项目介绍
项目地址:戳这里
大概的讲一下这个项目的起因是大神要参加HackMIT,需要他们在15000张验证码中识别出10000张或者每个字符的识别准确率要到90%。然后他不想标注数据(就是这么任性~)。于是决定先自己生成一批验证码(synthesizer合成器),然后把这些验证码用一个refiner(GAN)去对这批合成的验证码做一些调整让它们看起来和真实的训练样本的样式差不多。这样他就相当于有了一批标注好的验证码,用这部分的标注验证码去训练一个分类器,然后对需要hack的15000张图片做分类。借鉴的paper是Apple在2016年发的,戳这里。但是呢,他发现他的这批数据训练出来的模型对真实样本的准确率只有55%,于是他让一个同学标注了4000张要hack的图片(这个同学原本打算标注10000张),最后开开心心的一张图片都没标注的有了参加这个比赛的资格。
下面如果不想关注paper细节可以跳过这部分,直接到项目代码这一块就可以。
Overview
下图是paper中的总体结构。paper中是要合成和训练集相似的眼睛图片。

模拟器先合成一些图片(Synthetic),然后用一个Refiner对这个图片进行refine(改善,调整),再用一个判别器(discriminator)去判别refine之后的图片和真实的但没有标注的图片。目标是让判别器没有办法区分真实图片和refine出来的图片。那么我们就可以用模拟器生成一批有标注的数据,然后用refiner去进行修正,得到的图片就和原始的训练数据集很相近了。
Objective
这里简要的概述一下模型需要用到的损失函数。
Simulated+Unsupervised learning要用一些没有标注的的真实图片Y来学习一个Refiner,这个Refiner进一步用来refine我们的合成图片X。
关键点是需要让合成的图片x'看起来和真实的图片差不多,并且还要保留标注的信息。比如你要让你的合成图片的纹理和真实图片的纹理是一样的,同时你不能丢失合成图片的内容信息(realism)(验证码上面的数字字母)。因此有两个loss需要Refiner去优化:

上图中的l_real指的是refine之后的合成图片(x_i')和真实图片Y之间的loss。l_reg是原始合成图片x_i和被refine之后的合成图片的x_i'之间的loss。lambda是一个高参。
Refiner的目标就是尽可能的糊弄判别器D,让判别器没有办法区分一个图片是real还是合成的。判别器D的目标正好相反,是尽可能的能够区分出来。那么判别器的loss是这样的:

这个是一个二分类的交叉熵,D(.)是输入图片是合成图片的概率,1-D(.)就是输入图片是真实图片的概率。换句话说,如果输入的图片是合成图片,那么loss就是前半部分,如果输入是真实图片,loss就是后半部分。在实现的细节里面,当输入是合成图片x_i那么label就是1,反之为0。并且每个mini-batch当中,我们会随机采样一部分的真实图片和一部分的合成图片。模型方面用了ConvNet,最后一层输出是sample是合成图片的概率。最后用SGD来更新参数。(这里的判别器就是用了一个卷积网络,然后加了一个binary_categorical_crossentropy,再用SGD降低loss)。
那么和判别器目标相反,refiner应该是迫使判别器没有办法区分refine之后的合成图片。所以它的l_real是酱紫的:
接下来是l_reg, 为了保留原始图片的内容信息,我们需要一个loss来迫使模型不要把图片修改的和原始图片差异很大,这里引入了self-regularization loss。这个loss就是让refine之后的图片像素点和原始的图片的像素点之间的差不要太大。
综合起来refiner的loss如下:

在训练过程中,我们分别减小refiner和discriminator的loss。在更新refiner的时候就把discriminator的参数固定住不更新,在更新discriminator的参数的时候就固定refiner的参数。
这里有两个tricks。
- local adversarial loss
refiner在学习为真实图片建模的时候不应该引入artifacts, 当我们训练一个强判别器的时候,refiner会倾向于强调一些图片特征来fool当前的判别器,从而导致生成了一些artifacts。那么怎么解决呢?我可以可以观察到如果我们从refine的合成图片上挖出一块(patch),这一块的统计信息(statistics)应该是和真实图片的统计信息应该是相似的。因此,我们可以不用定义一个全局的判别器(对整张图片判断合成Or真实),我们可以对图片上的每一块都判别一下。这样的话,不仅仅是限定了接收域(receptive field),也为训练判别器提供了更多的样本。
判别器是一个全卷积网络,它的输出是w*h个patches是合成图片的概率。所以在更新refiner的时候,我们可以把这些w*h个patches的交叉熵loss相加。

比如上面这张图,输出就是2*3的矩阵,每个值表示的是这块patch是合成图片的概率值。算loss的时候把这6块图片的交叉熵都加起来。
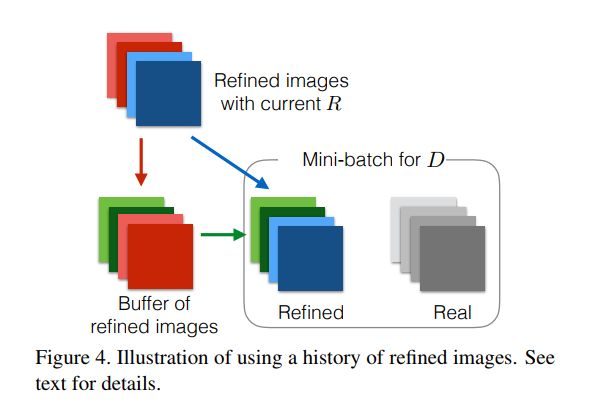
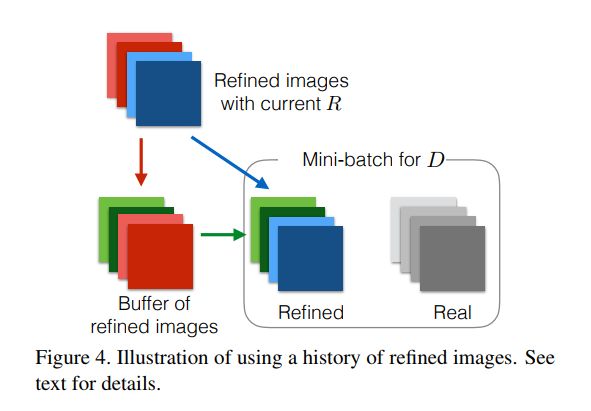
2.用refined的历史图片来更新判别器
对抗训练的一个问题是判别器只关注最近的refined图片,这会引起两个问题-对抗训练的分散和refiner网络又引进了判别器早就忘掉的artifacts。因此通过用refined的历史图片作为一个buffer而不单单是当前的mini-batch来更新分类器。具体方法是,在每一轮分类器的训练中,我们先从当前的batch中采样b/2张图片,然后从大小为B的buffer中采样b/2张图片,合在一起来更新判别器的参数。然后这一轮之后,用新生成的b/2张图片来替换掉B中的b/2张图片。
参数细节
实现细节:
Refiner:
输入图片55*35=> 64个3*3的filter => 4个resnet block => 1个1*1的fitler => 输出作为合成的图片(黑白的,所以1个通道)
1个resnet block是酱紫的:

Discriminator:
96个3*3filter, stride=2 => 64个3*3filter, stride = 2 => max_pool: 3*3, stride=1 => 32个3*3filter,stride=1 => 32个1*1的filter, stride=1 => 2个1*1的filter, stride=1 => softmax
我们的网络都是全卷积网络的,Refiner和Disriminator的最后层是很相似的(refiner的输出是和原图一样大小的, discriminator要把原图缩一下变成比如W/4 * H/4来表示这么多个patch的概率值)。 首先只用self-regularization loss来训练Refiner网络1000步, 然后训练Discriminator 200步。接着每次更新一次判别器,我们都更新Refiner两次。
算法具体细节如下:

项目代码Overview
challenges:需要预测的数据样本文件夹
imgs: 从challenges解压之后的图片文件夹
SimGAN-Captcha.ipynb: 整个项目的流程notebook
arial-extra.otf: 模拟器生成验证码的字体类型
avg.png: 比赛主办方根据每个人的信息做了一些加密生成的一些线条,训练的时候需要去掉这些线条。
image_history_buffer.py:

预处理
这部分原本作者是写了需要从某个地址把图片对应的base64加密的图片下载下来,但是因为这个是去年的比赛,url已经不管用了。所以作者把对应的文件直接放到了challenges里面。我们直接从第二步解压开始就可以了。因为python2和python3不太一样,作者应该用的是Python2, 我这里给出python3版本的代码。
解压
每个challenges文件下下的文件都是一个json文件,包含了1000个base64加密的jpg图片文件,所以对每一个文件,我们把base64的str解压成一个jpeg,然后把他们放到orig文件夹下。
import requests
import threading
URL = "https://captcha.delorean.codes/u/rickyhan/challenge"
DIR = "challenges/"
NUM_CHALLENGES = 20
lock = threading.Lock()
import json, base64, os
IMG_DIR = "./orig"
fnames = ["{}/challenge-{}".format(DIR, i) for i in range(NUM_CHALLENGES)]
if not os.path.exists(IMG_DIR):
os.mkdir(IMG_DIR)
def save_imgs(fname):
with open(fname,'r') as f:
l = json.loads(f.read(), encoding="latin-1")
for image in l['images']:
byte_image = bytes(map(ord,image['jpg_base64']))
b = base64.decodebytes(byte_image)
name = image['name']
with open(IMG_DIR+"/{}.jpg".format(name), 'wb') as f:
f.write(b)
for fname in fnames:
save_imgs(fname)
assert len(os.listdir(IMG_DIR)) == 1000 * NUM_CHALLENGES
解压之后的图片长这个样子:
from PIL import Image
imgpath = IMG_DIR + "/"+ os.listdir(IMG_DIR)[0]
imgpath2 = IMG_DIR + "/"+ os.listdir(IMG_DIR)[3]
im = Image.open(example_image_path)
im2 = Image.open(example_image_path2)
IMG_FNAMES = [IMG_DIR + '/' + p for p in os.listdir(IMG_DIR)]
im

img2

转换成黑白图片
二值图会节省很大的计算,所以我们这里设置了一个阈值,然后把图片一张张转换成相应的二值图。(这里采用的转换方式见下面的注释。)
def gray(img_path):
# convert to grayscale, then binarize
#L = R * 299/1000 + G * 587/1000 + B * 114/1000
img = Image.open(img_path).convert("L") # convert to gray scale, one 8-bit byte per pixel
img = img.point(lambda x: 255 if x > 200 or x == 0 else x) # value found through T&E
img = img.point(lambda x: 0 if x < 255 else 255, "1") # convert to binary image
img.save(img_path)
for img_path in IMG_FNAMES:
gray(img_path)
im = Image.open(example_image_path)
im

抽取mask
可以看到这些图片上面都有相同的水平的线,前面讲过,因为是比赛,所以这些captcha上的线都是根据参赛者的名字生成的。在现实生活中,我们可以用openCV的一些 形态转换函数(morphological transformation)来把这些噪音给过滤掉。这里作者用的是把所有图片相加取平均得到了mask。他也推荐大家可以用bit mask(&=)来过滤掉。
mask = np.ones((height, width))
for im in ims:
mask &= im
这里是把所有图片相加取平均:
import numpy as np
WIDTH, HEIGHT = im.size
MASK_DIR = "avg.png"
def generateMask():
N=1000*NUM_CHALLENGES
arr=np.zeros((HEIGHT, WIDTH),np.float)
for fname in IMG_FNAMES:
imarr=np.array(Image.open(fname),dtype=np.float)
arr=arr+imarr/N
arr=np.array(np.round(arr),dtype=np.uint8)
out=Image.fromarray(arr,mode="L") # save as gray scale
out.save(MASK_DIR)
generateMask()
im = Image.open(MASK_DIR) # ok this can be done with binary mask: &=
im

再修正一下
im = Image.open(MASK_DIR)
im = im.point(lambda x:255 if x > 230 else x)
im = im.point(lambda x:0 if x<255 else 255, "1") # 1-bit bilevel, stored with the leftmost pixel in the most significant bit. 0 means black, 1 means white.
im.save(MASK_DIR)
im

真实图片的生成器
我们在训练的时候也需要把真实的图片丢进去,所以这里直接用keras的flow_from_directory来自动生成图片并且把图片做一些预处理。
from keras import models
from keras import layers
from keras import optimizers
from keras import applications
from keras.preprocessing import image
import tensorflow as tf
# Real data generator
datagen = image.ImageDataGenerator(
preprocessing_function=applications.xception.preprocess_input
# 调用imagenet_utils的preoprocess input函数
# tf: will scale pixels between -1 and 1,sample-wise.
)
flow_from_directory_params = {'target_size': (HEIGHT, WIDTH),
'color_mode': 'grayscale',
'class_mode': None,
'batch_size': BATCH_SIZE}
real_generator = datagen.flow_from_directory(
directory=".",
**flow_from_directory_params
)
(Dumb)生成器(模拟器Simulator)
接着我们需要定义个生成器来帮我们生成(验证码,标注label)对,这些生成的验证码应该尽可能的和真实图片的那些比较像。
# Synthetic captcha generator
from PIL import ImageFont, ImageDraw
from random import choice, random
from string import ascii_lowercase, digits
alphanumeric = ascii_lowercase + digits
def fuzzy_loc(locs):
acc = []
for i,loc in enumerate(locs[:-1]):
if locs[i+1] - loc < 8:
continue
else:
acc.append(loc)
return acc
def seg(img):
arr = np.array(img, dtype=np.float)
arr = arr.transpose()
# arr = np.mean(arr, axis=2)
arr = np.sum(arr, axis=1)
locs = np.where(arr < arr.min() + 2)[0].tolist()
locs = fuzzy_loc(locs)
return locs
def is_well_formed(img_path):
original_img = Image.open(img_path)
img = original_img.convert('1')
return len(seg(img)) == 4
noiseimg = np.array(Image.open("avg.png").convert("1"))
# noiseimg = np.bitwise_not(noiseimg)
fnt = ImageFont.truetype('./arial-extra.otf', 26)
def gen_one():
og = Image.new("1", (100,50))
text = ''.join([choice(alphanumeric) for _ in range(4)])
draw = ImageDraw.Draw(og)
for i, t in enumerate(text):
txt=Image.new('L', (40,40))
d = ImageDraw.Draw(txt)
d.text( (0, 0), t, font=fnt, fill=255)
if random() > 0.5:
w=txt.rotate(-20*(random()-1), expand=1)
og.paste( w, (i*20 + int(25*random()), int(25+30*(random()-1))), w)
else:
w=txt.rotate(20*(random()-1), expand=1)
og.paste( w, (i*20 + int(25*random()), int(20*random())), w)
segments = seg(og)
if len(segments) != 4:
return gen_one()
ogarr = np.array(og)
ogarr = np.bitwise_or(noiseimg, ogarr)
ogarr = np.expand_dims(ogarr, axis=2).astype(float)
ogarr = np.random.random(size=(50,100,1)) * ogarr
ogarr = (ogarr > 0.0).astype(float) # add noise
return ogarr, text
def synth_generator():
arrs = []
while True:
for _ in range(BATCH_SIZE):
img, text = gen_one()
arrs.append(img)
yield np.array(arrs)
arrs = []
上面这段代码主要是随机产生了不同的字符数字,然后进行旋转,之后把字符贴在一起,把原来的那个噪音图片avg.png加上去,把一些重合的字符的验证码给去掉。这里如果发现有问题,强烈建议先升级一下PILLOW,debug了好久....sigh~
def get_image_batch(generator):
"""keras generators may generate an incomplete batch for the last batch"""
#img_batch = generator.next()
img_batch = next(generator)
if len(img_batch) != BATCH_SIZE:
img_batch = generator.next()
assert len(img_batch) == BATCH_SIZE
return img_batch
看一下真实的图片长什么样子
import matplotlib.pyplot as plt
%matplotlib inline
imarr = get_image_batch(real_generator)
imarr = imarr[0, :, :, 0]
plt.imshow(imarr)

我们生成的图片长什么样子
imarr = get_image_batch(synth_generator())[0, :, :, 0]
print imarr.shape
plt.imshow(imarr)

注意上面的图片之所以显示的有颜色是因为用了plt.imshow, 实际上是灰白的二值图。
这部分生成的代码,我个人觉得读者可以直接在github上下载一个验证码生成器就好,然后把图片根据之前的步骤搞成二值图就行,而且可以尽可能的选择跟自己需要预测的验证码比较相近的字体。
模型定义
整个网络一共有三个部分
- Refiner
Refiner,Rθ,是一个RestNet, 它在像素维度上去修改我们生成的图片,而不是整体的修改图片内容,这样才可以保留整体图片的结构和标注。(要不然就尴尬了,万一把字母a都变成别的字母标注就不准确了) - Discriminator
判别器,Dφ,是一个简单的ConvNet, 包含了5个卷积层和2个max-pooling层,是一个二分类器,区分一个验证码是我们合成的还是真实的样本集。 - 把他们合在一起
把refined的图片合到判别器里面
Refiner
主要是4个resnet_block叠加在一起,最后再用一个1*1的filter来构造一个feature_map作为生成的图片。可以看到全部的border_mode都是same,也就是说当中任何一步的输出都和原始的图片长宽保持一致(fully convolution)。
一个resnet_block是酱紫的:

我们先把输入图片用64个3*3的filter去conv一下,得到的结果(input_features)再把它丢到4个resnet_block中去。
def refiner_network(input_image_tensor):
"""
:param input_image_tensor: Input tensor that corresponds to a synthetic image.
:return: Output tensor that corresponds to a refined synthetic image.
"""
def resnet_block(input_features, nb_features=64, nb_kernel_rows=3, nb_kernel_cols=3):
"""
A ResNet block with two `nb_kernel_rows` x `nb_kernel_cols` convolutional layers,
each with `nb_features` feature maps.
See Figure 6 in https://arxiv.org/pdf/1612.07828v1.pdf.
:param input_features: Input tensor to ResNet block.
:return: Output tensor from ResNet block.
"""
y = layers.Convolution2D(nb_features, nb_kernel_rows, nb_kernel_cols, border_mode='same')(input_features)
y = layers.Activation('relu')(y)
y = layers.Convolution2D(nb_features, nb_kernel_rows, nb_kernel_cols, border_mode='same')(y)
y = layers.merge([input_features, y], mode='sum')
return layers.Activation('relu')(y)
# an input image of size w × h is convolved with 3 × 3 filters that output 64 feature maps
x = layers.Convolution2D(64, 3, 3, border_mode='same', activation='relu')(input_image_tensor)
# the output is passed through 4 ResNet blocks
for _ in range(4):
x = resnet_block(x)
# the output of the last ResNet block is passed to a 1 × 1 convolutional layer producing 1 feature map
# corresponding to the refined synthetic image
return layers.Convolution2D(1, 1, 1, border_mode='same', activation='tanh')(x)
Discriminator
这里注意一下subsample就是strides, 由于subsample=(2,2)所以会把图片长宽减半,因为有两个,所以最后的图片会变成原来的1/16左右。比如一开始图片大小是10050, 经过一次变换之后是5025,再经过一次变换之后是25*13。

最后生成了两个feature_map,一个是用来判断是不是real还有一个用来判断是不是refined的。
def discriminator_network(input_image_tensor):
"""
:param input_image_tensor: Input tensor corresponding to an image, either real or refined.
:return: Output tensor that corresponds to the probability of whether an image is real or refined.
"""
x = layers.Convolution2D(96, 3, 3, border_mode='same', subsample=(2, 2), activation='relu')(input_image_tensor)
x = layers.Convolution2D(64, 3, 3, border_mode='same', subsample=(2, 2), activation='relu')(x)
x = layers.MaxPooling2D(pool_size=(3, 3), border_mode='same', strides=(1, 1))(x)
x = layers.Convolution2D(32, 3, 3, border_mode='same', subsample=(1, 1), activation='relu')(x)
x = layers.Convolution2D(32, 1, 1, border_mode='same', subsample=(1, 1), activation='relu')(x)
x = layers.Convolution2D(2, 1, 1, border_mode='same', subsample=(1, 1), activation='relu')(x)
# here one feature map corresponds to `is_real` and the other to `is_refined`,
# and the custom loss function is then `tf.nn.sparse_softmax_cross_entropy_with_logits`
return layers.Reshape((-1, 2))(x) # (batch_size, # of local patches, 2)
把它们合起来
refiner 加到discriminator中去。这里有两个loss:
- self_regularization_loss
论文中是这么写的: The self-regularization term minimizes the image difference
between the synthetic and the refined images. 就是用来控制refine的图片不至于跟原来的图片差别太大,由于paper中没有具体写公式,但是大致就是让生成的像素值和原始图片的像素值之间的距离不要太大。这里项目的原作者是用了:
def self_regularization_loss(y_true, y_pred):
delta = 0.0001 # FIXME: need to figure out an appropriate value for this
return tf.multiply(delta, tf.reduce_sum(tf.abs(y_pred - y_true)))
y_true: 丢到refiner里面的input_image_tensor
y_pred: refiner的output
这里的delta是用来控制这个loss的权重,论文里面是lambda。
整个loss就是把refiner的输入图片和输出图片的每个像素点值相减取绝对值,最后把整张图片的差值都相加起来再乘以delta。
- local_adversarial_loss
为了让refiner能够学习到真实图片的特征而不是一些artifacts来欺骗判别器,我们认为我们从refined的图片中sample出来的patch, 应该是和真实图片的patch的statistics是相似的。所以我们在所有的local patches上定义判别器而不是学习一个全局的判别器。
def local_adversarial_loss(y_true, y_pred):
# y_true and y_pred have shape (batch_size, # of local patches, 2), but really we just want to average over
# the local patches and batch size so we can reshape to (batch_size * # of local patches, 2)
y_true = tf.reshape(y_true, (-1, 2))
y_pred = tf.reshape(y_pred, (-1, 2))
loss = tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_pred)
return tf.reduce_mean(loss)
合起来如下:
# Refiner
synthetic_image_tensor = layers.Input(shape=(HEIGHT, WIDTH, 1)) #合成的图片
refined_image_tensor = refiner_network(synthetic_image_tensor)
refiner_model = models.Model(input=synthetic_image_tensor, output=refined_image_tensor, name='refiner')
# Discriminator
refined_or_real_image_tensor = layers.Input(shape=(HEIGHT, WIDTH, 1)) #真实的图片
discriminator_output = discriminator_network(refined_or_real_image_tensor)
discriminator_model = models.Model(input=refined_or_real_image_tensor, output=discriminator_output,
name='discriminator')
# Combined
refiner_model_output = refiner_model(synthetic_image_tensor)
combined_output = discriminator_model(refiner_model_output)
combined_model = models.Model(input=synthetic_image_tensor, output=[refiner_model_output, combined_output],
name='combined')
def self_regularization_loss(y_true, y_pred):
delta = 0.0001 # FIXME: need to figure out an appropriate value for this
return tf.multiply(delta, tf.reduce_sum(tf.abs(y_pred - y_true)))
# define custom local adversarial loss (softmax for each image section) for the discriminator
# the adversarial loss function is the sum of the cross-entropy losses over the local patches
def local_adversarial_loss(y_true, y_pred):
# y_true and y_pred have shape (batch_size, # of local patches, 2), but really we just want to average over
# the local patches and batch size so we can reshape to (batch_size * # of local patches, 2)
y_true = tf.reshape(y_true, (-1, 2))
y_pred = tf.reshape(y_pred, (-1, 2))
loss = tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_pred)
return tf.reduce_mean(loss)
# compile models
BATCH_SIZE = 512
sgd = optimizers.RMSprop()
refiner_model.compile(optimizer=sgd, loss=self_regularization_loss)
discriminator_model.compile(optimizer=sgd, loss=local_adversarial_loss)
discriminator_model.trainable = False
combined_model.compile(optimizer=sgd, loss=[self_regularization_loss, local_adversarial_loss])
预训练
预训练对于GAN来说并不是一定需要的,但是预训练可以让GAN收敛的更快一些。这里我们两个模型都先预训练。
对于真实样本label标注为[1,0], 对于合成的图片label为[0,1]。
# the target labels for the cross-entropy loss layer are 0 for every yj (real) and 1 for every xi (refined)
# discriminator_model.output_shape = num of local patches
y_real = np.array([[[1.0, 0.0]] * discriminator_model.output_shape[1]] * BATCH_SIZE)
y_refined = np.array([[[0.0, 1.0]] * discriminator_model.output_shape[1]] * BATCH_SIZE)
assert y_real.shape == (BATCH_SIZE, discriminator_model.output_shape[1], 2)
对于refiner, 我们根据self_regularization_loss来预训练,也就是说对于refiner的输入和输出都是同一张图(类似于auto-encoder)。
LOG_INTERVAL = 10
MODEL_DIR = "./model/"
print('pre-training the refiner network...')
gen_loss = np.zeros(shape=len(refiner_model.metrics_names))
for i in range(100):
synthetic_image_batch = get_image_batch(synth_generator())
gen_loss = np.add(refiner_model.train_on_batch(synthetic_image_batch, synthetic_image_batch), gen_loss)
# log every `log_interval` steps
if not i % LOG_INTERVAL:
print('Refiner model self regularization loss: {}.'.format(gen_loss / LOG_INTERVAL))
gen_loss = np.zeros(shape=len(refiner_model.metrics_names))
refiner_model.save(os.path.join(MODEL_DIR, 'refiner_model_pre_trained.h5'))··
对于判别器,我们用一个batch的真实图片来训练,再用另一个batch的合成图片来交替训练。
from tqdm import tqdm
print('pre-training the discriminator network...')
disc_loss = np.zeros(shape=len(discriminator_model.metrics_names))
for _ in tqdm(range(100)):
real_image_batch = get_image_batch(real_generator)
disc_loss = np.add(discriminator_model.train_on_batch(real_image_batch, y_real), disc_loss)
synthetic_image_batch = get_image_batch(synth_generator())
refined_image_batch = refiner_model.predict_on_batch(synthetic_image_batch)
disc_loss = np.add(discriminator_model.train_on_batch(refined_image_batch, y_refined), disc_loss)
discriminator_model.save(os.path.join(MODEL_DIR, 'discriminator_model_pre_trained.h5'))
# hard-coded for now
print('Discriminator model loss: {}.'.format(disc_loss / (100 * 2)))
训练
这里有两个点1)用refined的历史图片来更新判别器,2)训练的整体流程
1)用refined的历史图片来更新判别器
对抗训练的一个问题是判别器只关注最近的refined图片,这会引起两个问题-对抗训练的分散和refiner网络又引进了判别器早就忘掉的artifacts。因此通过用refined的历史图片作为一个buffer而不单单是当前的mini-batch来更新分类器。具体方法是,在每一轮分类器的训练中,我们先从当前的batch中采样b/2张图片,然后从大小为B的buffer中采样b/2张图片,合在一起来更新判别器的参数。然后这一轮之后,用新生成的b/2张图片来替换掉B中的b/2张图片。
由于论文中没有写B的大小为多少,这里作者用了100*batch_size作为buffer的大小。
2)训练流程
xi是合成的的图片
yj是真实的图片
T是步数(steps)
K_d是每个step,判别器更新的次数
K_g是每个step,生成网络的更新次数(refiner的更新次数)

这里要注意在判别器更新的每一轮,其中的合成的图片的minibatch已经用1)当中的采样方式来替代了。
from image_history_buffer import ImageHistoryBuffer
k_d = 1 # number of discriminator updates per step
k_g = 2 # number of generative network updates per step
nb_steps = 1000
# TODO: what is an appropriate size for the image history buffer?
image_history_buffer = ImageHistoryBuffer((0, HEIGHT, WIDTH, 1), BATCH_SIZE * 100, BATCH_SIZE)
combined_loss = np.zeros(shape=len(combined_model.metrics_names))
disc_loss_real = np.zeros(shape=len(discriminator_model.metrics_names))
disc_loss_refined = np.zeros(shape=len(discriminator_model.metrics_names))
# see Algorithm 1 in https://arxiv.org/pdf/1612.07828v1.pdf
for i in range(nb_steps):
print('Step: {} of {}.'.format(i, nb_steps))
# train the refiner
for _ in range(k_g * 2):
# sample a mini-batch of synthetic images
synthetic_image_batch = get_image_batch(synth_generator())
# update θ by taking an SGD step on mini-batch loss LR(θ)
combined_loss = np.add(combined_model.train_on_batch(synthetic_image_batch,
[synthetic_image_batch, y_real]), combined_loss) #注意combine模型的local adversarial loss是要用y_real来对抗学习,从而迫使refiner去修改图片来做到跟真实图片很像
for _ in range(k_d):
# sample a mini-batch of synthetic and real images
synthetic_image_batch = get_image_batch(synth_generator())
real_image_batch = get_image_batch(real_generator)
# refine the synthetic images w/ the current refiner
refined_image_batch = refiner_model.predict_on_batch(synthetic_image_batch)
# use a history of refined images
half_batch_from_image_history = image_history_buffer.get_from_image_history_buffer()
image_history_buffer.add_to_image_history_buffer(refined_image_batch)
if len(half_batch_from_image_history):
refined_image_batch[:batch_size // 2] = half_batch_from_image_history
# update φ by taking an SGD step on mini-batch loss LD(φ)
disc_loss_real = np.add(discriminator_model.train_on_batch(real_image_batch, y_real), disc_loss_real)
disc_loss_refined = np.add(discriminator_model.train_on_batch(refined_image_batch, y_refined),
disc_loss_refined)
if not i % LOG_INTERVAL:
# log loss summary
print('Refiner model loss: {}.'.format(combined_loss / (LOG_INTERVAL * k_g * 2)))
print('Discriminator model loss real: {}.'.format(disc_loss_real / (LOG_INTERVAL * k_d * 2)))
print('Discriminator model loss refined: {}.'.format(disc_loss_refined / (LOG_INTERVAL * k_d * 2)))
combined_loss = np.zeros(shape=len(combined_model.metrics_names))
disc_loss_real = np.zeros(shape=len(discriminator_model.metrics_names))
disc_loss_refined = np.zeros(shape=len(discriminator_model.metrics_names))
# save model checkpoints
model_checkpoint_base_name = os.path.join(MODEL_DIR, '{}_model_step_{}.h5')
refiner_model.save(model_checkpoint_base_name.format('refiner', i))
discriminator_model.save(model_checkpoint_base_name.format('discriminator', i))
SimGAN的结果
我们从合成图片的生成器中拿一个batch的图片,用训练好的refiner去Predict一下,然后显示其中的一张图(我运行生成的图片当中是一些点点的和作者的不太一样,但是跟真实图片更像,待补充):
synthetic_image_batch = get_image_batch(synth_generator())
arr = refiner_model.predict_on_batch(synthetic_image_batch)
plt.imshow(arr[200, :, :, 0])
plt.show()

plt.imshow(get_image_batch(real_generator)[2,:,:,0])
plt.show()

这里作者认为生成的图片中字母的边都模糊和有噪音的,不那么的平滑了。(我觉得和原始图片比起来,在refine之前的图片看起来和真实图片也很像啊,唯一不同的应该是当中那些若有若无的点啊,读者可以在生成图片的时候把噪音给去掉,再来refine图片,看能不能生成字母边是比较噪音的(noisy),我这边refine之后的图片就是当中有一点一点的,图片待补充)
开始运用到实际的验证码识别
那么有了可以很好的生成和要预测的图片很像的refiner之后,我们就可以构造我们的验证码分类模型了,这里作者用了多输出的模型,就是给定一张图片,有固定的输出(这里是4,因为要预测4个字母)。
我们先用之前的合成图片的生成器(gen_one)来构造一个生成器,接着用refiner_model来预测一下作为这个generator的输出图片。由于分类模型的输出要用categorical_crossentropy,所以我们需要把输出的字母变成one-hot形式。
n_class = len(alphanumeric)
def mnist_generator(batch_size=128):
X = np.zeros((batch_size, HEIGHT, WIDTH, 1), dtype=np.uint8)
y = [np.zeros((batch_size, n_class), dtype=np.uint8) for _ in range(4)] # 4 chars
while True:
for i in range(batch_size):
im, random_str = gen_one()
X[i] = im
for j, ch in enumerate(random_str):
y[j][i, :] = 0
y[j][i, alphanumeric.find(ch)] = 1 # one_hot形式,让当前字母的index为1
yield refiner_model.predict(np.array(X)), y
mg = mnist_generator().next()
建模
from keras.layers import *
input_tensor = Input((HEIGHT, WIDTH, 1))
x = input_tensor
x = Conv2D(32, kernel_size=(3, 3),
activation='relu')(x)
# 4个conv-max_polling
for _ in range(4):
x = Conv2D(128, (3, 3), activation='relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.25)(x)
x = Flatten()(x)
x = Dense(128, activation='relu')(x)
x = Dropout(0.5)(x)
x = [Dense(n_class, activation='softmax', name='c%d'%(i+1))(x) for i in range(4)] # 4个输出
model = models.Model(inputs=input_tensor, outputs=x)
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
from keras.callbacks import History
history = History() # history call back现在已经是每个模型在训练的时候都会自带的了,fit函数会返回,主要用于记录事件,比如loss之类的
model.fit_generator(mnist_generator(), steps_per_epoch=1000, epochs=20, callbacks=[history])
测试模型
先看一下在合成图片上的预测:
def decode(y):
y = np.argmax(np.array(y), axis=2)[:,0]
return ''.join([alphanumeric[x] for x in y])
X, y = next(mnist_generator(1))
y_pred = model.predict(X)
plt.title('real: %s\npred:%s'%(decode(y), decode(y_pred)))
plt.imshow(X[0, :, :, 0], cmap='gray')
plt.axis('off')

看一下对于要预测的图片的预测:
X = next(real_generator)
X = refiner_model.predict(X)
# 不确定作者为什么要用refiner来predict,应该是可以省去这一步的
# 事实证明是不可以的,后面会分析
y_pred = model.predict(X)
plt.title('pred:%s'%(decode(y_pred)))
plt.imshow(X[0,:,:,0], cmap='gray')
plt.axis('off')

后续补充
-
将预测模型这里的图片替换掉,改成实际操作时候生成的图片
在训练过程中可以发现判别器的loss下降的非常快,并且到后面很难让refine的和real的loss都变高。有的时候运气好的话也许可以。我在训练的时候出现了两种情况:
第一种情况:
合成前:
 syn_before.png
syn_before.png
合成后:
 syn_after.png
syn_after.png
可以看到合成之后的图片中也是有一点一点的。拿这种图片去做训练,后面对真实图片做预测的时候就可以直接丢进分类器训练了。
第二种情况(作者notebook中展示的):
也就是前面写到的情况。
类似于下面这样,看起来refiner之后没什么变化的感觉:

这个看起来并没有感觉和真实图片很像啊!!!
可是神奇的是,作者在预测真实的图片的时候,他居然用refiner去predict真实的图片!
真实的图片之前是长这个样子的:

refiner之后居然长成了这样:

无语了呢!它居然把那些噪声点给去掉了一大半........他这波反向的操作让我很措手不及。于是他用refine之后的真实图片丢到分类器去做预测.....效果居然还不错.....
反正我已经凌乱了呢..............................
不过如何让模型能够学到我们人脑做识别的过程是件非常重要的事情呢...这里如果你想用合成的图片直接当作训练集去训练然后预测真实图片,准确率应该会非常低(我试了一下),也就是说模型在学习的过程中还是没有学习到字符的轮廓概念,但是我们又没办法控制教会它去学习怎么"识别"物体,应该学习哪些特征,最近发布的论文(戳这里)大家可以去看看(我还没有看...)。
未完待续
- 评估准确率
- 修改验证码生成器,改成其他任意的生成器
- 将模型用到更复杂的背景的验证码上,评估准确率