论文:Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation
,WWW,2019,Microsoft Research Asia & Meituan Dianping Group
1. 应用背景
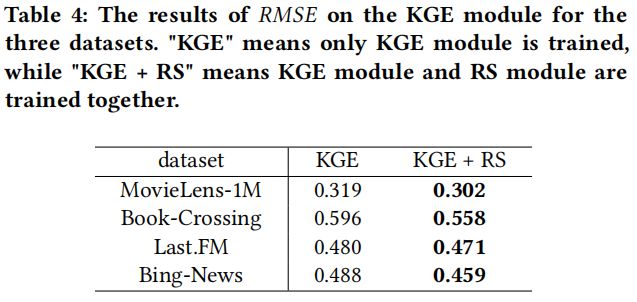
如图所示,知识图谱在推荐系统中应用的三种方式:
依次训练:DKN
联合训练:RippleNet
交替训练:MKR
文章认为现有的模型存在的问题有:
DKN:需要先获取Entity embedding才能训练,因而无法端到端训练;
RippleNet:对关系向量的表示不充分,关系矩阵很难在 中得到训练;
因此作者提出了MKR。MKR是一个通用的、端对端的深度推荐框架,旨在利用知识图谱嵌入(KGE)去协助推荐任务。两个任务是相互独立的,但是由于RS中的item和KG中的entity相互联系而高度相关。整个框架可以通过交替优化两个任务来被训练,赋予了MKR在真实推荐场景中高度的灵活性和适应性。
2. MKR模型结构
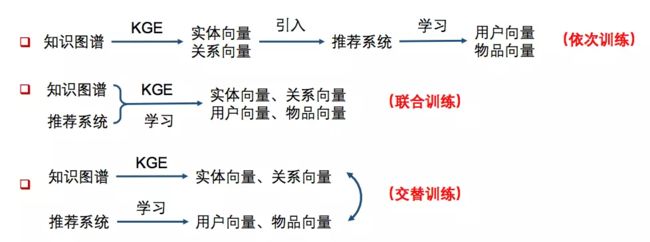
MKR模型结构如图所示。由三个主要部分组成:推荐模块、KGE模块、交叉压缩单元。
左侧 推荐模块:将一个 user 和 item 作为输入,使用多层感知器(MLP)提取 user 特征,使用交叉压缩单元提取 item 特征,提取出的特征再一起送入另一个MLP,输出可能性预测结果。
右侧 KGE模块:将一个 head 和 relation 作为输入,使用 MLP 提取 relation 特征,使用交叉压缩单元提取 head 特征,使用 head 和 relation 计算出预测 tail 的表示,然后使用函数 f 计算预测 tail 和实际 tail 的相似度,作为KGE链路预测的能力分数。
中间 交叉压缩单元:是将推荐模块和KGE模块连接起来的关键,这个单元可以自动的学习 RS 中 item 和 KG 中 entity 的高阶交互特征。
2.1 Cross & Compress unit
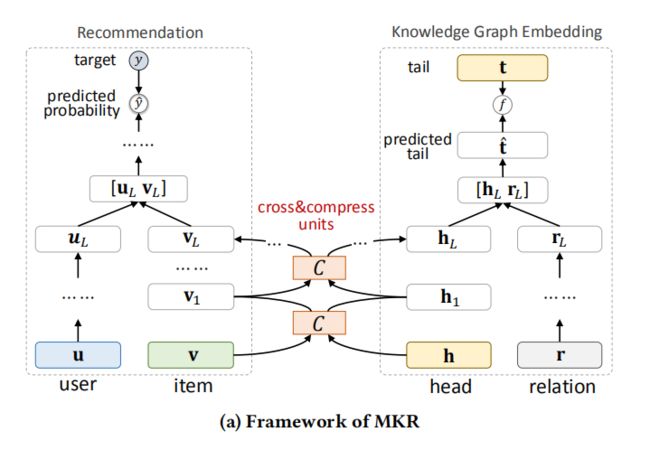
交叉压缩单元结构如图所示。
交叉特征共享单元(cross-feature-sharing units)是一个可以让两个任务交换信息的模块。由于物品向量和实体向量实际上是对同一个对象的两种描述,他们之间的信息交叉共享可以让两者都获得来自对方的额外信息,从而弥补了自身的信息稀疏性的不足。
结合代码来理解这个过程的具体实现:
v,e = inputs
v = tf.expand_dims(v,dim=2)
e = tf.expand_dims(e,dim=1)
# [batch_size, dim, dim]
c_matrix = tf.matmul(v, e)
c_matrix_transpose = tf.transpose(c_matrix, perm=[0, 2, 1])
# [batch_size * dim, dim]
c_matrix = tf.reshape(c_matrix, [-1, self.dim])
c_matrix_transpose = tf.reshape(c_matrix_transpose, [-1, self.dim])
v_output = tf.reshape(tf.matmul(c_matrix,self.weight_vv) +
tf.matmul(c_matrix_transpose,self.weight_ev),[-1,self.dim]) + self.bias_v
e_output = tf.reshape(tf.matmul(c_matrix, self.weight_ve) +
tf.matmul(c_matrix_transpose, self.weight_ee),[-1, self.dim]) + self.bias_e
return v_output,e_output
item对应的embedding用v表示,head对应的embedding用e表示,二者初始情况下都是batch * dim大小的。过程如下:
1、v扩展成三维batch * dim * 1,e扩展成三维batch * 1 * dim,随后二者进行矩阵相乘v * e,我们知道三维矩阵相乘实际上是后两维进行运算,因此得到c_matrix的大小为 batch * dim * dim
2、对得到的c_matrix进行转置,得到c_matrix_transpose,大小为batch * dim * dim。这相当于将e扩展成三维batch * dim * 1,v扩展成三维batch * 1 * dim,随后二者进行矩阵相乘e * v。这是两种不同的特征交叉方式。
3、对c_matrix和c_matrix_transpose 进行reshape操作,变为(batch * dim ) * dim的二维矩阵
4、定义两组不同的参数和偏置,分别得到交叉后的v_output和e_output.
2.2 KGE模块
因为RS模块就是传统的MLP,无创新点,这里主要对KGE再进行一下补充说明。
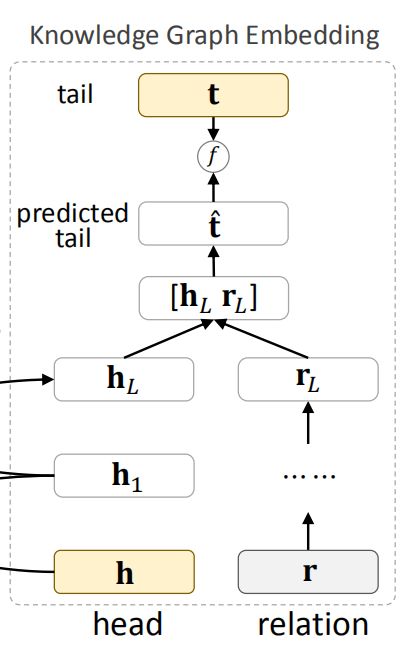
作者没有使用已有的KGE方法,而是提出了一种深度语义匹配结构。
对于给定的知识三元组(h, r, t),利用交叉压缩单元和多层感知器分别从原始的head h 和 relation r 提取特征,然后将head和relation对应的向量进行 拼接,经过多层神经网络,得到一个 tail 对应向量的预估值 t^ 。
具体过程如代码所示:
# kge
self.head_relation_concat = tf.concat([self.head_embeddings,self.relation_embeddings],axis=1)
for _ in range(args.H - 1):
kge_mlp = Dense(input_dim=args.dim * 2,output_dim = args.dim * 2)
self.head_relation_concat = kge_mlp(self.head_relation_concat)
kge_pred_mlp = Dense(input_dim=args.dim * 2,output_dim = args.dim)
self.tail_pred = kge_pred_mlp(self.head_relation_concat)
self.tail_pred = tf.nn.sigmoid(self.tail_pred)
3 损失函数
模型结构非常清晰的分为3部分,损失也是一样:
第一项是 推荐模块的交叉熵损失,其中u和v便利users和items集合;
第二项是 KGE模块的损失,旨在增加正确三元组的得分,减少错误三元组的得分;
第三项是 正则项,防止过拟合。
ps:作者实践中,在每次的迭代中先重复训练推荐任务 t 次,再训练KGE任务1次,因为更加关注提升推荐的性能。
4. 实验结果
数据集:
MovieLens-1M,Book-Crossing dataset,Last.FM dataset,Bing-News dataset
知识图谱:
Microsoft Satori
数据描述:
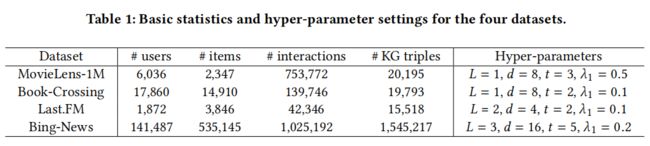
特征:
MovieLens-1M:使用电影的 ID embedding
Book-Crossing:使用书籍的 ID embedding
Last-FM:使用音乐的 ID embedding
Bing-News :使用新闻的 ID embedding 和 titles word embedding 的拼接
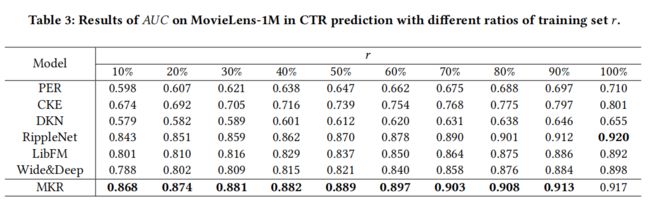
实验结果:

2.可以看到,MKR在训练集很小的时候也有很好的效果,能有效应对冷启动问题。
3.可以看到,在KGE一端,embedding效果也提升了。