
深度学习的模型有很多,但是考虑到移动端的硬件限制,并不是所有模型都适合移植,在这里整理一下适合移植的模型。
图片


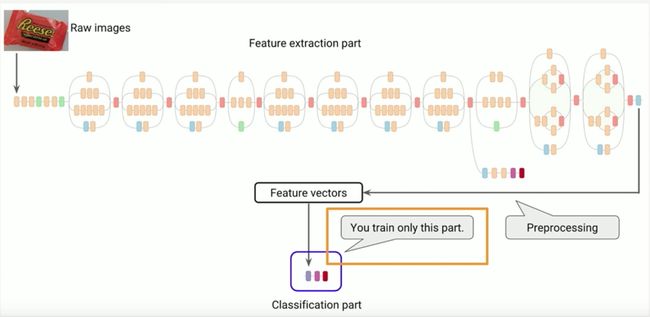
“冻结”计算图
train.py 将计算图定义保存在了 .pb 文件当中。遗憾的是,大家无法直接将该计算图加载至应用当中。完整的计算图中包含的操作目前还不受TensorFlow C++/Java API的支持。正因为如此,我们才需要使用上图中的工具。其中 freeze_graph 负责获取 .pb 以及包含有 w 与 b 训练结果值的 checkpoint 文件。其还会移除一切在移动端之上不受支持的操作。
在 tensorflow 目录下运行该工具:
bazel-bin/tensorflow/python/tools/freeze_graph \
--input_graph=/tmp/voice/graph.pb --input_checkpoint=/tmp/voice/model \
--output_node_names=model/y_pred,inference/inference --input_binary \
--output_graph=/tmp/voice/frozen.pb
以上命令将在 frozen.pb 当中创建一套经过简化的计算图,其仅具备 y_pred 与 inference 两个节点,不包含任何用于训练的计算图节点。
使用 freeze_graph 的好处在于,其还将固定该文件中的权重值,这样大家就无需分别进行权重值加载了:frozen.pb中已经包含我们需要的一切。而 optimize 工具则负责对计算图进行进一步简化。其将作为 grozen.pb 文件的输入内容,并写入 inference.pb 作为输出结果。我们随后会将此文件嵌入至应用当中。使用以下命令运行该工具:
bazel-bin/tensorflow/python/tools/optimize_for_inference \
--input=/tmp/voice/frozen.pb --output=/tmp/voice/inference.pb \
--input_names=inputs/x --output_names=model/y_pred,inference/inference \
--frozen_graph=True
实现过程
- 了解模型结构(LeNet、AlexNet、VGG、Incetption V3...)
- 在 pc 端做
迁移学习(深度学习训练需要数周时间、迁移学习只需几小时),保存为 pb 模型
注:迁移学习是利用已有模型,在最后一层进行重新分类训练 - 在 pc 端进行简单的模型准确度验证
- 对 pb 模型进行优化、压缩移植到移动端(可以使模型大小减小75%,精度仅略微下降)
- 在移动端恢复模型
- 模型产品化
在移动端要做的事情不多,一般来说,只需完成以下工作:
- 从.pb文件中加载计算图与权重值
- 利用此计算图创建一项会话
- 将您的数据放置在一个输入张量内
- 在一个或者多个节点上运行计算图
- 从输出结果张量中获取结果z
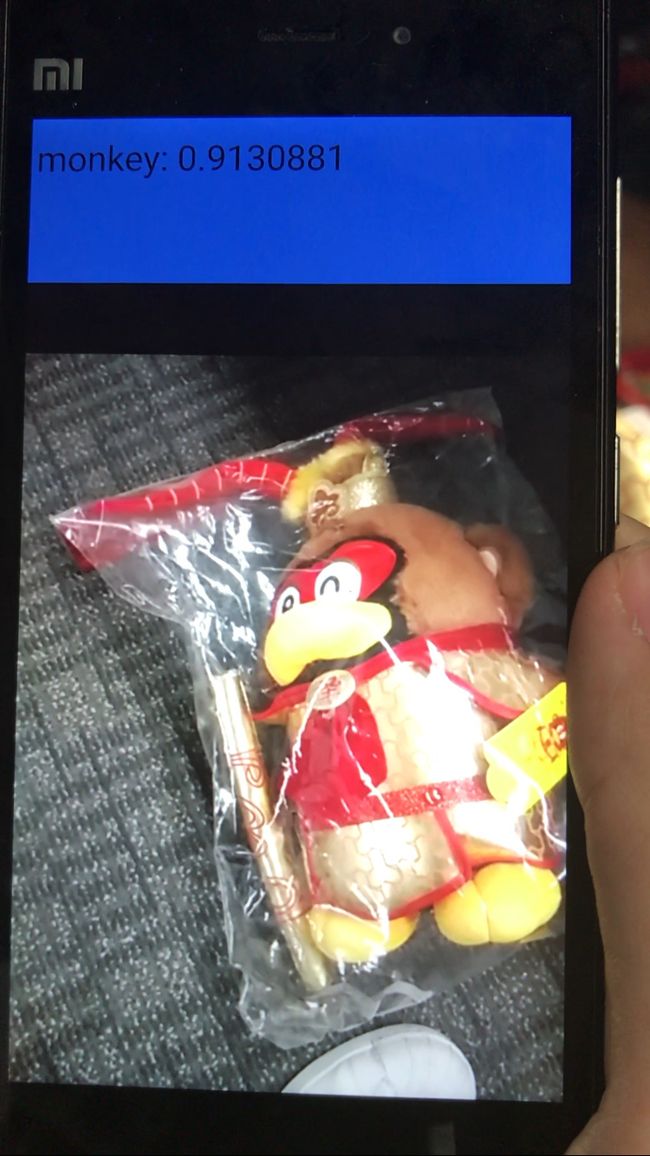
demo: 实时识别出是哪一种公仔(coin 存钱罐、羊年公仔、猴年公仔)


声音
训练集 由3,168个声音样本组成,并区分为男声和女声。通过分析声音的20种声学特性,可以达到99%的准确度。
可以看一下基于这个训练集的 web 应用: What is Your Voice Gender?
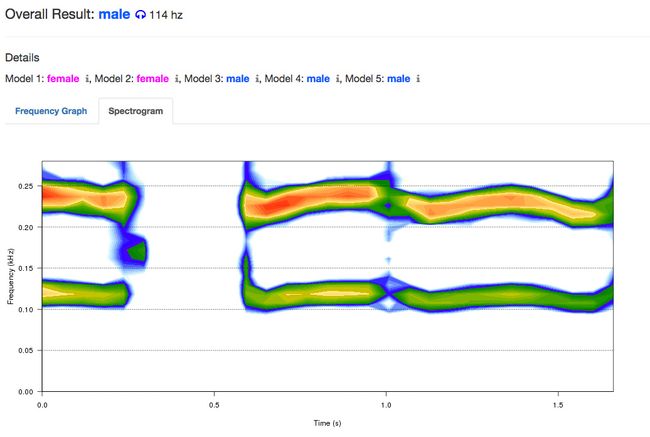
识别效果图:

下载该数据集并打开 voice.csv 文件之后,大家会看到其中包含着一排排数字:
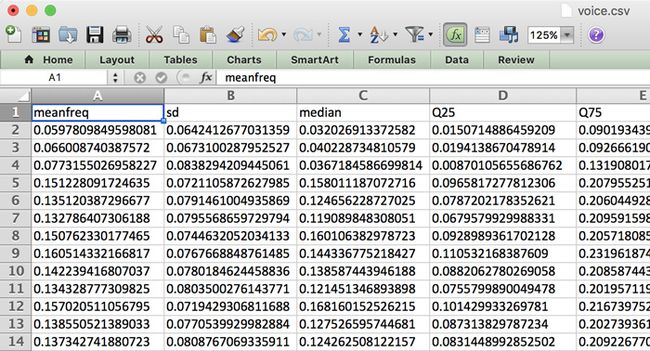
这里列出的并非实际音频数据,这些数字代表着语音记录当中的不同声学特征。这些属性或者特征由一套脚本自音频记录中提取得出,并被转化为这个 CSV 文件。具体提取方式可点击此处查阅 R 源代码。
每一项示例中存在20项声学特征,例如:
- 以kHz为单位的平均频率
- 频率的标准差
- 频谱平坦度
- 频谱熵
- 峰度
- 声学信号中测得的最大基频
- 调制指数
- 等等……
在以下示意图当中,大家可以看到这20个数字全部接入一个名为 sum 的小框。这些连接拥有不同的 weights(权重),对于分类器而言代表着这20个数字各自不同的重要程度。

sum = x[0]*w[0] + x[1]*w[1] + x[2]*w[2] + ... + x[19]*w[19] + b
数组 w 中的权重与值 b 代表着此分类器所学习到的经验。对该分类器进行训练的过程,实际上是为了帮助其找到与 w 及 b 正确匹配的数字。最初,我们将首先将全部 w 与 b 设置为0。在数轮训练之后,w 与 b 则将包含一组数字,分类器将利用这些数字将输入语音中的男声与女声区分开来。为了能够将 sum 转化为一条概率值——其取值在0与1之间——我们在这里使用 sigmoid 函数:
y_pred = 1 / (1 + exp(-sum))
如果 sum 是一个较大正数,则 sigmoid 函数返回1或者概率为100%; 如果 sum 是一个较大负数,则 sigmoid 函数返回0。因此对于较大的正或者负数,我们即可得出较为肯定的“是”或者“否”预测结论。
现在 y_pred 中包含的预测结果显示,该语音为男声的可能性更高。如果其概率高于0.5,则我们认为语音为男声; 相反则为女声。
决策树:

移植到安卓端:
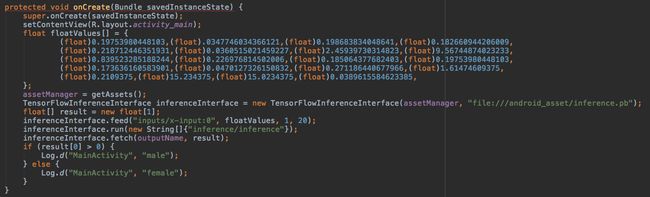
floatValues 数组:这里面保存的是20种声音声学特性
如果大家希望在一款应用程序当中使用此分类器,通过录音或者来自麦克风的音频信息检测语音性别,则首先需要从此类音频数据中提取声学特征。在拥有了这20个数字之后,大家即可对其分类器加以训练,并利用其判断语音内容为男声还是女声。
更多参考资料:
http://www.primaryobjects.com/2016/06/22/identifying-the-gender-of-a-voice-using-machine-learning
https://github.com/primaryobjects/voice-gender
http://www.infoq.com/cn/articles/getting-started-with-tensorflow-on-ios
char-rnn
char-rnn 是一个字符水平的语言模型,通过训练文本文件可以预测序列中下一个出现的字符,并以此来生成完整的文本。
应用场景
- 写武侠小说
- 训练汪峰歌词可以得到汪峰风格的歌词
我在这里中的夜里
就像一场是一种生命的意旪
就像我的生活变得在我一样
可我们这是一个知道
我只是一天你会怎吗
可我们这是我们的是不要为你
我们想这有一种生活的时候
我在哭泣
我不能及你的时光
我是我们在这是一种无法少得可以没有一天
我们想这样
我们远在一场我在我一个相多地在此向
可我是个想已经把我的时候
我看到在心悄一种痛定的时候
我看着我的感觉在飞歌
我不能在这多在心中
就像在我一瞬间
我的生命中的感觉
我在我一次到孤独所
我们在这是一看可以是一场我们在这样
我在这里失命
我不能在这感觉在天里
夜里
夜里
没有一天 我想心的是不吗到了
- 写古诗

优势:对于大多数用户来说,不在乎诗的平仄、韵律,而在于其中的意境(用户钟爱情诗和藏头诗)
目前在云 GPU 上完成模型的训练,并在 pc 上实现自动写诗功能
奇了了不为
点石上风烟
你凭栏干将
好事系在边
参考文章:
http://www.infoq.com/cn/articles/getting-started-with-tensorflow-on-ios
https://www.zhihu.com/question/21329754
https://github.com/primaryobjects/voice-gender
深度学习1--浅谈char-rnn三种模型