AdaBoost算法原理详细总结
在集成学习方法之Bagging,Boosting,Stacking篇章中,我们谈论boosting框架的原理,在boosting系列算法中,AdaBoost是著名的算法之一。AdaBoost是英文"Adaptive Boosting"(自适应增强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。
今天我们就来探讨下AdaBoost分类算法的原理,本篇我们先介绍AdaBoost算法;然后通过误差分析探讨AdaBoost为什么能提升模型的学习精度;并且从前向分步加法模型角度解释AdaBoost;最后对AdaBoost的算法优缺点进行一个总结。
1)从boosting到AdaBoost算法
集成原理中,我们提到的boosting框架的思想是选择同质的基分类器,让基分类器之间按照顺序进行训练,并让每个基分类器都尝试去修正前面的分类。既然这样,怎样才能让同质的基分类器能够修正前面的分类?或者说怎样才能让同质的基分类器之间保持“互助”呢?
AdaBoost的做法是,让前一个基分类器 f t − 1 ( x ) f_{t-1}(x) ft−1(x)在当前基分类器 f t ( x ) f_t(x) ft(x)的训练集上的效果很差(和我们随机瞎猜一样),这样 f t ( x ) f_t(x) ft(x)就能修正 f t − 1 ( x ) f_{t-1}(x) ft−1(x)的分类误差, f t ( x ) f_t(x) ft(x)和 f t − 1 ( x ) f_{t-1}(x) ft−1(x)之间也就产生了“互助”。
AdaBoost的具体做法是,通过提高被前一轮基分类器 f t − 1 ( x ) f_{t-1}(x) ft−1(x)分类错误的样本的权值,降低被正确分类样本的权值,使得上一个基分类器 f t − 1 ( x ) f_{t-1}(x) ft−1(x)在更新权值后的训练集上的错误率 ϵ t − 1 \epsilon_{t-1} ϵt−1增大到0.5。(再在更新权值后的训练集上训练基分类器 f t ( x ) f_t(x) ft(x),那 f t ( x ) f_t(x) ft(x)必能和 f t − 1 ( x ) f_{t-1}(x) ft−1(x)产生互助。)
2)AdaBoost算法
下面我们在二分类问题上介绍AdaBoost算法。假如给定训练数据集 T = { ( x i , y i ) } i = 1 n T=\left\{ (x^i,y^i) \right\}^n_{i=1} T={(xi,yi)}i=1n, x i ∈ R d x^i\in R^d xi∈Rd, y i ∈ { − 1 , 1 } y^i\in\left\{ -1,1\right\} yi∈{−1,1}
样本权值为 w i n w_i^n win,误差率 ϵ i \epsilon_i ϵi。在训练数据集 T T T上训练第一个基分类器 f 1 ( x ) f_1(x) f1(x),其错误率为 ϵ 1 , ϵ 1 < 0.5 \epsilon_1,\epsilon_1 < 0.5 ϵ1,ϵ1<0.5(起码比瞎猜要好一些)
ϵ 1 = ∑ n w 1 n δ ( ( f 1 ( x n ) ≠ y ^ n ) Z 1 Z 1 = ∑ n w 1 n \epsilon_1=\frac{\sum_nw_1^n\delta((f_1(x^n)\neq {\hat y}^n)}{Z_1} \qquad Z_1 = \sum_nw_1^n ϵ1=Z1∑nw1nδ((f1(xn)=y^n)Z1=n∑w1n
更新样本的权值(权值为 w 2 n w_2^n w2n)后的训练集为 T ′ {T}' T′,使得 f 1 ( x ) f_1(x) f1(x)在 T ′ {T}' T′分类效果等同于随机瞎猜( ϵ = 0.5 \epsilon=0.5 ϵ=0.5)。用数学语言表示即为
∑ n w 2 n δ ( ( f 1 ( x n ) ≠ y ^ n ) Z 2 = 0.5 Z 2 = ∑ n w 2 n \frac{\sum_nw_2^n\delta((f_1(x^n)\neq {\hat y}^n)}{Z_2}=0.5 \qquad Z_2 = \sum_nw_2^n Z2∑nw2nδ((f1(xn)=y^n)=0.5Z2=n∑w2n
那么样本权重如何更新呢?AdaBoost具体做法是,减小 f 1 ( x ) f_1(x) f1(x)分类正确的样本的权值,权值除以一个常数 d d d,即 w 1 n d 1 \frac{w_1^n}{d_1} d1w1n;增大 f 1 ( x ) f_1(x) f1(x)分类错误的样本的权值,权值乘以一个常数 d d d,即 w 1 n d 1 w_1^nd_1 w1nd1。用数学语言表示即为
{ w 2 n = w 1 n d 1 i f f 1 ( x n ) ≠ y ^ n ) w 2 n = w 1 n d 1 i f f 1 ( x n ) = y ^ n ) \begin{cases} w_2^n = w_1^nd_1 \qquad if \ f_1(x^n)\neq {\hat y}^n)\\ w_2^n = \frac{w_1^n}{d_1} \qquad if \ f_1(x^n)= {\hat y}^n)\\ \end{cases} {w2n=w1nd1if f1(xn)=y^n)w2n=d1w1nif f1(xn)=y^n)
下面我们再回到下式中来,
∑ n w 2 n δ ( ( f 1 ( x n ) ≠ y ^ n ) Z 2 = 0.5 \frac{\sum_nw_2^n\delta((f_1(x^n)\neq {\hat y}^n)}{Z_2}=0.5 Z2∑nw2nδ((f1(xn)=y^n)=0.5
其中, Z 2 = ∑ f 1 ( x n ) ≠ y ^ n w 1 n d 1 + ∑ f 1 ( x n ) = y ^ n w 1 n d 1 Z_2=\sum_{f_1(x^n)\neq {\hat y}^n} w_1^n d_1+\sum_{f_1(x^n)= {\hat y}^n} \frac{w_1^n}{d_1} Z2=∑f1(xn)=y^nw1nd1+∑f1(xn)=y^nd1w1n;当 f 1 ( x n ) ≠ y ^ n f_1(x^n)\neq {\hat y}^n f1(xn)=y^n时, w 2 n = w 1 n d 1 w_2^n = w_1^nd_1 w2n=w1nd1。
将上面两式带入得:
∑ f 1 ( x n ) ≠ y ^ n w 1 n d 1 ∑ f 1 ( x n ) ≠ y ^ n w 1 n d 1 + ∑ f 1 ( x n ) = y ^ n w 1 n d 1 = 0.5 \frac{\sum_{f_1(x^n)\neq {\hat y}^n} w_1^n d_1}{\sum_{f_1(x^n)\neq {\hat y}^n} w_1^n d_1+\sum_{f_1(x^n)= {\hat y}^n} \frac{w_1^n}{d_1}}=0.5 ∑f1(xn)=y^nw1nd1+∑f1(xn)=y^nd1w1n∑f1(xn)=y^nw1nd1=0.5
∑ f 1 ( x n ) = y ^ n w 1 n d 1 = ∑ f 1 ( x n ) ≠ y ^ n w 1 n d 1 \sum_{f_1(x^n)= {\hat y}^n} \frac{w_1^n}{d_1}=\sum_{f_1(x^n)\neq {\hat y}^n} w_1^n d_1 f1(xn)=y^n∑d1w1n=f1(xn)=y^n∑w1nd1
又因为 ϵ 1 = ∑ f 1 ( x n ) ≠ y ^ n w 1 n Z 1 ⇒ ϵ 1 Z 1 = ∑ f 1 ( x n ) ≠ y ^ n w 1 n \epsilon_1=\frac{\sum_{f_1(x^n)\neq {\hat y}^n} w_1^n}{Z_1}\Rightarrow \epsilon_1Z_1=\sum_{f_1(x^n)\neq {\hat y}^n} w_1^n ϵ1=Z1∑f1(xn)=y^nw1n⇒ϵ1Z1=f1(xn)=y^n∑w1n
1 − ϵ 1 = ∑ f 1 ( x n ) = y ^ n w 1 n Z 1 ⇒ ( 1 − ϵ 1 ) Z 1 = ∑ f 1 ( x n ) = y ^ n w 1 n 1-\epsilon_1=\frac{\sum_{f_1(x^n)= {\hat y}^n} w_1^n}{Z_1}\Rightarrow (1-\epsilon_1)Z_1=\sum_{f_1(x^n)= {\hat y}^n} w_1^n 1−ϵ1=Z1∑f1(xn)=y^nw1n⇒(1−ϵ1)Z1=f1(xn)=y^n∑w1n
因此,
∑ f 1 ( x n ) = y ^ n w 1 n d 1 = ∑ f 1 ( x n ) ≠ y ^ n w 1 n d 1 \sum_{f_1(x^n)= {\hat y}^n} \frac{w_1^n}{d_1}=\sum_{f_1(x^n)\neq {\hat y}^n} w_1^n d_1 f1(xn)=y^n∑d1w1n=f1(xn)=y^n∑w1nd1
1 d 1 ∑ f 1 ( x n ) = y ^ n w 1 n = d 1 ∑ f 1 ( x n ) ≠ y ^ n w 1 n \frac{1}{d_1}\sum_{f_1(x^n)= {\hat y}^n} {w_1^n}=d_1\sum_{f_1(x^n)\neq {\hat y}^n} w_1^n d11f1(xn)=y^n∑w1n=d1f1(xn)=y^n∑w1n
1 d 1 ( 1 − ϵ 1 ) Z 1 = d 1 ϵ 1 Z 1 \frac{1}{d_1}(1-\epsilon_1)Z_1=d_1\epsilon_1Z_1 d11(1−ϵ1)Z1=d1ϵ1Z1
d 1 = 1 − ϵ 1 ϵ 1 d_1=\sqrt{\frac{1-\epsilon_1 }{\epsilon_1}} d1=ϵ11−ϵ1
其中 d 1 > 1 d_1>1 d1>1(因为 ϵ 1 < 0.5 \epsilon_1<0.5 ϵ1<0.5)。
因此AdaBoost每次更新权值表达式为:
{ w t + 1 n = w t n 1 − ϵ t ϵ t = w t n e x p ( L n ( 1 − ϵ t ϵ t ) ) i f f t ( x n ) ≠ y ^ n ) w t + 1 n = w t n 1 − ϵ t ϵ t = w t n e x p ( − L n ( 1 − ϵ t ϵ t ) ) i f f t ( x n ) = y ^ n ) \begin{cases} w_{t+1}^n = w_t^n\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}=w_t^nexp(Ln(\sqrt{\frac{1-\epsilon_t }{\epsilon_t}})) \qquad if \ f_t(x^n)\neq {\hat y}^n)\\ w_{t+1}^n = \frac{w_t^n}{\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}}=w_t^nexp(-Ln(\sqrt{\frac{1-\epsilon_t }{\epsilon_t}})) \qquad if \ f_t(x^n)= {\hat y}^n)\\ \end{cases} ⎩⎪⎨⎪⎧wt+1n=wtnϵt1−ϵt=wtnexp(Ln(ϵt1−ϵt))if ft(xn)=y^n)wt+1n=ϵt1−ϵtwtn=wtnexp(−Ln(ϵt1−ϵt))if ft(xn)=y^n)
令 α t = L n ( 1 − ϵ t ϵ t ) \alpha_t= Ln(\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}) αt=Ln(ϵt1−ϵt), α t \alpha_t αt即为基分类器 f t ( x ) f_t(x) ft(x)的权重系数。当 ϵ t = 0.1 \epsilon_t =0.1 ϵt=0.1时, α t = 1.1 \alpha_t=1.1 αt=1.1,当 ϵ t = 0.4 \epsilon_t =0.4 ϵt=0.4时, α t = 0.2 \alpha_t=0.2 αt=0.2。这表明,当基分类器分类误差率越小时,基分类器的权重越大,在最终表决时起的作用也越大;当基分类器分类误差率越大时,基分类器的权重越小,在最终表决时起的作用也越小。将 α t \alpha_t αt带入上式,样本权值更新表达式变成:
{ w t + 1 n = w t n 1 − ϵ t ϵ t = w t n e x p ( α t ) i f f t ( x n ) ≠ y ^ n ) w t + 1 n = w t n 1 − ϵ t ϵ t = w t n e x p ( − α t ) i f f t ( x n ) = y ^ n ) \begin{cases} w_{t+1}^n = w_t^n\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}=w_t^nexp(\alpha_t) \qquad if \ f_t(x^n)\neq {\hat y}^n)\\ w_{t+1}^n = \frac{w_t^n}{\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}}=w_t^nexp(-\alpha_t) \qquad if \ f_t(x^n)= {\hat y}^n)\\ \end{cases} ⎩⎨⎧wt+1n=wtnϵt1−ϵt=wtnexp(αt)if ft(xn)=y^n)wt+1n=ϵt1−ϵtwtn=wtnexp(−αt)if ft(xn)=y^n)
为了方便表示,将上式两项合并成一项得,权值更新的表达式为:
w t + 1 n = w t n e x p ( − y ^ n f t ( x n ) α t ) w_{t+1}^n =w_t^nexp(-{\hat y}^nf_t(x^n)\alpha_t) wt+1n=wtnexp(−y^nft(xn)αt)
当 f t ( x n ) = y ^ n f_t(x^n)= {\hat y}^n ft(xn)=y^n时, y ^ n f t ( x n ) {\hat y}^nf_t(x^n) y^nft(xn)为+1,当 f t ( x n ) ≠ y ^ n \ f_t(x^n)\neq {\hat y}^n ft(xn)=y^n时, y ^ n f t ( x n ) {\hat y}^nf_t(x^n) y^nft(xn)为-1,以上两式为等价变换。
以上就是AdaBoost算法如何做样本权值更新的整个推导过程。
下面对二元分类AdaBoost算法流程进行总结:
输入:训练数据集 T = { ( x i , y i ) } i = 1 N T=\left\{ (x^i,y^i) \right\}^N_{i=1} T={(xi,yi)}i=1N, x i ∈ R d x^i\in R^d xi∈Rd, y i ∈ { − 1 , 1 } y^i\in\left\{ -1,1\right\} yi∈{−1,1}
输出:最终的分类器 H ( x ) H(x) H(x)
①初始化训练数据的权值(权值相等)
w 1 n = 1 w_1^n=1 w1n=1
② f o r t = 1... T : for \ t=1...T: for t=1...T:
-
在权值为 { w t 1 , w t 2 . . . w t N } \left\{ w_t^1,w_t^2...w_t^N\right\} {wt1,wt2...wtN}的训练机上训练基分类器 f t ( x ) f_t(x) ft(x)
-
计算 f t ( x ) f_t(x) ft(x)在训练数据集上的分类误差率 ϵ t \epsilon_t ϵt ϵ t = P ( f t ( x n ≠ y ^ n ) ) = ∑ n w t n δ ( f t ( x n ≠ y ^ n ) ) \epsilon_t=P(f_t(x^n\neq {\hat y}^n))=\sum_nw_t^n\delta (f_t(x^n\neq {\hat y}^n)) ϵt=P(ft(xn=y^n))=n∑wtnδ(ft(xn=y^n))
-
计算 f t ( x ) f_t(x) ft(x)的权值系数
α t = L n ( 1 − ϵ t ϵ t ) \alpha_t= Ln(\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}) αt=Ln(ϵt1−ϵt) -
f o r n = 1 , 2.... N : for \ n=1,2....N: for n=1,2....N:
i f x n 被 f t ( x ) 分 类 错 误 : if \ x^n 被f_t(x)分类错误: if xn被ft(x)分类错误:
w t + 1 n = w t n 1 − ϵ t ϵ t = w t n e x p ( α t ) w_{t+1}^n= w_t^n\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}=w_t^nexp(\alpha_t) wt+1n=wtnϵt1−ϵt=wtnexp(αt)
e l s e x n else \ x^n else xn 被 f t ( x ) f_t(x) ft(x)分类正确:
w t + 1 n = w t n 1 − ϵ t ϵ t = w t n e x p ( − α t ) w_{t+1}^n = \frac{w_t^n}{\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}}=w_t^nexp(-\alpha_t) wt+1n=ϵt1−ϵtwtn=wtnexp(−αt)
③构建基分类器线性组合
f ( x ) = ∑ T α t f t ( x ) f(x)=\sum_T\alpha_tf_t(x) f(x)=T∑αtft(x)
得到最终的分类器 H ( x ) H(x) H(x)
H ( x ) = s i g n ( ∑ T α t f t ( x ) ) H(x)=sign(\sum_T\alpha_tf_t(x)) H(x)=sign(T∑αtft(x))
3)AdaBoost的训练误差分析
AdaBoost最基本的性质是它能在学习的过程中不断减少训练误差,且训练误差以指数速率下降,且无限逼近于0。具体的数学表达式为:
E r r o r R a t e = 1 N ∑ δ ( y ^ n g ( x ) < 0 ) ≤ 1 N ∑ n e x p ( − y ^ n g ( x ) ) = 1 N Z T + 1 Error Rate=\frac{1}{N}\sum \delta (\hat y^n g(x)<0)\leq \frac{1}{N}\sum_nexp(-\hat y^n g(x))=\frac{1}{N}Z_{T+1} ErrorRate=N1∑δ(y^ng(x)<0)≤N1n∑exp(−y^ng(x))=N1ZT+1
1 N Z T + 1 = ∏ t = 1 T 2 ϵ t ( 1 − ϵ t ) = ∏ t = 1 T ( 1 − 4 γ t 2 ) ≤ e x p ( − 2 ∑ t = 1 T γ t 2 ) \frac{1}{N}Z_{T+1}=\prod _{t=1}^T2\sqrt{\epsilon _t(1-\epsilon _t)}=\prod _{t=1}^T\sqrt{(1-4\gamma _t^2)}\leq exp(-2\sum _{t=1}^T\gamma _t^2) N1ZT+1=t=1∏T2ϵt(1−ϵt)=t=1∏T(1−4γt2)≤exp(−2t=1∑Tγt2)
其中, γ t = 1 2 − ϵ t \gamma_t=\frac{1}{2}-\epsilon _t γt=21−ϵt。
下面我们就AdaBoost做二元分类的情况,对这一结论分步进行证明。证明过程会涉及较多的数学公式的推导,对证明不感兴趣的小伙伴可以直接跳到第5部分AdaBoost算法总结。
首先我们证明:
E r r o r R a t e = 1 N ∑ δ ( y ^ n g ( x ) < 0 ) ≤ 1 N e x p ( − y ^ n g ( x ) ) Error Rate=\frac{1}{N}\sum \delta (\hat y^n g(x)<0)\leq \frac{1}{N}exp(-\hat y^n g(x)) ErrorRate=N1∑δ(y^ng(x)<0)≤N1exp(−y^ng(x))
从上一部分内容可知,训练数据集 T = { ( x i , y i ) } i = 1 n T=\left\{ (x^i,y^i) \right\}^n_{i=1} T={(xi,yi)}i=1n, x i ∈ R d x^i\in R^d xi∈Rd, y i ∈ { − 1 , 1 } y^i\in\left\{ -1,1\right\} yi∈{−1,1},最终的分类器 H ( x ) , α t H(x),\alpha_t H(x),αt的表达式为
H ( x ) = s i g n ( ∑ t = 1 T α t f t ( x ) ) α t = L n ( 1 − ϵ t ϵ t ) H(x)=sign(\sum_{t=1}^T\alpha_tf_t(x)) \qquad \alpha_t = Ln(\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}) H(x)=sign(t=1∑Tαtft(x))αt=Ln(ϵt1−ϵt)
分类器 H ( x ) H(x) H(x)的分类误差率为 E r r o r R a t e Error Rate ErrorRate等于分类错误的样本所占总样本的比例,用数学语言表达即为,
E r r o r R a t e = 1 N ∑ δ ( H ( x n ) ≠ ( y ^ ) n ) Error Rate=\frac{1}{N}\sum \delta (H(x^n)\neq (\hat y)^n) ErrorRate=N1∑δ(H(xn)=(y^)n)
其中, H ( x n ) ≠ ( y ^ ) n H(x^n)\neq (\hat y)^n H(xn)=(y^)n表示模型的预测值和真实值异号,因此,
E r r o r R a t e = 1 N ∑ δ ( y ^ n ∑ t = 1 T α t f t ( x ) < 0 ) Error Rate=\frac{1}{N}\sum \delta (\hat y^n \sum_{t=1}^T\alpha_tf_t(x)<0) ErrorRate=N1∑δ(y^nt=1∑Tαtft(x)<0)
令 g ( x ) = ∑ t = 1 T α t f t ( x ) g(x)=\sum_{t=1}^T\alpha_tf_t(x) g(x)=∑t=1Tαtft(x),因此,
E r r o r R a t e = 1 N ∑ δ ( y ^ n g ( x ) < 0 ) Error Rate=\frac{1}{N}\sum \delta (\hat y^n g(x)<0) ErrorRate=N1∑δ(y^ng(x)<0)
下面我们开始证明:
E r r o r R a t e = 1 N ∑ δ ( y ^ n g ( x ) < 0 ) ≤ 1 N e x p ( − y ^ n g ( x ) ) Error Rate =\frac{1}{N}\sum \delta (\hat y^n g(x)<0)\leq \frac{1}{N}exp(-\hat y^n g(x)) ErrorRate=N1∑δ(y^ng(x)<0)≤N1exp(−y^ng(x))
其中 δ ( y ^ n g ( x ) < 0 ) \delta (\hat y^n g(x)<0) δ(y^ng(x)<0)为01损失函数, e x p ( − y ^ n g ( x ) ) exp(-\hat y^n g(x)) exp(−y^ng(x))为指数损失函数。画出函数图像很容易发现上式不等式成立: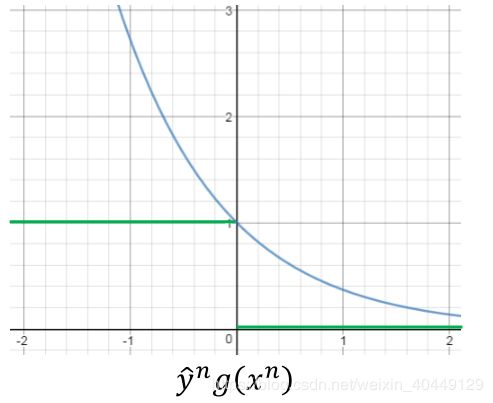
下面我们证明
E r r o r R a t e ≤ 1 N ∑ n e x p ( − y ^ n g ( x ) ) = 1 N Z T + 1 Error Rate\leq \frac{1}{N}\sum_nexp(-\hat y^n g(x))=\frac{1}{N}Z_{T+1} ErrorRate≤N1n∑exp(−y^ng(x))=N1ZT+1
已知 g ( x ) = ∑ t = 1 T α t f t ( x ) g(x)=\sum_{t=1}^T\alpha_tf_t(x) g(x)=∑t=1Tαtft(x)(上面我们定义的等式)。且 Z t + 1 Z_{t+1} Zt+1为基分类器 f t + 1 ( x ) f_{t+1}(x) ft+1(x)所有训练样本的权重之和,用数学语言表示,
Z t + 1 = ∑ n w T + 1 n Z_{t+1}=\sum _nw_{T+1}^n Zt+1=∑nwT+1n
= ∑ n w T n e x p ( − y ^ n f t ( x n ) α t ) =\sum _nw_{T}^nexp(-\hat y^nf_t(x^n)\alpha_t) =∑nwTnexp(−y^nft(xn)αt)(权值更新公式)
= ∑ n ∏ t = 1 T e x p ( − y ^ n f t ( x n ) α t ) =\sum _n\prod _{t=1}^Texp(-\hat y^nf_t(x^n)\alpha_t) =∑n∏t=1Texp(−y^nft(xn)αt)
= ∑ n e x p ( − y ^ n ∑ t = 1 T f t ( x n ) α t ) =\sum _nexp(-\hat y^n\sum _{t=1}^Tf_t(x^n)\alpha_t) =∑nexp(−y^n∑t=1Tft(xn)αt)(连乘符号 ∏ \prod ∏,放到指数 e x p exp exp中变成求和 ∑ \sum ∑)
= ∑ n e x p ( − y ^ n g ( x n ) ) =\sum _nexp(-\hat y^ng(x^n)) =∑nexp(−y^ng(xn))
因此, E r r o r R a t e ≤ 1 N ∑ n e x p ( − y ^ n g ( x ) ) = 1 N Z T + 1 Error Rate\leq \frac{1}{N}\sum_nexp(-\hat y^n g(x))=\frac{1}{N}Z_{T+1} ErrorRate≤N1n∑exp(−y^ng(x))=N1ZT+1
已知 α t = L n ( 1 − ϵ t ϵ t ) \alpha_t = Ln(\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}) αt=Ln(ϵt1−ϵt),下面我们证明
E r r o r R a t e ≤ 1 N Z T + 1 = ∏ t = 1 T 2 ϵ t ( 1 − ϵ t ) Error Rate\leq \frac{1}{N}Z_{T+1}=\prod _{t=1}^T2\sqrt{\epsilon _t(1-\epsilon _t)} ErrorRate≤N1ZT+1=t=1∏T2ϵt(1−ϵt)
Z t + 1 Z_{t+1} Zt+1为基分类器 f t + 1 ( x ) f_{t+1}(x) ft+1(x)所有训练样本的权重之和,它是由上一轮权值 Z t Z_{t} Zt更新而来的,被分类错误的样本权值增大,被分类正确的样本权值减小。
且 Z 1 = N Z_1=N Z1=N,因此,
Z T + 1 = Z t ϵ t e x p ( α t ) + Z t ( 1 − ϵ t ) e x p ( − α t ) Z_{T+1}=Z_t \epsilon _{t}exp(\alpha _{t})+Z_t(1-\epsilon _{t})exp(-\alpha _{t}) ZT+1=Ztϵtexp(αt)+Zt(1−ϵt)exp(−αt)
= Z t ϵ t 1 − ϵ t ϵ t + Z t ( 1 − ϵ t ) ϵ t 1 − ϵ t =Z_t \epsilon _{t}\sqrt{\frac{1-\epsilon _{t}}{\epsilon _{t}}}+Z_t(1-\epsilon _{t})\sqrt{\frac{\epsilon _{t}}{1-\epsilon _{t}}} =Ztϵtϵt1−ϵt+Zt(1−ϵt)1−ϵtϵt
= 2 Z t ϵ t ( 1 − ϵ t ) =2Z_t\sqrt{\epsilon _{t}(1-\epsilon _{t})} =2Ztϵt(1−ϵt)
= N ∏ t = 1 T 2 ϵ t ( 1 − ϵ t ) =N\prod _{t=1}^T2\sqrt{\epsilon _{t}(1-\epsilon _{t})} =N∏t=1T2ϵt(1−ϵt)
因此,
E r r o r R a t e ≤ 1 N Z T + 1 = ∏ t = 1 T 2 ϵ t ( 1 − ϵ t ) Error Rate\leq \frac{1}{N}Z_{T+1}=\prod _{t=1}^T2\sqrt{\epsilon _t(1-\epsilon _t)} ErrorRate≤N1ZT+1=t=1∏T2ϵt(1−ϵt)
由于 ϵ t < 0.5 \epsilon _t<0.5 ϵt<0.5,因此 2 ϵ t ( 1 − ϵ t ) ≤ 1 2\sqrt{\epsilon _t(1-\epsilon _t)}\leq 1 2ϵt(1−ϵt)≤1,所以AdaBoost的分类误差率是不断的再减小的。
下面我们证明
∏ t = 1 T 2 ϵ t ( 1 − ϵ t ) = ∏ t = 1 T ( 1 − 4 γ t 2 ) ≤ e x p ( − 2 ∑ t = 1 T γ t 2 ) \prod _{t=1}^T2\sqrt{\epsilon _t(1-\epsilon _t)}=\prod _{t=1}^T\sqrt{(1-4\gamma _t^2)}\leq exp(-2\sum _{t=1}^T\gamma _t^2) t=1∏T2ϵt(1−ϵt)=t=1∏T(1−4γt2)≤exp(−2t=1∑Tγt2)
∏ t = 1 T 2 ϵ t ( 1 − ϵ t ) \prod _{t=1}^T2\sqrt{\epsilon _t(1-\epsilon _t)} ∏t=1T2ϵt(1−ϵt)
= ∏ t = 1 T 2 ( 1 2 − ( 1 2 − ϵ t ) ) ( 1 2 + 1 2 − ϵ t ) =\prod _{t=1}^T2\sqrt{(\frac{1}{2}-(\frac{1}{2}-\epsilon _t))(\frac{1}{2}+\frac{1}{2}-\epsilon _t)} =∏t=1T2(21−(21−ϵt))(21+21−ϵt)
令 γ t = 1 2 − ϵ t \gamma_t=\frac{1}{2}-\epsilon _t γt=21−ϵt, γ t > 0 \gamma_t >0 γt>0得,
∏ t = 1 T 2 ϵ t ( 1 − ϵ t ) \prod _{t=1}^T2\sqrt{\epsilon _t(1-\epsilon _t)} ∏t=1T2ϵt(1−ϵt)
= ∏ t = 1 T 2 ( 1 2 − ( 1 2 − ϵ t ) ) ( 1 2 + 1 2 − ϵ t ) =\prod _{t=1}^T2\sqrt{(\frac{1}{2}-(\frac{1}{2}-\epsilon _t))(\frac{1}{2}+\frac{1}{2}-\epsilon _t)} =∏t=1T2(21−(21−ϵt))(21+21−ϵt)
= ∏ t = 1 T 2 1 4 − γ t 2 =\prod _{t=1}^T2\sqrt{\frac{1}{4}-\gamma _t^2} =∏t=1T241−γt2
= ∏ t = 1 T 1 − 4 γ t 2 =\prod _{t=1}^T\sqrt{1-4\gamma _t^2} =∏t=1T1−4γt2
最后我们证明,
∏ t = 1 T ( 1 − 4 γ t 2 ) ≤ e x p ( − 2 ∑ t = 1 T γ t 2 ) \prod _{t=1}^T\sqrt{(1-4\gamma _t^2)}\leq exp(-2\sum _{t=1}^T\gamma _t^2) t=1∏T(1−4γt2)≤exp(−2t=1∑Tγt2)
首先我们构造一个函数 f ( x ) = e − x + x − 1 f(x)=e^{-x}+x-1 f(x)=e−x+x−1,由于 f ′ ′ ( x ) = e − x > 0 f''(x)=e^{-x}>0 f′′(x)=e−x>0,因此 f ( x ) f(x) f(x)为凸函数,且 m i n f ( x ) = f ( 0 ) = 0 minf(x)=f(0)=0 minf(x)=f(0)=0,所以 f ( x ) ≥ 0 f(x) \geq 0 f(x)≥0。下面我们进入正式证明:
f ( x ) = e − x + x − 1 ≥ 0 f(x)=e^{-x}+x-1 \geq 0 f(x)=e−x+x−1≥0
⇒ e − x ≥ 1 − x \Rightarrow e^{-x}\geq 1-x ⇒e−x≥1−x,令 x = 4 γ 2 x=4\gamma^2 x=4γ2,得
⇒ e − 4 γ 2 ≥ 1 − 4 γ 2 \Rightarrow e^{-4\gamma^2}\geq 1-4\gamma^2 ⇒e−4γ2≥1−4γ2
⇒ e − 2 γ 2 ≥ 1 − 4 γ 2 \Rightarrow e^{-2\gamma^2}\geq \sqrt{1-4\gamma^2} ⇒e−2γ2≥1−4γ2
因此对于 t = 1 , 2... T t=1,2...T t=1,2...T,都有 { e − 2 γ 1 2 ≥ 1 − 4 γ 1 2 e − 2 γ 2 2 ≥ 1 − 4 γ 2 2 . . . e − 2 γ t 2 ≥ 1 − 4 γ t 2 \begin{cases} e^{-2\gamma_1^2}\geq \sqrt{1-4\gamma_1^2}\\ e^{-2\gamma_2^2}\geq \sqrt{1-4\gamma_2^2}\\ ...\\ e^{-2\gamma_t^2}\geq \sqrt{1-4\gamma_t^2}\\ \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧e−2γ12≥1−4γ12e−2γ22≥1−4γ22...e−2γt2≥1−4γt2
将上式连乘得:
⇒ ∏ t = 1 T e x p ( − 2 γ t 2 ) ≥ ∏ t = 1 T 1 − 4 γ t 2 \Rightarrow\prod _{t=1}^Texp(-2\gamma_t^2) \geq \prod _{t=1}^T \sqrt{1-4\gamma_t^2} ⇒t=1∏Texp(−2γt2)≥t=1∏T1−4γt2
⇒ ∏ t = 1 T 1 − 4 γ t 2 ≤ ∏ t = 1 T e x p ( − 2 γ t 2 ) \Rightarrow\prod _{t=1}^T \sqrt{1-4\gamma_t^2}\leq \prod _{t=1}^Texp(-2\gamma_t^2) ⇒t=1∏T1−4γt2≤t=1∏Texp(−2γt2)
⇒ ∏ t = 1 T 1 − 4 γ t 2 ≤ e x p ( − 2 ∑ t = 1 T γ t 2 ) \Rightarrow \prod _{t=1}^T \sqrt{1-4\gamma_t^2}\leq exp(-2\sum _{t=1}^T\gamma_t^2) ⇒t=1∏T1−4γt2≤exp(−2t=1∑Tγt2)
因此,证明得到下式成立:
E r r o r R a t e = 1 N ∑ δ ( y ^ n g ( x ) < 0 ) ≤ e x p ( − 2 ∑ t = 1 T γ t 2 ) Error Rate=\frac{1}{N}\sum \delta (\hat y^n g(x)<0)\leq exp(-2\sum _{t=1}^T\gamma_t^2) ErrorRate=N1∑δ(y^ng(x)<0)≤exp(−2t=1∑Tγt2)
上不等式表明,AdaBoost的训练误差是以指数速率下降且无限逼近于0。( γ > 0 , − 2 ∑ t = 1 T γ t 2 < 0 \gamma >0,-2\sum _{t=1}^T\gamma_t^2<0 γ>0,−2∑t=1Tγt2<0,小于0的数求指数小于1,小于1的数无限连乘,将无限逼近与0)
4)前向分步加法模型解释AdaBoost
AdaBoost的另外一种解释,认为AdaBoost是加法模型、损失函数为指数函数、学习算法为前向分步算法的分类学习算法。
加法模型比较好理解,最终的分类器是有若干个基分类器加权平均得到。即
H ( x ) = ∑ T α t f t ( x ) H(x)=\sum_T\alpha_tf_t(x) H(x)=T∑αtft(x)
其中, f t ( x ) f_t(x) ft(x)为基分类器, α t \alpha_t αt为基分类器的权值。
前向分步学习算法,即利用前一个基分类器的结果更新后一个基分类器的训练权重。
假定第 t − 1 t-1 t−1轮后分类器为:
g t − 1 ( x ) = ∑ t = 1 t − 1 α t f t ( x ) g_{t-1}(x)= \sum_{t=1}^{t-1}\alpha_tf_t(x) gt−1(x)=t=1∑t−1αtft(x)
而第 t t t轮后分类器为为:
g t ( x ) = ∑ t = 1 t α t f t ( x ) g_{t}(x)= \sum_{t=1}^{t}\alpha_tf_t(x) gt(x)=t=1∑tαtft(x)
有上两式可以得:
g t ( x ) = g t − 1 ( x ) + α t f t ( x ) g_t(x)=g_{t-1}(x)+\alpha_tf_t(x) gt(x)=gt−1(x)+αtft(x)
因此,最终的分类器是通过前向学习算法得到的。
AdaBoost的损失函数为,
a r g m i n ⏟ α , f ∑ n e x p ( − y ^ n g t ( x ) ) \underbrace{argmin}_{\alpha,f}\sum_nexp(-\hat y^n g_t(x)) α,f argminn∑exp(−y^ngt(x))
利用前向分步学习算法可以得到损失函数为:
( α t , f t ( x ) ) = a r g m i n ⏟ α , f ∑ n e x p ( − y ^ n ( g t − 1 ( x ) + α t f t ( x ) ) (\alpha_t,f_t(x))= \underbrace{argmin}_{\alpha,f}\sum_nexp(-\hat y^n (g_{t-1}(x)+\alpha_tf_t(x)) (αt,ft(x))=α,f argminn∑exp(−y^n(gt−1(x)+αtft(x))
令 w t ′ n = e x p ( − y ^ n g t − 1 ( x ) ) w'^n_t=exp(-\hat y^n g_{t-1}(x)) wt′n=exp(−y^ngt−1(x)),它的值不依赖 α t , f t ( x ) \alpha_t,f_t(x) αt,ft(x),因此与最小化无关,仅仅依赖于 g t − 1 ( x ) g_{t-1}(x) gt−1(x),随着每一轮迭代而改变。将上式子代入损失函数,得
( α t , f t ( x ) ) = a r g m i n ⏟ α , f ∑ n w t ′ n e x p ( − y ^ α t f t ( x ) ) (\alpha_t,f_t(x))= \underbrace{argmin}_{\alpha,f}\sum_n w'^n_texp(-\hat y \alpha_tf_t(x)) (αt,ft(x))=α,f argminn∑wt′nexp(−y^αtft(x))
我们先求 f t ∗ ( x ) f^*_t(x) ft∗(x),对于任意的 α t > 0 \alpha_t>0 αt>0,使得上式最小的 f t ( x ) f_t(x) ft(x)由下式得到:
f t ∗ ( x ) = a r g m i n ⏟ f w t ′ n δ ( y ^ n ≠ f t ( x n ) ) f^*_t(x)=\underbrace{argmin}_fw_t'^n\delta (\hat y^n \neq f_t(x^n)) ft∗(x)=f argminwt′nδ(y^n=ft(xn))
其中, w t ′ n = e x p ( − y ^ n g t − 1 ( x ) ) w'^n_t=exp(-\hat y^n g_{t-1}(x)) wt′n=exp(−y^ngt−1(x))。
基分类器 f t ∗ ( x ) f^*_t(x) ft∗(x)即为AdaBoost算法的基分类器 f t ( x ) f_t(x) ft(x),因为它是让第 t t t轮加权训练数据分类误差率最小的基分类器。将 f t ∗ ( x ) f^*_t(x) ft∗(x)带入损失函数,对 α t \alpha_t αt求导,使其等于0,得
α t = 1 2 L n 1 − ϵ t ϵ t \alpha_t = \frac{1}{2}Ln\frac{1-\epsilon _t}{\epsilon _t} αt=21Lnϵt1−ϵt
其中 ϵ t \epsilon _t ϵt为分类误差率:
ϵ t = ∑ n w t ′ n δ ( y ^ n ≠ f t ( x n ) ) ∑ n w t ′ n = ∑ n w t n δ ( y ^ n ≠ f t ( x n ) ) \epsilon _t=\frac{\sum _nw'^n_t\delta (\hat y^n \neq f_t(x^n))}{\sum_n w'^n_t}=\sum _nw_t^n\delta (\hat y^n \neq f_t(x^n)) ϵt=∑nwt′n∑nwt′nδ(y^n=ft(xn))=n∑wtnδ(y^n=ft(xn))
这与我们在第二部分讨论的一致(见下式)。上式的 w t n w^n_t wtn为权值率,下式中的 w t n w^n_t wtn为权值,除以 Z 1 Z_1 Z1等价于权值率。
ϵ 1 = ∑ n w 1 n δ ( ( f 1 ( x n ) ≠ y ^ n ) Z 1 Z 1 = ∑ n w 1 n \epsilon_1=\frac{\sum_nw_1^n\delta((f_1(x^n)\neq {\hat y}^n)}{Z_1} \qquad Z_1 = \sum_nw_1^n ϵ1=Z1∑nw1nδ((f1(xn)=y^n)Z1=n∑w1n
α t = L n ( 1 − ϵ t ϵ t ) \alpha_t= Ln(\sqrt{\frac{1-\epsilon_t }{\epsilon_t}}) αt=Ln(ϵt1−ϵt)
最后我们来看下每一轮权值的更新,利用以下两式
g t ( x ) = g t − 1 ( x ) + α t f t ( x ) g_t(x)=g_{t-1}(x)+\alpha_tf_t(x) gt(x)=gt−1(x)+αtft(x)
w t ′ n = e x p ( − y ^ n g t − 1 ( x ) ) w'^n_t=exp(-\hat y^n g_{t-1}(x)) wt′n=exp(−y^ngt−1(x))
可得到权值更新公式为:
w t + 1 n = w t n e x p ( − y ^ n f t ( x n ) α t ) w_{t+1}^n =w_t^nexp(-{\hat y}^nf_t(x^n)\alpha_t) wt+1n=wtnexp(−y^nft(xn)αt)
这与我们在第一部分讨论的权值更新公式也一致。因此,AdaBoost也可以从加法模型、指数损失函数、前向分步学习算法角度来解释。
需要注意的是,是先有了AdaBoost算法之后,人们才发现,通过加法模型、指数损失函数、前向分步学习算法的方式可以解释AdaBoost算法的过程。
5)AdaBoost算法总结
下面我们对AdaBoost算法的优缺点进行总结。
优点:
- 既可以处理分类任务,又可以处理回归任务;
- 不易过拟合;
- AdaBoost训练的分类器,分类精度高;
- 支持各种分类器做基分类器,如逻辑回归,SVM;
缺点: - 对异常值敏感,异常值的权重在模型训练的过程中可能会越来越大,最终影响整个模型的性能;
终于写完了,这篇写的有点长,涉及的数学推导比较多,我也尽量往详细写了,大家需要一些耐心慢慢看。如果看到数学推导就头晕的小伙伴,可以只看第二部分AdaBoost算法原理部分。本篇涉及的数学公式较多,我也多检查了两遍,尽量减少数学上的表述错误。如果小伙伴发现还有错误,还望指正!
下篇我们探讨Scikit learn中的AdaBoost算法库类,并进行实践。
(欢迎大家在评论区探讨交流,也欢迎大家转载,转载请注明出处!)
上篇:Scikit-learn随机森林算法库总结与调参实践
下篇:持续更新中,敬请关注