生物或医学中涉及高通量测序的论文,一般会将原始测序数据上传到公开的数据库,上传方式见测序文章数据上传找哪里;并在文章末尾标明数据存储位置和登录号,如 The data from this study was deposited in NCBI Sequence Read Archive under accession SRA: SRP114962.。
NCBI的SRA (Sequence Read Archive) 数据库(http://www.ncbi.nlm.nih.gov/sra/) 是最常用的存储测序数据的数据库。目前SRA数据的组织方式分为下面4个层次:
Studies–研究课题;
Experiments–实验设计;
Runs–测序结果集;
Samples–样品信息。
进入SRA官网:https://www.ncbi.nlm.nih.gov/sra, Search框中输入SRA编号(SRP114962),获得如下图的界面:
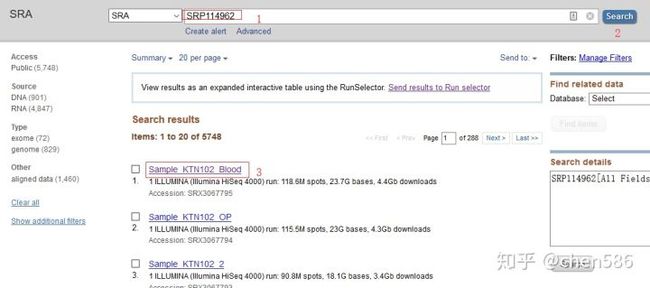
点击第一个样品即可查看其详细信息。

当样品比较多时,可以点击Send results to Run selector(图中画圈的位置)进入筛选页面。

从图中可发现,测序平台是Illumina HiSeq 4000,5748个Runs,每个Run的名字、样本名、测序类型(全基因组/外显子组等)、tissue、treatment等。
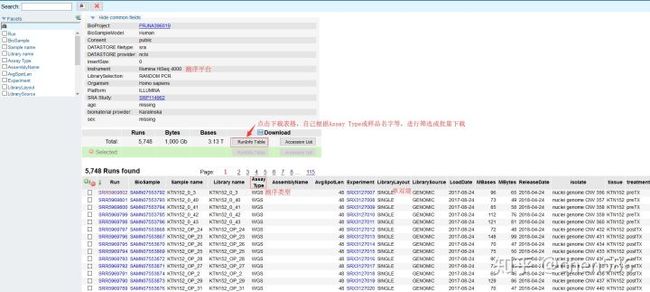
在如此多的Runs中,假设我们想获取其中两个病人的化疗前和化疗后的外显子组测序数据,观察其化疗前后究竟有哪些基因突变以及突变的频率怎么样。数据来自于文章 肿瘤化疗无效是对预先存在的突变的选择还是诱发新突变,Cell给你答案。
5748个Runs,有116Page,怎么找呢?
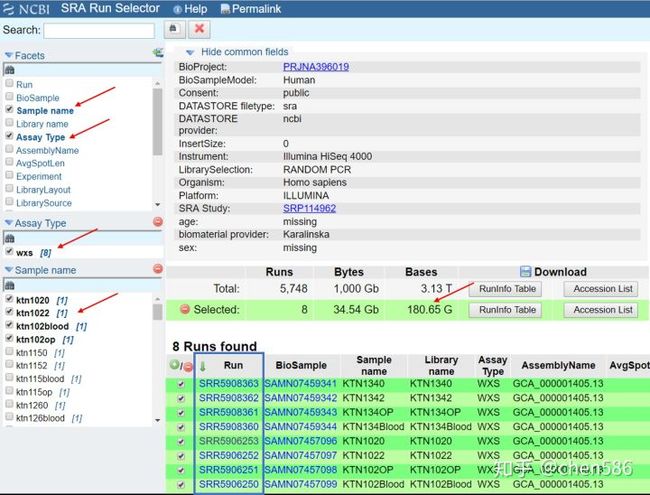
在Facets下拉框中先勾选Assay Type,等待页面相应后勾选wxs,即全外显子组数据,等待页面相应。
在Facets下拉框中勾选Sample name,等待页面相应后勾选ktn102及ktn102两个病人的分别四个样本(四种treatment:pre、2cycleschemo、operative和blood),如图。等待页面相应。获得Run编号(蓝色框):SRR5908363、SRR5908362…
然后使用NCBI提供的工具SRAToolkit下载。
SRA toolkit https://trace.ncbi.nlm.nih.gov/Traces/sra/sra.cgi?view=software, 根据服务器操作系统类型下载对应的二进制编码包,下载解压放到环境变量即可使用。
使用NCBI提供的SRA-toolkit中的工具fastq-dump直接下载SRR文件,并转换为FASTQ格式,--split-3参数表示如果是双端测序就自动拆分,如果是单端不受影响。--gzip转换fastq为压缩文件,节省空间。
下载的数据集一般比较大,放入后台不中断下载 (nohup cmd &)。
nohup fastq-dump -v --split-3 --gzip SRR5908360 &
nohup fastq-dump -v --split-3 --gzip SRR5908361 &
nohup fastq-dump -v --split-3 --gzip SRR5908362 &
nohup fastq-dump -v --split-3 --gzip SRR5908363 &
nohup fastq-dump -v --split-3 --gzip SRR5906250 &
nohup fastq-dump -v --split-3 --gzip SRR5906251 &
nohup fastq-dump -v --split-3 --gzip SRR5906252 &
nohup fastq-dump -v --split-3 --gzip SRR5906253 &
注意:如果数据量很大可能需要下载1-2天。数据下载完会在~/ncbi下面存在缓存的sra文件,记得定时清空。
Summary
按照上述步骤下载完毕后可看到很多个fastq.gz格式测序文件。
2019-03-07更新:Aspera Connect 工具在下载测序数据时的应用
1. 下载Aspera Connect:
wget http://download.asperasoft.com/download/sw/connect/3.7.4/aspera-connect-3.7.4.147727-linux-64.tar.gz
2. 解压:
tar zxvf aspera-connect-3.7.4.147727-linux-64.tar.gz
3. 安装:
bash aspera-connect-3.7.4.147727-linux-64.sh
4. 查看是否有.aspera文件夹
去根目录
ls -a #如果看到.aspera文件夹,代表安装成功
PS: 在这一步时,我用" cd / " 命令切到根目录没有找到.aspera文件,
于是我cd到用户目录,通过" ll -h" 命令在主用户目录下找到。

5. 永久添加环境变量
echo 'export PATH=~/.aspera/connect/bin:$PATH' >> ~/.bashrc source ~/.bashrc
6. 查看帮助文档,验证是否可以调用
ascp --help
PS:输入这个命令的时候,系统提示-bash: ascp: command not found,于是我进行了以下操作:
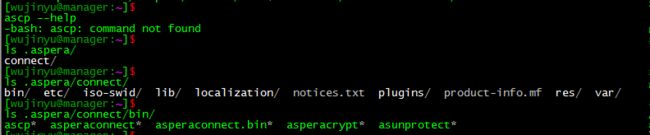
之后我再使用 .aspera/connect/bin/ascp --help 命令之后就能正常开始Aspera Connect的使用了。
开启命令换成如下:~/.aspera/connect/bin/ascp -v -i ~/.aspera/connect/etc/asperaweb_id_dsa.openssh -k 1 -T -l200m [email protected]:/sra/sra-instant/reads/ByRun/sra/SRR/SRR347/SRR3474721/SRR3474721.sra ~/downloads
这样你的电脑或者服务器就可以开启神器了
下面是开启命令
ascp -v -i ~/.aspera/connect/etc/asperaweb_id_dsa.openssh -k 1 -T -l200m [email protected]:/sra/sra-instant/reads/ByRun/sra/SRR/SRR347/SRR3474721/SRR3474721.sra ~/downloads
上面命令中SRR后面的数字就是下载文件的代号,大家应该能看懂规律吧。按照中的Access list就能够一个一个的下载到你要的文件。
你可以看一下速度,
根据那个ascp帮助文档,你可以去调整速度,也不能太快了,四不四。