support)
items.remove(i);
}
}
/**
* 获取指定item项集的支持度-support
* @return
*/
private double support(List data, Set items){
if(data == null || data.size() < 1)
return 0.0;
int count = 0;
for(AprioriNode d:data){
if(isFreqItems(d.getFeatures(), items)) count++;
}
return 1.0 * count / data.size();
}
/**
* 判断集合是否中的item是否均命中。
*
* @param features
* @param items
* @return
*/
private boolean isFreqItems(boolean[] features, Set items){
if(items == null || items.size() < 1) return false;
for(Integer i : items)
if(!features[i]) return false;
return true;
}
}
挖掘结果展示:
假设我们现在有以下数据记录:
| TID | P1 | P2 | P3 | P4 | P5 |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 1 |
| 2 | 0 | 1 | 0 | 1 | 0 |
| 3 | 0 | 1 | 1 | 0 | 0 |
| 4 | 1 | 1 | 0 | 1 | 0 |
| 5 | 1 | 0 | 1 | 0 | 0 |
| 6 | 0 | 1 | 1 | 0 | 0 |
| 7 | 1 | 0 | 1 | 0 | 0 |
| 8 | 1 | 1 | 1 | 0 | 1 |
| 9 | 1 | 1 | 1 | 0 | 0 |
| 10 | 1 | 0 | 1 | 0 | 1 |
根据不同的support,我们会得到不同的频繁项集挖掘结果。
support -> 0.1
step--[[0], [1], [2], [3], [4]]
step--[[0], [1], [2], [3], [4], [0, 1], [0, 2], [0, 3], [0, 4], [1, 2], [1, 3], [1, 4], [2, 3], [2, 4]]
step--[[0], [1], [2], [3], [4], [0, 1], [0, 2], [0, 3], [0, 4], [1, 2], [1, 3], [1, 4], [2, 3], [2, 4], [0, 1, 2], [0, 1, 3], [0, 1, 4], [0, 2, 4], [1, 2, 4]]
step--[[0], [1], [2], [3], [4], [0, 1], [0, 2], [0, 3], [0, 4], [1, 2], [1, 3], [1, 4], [2, 3], [2, 4], [0, 1, 2], [0, 1, 3], [0, 1, 4], [0, 2, 4], [1, 2, 4], [0, 1, 2, 4]]
Frequent Items -> [[0], [1], [2], [3], [4], [0, 1], [0, 2], [0, 3], [0, 4], [1, 2], [1, 3], [1, 4], [2, 3], [2, 4], [0, 1, 2], [0, 1, 3], [0, 1, 4], [0, 2, 4], [1, 2, 4], [0, 1, 2, 4]]
--------------------------------
support -> 0.2
step--[[0], [1], [2], [3], [4]]
step--[[0], [1], [2], [3], [4], [0, 1], [0, 2], [0, 4], [1, 2], [1, 3], [1, 4], [2, 4]]
step--[[0], [1], [2], [3], [4], [0, 1], [0, 2], [0, 4], [1, 2], [1, 3], [1, 4], [2, 4], [0, 1, 2], [0, 1, 4], [0, 2, 4]]
Frequent Items -> [[0], [1], [2], [3], [4], [0, 1], [0, 2], [0, 4], [1, 2], [1, 3], [1, 4], [2, 4], [0, 1, 2], [0, 1, 4], [0, 2, 4]]
--------------------------------
support -> 0.30000000000000004
step--[[0], [1], [2]]
step--[[0], [1], [2], [0, 1], [0, 2]]
Frequent Items -> [[0], [1], [2], [0, 1], [0, 2]]
--------------------------------
support -> 0.4
step--[[0], [1], [2]]
step--[[0], [1], [2], [0, 1], [0, 2]]
Frequent Items -> [[0], [1], [2], [0, 1], [0, 2]]
--------------------------------
support -> 0.5
step--[[0], [1], [2]]
step--[[0], [1], [2], [0, 2]]
Frequent Items -> [[0], [1], [2], [0, 2]]
--------------------------------
support -> 0.6
step--[[0], [1], [2]]
Frequent Items -> [[0], [1], [2]]
--------------------------------
support -> 0.7
step--[[0], [2]]
Frequent Items -> [[0], [2]]
--------------------------------
support -> 0.7999999999999999
step--[]
Frequent Items -> []
--------------------------------
support -> 0.8999999999999999
step--[]
Frequent Items -> []
--------------------------------
FP-Growth
算法简介:
FP-Growth(Frequent Pattern Growth, 频繁模式增长)算法是韩家炜等人在2000年提出的关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息。
在算法中使用了一种称为频繁模式树(Frequent Pattern Tree)的数据结构。FP-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成。FP-Growth算法基于以上的结构加快整个挖掘过程。FP-Growth比Apriori算法效率更高,在整个算法执行过程中,只需要遍历数据集2次,就可完成频繁模式的发现。
提出背景:
所周知,Apriori算法[1] 在产生频繁模式完全集前需要对数据库进行多次扫描,同时产生大量的候选频繁集,这就使Apriori算法时间和空间复杂度较大。但是Apriori算法中有一个很重要的性质:频繁项集的所有非空子集都必须也是频繁的。但是Apriori算法在挖掘额长频繁模式的时候性能往往低下,于是Jiawei Han提出了FP-Growth算法。
算法思想:
FP-Growth算法的描述如下:
1、对于每个频繁项,构造它的条件投影数据库和投影FP-tree。
2、对每个新构建的FP-tree重复这个过程,直到构造的新FP-tree为空,或者只包含一条路径。
3、当构造的FP-tree为空时,其前缀即为频繁模式;当只包含一条路径时,通过枚举所有可能组合并与此树的前缀连接即可得到频繁模式。
示例说明:
假设我们有以下数据,假设现在支持度support=3:
| TID | P1 | P2 | P3 | P4 | P5 |
|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 0 | 1 |
| 2 | 0 | 1 | 0 | 1 | 0 |
| 3 | 0 | 1 | 1 | 0 | 1 |
| 4 | 1 | 1 | 0 | 1 | 0 |
| 5 | 1 | 0 | 1 | 0 | 1 |
| 6 | 0 | 1 | 1 | 0 | 0 |
| 7 | 1 | 0 | 1 | 0 | 0 |
| 8 | 1 | 1 | 1 | 0 | 1 |
| 9 | 1 | 1 | 0 | 0 | 0 |
| 10 | 1 | 0 | 1 | 0 | 0 |
我们可以得到所有item的出现频率:
| item | p1 | p2 | p3 | p4 | p5 |
|---|---|---|---|---|---|
| frequency | 6 | 7 | 6 | 2 | 4 |
step 1. 生成Header Table
去除不满足support的item,并依据frequency按照从大到小进行排序。我们可以得到如下的table。
| item | p2 | p1 | p3 | p5 |
|---|---|---|---|---|
| frequency | 0.7 | 0.6 | 0.6 | 0.4 |
step 2. 生成Header Tree
再次扫描一次数据库,依据Header Table中的各个属性的顺序,将每个示例加入到Header Tree中,过程如下图所示:
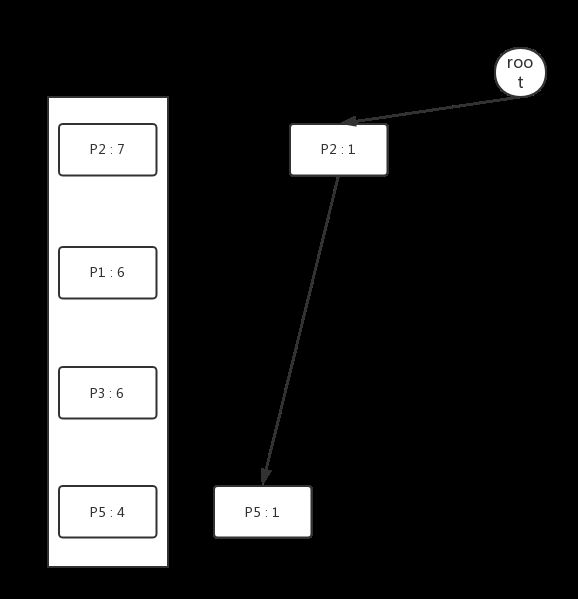
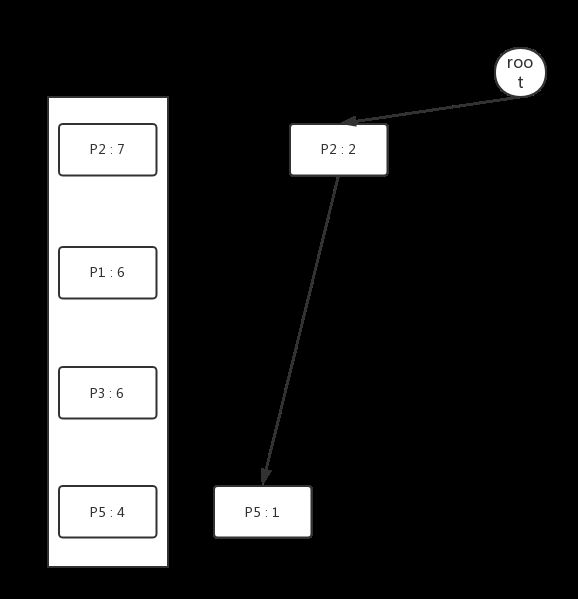
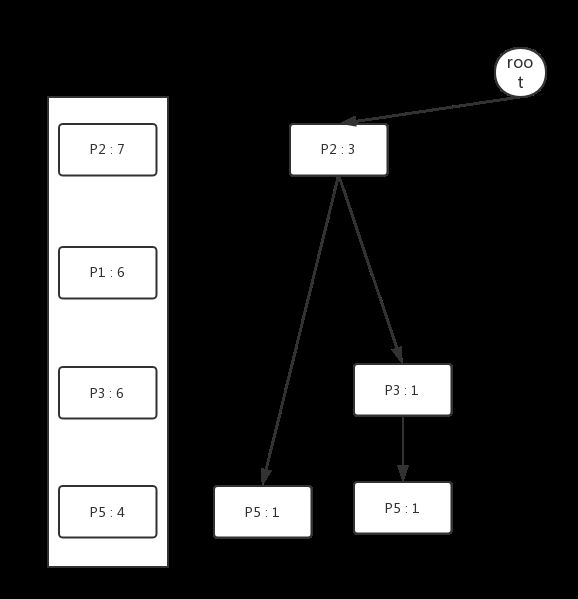
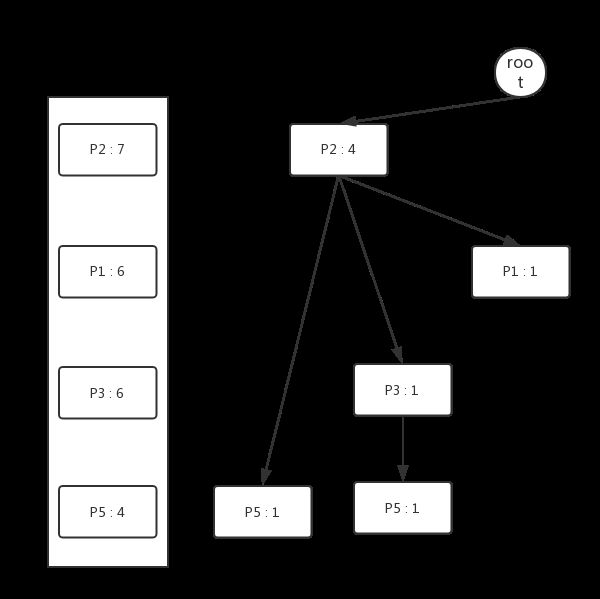

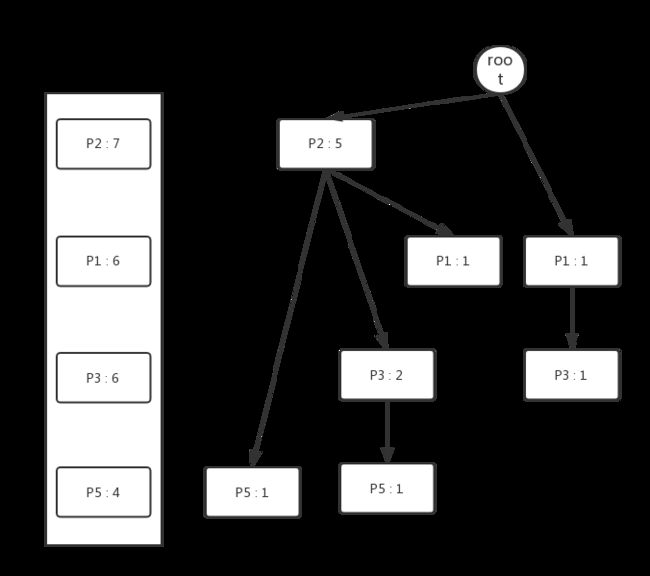

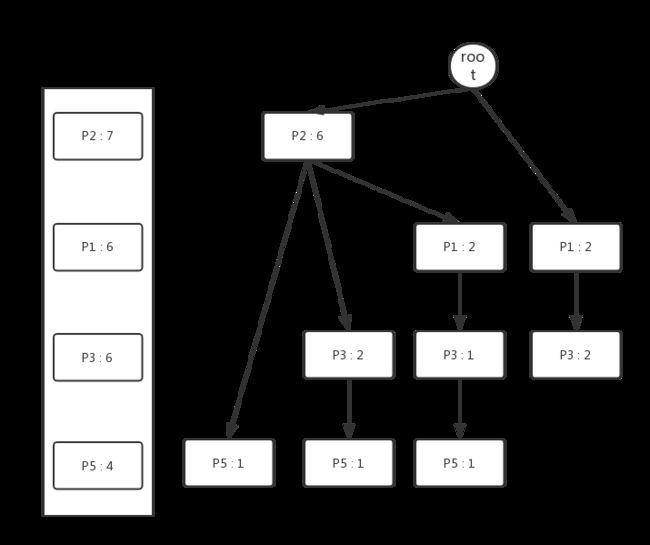
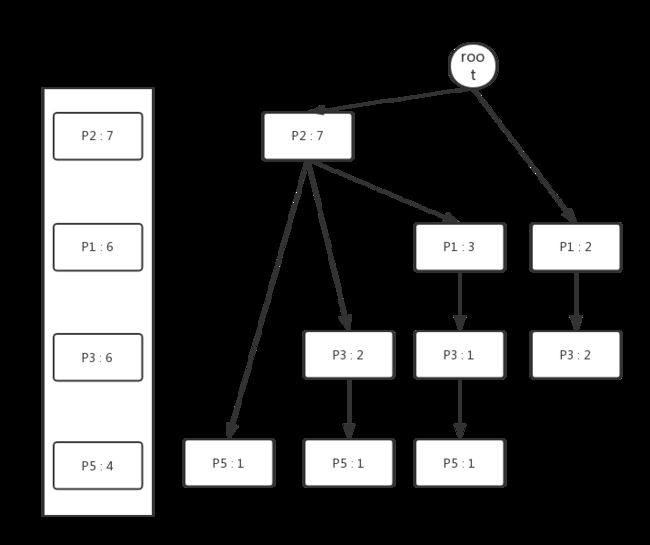
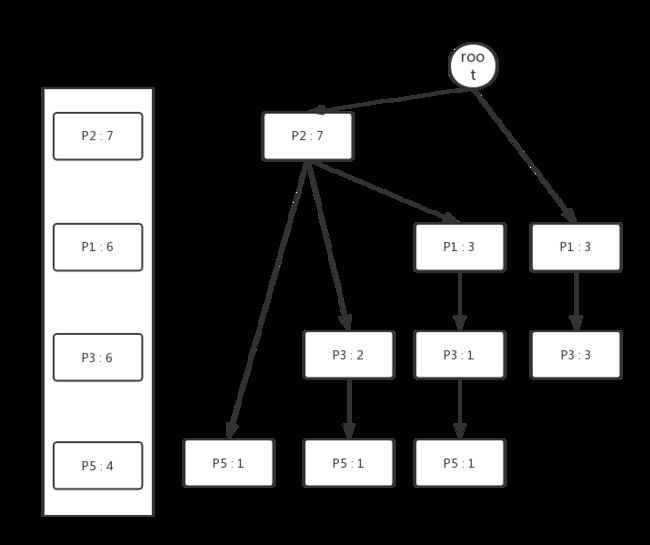
从Header Table出发,将每个相同的属性串在同一条链表上,最终我们可以得到如下结构的FP Tree。
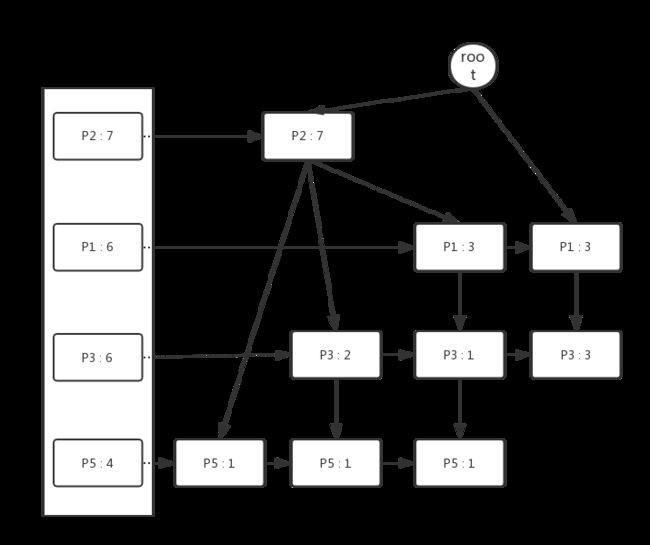
step 3. 挖掘频繁项集
从FP树中抽取频繁项集的三个步骤:
(1) 从FP树中获得条件模式基
(2)利用每个频繁项集的条件模式基,构建一颗条件FP树
迭代重复步骤(1),(2),直到树包含一个元素项为止
条件模式基: 以所查找元素项为结尾的路径集合,每一条路径都是一条前缀路径。 根据上图挖掘的FP-Tree的结果,我们可以得到如下的条件模式基。
| 频繁项 | 前缀路径 |
|---|---|
| p2 | {}7 |
| p1 | {p2}3, {}3 |
| p3 | {p2}2, {p2,p1}1, {p1}3 |
| p5 | {p2}1, {p2,p3}1, {p2,p1,p3}1 |
结果:
{p2},{p1},{p3},{p5}
{p2, p1},
{p2,p3},{p1,p3}
{p2,p5}
算法实现:
应用
关联规则挖掘技术已经被广泛应用在西方金融行业企业中,它可以成功预测银行客户需求。一旦获得了这些信息,银行就可以改善自身营销。银行天天都在开发新的沟通客户的方法。各银行在自己的ATM机上就捆绑了顾客可能感兴趣的本行产品信息,供使用本行ATM机的用户了解。如果数据库中显示,某个高信用限额的客户更换了地址,这个客户很有可能新近购买了一栋更大的住宅,因此会有可能需要更高信用限额,更高端的新信用卡,或者需要一个住房改善贷款,这些产品都可以通过信用卡账单邮寄给客户。当客户打电话咨询的时候,数据库可以有力地帮助电话销售代表。销售代表的电脑屏幕上可以显示出客户的特点,同时也可以显示出顾客会对什么产品感兴趣。
再比如市场的数据,它不仅十分庞大、复杂,而且包含着许多有用信息。随着数据挖掘技术的发展以及各种数据挖掘方法的应用,从大型超市数据库中可以发现一些潜在的、有用的、有价值的信息来,从而应用于超级市场的经营。通过对所积累的销售数据的分析,可以得出各种商品的销售信息。从而更合理地制定各种商品的定货情况,对各种商品的库存进行合理地控制。另外根据各种商品销售的相关情况,可分析商品的销售关联性,从而可以进行商品的货篮分析和组合管理,以更加有利于商品销售。
同时,一些知名的电子商务站点也从强大的关联规则挖掘中的受益。这些电子购物网站使用关联规则中规则进行挖掘,然后设置用户有意要一起购买的捆绑包。也有一些购物网站使用它们设置相应的交叉销售,也就是购买某种商品的顾客会看到相关的另外一种商品的广告。
但是在我国,“数据海量,信息缺乏”是商业银行在数据大集中之后普遍所面对的尴尬。金融业实施的大多数数据库只能实现数据的录入、查询、统计等较低层次的功能,却无法发现数据中存在的各种有用的信息,譬如对这些数据进行分析,发现其数据模式及特征,然后可能发现某个客户、消费群体或组织的金融和商业兴趣,并可观察金融市场的变化趋势。可以说,关联规则挖掘的技术在我国的研究与应用并不是很广泛深入。
参考:https://www.cnblogs.com/en-heng/p/5719101.html
https://baike.baidu.com/item/关联分析/1198018?fr=aladdin
https://www.cnblogs.com/bigmonkey/p/7405555.html