一、Scrapy是什么?
先看官网上的说明,http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
Scrapy是一个非常好用的爬虫框架,它不仅提供了一些开箱即用的基础组件,还提供了强大的自定义功能。
框架学习的规律就是修改配置文件,填充代码就可以了。复杂之处就是一开始代码很多,不同的功能模块,scrapy也是这样的吗?
二、Scrapy安装
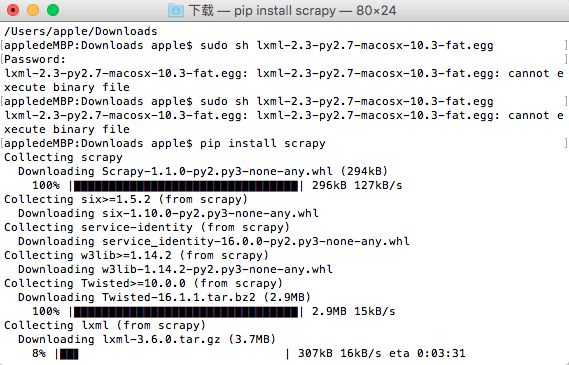
看了一个网上的文章,说windows下安装的比较多,Scrapy前置需要安装很多包,也有各种各样的问题,我是在mac下安装的,安装了两次都比较顺利。(python的版本是2.7.10 系统自带)
pip install scrapy
提示six 需要升级,用命令升级失败,提示一个文件夹没有权限,修改文件夹权限后仍然不行,查看是一个临时文件。想卸载后six再安装也行。直接去下载six源码安装,就好了。再 pip install scrapy ,顺利!
三、Scrapy创建项目
Scrapy 提供了一个命令来创建项目 scrapy 命令,在命令行上运行:
scrapy startproject jianshu
我们创建一个项目jianshu用来爬取首页热门文章的所有信息。
jianshu/
scrapy.cfg
jianshu/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
spiders文件夹下就是你要实现爬虫功能(具体如何爬取数据的代码),爬虫的核心。在spiders文件夹下自己创建一个spider,用于爬取首页热门文章。
scrapy.cfg是项目的配置文件。
settings.py用于设置请求的参数,使用代理,爬取数据后文件保存等。
四、Scrapy爬取首页热门文章
1)新建jianshuSpider
class Jianshu(CrawlSpider):
name='jianshu' # 运行时这个爬虫的名字
start_urls=['http://www.jianshu.com']
url = 'http://www.jianshu.com'
def parse(self, response):
selector = Selector(response)
#....
# response就是返回的网页数据
# 处理好的数据放在items中,在items.py设置好你要处理哪些数据字段,这里我们抓取文章标题,url,作者,阅读数,喜欢,打赏数
## 解析处理数据的地方,用xpath解析处理数据
要解析处理哪些数据,在items.py中定义好,相当于Java中的实体类:
from scrapy.item import Item,Field
class JianshuItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = Field()
author = Field()
url = Field()
readNum = Field()
commentNum = Field()
likeNum = Field()
2)xpath的数据解析:
articles = selector.xpath('//ul[@class="article-list thumbnails"]/li')
for article in articles:
title = article.xpath('div/h4/a/text()').extract()
url = article.xpath('div/h4/a/@href').extract()
author = article.xpath('div/p/a/text()').extract()
解析的数据保存:
item['title'] = title
item['url'] = 'http://www.jianshu.com/'+url[0]
item['author'] = author
这时数据经解析处理好了,还有最重要一步,提交:
yield item
OK! 万事俱备,数据保存在哪里,以什么格式?
在settings.py中加入两行代码:
FEED_URI=u'/Users/apple/Documents/jianshu-hot.csv'
FEED_FORMAT='CSV'
如何运行这个爬虫?命令行:
scrapy crawl jianshu
是不是把首页上的文章信息都爬取到本地的csv文件里来了。
等等还有一个问题,首页热门还有更多文章,点击“点击查看更多”就可以加载。怎样才能一网打尽把所有信息都爬取下来呢?就是要递归调用parse()方法。
第一步,找到“点击查看更多”对应的url
next_link = selector.xpath('//*[@id="list-container"]/div/button/@data-url').extract()[0]
第二步,递归调用,将新的url传给parse方法,直到最后一页为止。
if next_link :
next_link = self.url+ str(next_link)
print next_link
yield Request(next_link,callback=self.parse) #递归调用并提交数据
大功告成,来看看成果。
PS:
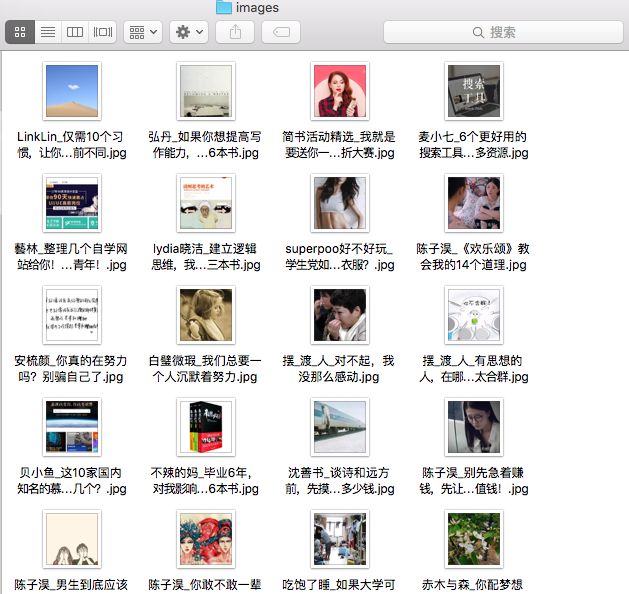
1、增加所有文章的缩略图下载。一行代码:
urllib.urlretrieve(image[0], '/Users/apple/Documents/images/%s-%s.jpg' %(author[0],title[0]))
注意:1)此处取出来的作者、标题还是集合,需要加上索引。2)有些文章是没有缩略图的。
2、提供源码下载
https://github.com/ppy2790/jianshu.git