1. 背景
由于项目初期设计问题,采集到es的业务日志只使用了一个索引(index),随着线上日志量的增长,es很快飙升到磁盘警戒线,网上找了一圈,很多文章版本都比较老旧,最终直接啃官方文档,没有copy别人博客,如果你中途不走神,本文总共15min。version 适用于es 6.0+
本文前提保障:
- 文档中有时间字段,方便按日期切割
- index的
mapping配置中,_source需为true(默认),以保证es存入了源文档,而不仅仅是docId,便于执行reindex!
curl -XGET "localhost:9200/your_index_name/_mapping"
# 如果没有显示 _source, 代表"_source": false
2. 删文档(不建议)
这第一个想到的方法,将最老旧的日志删掉,如只保留近3个月的,采用 delete_by_query 接口
curl -X POST "localhost:9200/twitter/_delete_by_query" -H 'Content-Type: application/json' -d'
{
"query": {
"range" : {
"day" : {
"lt" : "2018-12-01"
}
}
}
}
'
但是,es的delete,并不是真正的物理删,磁盘使用率(utilization)并不会下降。删除的文档仅仅被标记,es将文档存入一个个segment file中,其file数量随着文档的写入不断增加,es因此会有合并segment file的操作,将多个小的segment合并成一个大的segment file,当segment合并的时候,标记的文档才会真正的物理删除。
这种方案,只适合在 项目早期、文档量少、且机器负载不高 情况下进行,因为批量读写会导致cpu utilization的飙升,造成系统负载加重,可以在晚上业务量不高的时候进行
3. 磁盘扩容 (短期有效)
那如果标记删除不能立即解决问题,那就对磁盘扩容吧!1T 到 2T,2T 到 4T,由于升级磁盘需要重启机器,所以,如何做到优雅滚动关停es至关重要!
3.1 停止es集群服务
常见就是ps看一下es的进程,然后kill,先等一下!在此之前,需对集群进行配置,方便更加快速的服务重启
3.1.1 停止分片分配
由于es中的index是分布式存储,所以一个index分成了多个shard,分布在各个节点node上,每个shard都可以单独提供服务,同时每个shard可以配置多个副本(replicas),保证集群的高可用,提高了查询效率。同时,es在管理这些分片时,有一套自有的均衡算法,保证shard均匀分散在各个node上,同时保证每个shard和其对应的replica不在同一node上。正是这种机制,使得当node离开和重新加入的时候,分片的分配会copy文件,会造成大量的io,因为node重启很快就回来,所以暂时关掉自动分片分配,详情参见另一篇文章,介绍集群重启步骤。这里选择直接停止分配
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.enable": "none"
}
}'
这样,在node停掉的时候,不会出现分片分配重新均衡了。
3.1.2 挂载新盘
由于机器是云上资源,因此按照各个云上的扩容文档操作即可,无论是自有机房还是云上机器,无非是下面几个步骤:
reboot重启df -h看一下现在的挂载点(如/dev/vdb)和 挂载路径(如/data/es/)fdisk -l可以进一步确认盘的信息fdisk /dev/vdb,对新盘进行重新挂载,命令中可能涉及到的选项,不分区的话,大部分按回车默认选项:d n p 1 wq其他操作 如
e2fsck -f /dev/vdb,resize2fs /dev/vdbmount /dev/vdb /data重新挂载即可
3.1.3 恢复分配分配
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"transient": {
"cluster.routing.allocation.enable": "all"
}
}
'
这一步,会有部分io,等到recovery结束,集群恢复正常。如果有 Unassigned 状态的shard,需要手动执行分片分配,对应的命令reroute,这个不难,正常情况下,几乎不会出现 Unassigned 的shard。
执行完上述操作,磁盘体积翻倍。在短期内,可以保证服务正常。
4. 索引拆分(最佳实践)
无论标记删除,还是磁盘扩容,都没有真正的解决索引过大的问题,随着文档数的增加,索引势必会变得更大。针对大索引,标记删除以及扩容后分片恢复的操作时间,也会大幅增加,可能会从几小时到一两天。上述方法不可行!
因为es对index的删除是物理删除,是立即的,既然不能直接删除原索引,得想办法把大索引拆成小索引,然后再删除老旧的。那么es有么有这种api,将大的索引按照某种条件(按天、按月)进行拆分呢?为此,我找了很多博客,最后发现,很多博客里介绍的api都很老旧,还是官网的文档最实在,文档是英文,不过理解起来并不复杂。墙裂推荐看官方文档。为此,我调研了这些api:_rollover,alias,template,reindex,大家可以有针对的深入学习这几个api,细节这里就不讲了,先看我怎么用的吧~
4.1. 错误尝试
_rollover 当看到这个api时,我以为找到了最接近需求的api,这个api介绍如下
The rollover index API rolls an alias over to a new index when the existing index is considered to be too large or too old.
显然被 too large 和 too old 吸引了。。。
curl -X PUT "localhost:9200/logs-000001" -H 'Content-Type: application/json' -d'
{
"aliases": {
"logs_write": {}
}
}
'
# Add > 1000 documents to logs-000001
curl -X POST "localhost:9200/logs_write/_rollover" -H 'Content-Type: application/json' -d'
{
"conditions": {
"max_age": "7d", #当文档创建时间大于7天
"max_docs": 1000, #当文档数量超过上限1000
"max_size": "5gb" #当索引大小超过5GB
}
}
'
思路:
先给 index 建一个别名 alias,再 rollover,当执行时,满足任一个条件即可创建新索引,同时别名 alias 指向新的,除此之外,_rollover还可以按日期生成新索引
问题:
- 拆分只在api执行时生效,后面不会自动拆分,如果按天索引,则必须每天定时执行,增加维护成本,如果定时任务失败...
- 当别名滚向新的索引后,旧索引不能通过 alias 再访问
- 并没有将历史的索引按天生成,只是在此api执行后,新文档才会进新index
4.2 最佳实践
假设原索引name knight-log,当前月份 2019-02
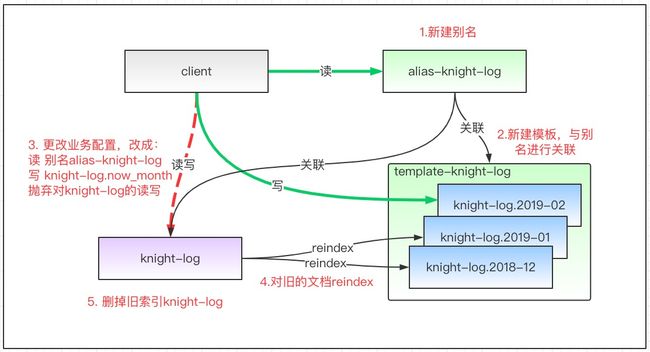
思路:
- 创建别名alias:alias-knight-log
- 为旧的 knight-log 关联别名 alias-knight-log
- 创建索引模板template: template-knight-log,该模板匹配所有
knight-log.*索引,在模板中定义settings和mappings,以及自动关联别名 alias-knight-log
此外,将项目中读写es的操作分别设置:
- 读 alias-knight-log,可以查询所有关联索引
- 写 knight-log.2019-02,在原索引后append月份即可!调用Java api进行索引时,接口规定每条文档需要指定index name,因此将原来的 name 变为 name + current_month 即可,其他语言同理!
更新业务代码,重新上线后,新文档会进入到形如 knight-log.2019-02 的索引中,原 knight-log 将不会有写请求,读请求也经过别名 alias-knight-log 代理了
经过上述步骤,旧的index只读不写,写请求全部进入 knight-log.2019-02 的索引中,保障了这一点,我们就可以对 knight-log 按时间粒度以大化小,逐个删除了!
Sad,没有这种直接的api,不过,不起眼的reindex却承担起这个重任,一开始我觉得跟这个api应该没有关系,不仅不省空间,反而还翻倍,直到发现可以按条件reindex后,眼前一亮!我按时间条件reindex不就好了嘛~~
# 将 2019-01 月的文档, 全部 reindex 到 knight-log.2019-01 中
curl -X POST "localhost:9200/_reindex" -H 'Content-Type: application/json' -d'
{
"source": {
"index": "knight-log",
"type": "your_doc_type",
"query": {
"bool": {
"filter": {
"range": {
"day": {
"gte": "2019-01-01",
"lt": "2019-02-01"
}
}
}
}
}
},
"dest": {
"index": "knight-log.2019-01"
}
}
'
tips1: 在reindex到新index之前,为了加快索引,可以对新index设置,常规的批量索引设置注意项,这里也适用,如:replicas=0,refresh_interval=-1
tips2:第一次使用reindex,没有开启slice(相当于多线程),io和cpu虽然都不高,但很慢,可适当开启,但注意slice不要超过index的shard数,看官方文档,此处不多提!
tips3:如果一个月的文档数太多,不放心一次性操作,你可以尝试先按天reindex到新月份index中,这样可以观察cup和io,然后适当调整reindex相关参数后,再把当月余下天数的文档全部reindex到新index中
tips4:当进行完一次reindex,恢复 refresh_interval 后,可以对新旧索引同时查询,看文档数是否一致!确保无异常!
tips5:手误执行reindex,可以中途取消本次task
将 knight-log 的replicas数从默认的1 变为 0,这样整个index省掉一半大小(非必须,剩余磁盘多可以忽略),然后,对 knight-log 按月份进行reindex,这样反复操作几次,可完成近几月的备份,形如 knight-log.2019-01,knight-log.2018-12 等(不要忘记2月的旧文档哦,同样需要reindex,这样2月的index才会完整),同时因为模板的特性,月份索引会自动加上 alias-knight-log 这个别名,一举两得!
reindex完必要的数据后(如近3月),就可以直接删掉 knight-log!
若几个月后,磁盘又满了,就可以将最久老月份的index直接物理删除,方便快捷!
5. 总结
追根究底,这种问题就不应该存在!可能一开始使用es不熟吧,起码按天/月索引是应该具备的基本sense吧,大家要避免这个坑!
其次,如果单条文档体积较大,可以考虑将数据存入HBase,es中只存docId即可,通过条件搜出对应的docId,然后用docId去HBase取数据,进一步高效利用es,这通过禁用_source字段(保存原文档的json字段)实现。不过,因为es只存倒排索引,所以没了原文档,会缺失部分便捷性,慎重考虑!
说回来,es不支持将大的索引按时间拆分成小索引,只能在多个api组合中找到最优实践,对应用来说,需要改动索引名后重启,已经是最小化改动,在整个过程中,es保障了正常提供服务,不影响其他业务。
经历过上述操作,更加熟练的掌握了es多个相关api,了解查询原理,写入原理,分片分配策略以及查询语句优化等知识点。另: kibana下使用dev tools也非常爽,会弹提示,算是发现的彩蛋,建议多用!