Hadoop先导
大数据时代的核心是计算和数据处理,在计算方面,主要是通过分布式计算完成海量数据的计算,在海量数据的计算方面,目前集中于3个场景,离线计算:Hadoop,内存计算:Spark,实时计算(流式计算):Storm,Flink等。Hadoop的搭建对于入门是必不可少的,以前曾经搭建过,但是很久没弄了,现在重新拾起Hadoop,Spark等,搭建其运行环境是第一步,这里详细记录我的步骤,个人负责的认为,按照我的步骤,一定能成功搭建出完全分布式的Hadoop集群!
Hadoop三种运行模式
- 单机模式
单击模式是指:Hadoop被配置成以非分布式模式运行的一个独立Java进程,在一个JVM中运行。这对调试非常有帮助。
- 伪分布式模式
伪分布式是指:一个机器上,即当namenode,又当datanode,是jobtracker也是tasktracker。没有所谓的在多台机器上进行真正的分布式计算,故称为伪分布式模式
- 完全分布式模式
namenode,datanode,jobtracker,tasktracker各司其职。可以部署几十上千个节点中。
在这里,介绍完全分布式模式的搭建过程。
第一步:集群规划
按照Hadoop集群的基本要求,其中一个是Master节点,用于运行Hadoop程序中的namenode,sencondorynamenode和jobtracker任务。另外一个用于冗余目的。Slaver节点用于运行hadoop程序中的datanode和tasktracker任务。所以模拟hadoop集群至少三个节点。在实际生产环境中,部署的肯定是几十上千台,这个时候,至少有2+个Master和2+Slaver,所以,其实部署4台是比较适合,但是由于4台对机器要求,因为我是在VM里面进行安装集群,所以能安装的数量有限,同时部署更多机器,主要是Hadoop文件的配置上,不是搭建上的意义,所以3台已经足够能理解Hadoop分布式集群了。在这里我先安装一台机器Master,两台Slaver通过虚拟机复制即可。废话不多说,直接实践最重要。
第二步:搭建说明
在VM中搭建Hadoop完全分布式集群是十分容易的,因为可以通过克隆操作系统,克隆多个虚拟系统,克隆的虚拟操作系统的IP地址是连续的。纵观搭建Hadoop的整个流程,第一,每天机器都必须有JDK,ssh,vim(可选),然后每台机器能免ssh登录。第二就是每台机器安装Hadoop,配置Hadoop文件。在这里搭建的流程,其中就是上述两个步骤。
第三步:在VM安装Linux虚拟机
因为CentOS需要下载,我现成有Ubuntu14.04-64位的镜像文件,所以直接安装这个,但是为了体验真实的生产环境,我建议从CentOS入手,因为CentOS更适合实际生产。
- 安装Linux虚拟机十分简单,在此处略过。
- 安装好后安装VM tools。
3.安装搜狗输入法,毕竟容易中英文切换,如果习惯中文,安装中文包。
4.初始化root用户的密码,新建一个用户,在这里我是bigger用户,完成这些可以进入第二步。
第四步:安装JDK,ssh,vim
JDK
- 搜索,JDK,进入官网,下载JDK。
网址:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html

- 我的是64位的系统,所以下载Linux x64的版本。
-
下载后,移到Ubuntu桌面,解压,出现文件夹如下:

-
直接将解压后的jdk移到lib文件夹下面

- 配置环境变量
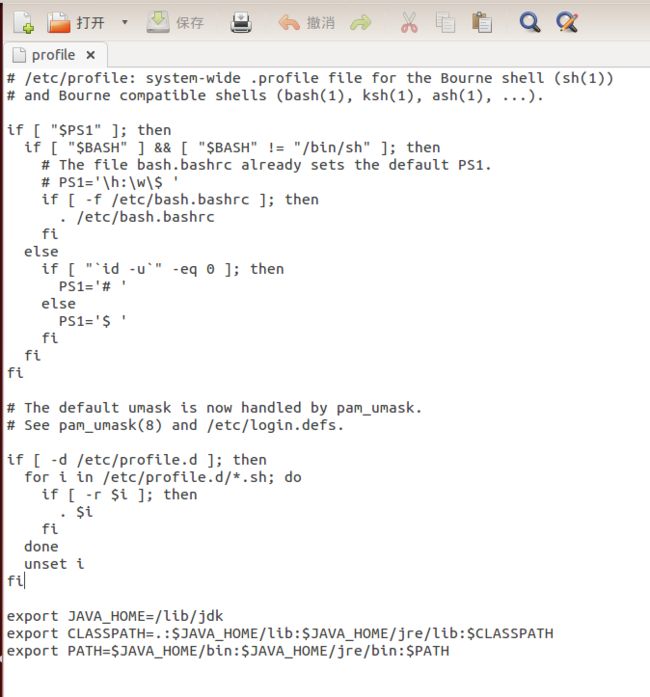
gedit /etc/profile - 配置如下:
export JAVA_HOME=/lib/jvm/jdk1.7.0_76
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
- 更新配置文件
source /etc/profile -
验证
java -version

安装ssh和vim
sudo apt-get install vim
sudo apt-get install openssh-server
查看ssh状态
sudo ps -e | grep ssh
如果有sshd,说明ssh服务已经启动

如果ssh关闭了,可以使用开启服务
service ssh start
第五步:开始准备克隆
这时候,虚拟机,安装了JDK,vim,ssh,里面保存了Hadoop安装文件,这个时候,我们就可以进行虚拟机的克隆。

克隆两台,分别为Slave1和Slave2.
这时候显示如下:
这时候,三台机器的ip分别为:(Master) 192.168.175.128,(Slaver1)192.168.175.131,(Slaver2)192.168.175.132
Master:

Slaver1:

Slaver2:

这时候配置host文件,这样每台机器就能根据名字做IP地址的映射

第六步:配置免SSH
配置的SSH的原因是,比如Hadoop需要访问另一台机器,这时候如果不需要密码能直接连接该多好,这就是配置SSH免密码登录的原因。
ssh-keygen -t rsa
Master:

Master秘钥存放:

Slaver1和秘钥存放:

Slaver2 和秘钥存放:

这时候在目录:~/.ssh下生成了公钥和私钥,谁有了这个公钥,就能访问这台机器不需要密码了,所以三台机器的公钥是共享的。在这里我们发现没有authorized_keys 文件夹,所以直接用命令追加。
cat id_rsa.pub >> authorized_keys

重启
登录
ssh localhost

这时候如果需要这台机器配置互相免密码登录:
原理如下:A若想无密码访问B,就需要把公钥发送给B,B把A发来的公钥添加到自己的授权文件里。所以步骤如下:
1.将Slaver1和Slaver2的公钥都发给Master,Master在自己的授权追加。
命令如下:
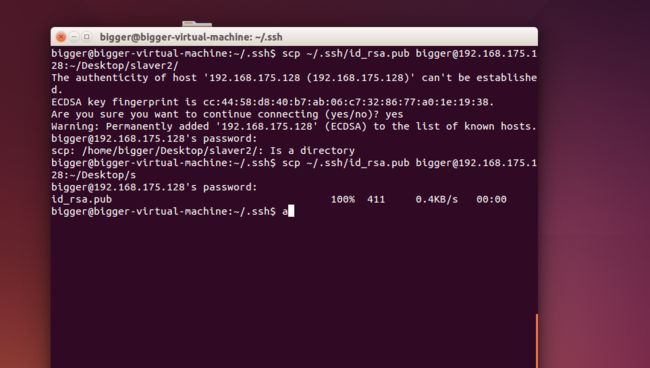
scp ~/.ssh/id_rsa.pub [email protected]:~/Desktop
复制桌面,比较感性

传输完成后
此时,进行追加:
cat ~/Desktop/id_rsa.pub /home/bigger/.ssh/authorized_keys
这时候,配置的Slaver1:192.168.175.131的公钥,所以,检验是否能免密码:

IP变化了,所以登录成功!
同理。增加Slaver2的机器到Master:
传输:
追加:

检验:

这时候,Master的文件有三个机器的公钥,后续直接复制到每台机器并追加即可。
- 首先将授权文件复制到桌面

- 传给每台机器
- 追加公钥
cat /home/bigger/Desktop/authorized_keys /home/bigger/.ssh/authorized_keys
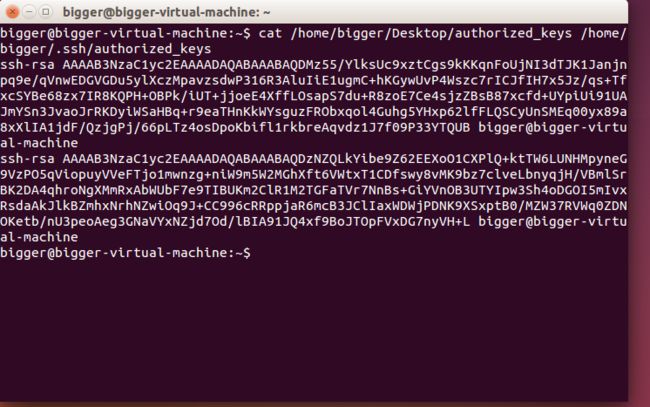
验证:
登录Master:
登录Slaver2:

对于Slaver2重复上述,至此,免ssh配置完成!
最后是权限修改:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
第七步:开始Hadoop安装的配置!
-
复制解压后的Hadoop文件到/lib文件夹下面

-
配置Hadoop的配置文件,Hadoop2.6的配置文件在
/hadoop-2.6.0/etc/hadoop下面

- 配置涉及7个文件
~/hadoop/etc/hadoop/hadoop-env.sh
~/hadoop/etc/hadoop/yarn-env.sh
~/hadoop/etc/hadoop/slaves
~/hadoop/etc/hadoop/core-site.xml
~/hadoop/etc/hadoop/hdfs-site.xml
~/hadoop/etc/hadoop/mapred-site.xml
~/hadoop/etc/hadoop/yarn-site.xml -
配置文件
1.hadoop-env.sh
该文件是hadoop运行基本环境的配置,需要修改的为java虚拟机的位置。
故在该文件中修改JAVA_HOME值为本机安装位置
export JAVA_HOME=/lib/jdk

2.yarn-env.sh
该文件是yarn框架运行环境的配置,同样需要修改java虚拟机的位置。
在该文件中修改JAVA_HOME值为本机安装位置
export JAVA_HOME=/lib/jdk

3.修改slaves文件
添加
slaver1
slaver2

4:core-site.xml
这个是hadoop的核心配置文件,这里需要配置的就这两个属性,fs.default.name配置了hadoop的HDFS系统的命名,位置为主机的9000端口;hadoop.tmp.dir配置了hadoop的tmp目录的根位置。这里使用了一个文件系统中没有的位置,所以要先用mkdir命令新建一下。
hadoop.tmp.dir
/data/hadoop-${user.name}
fs.default.name
hdfs://master:9000

5:hdfs-site.xml
这个是hdfs的配置文件,dfs.http.address配置了hdfs的http的访问位置;dfs.replication配置了文件块的副本数,一般不大于从机的个数。
dfs.http.address
master:50070
dfs.namenode.secondary.http-address master:50090
dfs.replication
1

6:mapred-site.xml
这个是mapreduce任务的配置,由于hadoop2.x使用了yarn框架,所以要实现分布式部署,必须在mapreduce.framework.name属性下配置为yarn。mapred.map.tasks和mapred.reduce.tasks分别为map和reduce的任务数,至于什么是map和reduce,可参考其它资料进行了解。
其它属性为一些进程的端口配置,均配在主机下。
mapred.job.tracker
master:9001
mapred.map.tasks
20
mapred.reduce.tasks
4
mapreduce.framework.name
yarn
mapreduce.jobhistory.address master:10020
mapreduce.jobhistory.webapp.address master:19888

配置文件7:yarn-site.xml
该文件为yarn框架的配置,主要是一些任务的启动位置
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.webapp.address
master:8088
yarn.resourcemanager.resource-tracker.address master:8031
yarn.resourcemanager.admin.address master:8033
yarn.nodemanager.aux-services mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler
将这些文件都复制到所有节点中
第八步:启动和验证
-
进行格式化:
sudo ./bin/hdfs namenode -format

- 启动hdfs:
./sbin/start-dfs.sh
此时在Master上面运行的进程有:namenode secondarynamenode
Slave1和Slave2上面运行的进程有:datanode
启动yarn: ./sbin/start-yarn.sh
此时在Master上面运行的进程有:namenode secondarynamenode resourcemanager
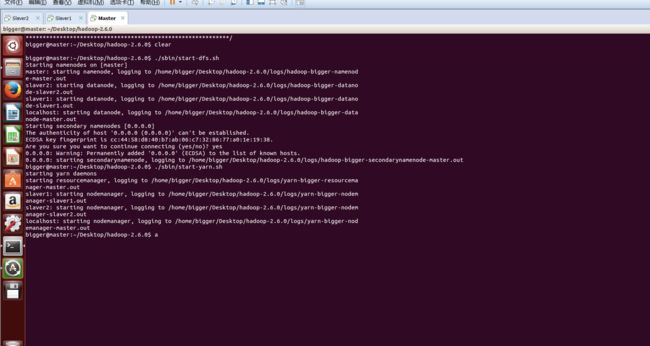
Slave1和Slave2上面运行的进程有:datanode nodemanager
- 检查启动结果
查看集群状态:./bin/hdfs dfsadmin –report
查看文件块组成: ./bin/hdfsfsck / -files -blocks
查看HDFS: http://master:50070(主机IP)
查看RM: http:// master:8088(主机IP)