最近在学习Hbase二级索引的构建,虽然网上方案挺多,代码也并不复杂,但还是花了不少时间,主要是集群环境的调试踩了不少坑,毕竟新手... 这里将整个过程记录下来,以便日后学习之用。
为什么需要二级索引
Hbase默认只支持对行键的索引,那么如果需要针对其它的列来进行查询,就只能全表扫描了。表如果较大的话,代价是不可接受的,所以要提出二级索引的方案。网上的实现方法很多,华为,360等公司都有自己的方案,其中华为的已经开源,但是貌似对源码改动较大,新手不容易接受,所以没有选择它们。而其它的像利用Phoenix,solr等外部框架构建索引对Hbase的学习并没有太大的帮助。综上所述,我使用了Hbase自带的Cprocessor(协处理器)来实现。
Coprocessor
有关协处理器的讲解,Hbase官方文档是最好的,这里大体说一下它的作用与使用方法。
- Coprocessor提供了一种机制可以让开发者直接在RegionServer上运行自定义代码来管理数据。
通常我们使用get或者scan来从Hbase中获取数据,使用Filter过滤掉不需要的部分,最后在获得的数据上执行业务逻辑。但是当数据量非常大的时候,这样的方式就会在网络层面上遇到瓶颈。客户端也需要强大的计算能力和足够大的内存来处理这么多的数据,客户端的压力就会大大增加。但是如果使用Coprocessor,就可以将业务代码封装,并在RegionServer上运行,也就是数据在哪里,我们就在哪里跑代码,这样就节省了很大的数据传输的网络开销。 - Coprocessor有两种:Observer和Endpoint
EndPoint主要是做一些计算用的,比如计算一些平均值或者求和等等。而Observer的作用类似于传统关系型数据库的触发器,在一些特定的操作之前或者之后触发。学习过Spring的朋友肯定对AOP不陌生,想象一下AOP是怎么回事,就会很好的理解Observer了。Observer Coprocessor在一个特定的事件发生前或发生后触发。在事件发生前触发的Coprocessor需要重写以pre作为前缀的方法,比如prePut。在事件发生后触发的Coprocessor使用方法以post作为前缀,比如postPut。
Observer Coprocessor的使用场景如下:
2.1. 安全性:在执行Get或Put操作前,通过preGet或prePut方法检查是否允许该操作;
2.2. 引用完整性约束:HBase并不直接支持关系型数据库中的引用完整性约束概念,即通常所说的外键。但是我们可以使用Coprocessor增强这种约束。比如根据业务需要,我们每次写入user表的同时也要向user_daily_attendance表中插入一条相应的记录,此时我们可以实现一个Coprocessor,在prePut方法中添加相应的代码实现这种业务需求。
2.3. 二级索引:可以使用Coprocessor来维持一个二级索引。正是我们需要的
索引设计思想
关键部分来了,既然Hbase并没有提供二级索引,那如何实现呢?先看下面这张图
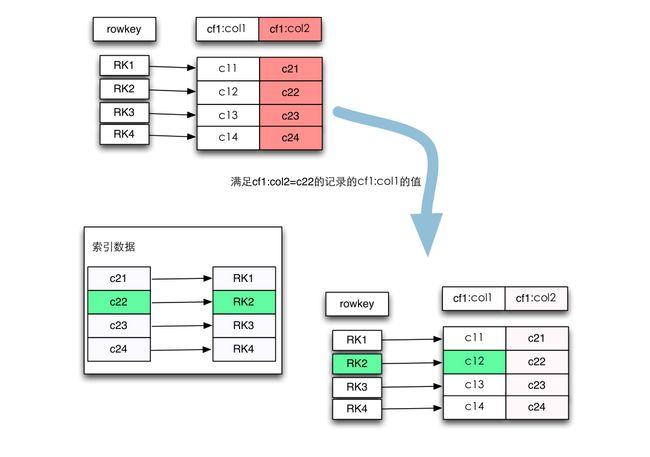
我们的需求是找出满足cf1:col2=c22这条记录的cf1:col1的值,实现方法如图,首先根据cf1:col2=c22查找到该记录的行键,然后再通过行健找到对应的cf1:col1的值。其中第二步是很容易实现的,因为Hbase的行键是有索引的,那关键就是第一步,如何通过cf1:col2的值找到它对应的行键。很容易想到建立cf1:col2的映射关系,即将它们提取出来单独放在一张索引表中,原表的值作为索引表的行键,原表的行键作为索引表的值,这就是Hbase的倒排索引的思想。
思想有了,工具有了Coprocessor,就开始具体实现了。我们想实现的功能就是每在原表插入一条数据,就相应的在索引表中也插入一条数据。也就是在Put数据到原表之前/之后使用Coprocessor提供的prePut/postPut方法向索引表中插入你想要的数据!
具体编码和排坑过程
我使用的环境
| 工具 | 版本 |
|---|---|
| hadoop | 2.7.1 |
| Hbase | 1.2.4 |
| zookeeper | 3.4.9 |
| Ubuntu | 14.04 |
| IDEA | 2017.1.2 |
Hbase提供了JavaAPI以实现增删改查,网上很多教程,大家可以自己去找,或者从我的github中down也行,我们直接来看Coprocessor中的代码怎么写
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
/**
* Created by cwj on 17-10-26.
*
*/
public class IndexObserver extends BaseRegionObserver {
private static final byte[] TABLE_NAME = Bytes.toBytes("index_name_users");
private static final byte[] COLUMN_FAMILY = Bytes.toBytes("personalDet");
private static final byte[] COLUMN = Bytes.toBytes("name");
private Configuration configuration = HBaseConfiguration.create();
@Override
public void prePut(ObserverContext e, Put put, WALEdit edit, Durability durability)
throws IOException {
HTable indexTable = new HTable(configuration, TABLE_NAME);
List cells = put.get(COLUMN_FAMILY, COLUMN);
Iterator| cellIterator = cells.iterator();
while (cellIterator.hasNext()) {
Cell cell = cellIterator.next();
Put indexPut = new Put(CellUtil.cloneValue(cell));
indexPut.add(COLUMN_FAMILY, COLUMN, CellUtil.cloneRow(cell));
indexTable.put(indexPut);
}
}
}
| | 这里用的是Hbase官网在Coprocessor给的那个例子,表结构是这样的:
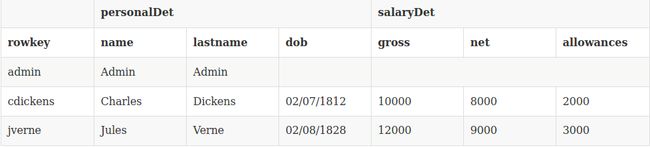
给personalDet:name列建立索引,代码本身很简单,大体说说吧,RegionObserver是基本接口,BaseRegionObserver是其实现类,一般继承这个类就行了,然后在prePut方法中向索引表中插入数据。可以看到prePut方法的入参有一个put对象,这个对象就是你在主表插入数据时的那个put对象,所以你可以通过这个对象拿到之前主表插入的数据,这样就可以实现自己的需求了。
之后将这个工程打成jar包(可以用IDEA自带的打包方式,或者maven-assembly-plugin插件也行),pom文件有这两个依赖就行了
org.apache.hbase
hbase-server
1.2.4
org.apache.hbase
hbase-client
1.2.4
Coprocessor加载方式
要使用Coprocessor,就需要先完成对其的装载。这可以静态实现(通过HBase配置文件),也可以动态完成(通过shell或Java API)。
静态装载和卸载Coprocessor
按以下如下步骤可以静态装载自定义的Coprocessor。需要注意的是,如果一个Coprocessor是静态装载的,要卸载它就需要重启HBase。
静态装载步骤如下:
- 在hbase-site.xml中使用
标签定义一个Coprocessor。 的子元素 的值只能从下面三个中选一个:
hbase.coprocessor.region.classes 对应 RegionObservers和Endpoints;
hbase.coprocessor.wal.classes 对应 WALObservers;
hbase.coprocessor.master.classes 对应MasterObservers。
而标签的内容则是自定义Coprocessor的全限定类名。
下面演示了如何装载一个自定义Coprocessor(这里是在SumEndPoint.java中实现的),需要在每个RegionServer的hbase-site.xml中创建如下的记录:
hbase.coprocessor.region.classes
org.cwj.hbase.coprocessor.observer.IndexObserver
如果要装载多个类,类名需要以逗号分隔。HBase会使用默认的类加载器加载配置中的这些类,因此需要将相应的jar文件上传到HBase服务端的类路径下。
使用这种方式加载的Coprocessor将会作用在HBase所有表的全部Region上,因此这样加载的Coprocessor又被称为系统Coprocessor。在Coprocessor列表中第一个Coprocessor的优先级值为Coprocessor.Priority.SYSTEM,其后的每个Coprocessor的值将会按序加一(这意味着优先级会减降低,因为优先级是按整数的自然顺序降序排列的)。
当调用配置的Observer Coprocessor时,HBase将会按照优先级顺序依次调用它们的回调方法。
- 将代码放到HBase的类路径下。一个简单的方法是将封装好的jar(包括代码和依赖)放到HBase安装路径下的/lib目录中。
- 重启HBase。
静态卸载的步骤如下:
- 移除在hbase-site.xml中的配置。
- 重启HBase。
- 这一步是可选的,将上传到HBase类路径下的jar包移除。
动态装载Coprocessor
动态装载Coprocessor的一个优势就是不需要重启HBase。不过动态装载的Coprocessor只是针对某个表有效。因此,动态装载的Coprocessor又被称为表级Coprocessor。
此外,动态装载Coprocessor是对表的一次schema级别的调整,因此在动态装载Coprocessor时,目标表需要离线(disable)。
动态装载Coprocessor有两种方式:通过HBase Shell和通过Java API。不管选择哪一种,都要先将打好的jar包上传到HDFS中
- Hbase Shell装载/卸载
1.1 先将表disable
disable 'users'
1.2 使用类似如下命令装载
alter 'users', METHOD => 'table_att', 'Coprocessor'=>'hdfs://:/
user//coprocessor.jar| org.cwj.hbase.Coprocessor.IndexObserver|1073741823|
arg1=1,arg2=2'
简单解释下这个命令。这条命令在一个表的table_att中添加了一个新的属性“Coprocessor”。使用的时候Coprocessor会尝试从这个表的table_attr中读取这个属性的信息。这个属性的值用管道符“|”分成了四部分:
文件路径:文件路径中需要包含Coprocessor的实现,并且对所有的RegionServer都是可达的。这个路径可以是每个RegionServer的本地磁盘路径,也可以是HDFS上的一个路径。通常建议是将Coprocessor实现存储到HDFS。HBASE-14548允许使用一个路径中包含的所有的jar,或者是在路径中使用通配符来指定某些jar,比如:hdfs://
类名:Coprocessor的全限定类名。
优先级:一个整数。HBase将会使用优先级来决定在同一个位置配置的所有Observer Coprocessor的执行顺序。这个位置可以留白,这样HBase将会分配一个默认的优先级。
参数(可选的):这些值会被传递给要使用的Coprocessor实现。这个项是可选的,可以不用填
1.3 enable这个表
enable 'users'
1.4 查看是否加载成功
describe 'users'
装载过程就是这样,卸载过程和装载大体一样的,也是先将表disable,卸载之后在重新enable
卸载方式如下:
hbase> alter 'users', METHOD => 'table_att_unset', NAME => 'coprocessor$1'
- 使用JavaAPI装载/卸载
Hbase版本前后经历了很大的变化,JavaAPI也是,有些方法在这个版本过期了,下个版本可能又会拿回来,所以代码根据自己的版本来,我这里提供的代码在1.2.4下是可以用的
public class CoprocessorUtilTest {
private String tableName;
private String jarPath;
private Class className;
private Logger logger = LogManager.getLogger(CoprocessorUtilTest.class);
@Before
public void setUp() throws Exception {
tableName = "users";
jarPath = "hdfs://os-1:9000/HbaseTest.jar";
className = ObserverExample.class;
// className = SumEndPoint.class;
// className = IndexObserver.class;
}
@Test
public void loadCoprocessor() throws Exception {
logger.info("load coprocessor...");
TableName tName = TableName.valueOf(tableName);
Path path = new Path(jarPath);
Configuration configuration = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
admin.disableTable(tName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
hTableDescriptor.addCoprocessor(className.getCanonicalName(), path, Coprocessor.PRIORITY_USER, null);
admin.modifyTable(tName, hTableDescriptor);
admin.enableTable(tName);
logger.info("load coprocessor successful!");
}
@Test
public void unloadCoprocessor() throws Exception {
logger.info("unload coprocessor...");
TableName tName = TableName.valueOf(tableName);
Configuration configuration = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
admin.disableTable(tName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
hTableDescriptor.removeCoprocessor(className.getCanonicalName());
admin.modifyTable(tName, hTableDescriptor);
admin.enableTable(tName);
logger.info("unload coprocessor successful!");
}
}
好了,这里有几个注意的地方
- 首先远程连接Hbase有两种方式,第一是在客户端代码中设置地址:
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "xxx.xxx.x.xx");
conf.set("hbase.zookeeper.property.clientPort", "2181");
我的环境使用这种方式一直提示无法连接到Hbase,不知道什么原因,这里推荐第二种方式,就是将的服务器的Hbase的配置文件hbase-site.xml,core-site.xml复制到客户端的src目录下,这样在加载的时候,首先它会从本地的配置文件读取地址,这样就可以连接到你的远程Hbase了。
- 表中有几个列族就一定要new几个HColumnDescriptor出来,当时以为只在personalDet上建立索引,所以就只new了一个出来,果然没有成功
- 这个问题就有点弱智了,看这句代码
hTableDescriptor.addCoprocessor(className.getCanonicalName(), path, Coprocessor.PRIORITY_USER, null);
第一个入参一定是一个Class对象.getCanonicalName(),刚开始傻叉的String classname。。。关于这个问题,我在另一篇帖子中说明了java中几种获取class的方式,有兴趣请看这里
这个问题本身很弱智,但是引发的后果还是很严重的,那就是加载之后,集群直接崩了,几个RegionServer全部dead了,重启之后也一样,10S之内,相继挂掉。。。毫无运维经验的我,看到这种情况一脸懵比,硬着头皮翻log,发现这个错误 java.lang.RuntimeException: HRegionServer Aborted,各种搜索发现,默认当加载了错误的Coprocessor之后,会导致RegionServer挂掉,原来如此,那就不慌了,解决方法是修改hbase-site.xml文件
hbase.coprocessor.abortonerror
false
关于这个参数,后续还会对它进行说明,这里设为false是指,哪怕加载了错误的Coprocessor,集群也不会崩溃
好了,集群重新起来了,修改了代码,成功加载上去了,兴冲冲的插入一条数据试试,然而再次懵比,索引表中并没有插入相应的索引数据
- 这又是什么鬼问题?log里并没有什么错误,在Coprocessor中加了log输出,发现并没有打印出来,看来是方法根本没有被调用。又是一顿搜索,问题还是出在上面说的那个参数上,
hbase.coprocessor.abortonerror:如果coprocessor加载失败或者初始化失败或者抛出Throwable对象,则主机退出。设置为false会让系统继续运行,但是coprocessor的状态会不一致,所以一般debug时才会设置为false,默认是true;.说的很清楚了,虽然我之后上传了很多个版本的coprocessor,但是在集群重启之前它一直沿用着最早那个版本。将参数再调整为true,重新上传jar包,重启集群,这下没问题了,索引表中出现了数据 - 还有一个问题,具体则怎么引起的给忘了,错误log好像是说hbase.table.sanity.checks的问题,解决方法依然是更改配置文件
hbase.table.sanity.checks
false
总结
代码其实并不复杂,但是集群的调试最麻烦,没事就去翻翻log,然后在根据错误找原因,今天就到此为止,之后再深入学习Hbase!
学习过程中参考的博客资料都在下面了
http://blog.itpub.net/12129601/viewspace-1690668/
http://blog.csdn.net/wwwxxdddx/article/details/50914667
http://blog.csdn.net/u013063153/article/details/72374974
http://blog.csdn.net/u011750989/article/details/50602373
http://blog.csdn.net/carl810224/article/details/52224441
http://hbasefly.com/2016/09/08/hbase-rit/
http://blog.itpub.net/12129601/viewspace-1690668/