面向Mobile device的CNN模型设计与NAS分析总结,Efficient network design,手工和NAS两种方法
手工方法和NAS的高效网络模型设计总结与分析
这篇文章主要关注对于移动端,资源受限平台的高效神经网络设计(Manually)和搜索(NAS)。
高效的CNN设计不只是用在服务器,云端,资源充足的设备上,也逐渐迁移应用到mobile devices,robotics等。这些平台具有内存有限,计算资源一定,对应用延迟敏感等特点。最近的一些文章,已经从耗时,耗资源的大型模型设计,关注到具体能够在mobile device上实际work起来的轻量级模型设计上。本文稍微总结一下efficient mobile-size models的设计和发展。(逐渐更新,一次性就不罗列出所有model了。)
基于手工设计的,包括MobileNet v1,v2;然后是stage-wise的NAS:MnasNet;接着MobileNet V3在MnasNet的基础上,先进行stage-wise的block搜索,然后在进行layer-wise的微调。EfficientNet也是和MnasNet一样,block-wsie的搜索。这几篇论文,全是来自Google的一个团队,同一批人。随后,Facebook-Berkeley也基于NAS,搜索出了一些高效的应用于mobile device的模型。包括layer-wise的FBNet,模型自适应的ChamNet。本文主要思想是efficient network design,方法有manually design和platform-aware NAS。
-
1. MobileNet V1,V2,V3。
MobileNet V1和V2是人工设计的。
- MobileNet V1
MobileNet V1第一次采用 depthwise separable convolution来大幅度降低FLOPs和parameters。depthwise separable convolution 是采用一个depthwise convolution,接着一个1![]() 1 pointwise convolution。这是17年的一个创新。当大家都在关注,如何设计更powerful的模型(不太在乎参数量,计算量,模型大小),来在各类任务上取得相对更好的state-of-the-art的效果,MobileNet V1在更小的模型,面向mobile devices的网络结构设计上,开了先河,开辟思路。
1 pointwise convolution。这是17年的一个创新。当大家都在关注,如何设计更powerful的模型(不太在乎参数量,计算量,模型大小),来在各类任务上取得相对更好的state-of-the-art的效果,MobileNet V1在更小的模型,面向mobile devices的网络结构设计上,开了先河,开辟思路。
论文名称:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
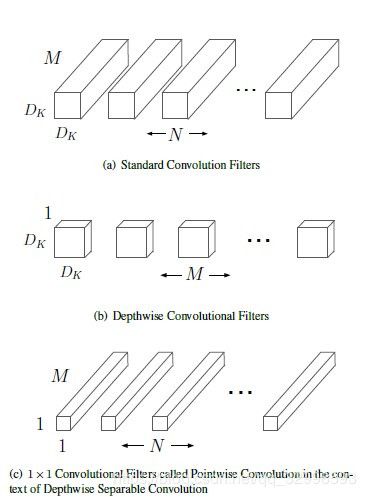 图1:标准卷积与depthwise separable convolution的对比。
图1:标准卷积与depthwise separable convolution的对比。
- MobileNet V2
MobileNet V2主要设计了inverted residual block和linear bottleneck结构,来进一步降低了FLOPs和parameters。其中inverted residual block先采用1![]() 1 pointwise convolution将输入扩张到更深的中间层,expansion factor = t (文章设置为6),然后采用3
1 pointwise convolution将输入扩张到更深的中间层,expansion factor = t (文章设置为6),然后采用3![]() 3 depthwise convolution,最后在用一个linear的1
3 depthwise convolution,最后在用一个linear的1![]() 1 pointwise convolution将较深的中间层压缩到原始的输入。
1 pointwise convolution将较深的中间层压缩到原始的输入。
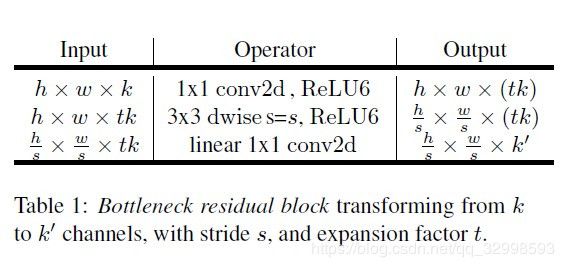 图2:bottleneck residual block的计算步骤分析。
图2:bottleneck residual block的计算步骤分析。
基于这个模块构建的架构,能够进一步在内存有限的手机上实现目标分类,目标检测等功能。
论文名称:MobileNetV2: Inverted Residuals and Linear Bottlenecks
 图:3:residual block和inverted residual block的比较。
图:3:residual block和inverted residual block的比较。
- MobileNet V3
MobileNet V3,首先采用platform-aware NAS,进行block-wise的搜索。建立accuracy ACC(m)和 latency LAT(m)的多目标函数,采用强化学习搜索出一个global network 架构。其实就是搜索出几个block,以及每个block的固定模块。这和MnasNet类似。(作者也说了,就是按照MnasNet来进行搜索的,然后再微调)。其中,一个大的stage,也叫做block,里面有2,3,4~~或者更多层,每一层的操作都是固定的,采用inverted residual bottleneck block,就是图4所示的模型 。然后,采用NetAdapt 进行互补搜索,这一步是layer-wise操作。在NAS搜索的大框架下面,对每一个block里面的每一层的output channels, expansion layer channels进行具体最优的通道数量搜索。其中,对MobileNet V2的基础模块进行了改进,在inverted residual 模块中加入了Squeeze-and-Excite模块,这是一个轻量级注意力机制的模块,能够增强卷积模块的特征提取性能。然后,对激活函数进行了改造。前两个模型,MobileNet V1和MobileNet V2,没有对激活函数进行改造,直接采用的ReLU。而V3,采用了硬件计算友好的h-swish非线性函数,这是对swish函数的modified。最后评测了在CPU和GPU上的运行时间。
主要模块和结构的示意图如下:
 图4:MobileNet V3的基础模块。
图4:MobileNet V3的基础模块。
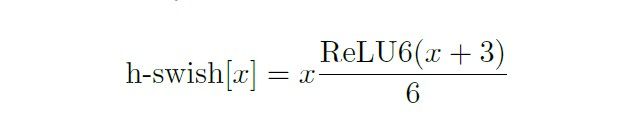 图5:文章中使用广泛的激活函数:h-swish。
图5:文章中使用广泛的激活函数:h-swish。
最终,MobileNet V3 large 和small两个版本,在实际的Google Pixel 手机上的latency,模型的精度,以及参数量上,都取得了很好的效果。图6展示了MobileNet 系列的对比:模型的整体精度提升较大,latency相对较低。
 图6:MobileNet V3在Google P1手机上实际运行延迟对比。
图6:MobileNet V3在Google P1手机上实际运行延迟对比。
论文名称:Searching for MobileNetV3
-
2. MnasNet
MnasNet,block-wise,也可以称为stage-wise搜索。是采用基于强化学习的Platform-Aware mobile-size NAS:automated mobile neural architecture search。直接将实际手机运行latency与accuracy指标,来作为reward,进行训练。
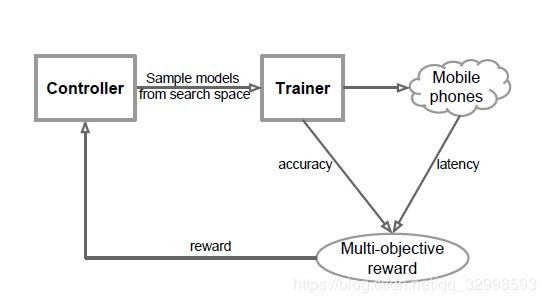 图7: Platform-Aware的NAS流程图,即MnasNet的搜索过程。
图7: Platform-Aware的NAS流程图,即MnasNet的搜索过程。
移动端大小的NAS,最重要的是搜索空间的预定义。MnasNet提出了Factorized Hierarchical Search Space,将搜索空间层次化分解。思想是,将搜索空间定义为一个block,然后将搜索的block连接起来。每一个block内的operator是固定的,但是不同的block内部的layer,也可以叫operator,是不同的。这种方法,降低了搜索空间复杂度。每一个block需要搜索的内容如下:
- convolution operations:包括regular conv,depthwise conv,inverted residual and bottleneck block(MobileNet V2的模块)。
- kernel size:3
 3,55 。
3,55 。 - Squeeze-and-excitation ratio:0,0.25。0的时候,表示不采用SE模块,不加注意力机制。0.25,就是标准的注意力机制。压缩为0.25,在扩展回来。
- Skip operations: pooling, identity residual,no skip。这个不用多解释。
- output filters size:也就是输出channel数。
- Number of layers per blocks:blocks中的layer数量。
注意,block的数量是预先定义好的,也就是说基本的skeleton是定义好的。文章设定为7。因此,每个block的layer不同,但是同一个block的layer操作相同。整体想法如图8所示。
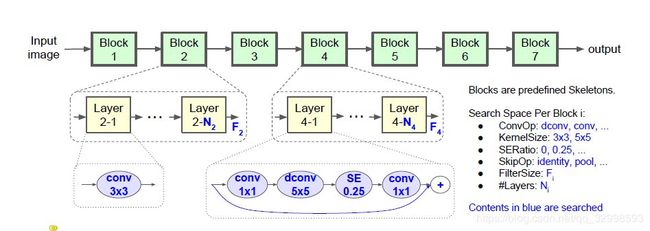 图8:Factorized Hierarchical Search Space,搜索的内容和结构图。
图8:Factorized Hierarchical Search Space,搜索的内容和结构图。
这种方法比简单的cell-based的效果较好,cell-based,只搜索一个cell,然后在重复的堆叠起来,整个网络的每一个cell相同。网络的每一层或者每一个block没有多样性。搜索结果如图9所示。
 图9:MnasNet-A1的结构图。每一个block的操作不同,但同一个block的layer操作相同。
图9:MnasNet-A1的结构图。每一个block的操作不同,但同一个block的layer操作相同。
从图9可以看出,MnasNet的每一个block都不尽相同,有separable conv,有MBConv6,MBConv3等。而且,每一个block的layer不同,有1,2,3,4,2,3,1等不同层。MobileNet V3就是在此基础上,在对每一个block中的每一层进行单独优化。
论文名称:MnasNet: Platform-Aware Neural Architecture Search for Mobile
-
3. EfficientNet and others.
EfficientNet,除了上面一系列的优化的模型,还有EfficientNet,采用MobileNet V2的基础block,来进行搜索。这里不再考虑实际的latency,而是将FLOPs和memory作为目标函数。搜索出了EfficientNet-B0,然后进行混合模型尺度调整。主要探究的是不同尺度对模型性能的影响。最后发现,通过调节depth,width,resolution来共同搜索出满足不同条件的模型。
 图10:搜索优化的目标函数
图10:搜索优化的目标函数
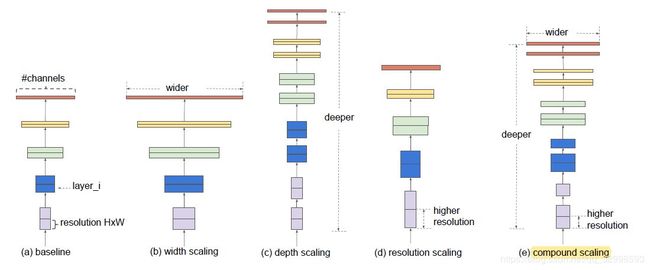 图11:模型尺度变换的方法,有width,depth,resolution,本文采用混合尺度伸缩方法。
图11:模型尺度变换的方法,有width,depth,resolution,本文采用混合尺度伸缩方法。
最后也是取得了promising的结果。所提出的方法,探究了不只是block的单独搜索,cell的堆叠,也包括了对得到的模型,进行三个尺度方面的调整,还能进一步提升性能。
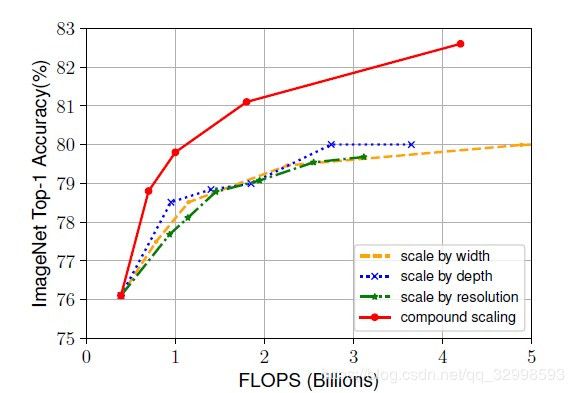 图12:三个尺度单独改变与混合尺度的性能比较
图12:三个尺度单独改变与混合尺度的性能比较
从图12可以看出来,混合尺度的调节比三个尺度的单一调节性能更好。
论文名称:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
还有很大一部分work,包括ShuffleNet V1,V2,Proxyless Net,CondenseNet等,一系列针对resource-constrained platform的优化。
未完待续!!!
感觉将manually的efficient网络设计和基于NAS的efficient网络搜索,放在一起,内容会太多了,篇幅太长了,也许看起来会让然很疲惫。我想一想分两篇讲还是就在这一个文章总结完。