Open Relation Extraction: Relational Knowledge Transfer论文解析
Open Relation Extraction: Relational Knowledge Transfer from Supervised Data to Unsupervised Data
Abstract
- 多数的OpenRE问题都限定在了unsupervised的模式中,没有利用Knowledge Base中的知识和标注数据。
- 所以提出RSN,学习预定义relation中的相似metric,并迁移至新的关系中进行识别。(学习relation中的共性,通过共性来判断两个entity是否存在某种relation的关系。)
Introduction
- relation extraction专注于抽取出实体之间的关系,其实就是relation classification。现在越来越多的方法使用训练数据集(因为DL的广泛使用和进步)。
- 也有非常多的人研究如何使用更少的标注数据去进行RE,例如boot strapping 类型的semi-supervised learning. distant supervision等等。但这些都只能抽取预定义的relation
- OpenRE尝试在开放领域的文本中抽取未被预定义的relation。Banko(2008 首次提出open information extraction) 直接将句子中出现的短语作为关系。e.g. received
- 也有一些人尝试用 unsupervised方法,聚类来解决问题,然而大多数的聚类都是unsupervised。很难筛选出中有用的relation和滤去不相关的relation
- 预定义的relation和全新的relation之间存在着一定的gap,因此我们提出了RSN网络,从预定义的类别和标注数据中抽取出relation指标,通过这个可迁移的relation metric来度量两个entity之间是否存在relation(这是这篇文章最核心的观点,两个domain之间的relation存在gap,需要transfer的去measure
- 此外作者的RSN也可以用于semi-supervised 和distantly-supervised training paradigm.
在list自己的contribution的时候,作者也提到了自己是所知的第一个提出knowledge transfer的概念的
Related Work
- OpenRE 可以被分为几个简单的类别:tagging-based & cluster-based,但是tagging-based经常会面对提取出过于细粒度的relation(relation是有层级的)。cluster-based往往需要非常多的feature,语义模式(e.g. noun-verb-noun)等信息。
few shot learning中的learning image metric启发了我们使用siamese network 去学习relation中的metric
Methodology
主要是两个component:
- relation similarity calculation module: RSN 判断两个句子是否是同一类的relation
- relation similarity clustering module:hierarchical agglomerative clustering (HAC) and Louvain clustering algorithms. 聚类出target relation.
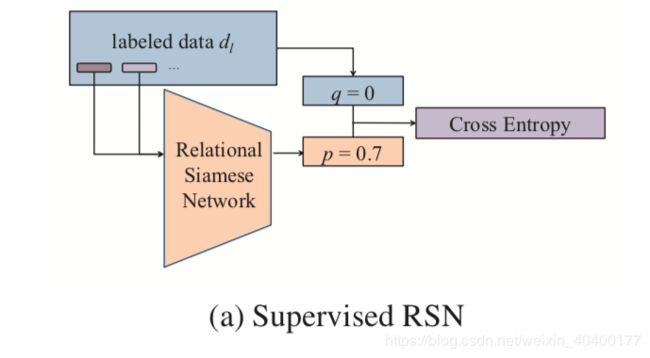
Relational Siamese Network (RSN)
- 每一个word representation 有word embedding和随机初始化的position embedding2014 Zeng,
CNN作为sentence encoder
这边的Siamese network share同样的parameter
v = C N N ( s ) (1) v = CNN(s) \tag{1} v=CNN(s)(1)
其中 s s s 是sentence, v v v是通过CNN encoder之后,得到的relation sentence representation
因此,度量两个relation sentence的distance:
v d = ∣ v l − v r ∣ (2) v_{d} = |v_{l} - v_{r}| \tag{2} vd=∣vl−vr∣(2)
再将计算所得的distance v d v_{d} vd
通过一个简单的linear并且让sigmoid归一化至[0, 1]区间,即可得到相似的probability p p p
p = σ ( kv d + b ) (3) p = \sigma(\textbf{kv}_d+b) \tag{3} p=σ(kvd+b)(3)
L l = E d l ∼ D l [ q l n ( p θ ( d l ) ) + ( 1 − q ) l n ( 1 − p θ ( d l ) ) ] (4) \mathcal{L_l} = \mathbb{E}_{d_l \sim D_l}[ qln(p_θ(d_l))+(1−q)ln(1−p_θ(d_l))] \tag{4} Ll=Edl∼Dl[qln(pθ(dl))+(1−q)ln(1−pθ(dl))](4)
其中 θ \theta θ是所有可训练的参数, d l d_l dl对应一个属于 D l D_l Dl数据集中的 data pair
使用的是cross entropy loss,即仅有0 1两个label而已。非常简单
Semi-supervised RSN
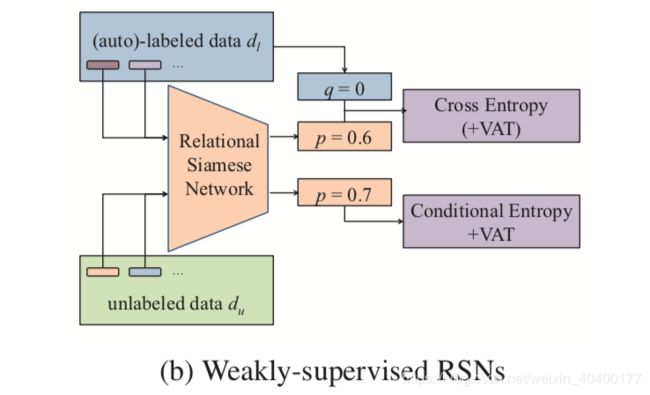
unlabeled dataset为 D u D_u Du unlabeled data pair 为 d u d_u du
semi-supervised RSN没有非常多的labeled data,需要使用大量的unlabeled data。所以一个比较好的决策是将所有在semantic space中的embedding尽可能的远离decision boundary(0/1 决策边界,是否属于同一类relation? )
此处使用conditional entropy loss Grandvalet and Bengio, 2005 来解决问题,文中表达的意思为: It’s safe to increase the margin of decision boundary.
直觉上说,在 p p p=0.5时,两个sentence中,至少有一个接近decision boundary(其实我觉得这个直觉没有那么的strong…抽空和坐我后面的作者聊一下…)
草图如下:
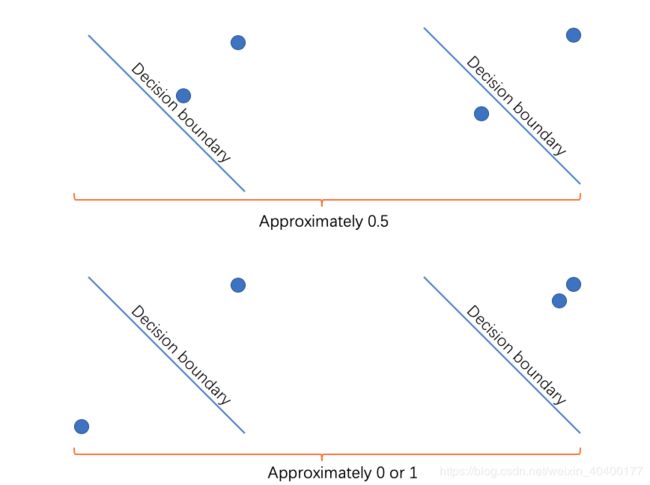
如果两个点reverse也一样可以得出结论
因此接近decision boundary是非常不利于聚类或者使用RSN度量的。因此Loss修改为:
L u = E d u ∼ D u [ d u l n ( p θ ( d u ) ) + ( 1 − d u ) l n ( 1 − p θ ( d u ) ) ] (5) \mathcal{L_u} = \mathbb{E}_{d_u \sim D_u}[ d_uln(p_θ(d_u))+(1−d_u)ln(1−p_θ(d_u))] \tag{5} Lu=Edu∼Du[duln(pθ(du))+(1−du)ln(1−pθ(du))](5)
注意式4中的 q q q已经不见了,因为此处使用的是unlabeled data
Virtual Adversarial Loss
由于神经网络的超强拟合能力,使用了conditional entropy loss(式5) 也许会使网络学习出一个非常复杂的超平面,导致所有的training data全部远离decision boundary. 针对这个问题又使用了virtual adversarial lossMiyato et al., 2016,搜索每一个在超平面上的data point的neighbor points,并且使得sharp change不会发生(也就是超平面变化更为平滑,否则一个离群点或者一个离群的pair就会导致RSN构成的超平面变化非常巨大)
使用 unlabled data训练的Virtual adversarial loss为 L v u \mathcal{L}_{vu} Lvu
所以,semi-supervised learning RSN的 L \mathcal{L} L为
L a l l = L l + λ v L v l + λ u ( L u + λ v L v u ) (6) \mathcal{L}_{all} = \mathcal{L}_l + \lambda_v\mathcal{L}_{vl}+\lambda_u(\mathcal{L}_{u}+\lambda_v\mathcal{L}_{vu}) \tag{6} Lall=Ll+λvLvl+λu(Lu+λvLvu)(6)
其中 λ v \lambda_v λv和 λ u \lambda_u λu都是可调的超参数
Distantly-supervised RSN
Distantly-supervised RSN 可以从unlabeled data以及Distantly-supervised data中学习
具体来说,label为:
L a l l = L l + λ u ( L u + λ v L v u ) (7) \mathcal{L}_{all} = \mathcal{L}_l + \lambda_u(\mathcal{L}_{u}+\lambda_v\mathcal{L}_{vu}) \tag{7} Lall=Ll+λu(Lu+λvLvu)(7)
此处直接将auto-labeled data(也就是distant supervised data)当作labeled data来进行处理,移除adv loss的labeled data的原因是因为会加重错误label的数据对模型的影响(很自然,会算两遍,当然有问题)
作者认为不需要其他去噪的方法因为RSN本身就能够tolerate这些噪音数据(wrong labeled data in distant supervision)
- negative samples 才是数据中的大部分内容,不会影响太多
- 其次真正做new relation detect的时候,重点在与密集的cluster区域,那些噪音数据不会影响太多。
上述三类训练RSN的方法适用于不同的场景,训练出来的RSN一定会结合聚类方法来进行使用!
Open Relation Clustering
训练出来的RSN会用于计算两个包含relation的 sentence之间的similarity。
Hierarchical Agglomerative Clustering
HAC是一个自底向上的聚类方法,首先将每一个instance都作为一类,通过计算距离来将instance合成一类。距离的计算方法是使用 complete-linkage criterion
然而HAC很难决定什么时候停止聚类,一般是通过设置distance阈值,但是这个阈值也非常很确定。而且这个方法有很大的缺点是,只有可能存在了一些cluster之后,才可以开始聚类。因此作者引入第二个聚类方法
Louvain
Louvain是基于图的聚类方法,通常用于community detection。 此处作者使用如果两个instance之间的similarity 为0,那么就代表这两个instance之间有一个edge(我感觉是1才代表了有一条edge?需要去看一下Louvain的原论文,才应该有更确切的解释)。通过构建graph来使用Louvain。此外Louvain也不需要有potential clusters之后才可以去使用。直接使用即可
实验证明了Louvain perform better than HAC
Experiments
实验是在FewRel 和FewRel-distant上进行的,效果非常好
Future Work
- 会尝试使用其他的sentence encoder。
- 以及思考relation中的层级关系