题外话: 第一次做全文翻译,翻译不好请谅解,多多给予意见。最近在看DDC,顺便就把这篇文章翻译一下。
摘要
最近的报告表明,在大规模数据集上训练的通用监督深度cnn模型可以减少但不消除对标准基准数据集的偏差。在新的领域中对深度模型进行微调可能需要大量的数据,对于许多应用程序来说,这些数据都是不可用的。我们提出了一种新的cnn体系结构,它引入了一个适应层和一个额外的域混淆损失,学习一种既具有语义意义又具有域不变的表示。此外,我们还显示,可以使用域混淆度量来进行模型选择,以决定适应层的尺寸和在CNN架构中的层的最佳位置。我们提出的自适应方法提供了超过先前公布的结果的经验性能。 在标准基准上视觉领域适配任务。
介绍
数据集偏差 是传统的有监督的图像识别方法中一个众所周知的问题。最近的一些理论和经验结果表明,监督方法的测试误差随测试和训练输入分布之间的差异而增加。在过去的几年中,已经提出了几种用于视觉领域适配的方法, 克服此问题,但仅限于浅层模型。适应深度模型的传统方法是微调;有关最近的示例,请参见。
在少量标记的目标数据上直接微调深度网络的参数是有问题的。幸运的是,经过预先训练的深层模型在新领域确实表现良好。最近, 表明,使用在ImageNet上学习到的深中位特征,而不是更传统的词包特征,有效地消除了某些域自适应集合中的偏差。 在office数据集中。
这些算法将特征从一个大范围内迁移出来。ImageNet,和使用该域中的所有数据作为相应类别的源数据。但是,这些方法无法从深层体系结构中选择特征,而是跨多层选择报告结果。
数据集偏差在计算机视觉中通过托拉尔巴和埃弗罗斯(Torralba and Efros)的“命名数据集”游戏进行了经典的说明。实际上,这被证明与领域差异度量有着正式的连接。 因此,对领域不变性的优化,可以被视为等同于学习预测类标签的任务。当同时找到一个特征时,使得这个领域出现尽可能相似。这一原则构成了我们提议的方法的本质。我们通过优化损失来学习深度特征,这既包括标签数据上的分类误差,也包括域混淆损失。 它试图使域无法区分。
我们提出了一个新的CNN架构(如图1所示),该架构使用自适应层以及基于最大均值差异(MMD)的域混淆损失来自动学习一个特征联合训练优化分类和域不变。我们表明,我们的域混淆度量可以用于选择适应层的尺寸。 在预先训练的CNN架构中,选择一个有效的位置对于一个新的适应层,并对特征进行微调。
我们的体系结构可以用来解决两种1.有监督的适应,当少量标记的目标域数据可用时,和2.无监督自适应,当没有标记的目标训练数据可用时。我们对流行的Office数据集在视觉上不同的领域进行了全面的评估。我们通过对领域混淆和分类的联合优化来证明我们能够显著地超越当前最新的视觉领域适配结果。事实上,对于轻微的姿势、分辨率和照明变化的情况,我们的算法能够在目标域上实现96%的准确率,这表明事实上,我们学到了一种对这些偏差不变的特征。

图1:我们的体系结构为分类损失和域不变性优化了深度CNN。当有少量的目标数据可用时,可以对模型进行监督适应训练。 在没有目标标签可用时。我们通过域混淆引入域不变性,引导自适应层深度和宽度的选择。以及微调期间附加的域损失项,它直接最小化了源和目标特征之间的距离。*
相关工作:
视觉数据集偏差的概念在【无偏查看数据集偏差。在过程中,CVPR,2011。1,2】中得到推广。近年来,人们提出了许多解决视觉领域适应问题的方法。大家都认识到有一个转变在源和目标数据特征的分布中。实际上,领域转换的大小经常通过源和目标子空间特征之间的距离来测量。大量的方法试图通过学习特征空间变换来克服这个差异,以对准源和目标特征。对于监督适应情景来说,当目标域中有限数量的标记数据是可用的时候,提出了一些方法来学习对源分类进行正则化的目标分类器。其他人试图同时学习特征变换并规范目标分类器。
最近,基于监督卷积神经网络(CNN)的特征表示已经被证明是非常有效的各种视觉识别任务。特别的,使用深度表示显着地减少分辨率和照明对域移动的影响。
并行CNN结构,如暹罗网络,已经被证明是有效的学习不变性特征。然而,训练这些网络需要每个训练实例的标签。 因此,还不清楚如何将这些方法扩展到无监督的设置。
多模态深度学习架构也被探索,用以学习对不同输入模态不变的表征。 然而,这种方法主要在生成环境中运作,因此没有提供足够的代表性功能来监督CNN表示。
[Deep learning for domain adaptation by interpolating between domains.]提出了训练联合源和目标CNN架构,但仅限于两层,因此使用更深层架构的方法显著优于[ImageNet classification with deep convolutional neural networks.],在大型辅助数据源上进行了预训练(例如: ImageNet )。
[Domain adaptive neural networks for object recognition]提出了使用去噪自动编码器进行预训练,然后在MMD域混淆损失的同时训练双层网络。 由于学习网络相对较浅,因此缺乏通过直接优化具有监督深度CNN的分类目标而学习的强语义表示,因此这有效地学习了领域不变性特征。
训练基于CNN的域不变表示
我们引入了一种新的卷积神经网络(CNN)架构,我们用它来学习视觉表示,它既是域不变的又提供了强大的语义分离。 已经表明,预训练的CNN可以通过微调来适应新的任务。 但是,在域适应场景中,目标域中很少或没有标记的训练数据,因此我们无法直接微调目标域T中的感兴趣类别C,相反,我们将使用的数据来自一个相关但不同的源域S,其中可以从相应的类别C中获得更多标记的数据。
仅使用源数据直接训练分类器通常会导致对源分布的过拟合,从而导致在目标域中识别时在测试时性能降低。 我们的直觉是,如果我们可以学习最小化源和目标分布之间距离的表示,那么我们可以在源标记的数据上训练分类器,并且直接应用目标域,并且精度损失最小。
为了最小化这个距离,我们考虑标准分布距离度量,最大均值差异(MMD)。该距离是相对于特定的表示φ(·)计算的。 在我们的例子中,我们定义了一个表示,φ(·),它对源数据点进行操作,,和目标数据点,。 该距离的经验近似计算如下:
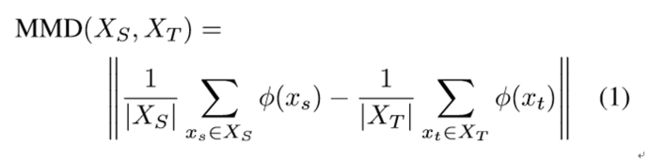
如图2所示,不仅是想要最小化域之间的距离(或最大化域混淆),但我们想要一种有助于训练强大分类器的表示。 这样的表示将使我们能够学习很容易跨域迁移的强大分类器。 满足这两个标准的一种方法是尽量减少损失:
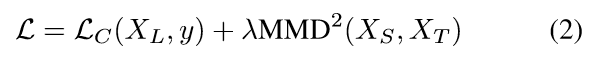
其中LC(XL,y)表示在可用的标签数据XL上的分类损失,和基本真实标签y和MMD(XS,XT)表示源数据XS与目标数据XT之间的距离。 超参数λ决定了我们想要的混淆域的强度。
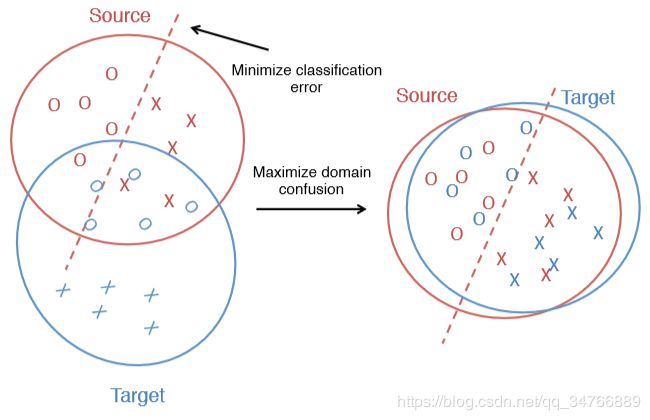
图2:对于偏差数据集(左),在源域中学习的分类不一定能很好地转移到目标域。 通过优化目标,同时最小化分类误差和最大化域混淆(右),我们可以学习具有判别性和域不变性的表示。*
最小化这种损失的一种方法是采用固定的CNN,这已经是一种强有力的分类表示,并且使用来自最小化域分布距离的MMD来决定哪个层使用激活。 然后,我们可以使用这样的特征,以便在其他类别的课程中感到有兴趣进行识别。 这可以被认为是等式2的坐标下降:我们采用一个网络可以经过训练最小化LC,选择最小化MMD的表示,然后根据表示再一次最小化LC.
然而,这种方法是有限的,因为它不能直接适应这个特征 - 相反,它被限制为从一组固定的表示中进行选择。 因此,我们建议创建一个网络来直接优化分类和域混淆目标,如图1所示。
我们从Krizhevsky架构开始,它具有五个卷积层和池化层以及三个全连接层,其尺寸为{4096,4096,| C |}。 我们另外添加了一个较低维度的“瓶颈”适应层。 我们的直觉是,较低维度的层可用于规范源分类器的训练,并防止过度拟合源分布的特定细微差别。 我们将域距离损失置于“瓶颈”层之上,以直接将特征规范化为不同的源和目标域。
必须进行两种模型选择才能添加适应层和域距离损失。 我们必须选择网络中放置适配层的位置,我们必须选择层的尺寸。 我们使用MMD度量来做出这两个决定。 首先,如前所述,对于我们的初始固定表示,我们找到了最小化所有可用源数据和目标数据之间的经验MMD距离的层,在我们的实验中,这对应于将层放置在全连接层fc7之后。
接下来,我们必须确定适应层的尺寸。 我们通过网格搜索解决了这个问题,我们使用各种维度对多个网络进行微调,并在新的低维表示中计算MMD,最终选择最小化源和目标距离的维度。
选择使用哪个特征层(“深度”)和适应层应该有多大(“宽度”)都由MMD引导,因此可以看作是我们整体目标的下降步骤。
我们的架构(参见图1)由源和目标CNN组成,具有共享权重。 仅使用标记的示例来计算分类损失,而从两个域使用所有数据来计算域混淆损失。 这个网络对所有可用的源和目标数据进行联合训练。
方程式2中概述的目标很容易通过该卷积神经网络中的MMD表示,其中MMD是在小批量的源和目标数据上计算的。 我们只需在适应层之后使用网络顶部的分支。 一个分支使用标签数据并训练分类器,其他分支使用所有数据并计算源和目标之间的MMD。
在对这种架构进行微调之后,由于联合损失中的两个项,适应层学习是由于分类损失项而能够有效地区分所讨论的类的表示,同时由于MMD术语仍然保持不变的域迁移。 我们希望这种表示能够提高适应性能。

图3:最大均值差异和测试准确度对于特征层的不同选择。 我们观察到源和目标之间的MMD以及目标域测试集上的准确度似乎是反向相关的,这表明MMD可以用于帮助选择适应层。*
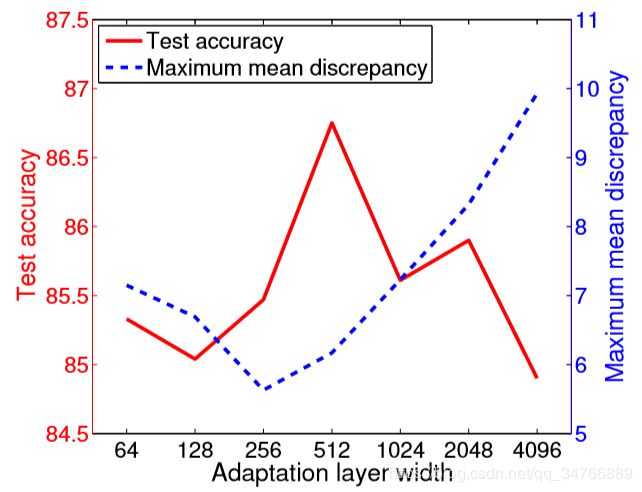
图4:最大均值差异和测试准确度对于适应层维度的不同值。 我们观察到源和目标之间的MMD以及目标域测试集上的准确度与之相反,表明MMD可用于帮助选择要使用的维度。*
评估
我们在具有小规模源域的标准域适应数据集上评估我们的自适应算法。 我们展示了我们的算法能够有效地适应一个深度CNN特征,具有有限或无目标标签数据的目标域。
Office 数据集是来自三个不同域的图像集合:亚马逊,DSLR和网络摄像头。数据集中的31个类别包括常用设置中常见的对象,如键盘,文件柜和笔记本电脑。 最大的域有2817个标记图像。
我们针对通常用于评估的3个传输任务(亚马逊→网络摄像头,数码单反相机→网络摄像头和网络摄像头→数码单反相机)中的每一个,对5个随机的训练/测试集拆分评估我们的方法,并报告每个设置的平均值和标准误差。 我们在监督和无监督情景中与最近发布的六种方法报告的数字进行比较。
我们遵循该数据集的标准训练协议,每个类别使用20个源示例用于Amazon源域,每个类别8个图像用于Webcam或DSLR作为源域[29,16]。 对于监督的适应设置,我们假设每个类别有3个标记的目标示例。
评估适应层位置
我们首先评估我们的特征选择策略。
使用预先训练的卷积神经网络,我们使用每个全连接层的表示从源数据和目标数据中提取特征。然后我们可以计算每层的源和目标之间的MMD。 由于较低的MMD预测该特征更加域不变,我们期望具有最低MMD的呈现以在适应层之后实现最高性能。
为了验证这一假设,对于Amazon→Webcam拆分之一,我们应用Daum'e III 引入的简单域自适应基线来计算目标域的测试精度。 图3显示了不同桥接层选择的MMD和适应性能的比较。 我们看到MMD准确地对特征进行排列,将fc7选为表现最佳的层,将fc6选为最差的。 因此,我们在fc7之后添加我们的适应层用于剩下的实验。
选择适应层的尺寸
通过我们提出的微调方法学习新的特征之前,我们必须决定这种特征有多宽。 同样,我们使用MMD作为决定度量。
为了确定我们学习的适应层应该具有什么维度,我们在Amazon→Webcam任务中训练具有不同宽度的各种网络,因为这是三者中最具挑战性的。 特别是,我们尝试不同的宽度,从64到4096不等,每次乘以两次幂。 一旦网络被训练,我们就为每个学习的特征计算源和目标之间的MMD。 然后,我们的方法是选择最小化源数据和目标数据之间的MMD的尺寸。

表1:使用Office数据集对标准监督适应设置进行多种类别的准确率评估。 我们使用[29]中的标准实验方案对所有31个类别进行评估。 在这里,我们与六种最先进的领域适应方法进行比较。*

表2:使用Office数据集对标准无监督自适应设置进行多种类别准确率评估。 我们使用[16]中的标准实验方案对所有31个类别进行评估。 在这里,我们与六种最先进的领域适应方法进行比较。*
为了验证MMD做出正确的选择,我们再次将MMD与测试集上的性能进行比较。 图4显示我们为适应层选择了256个维度,虽然此设置不是最大化测试性能的设置,但它似乎是一个合理的选择。 特别是,使用MMD可以避免选择性能受损的极端值。 值得注意的是,该情节有相当多的不规则性 - 也许精确的采样将允许更准确的选择。
使用域混淆正则化进行微调
一旦我们确定了我们对适应层尺寸的选择,我们就可以使用第3节中描述的联合损失开始微调。但是,我们需要设置正则化超参数λ。 将λ设置得太低将导致MMD正则化器对学习到的特征没有影响,但是将λ设置得太高将会过度调整并学习退化特征,其中所有点都太靠近在一起。 我们将正则化超参数设置为λ=
0.25,这使得目标主要加权分类,但具有足够的正则化以避免过度拟合。
我们对无监督和监督使用相同的微调架构。 但是,在监督设置中,分类器对来自两个域的数据进行训练,而在无监督设置中,由于缺少有标签的训练数据,分类器仅查看源数据。 在这两种设置中,MMD规范器都可以看到所有数据,因为它不需要标签。
最后,因为适应层和分类器正在从头开始训练,我们将其学习率设置为比从预训练模型复制的网络的较低层高10倍。 然后通过标准反向传播优化进行微调。
监督的适应设置结果如表1所示,无监督的自适应结果如表2所示。我们注意到我们的算法明显优于所有竞争方法。 我们方法的明显改进表明,通过MMD正则化调整学习的适应层能够成功地迁移到新的目标域。
为了确定MMD正则化如何影响学习,我们还在图5中的亚马逊→网络摄像头迁移任务上比较有和没有正则化的学习曲线。我们看到,虽然非正则化的版本最初训练更快,但它很快就开始过度训练, 并且测试精度受到影响。 相比之下,使用MMD正则化防止网络过拟合到源数据,虽然训练需要更长时间,但正则化导致更高的最终测试精度。

图5:对于正则化和非正则化方法的最初700次调整迭代期间无监督的亚马逊→Webcam分割的测试精度图。 虽然最初的非正则化训练可以获得更好的性能,但它可以超过源数据。 相比之下,使用正则化防止过拟合,因此尽管初始学习速度较慢,但我们最终会看到更好的最终性能。*
为了进一步证明我们学习的特征的域不变性,我们在图6中绘制了使用我们学习的表示的亚马逊和网络摄像头图像的t-SNE嵌入,并将其与在预训练模型中用fc7创建的嵌入进行比较。 通过检查嵌入,我们看到我们的特征表示在混合每个簇内的域时表现出更严格的类聚类。 虽然fc7嵌入中存在弱聚类,但我们发现大多数紧密聚类由来自一个域或另一个域的数据点组成,但很少都是。
在office数据集上历史的进步
在图7中,我们报告了自引入标准OFFICE数据集以来的历史进展。 我们指出使用传统特征的方法(例如:SURFBoW)和蓝色圆圈以及使用深红色方形的深度特征的方法。 我们展示了两种适应方案。 第一种方案是视觉上遥远的域(亚马逊→网络摄像头)的监督适应任务。 对于此任务,我们的算法优于DeCAF 3.4%的多类精度。 最后,我们展示了无监督适应相似转换的最艰巨的任务。 在这里,我们表明我们的方法提供了5.5%多类精度的最重要的改进。
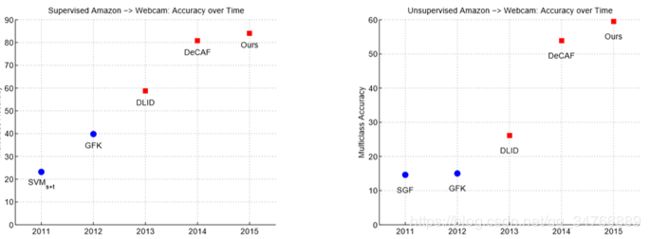
图7:过去几年在标准视觉域适应数据集上的快速进展,结果[29]。 我们在亚马逊→网络摄像头上展示使用传统手工设计的蓝色圆圈视觉表示的方法,使用深度表示的方法用红色方块表示。 对于监督任务,我们的方法实现了84%的多类精度,增加了3%。 对于无监督任务,我们的方法实现了60%的多类精度,增加了6%。*
结论
在本文中,我们提出了一个学习领域不变性特征的目标函数用于分类。 该目标利用额外的域混淆术语来确保在学习的特征中无法区分域。 然后,我们提出了各种方法来优化这一目标,从固定池的简单特征选择到通过反向传播直接最小化目标的完整卷积架构。
我们的完整方法使用MMD来选择体系结构的深度和宽度,同时在微调期间将其用作正则化器,在标准视觉域适应基准测试中实现了最先进的性能,超越了之前相当可观的方法。
这些实验表明,将域混淆项纳入判别特征学习过程是确保学习特征既可用于分类又对域移位不变的有效方法。
致谢
这项工作部分得到了DARPA的MSEE和SMISC计划的支持,NSF奖励了IIS-1427425,IIS-1212798和IIS-1116411,丰田以及伯克利远景和学习中心


图6:亚马逊(蓝色)和网络摄像头(绿色)图像的t-SNE嵌入使用我们基于MMD正则化学习的监督256维特征(左上)和来自预训练模型的原始fc7特征(右下)。 观察由我们的特征形成的聚类分离类别,同时比未训练域不变性的原始特征更有效地混合域。 例如,在fc7-space中,亚马逊监视器和Webcam监视器被分成不同的集群,而使用我们的所学习的特征,所有与域无关的监视器都被混合到同一个集群中。