一、Spark 集群安装
- 修改 spark-env.sh 文件,在该配置文件中添加如下配置
export JAVA_HOME=/usr/java/jdk1.7.0_45
export SPARK_MASTER_IP=node1.itcast.cn
export SPARK_MASTER_PORT=7077
修改 slaves 文件,加入节点。
发送到其他机器,然后启动。
二、启动 spark shell
spark-shell --master spark://node1.itcast.cn:7077 --executor-memory 2g --total-executor-cores 2
参数说明:
- --master spark://node1.itcast.cn:7077 指定Master的地址
- --executor-memory 2g 指定每个worker可用内存为2G
- --total-executor-cores 2 指定整个集群使用的cup核数为2个
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
二、 Spark RDD 编程
RDD 是弹性式分布式数据集,是 spark 对数据的核心抽象。 对 RDD 的操作包括两部分,转换操作(Transfermation)和行动操作(Action)
转换操作会由一个 RDD 生成一个新的 RDD。行动操作会对 RDD 计算出一个结果。 spark 对 RDD 是惰性求值的。转换操作并不会触发实际的 RDD 的计算,只有当第一次执行行动操作时才会计算。
2.1 RDD 的特性
一组分片(Partition. ,即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
一个列表,存储存取每个Partition的优先位置(preferred location. 。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
2.2 创建 RDD 的两种方式
- 通过读取外部数据源加载
val rdd2 = sc.textFile("hdfs://node1.itcast.cn:9000/words.txt")
- 创建集合的方式加载。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
RDD 的两种算子
Transformation
RDD 不会触发真正的计算,只是记录下这些转换的动作,等到触发 Action 时才会提交任务进行计算。
常用的 Transformation 算子
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| map() | 将函数应用于 RDD 的每个元素,将返回值构成新的 RDD | rdd.map(x => x + 1) | {2, 3, 4, 4} |
| flatMap() | 应用于 RDD 的每个元素,返回的迭代器的所有内容构成新的 RDD | rdd.flatMap(x => x.to(3)) | {1, 2, 3, 2, 3, 3, 3} |
| filter() | 过滤 | rdd.filter(x => x!= 1) | {2, 3, 3} |
| distinct() | 去重 | rdd.distinct() | {1, 2, 3} |
对 {1, 2, 3, 3} 的 RDD 进行转化操作
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| map() | 将函数应用于 RDD 的每个元素,将返回值构成新的 RDD | rdd.map(x => x + 1) | {2, 3, 4, 4} |
| flatMap() | 应用于 RDD 的每个元素,返回的迭代器的所有内容构成新的 RDD | rdd.flatMap(x => x.to(3)) | {1, 2, 3, 2, 3, 3, 3} |
| filter() | 过滤 | rdd.filter(x => x!= 1) | {2, 3, 3} |
| distinct() | 去重 | rdd.distinct() | {1, 2, 3} |
对 {1, 2, 3} 和 {3, 4, 5} 进行转化操作
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| union() | 将两个 RDD 合并成一个 RDD | rdd.union(other) | {1, 2, 3, 3, 4, 5} |
| intersection() | 求两个 RDD 中相同的元素 | rdd.intersection(other) | {3} |
| subtract() | 移除一个 RDD 中的内容 | rdd.subtract(other) | {1, 2} |
Action
真正触发计算的算子。
常用的 Action 算子
| 函数名 | 目的 |
|---|---|
| count | 统计rdd中的元素个数 |
| collect | 将集群上的数据拉取到本地进行遍历(不推荐使用) |
| saveAsTextFile | 直接将rdd中的数据保存在hdfs中 |
| take | 将远程rdd的前n个数据拉取到本地 |
三、RDD 的依赖关系
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
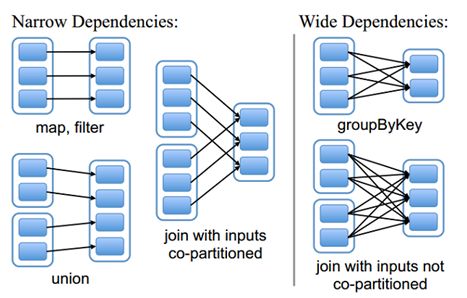
3.1 宽依赖
宽依赖指的是多个子 RDD 的 Partition 会依赖同一个父 RDD 的 Partition。一般情况下需要将宽依赖的算子进行缓存。
会形成宽依赖的算子:
reduceByKey, combineByKey, groupByKey, join, aggregateByKey
3.2 窄依赖
窄依赖指的是每一个父 RDD 的 Partition 最多被子 RDD 的一个 Partition 使用
会形成窄依赖的算子:
map, flatMap, filter, union
注意: 关于 join 的算子,如果每个Partition仅仅和已知的、特定的Partition进行join,那么这个依赖关系也是窄依赖。对于需要parent RDD的所有Partition进行join的转换,也是需要Shuffle,这类join的依赖就是宽依赖而不是前面提到的窄依赖了。
3.3 如何判断是否为宽依赖
- 一般情况下 value 型的算子产生的 RDD 是窄依赖,key-value 型的算子产生的 RDD 是宽依赖。
- 通过调用dependencies来判断是那种分区依赖关系

3.3 将 RDD 划分成宽依赖和窄依赖的原因
首先,narrow dependencies可以支持在同一个cluster node上,以pipeline形式执行多条命令,例如在执行了map后,紧接着执行filter。相反,shuffle / wide dependencies 需要所有的父分区都是可用的,可能还需要调用类似MapReduce之类的操作进行跨节点传递。
其次,则是从失败恢复的角度考虑。 narrow dependencies的失败恢复更有效,因为它只需要重新计算丢失的parent partition即可,而且可以并行地在不同节点进行重计算。相反,shuffle / wide dependencies 牵涉RDD各级的多个parent partition。
3.3 Lineage 血统
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
四、RDD 的缓存
默认情况下 RDD 会在每次行动操作时重新计算。如果想对这个 RDD 进行重用, 可以使用 RDD.persist() 或者 cache() 方法将 RDD 缓存下来,这样就可以重用。但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
持久化缓存的级别
| 级别 | 使用的空间 | CPU 时间 | 是否在内存中 | 是否在磁盘上 | 备注 |
|---|---|---|---|---|---|
| MEMORY_ONLY | 高 | 低 | 是 | 否 | |
| MEMORY_ONLY_SER | 低 | 高 | 是 | 否 | |
| MEMORY_AND_DISK | 高 | 中等 | 部分 | 部分 | 如果内存放不下,溢写到磁盘 |
| MEMORY_AND_DISK_SER | 低 | 高 | 部分 | 部分 | 如果内存放不下,溢写到磁盘,内存中存放序列化后的数据 |
| DISK_ONLY | 低 | 高 | 否 | 是 |
checkpoint
为了防止 RDD 的缓存中的数据丢失,从而导致 RDD 的重算带来的巨大开销。可以将认为比较重要的 RDD 计算的结果进行 checkpoint,这样会将计算得到的结果写入到分布式文件系统中,如 HDFS。==建议在调用 checkpoint 之前先将 RDD 的结果 cache 一下。==
注意:checkpoint 之后 RDD 的所有依赖关系将会被删除,恢复数据将会从 HDFS 中读取文件进行恢复,RDD 的依赖关系将会重新开始计算。